







文章信息

论文题目为《Accurate predictions on small data with a tabular foundation model》,文章来自Nature正刊,论文提出了一种名为Tabular Prior-data Fitted Network(TabPFN)的表格基础模型,用于在小到中型表格数据上进行准确的预测,并在多项基准测试中显著优于现有的方法,如梯度提升决策树(如CatBoost、XGBoost等)。

摘要

表格数据(以行和列组织的结构化数据)在生物医学、材料科学、经济学等领域广泛应用,但传统方法(如梯度提升决策树)在处理小样本数据集时存在知识迁移能力弱、不确定性建模不足等问题。本文提出了一种基于Transformer架构的表格基础模型——Tabular Prior-data Fitted Network (TabPFN),通过在大规模合成数据上进行预训练,实现了对小到中型表格数据(样本量≤10,000,特征数≤500)的高效预测。实验表明,TabPFN在分类和回归任务中显著优于现有方法,例如在分类任务中以2.8秒的推理时间超越经过4小时调优的CatBoost集成模型(速度提升5,140倍),同时具备生成数据、密度估计和可解释性等基础模型特性。这一研究为表格数据分析提供了一种端到端学习的范式,有望加速科学发现与决策优化。

引言

表格数据的重要性与挑战:表格数据是科学研究与工业应用的核心载体。例如,在药物发现中,化学性质表格用于预测分子活性;在气候科学中,气象观测表格用于建模气候变化。然而,表格数据具有高度异质性:特征类型多样(布尔型、分类型、连续型)、存在缺失值与异常值,且不同数据集间特征语义差异显著(如“温度”在材料科学与气象学中的含义不同)。传统方法(如梯度提升决策树)虽在单数据集上表现优异,但难以实现跨数据集的知识迁移,且无法建模预测不确定性。
深度学习的局限与机遇:尽管深度学习在图像和自然语言处理领域取得突破,但在表格数据上的应用仍受限。原因包括:(1)表格数据缺乏空间或序列的局部相关性;(2)小样本场景下模型易过拟合;(3)传统树模型在计算效率上具有优势。然而,基于Transformer的大模型通过上下文学习(In-Context Learning, ICL)展现了强大的算法学习能力,为表格数据分析提供了新思路。
本文提出TabPFN,首次将基础模型范式引入表格数据分析,核心创新包括:
(1)基于合成数据的预训练框架:通过结构因果模型生成百万级合成数据集,覆盖真实数据的多样性挑战(如缺失值、异常值、无关特征);
(2)双向注意力架构:设计针对表格结构的Transformer层,实现样本与特征的双向交互,支持快速推理与状态缓存;
(3)多功能基础模型特性:除预测外,支持数据生成、密度估计、特征嵌入与微调,为下游任务提供统一工具。

方法论

TabPFN的流程分为三个阶段(图1):
(1)合成数据生成:基于结构因果模型(SCM)生成多样化数据集,模拟真实数据分布与挑战(如缺失值、异常值);
(2)预训练:使用Transformer模型学习从上下文(训练集)到目标(测试集)的映射,优化交叉熵损失;
(3)推理:将预训练模型应用于真实数据集,以前向传播完成训练与预测。
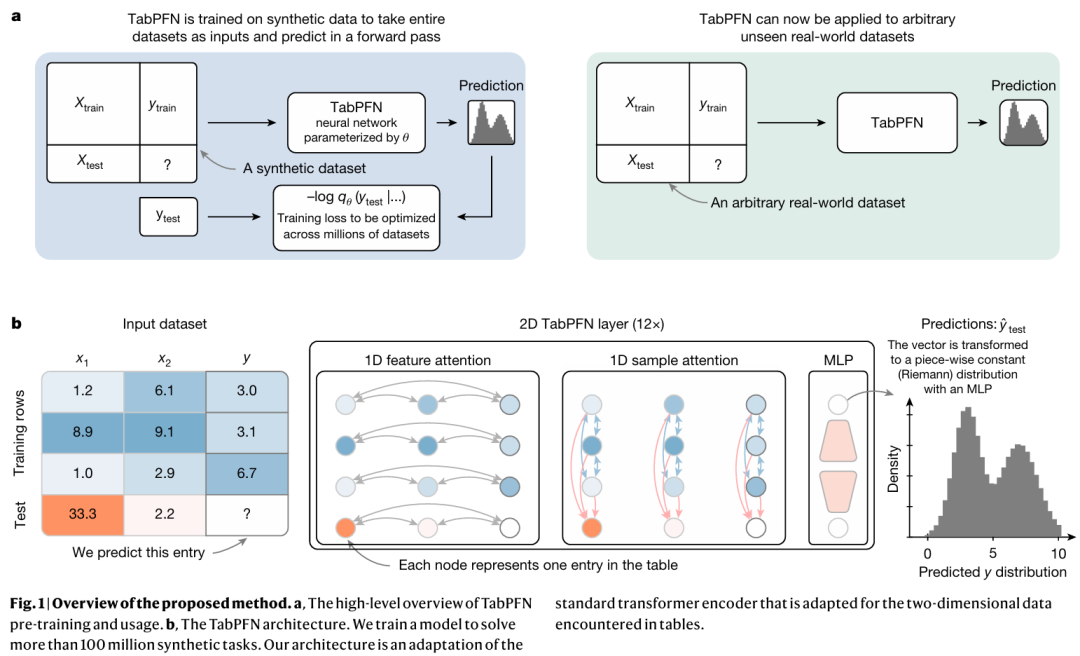
图1 模型框架图
1.合成数据生成
TabPFN的核心创新之一是通过大规模合成数据预训练模型,使其能够泛化到多样化的真实表格数据任务。本节详细阐述合成数据的生成机制,包括结构因果模型(Structural Causal Models, SCMs)的构建、计算图传播与后处理技术,确保生成数据覆盖真实场景中的复杂性(如缺失值、异常值、无关特征等)。步骤如图2:
(1)因果图采样:每个数据集的因果图节点数从对数均匀分布中采样,确保生成不同复杂度的图结构(如简单线性关系或深层非线性依赖)。采用偏好连接机制(Preferential Attachment)生成随机无标度网络。允许生成多个独立子图后合并,模拟真实数据中存在的无关特征(即与目标变量无因果路径的特征)。
(2)节点类型与初始化
根节点:代表数据生成过程的起点,其值通过正态分布、均匀分布、混合分布初始化。
中间节点与叶节点:通过计算图传播生成,代表衍生特征或目标变量。
(3)计算图传播与特征生成:每个节点的值通过其父节点的值经计算模块处理后生成,模块类型包括:非线性变换模块、离散化模块、决策树模块、噪声注入。
(4)特征与目标选择:完成计算图传播后,从图中选择特征列与目标列。
(5)后处理增强现实性:为逼近真实数据分布,对生成数据施加多种扰动:非线性扭曲、量化与分箱、缺失值注入、异常值生成。
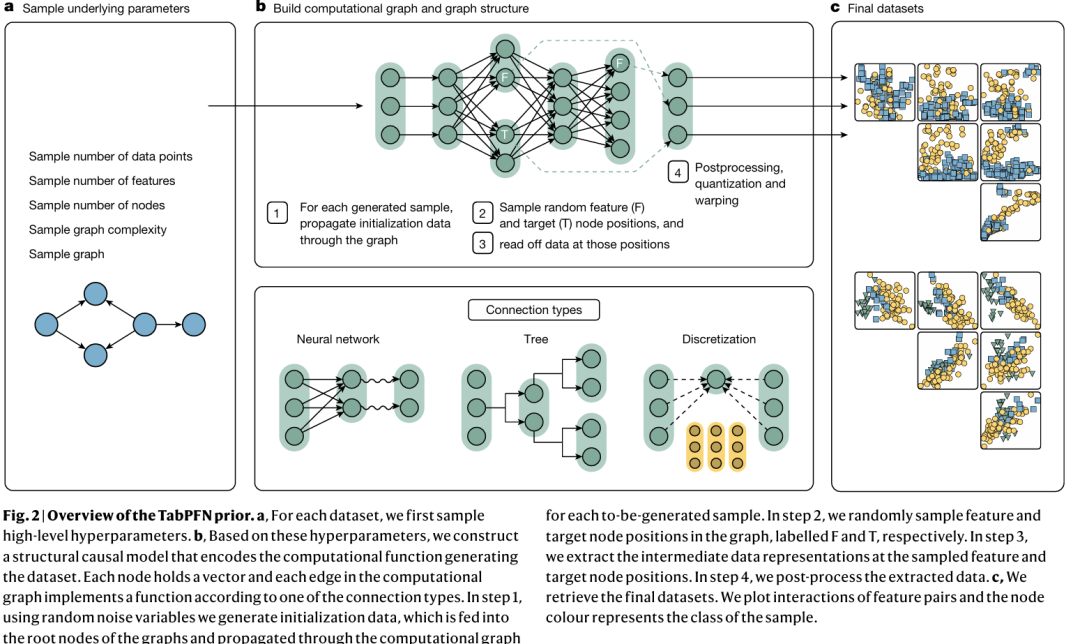
图2 合成数据生成
2.模型架构设计
TabPFN的模型架构针对表格数据的特性进行了深度优化,在标准Transformer编码器的基础上,引入了双向注意力机制、行列解耦计算和高效内存管理策略,实现了对表格结构的显式建模与高效推理。以下从核心模块、优化策略与输出建模三方面详细解析其设计原理。
(1)双向注意力机制:传统Transformer将输入视为单一序列处理,忽略了表格数据中行(样本)与列(特征)的二维结构。TabPFN提出双向注意力机制,将表格分解为行与列两个正交维度,分别进行注意力计算,充分捕捉样本间与特征间的依赖关系。特征注意力(Feature Attention):在同一行(样本)内,建模不同特征间的交互关系。例如,在医疗数据中,“年龄”与“血压”可能具有非线性关联。样本注意力(Sample Attention):在同一列(特征)内,建模不同样本间的全局依赖。例如,在金融风控中,相似客户的信用评分可能相互影响。双向注意力堆叠每个Transformer层依次执行特征注意力与样本注意力,形成“行→列”或“列→行”交替的计算流(图1b),不同层的注意力头共享部分参数,减少模型复杂度,增强泛化能力。
(2)针对表格数据规模大、特征异构性强的特点,TabPFN在计算与内存层面进行了多项优化:行列解耦计算、混合精度训练、动态内存分配、状态缓存与复用。
(3)输出建模:TabPFN不仅预测目标值,还建模其不确定性,支持回归与分类任务的概率输出。

实验

1.定量分析
在两个数据集上定量评估了TabPFN:AutoML Benchmark36和OpenML-CTR2337。这些基准包括不同的现实世界表格数据集,针对复杂性、相关性和领域多样性进行了精心策划。根据这些基准测试,使用了29个分类数据集和28个回归数据集,这些数据集有多达10000个样本、500个特征和10个类别。将TabPFN与最先进的基线进行了比较,包括基于树的方法(随机森林38、XGBoost(XGB)、CatBoost9、LightGBM8)、线性模型、支持向量机(SVM)和MLPs。评估指标包括ROC、AUC和分类准确性,以及R2和负RMSE用于回归,结果如图3。
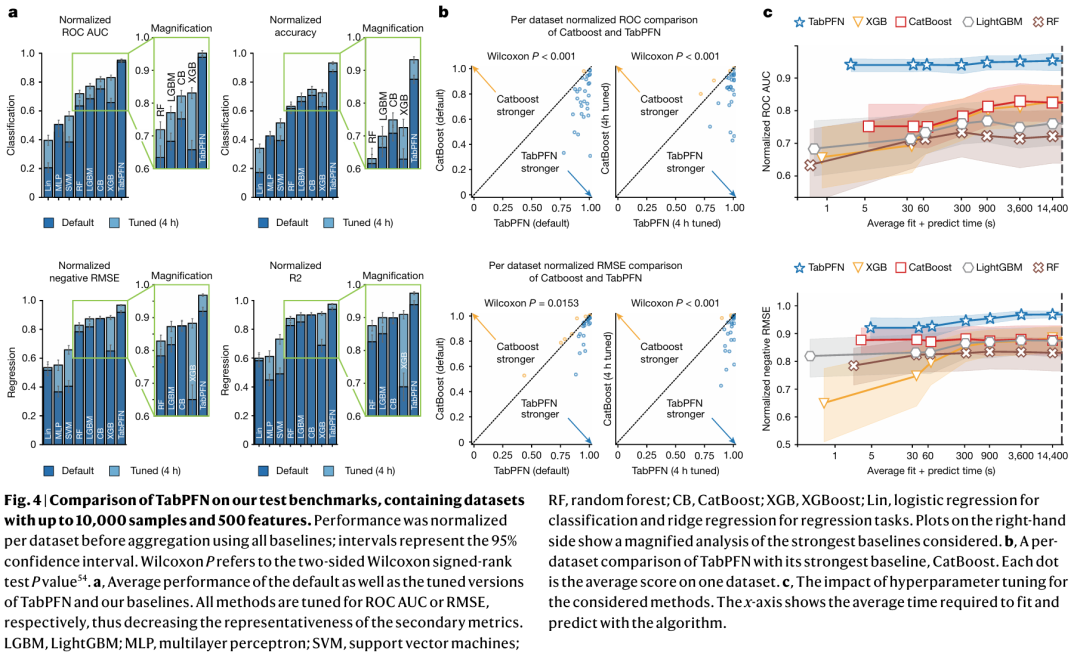
图3 实验结果
2.评估各种数据属性
在图4a、b中,展示了TabPFN对数据集特征的鲁棒性,而传统上基于神经网络的方法很难处理这些特征。图5a提供了TabPFN在各种数据集类型上的性能分析。首先,添加无信息特征(来自原始数据集的随机混洗特征)和异常值(将每个单元格以2%的概率乘以0和异常值因子之间的随机数)。结果表明,TabPFN对无信息特征和异常值具有很强的鲁棒性,这对神经网络来说通常很困难,正如MLP基线所示。其次,尽管丢弃样本或特征会损害所有方法的性能,但使用一半的样本,TabPFN的性能仍然与使用所有样本的次佳方法一样好。
在图4b中,将测试数据集划分为子组,并对每个子组进行分析。我们根据分类特征的存在、缺失值、样本数量和数据集中的特征数量创建子组。样本数和特征数子组被拆分,使得三分之一的数据集落入每个组中。可以看到,与其他方法相比,这些特征都没有强烈影响TabPFN的性能。
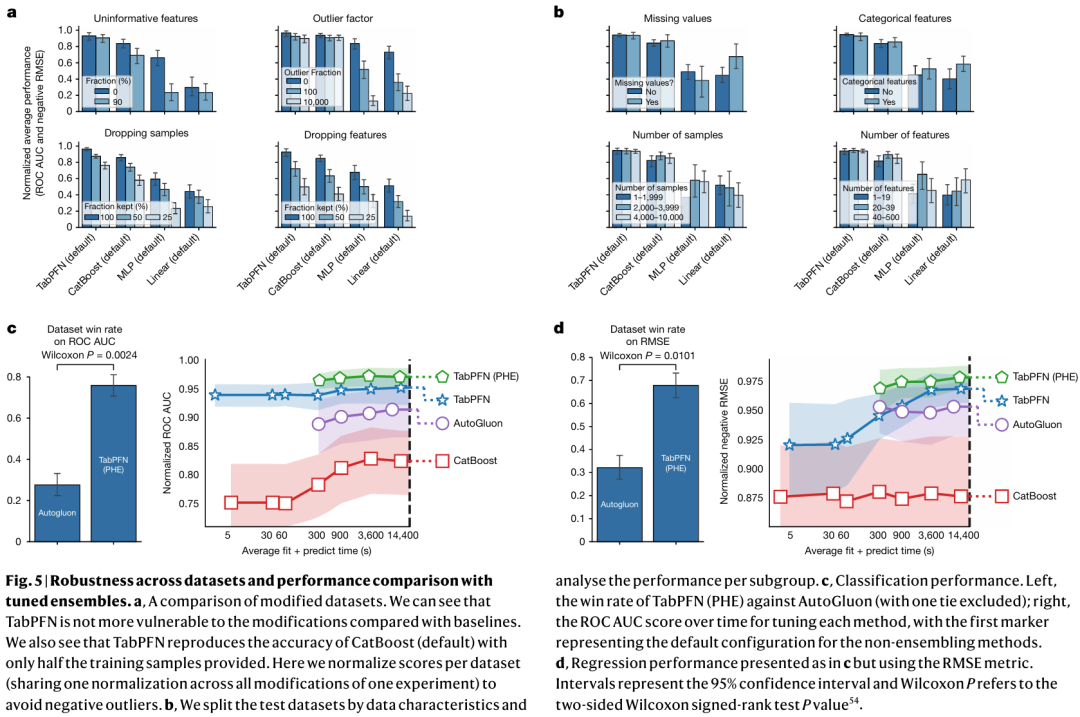
图4 实验结果

结论

TabPFN的合成数据生成框架通过结构因果模型与多样化后处理技术,系统性地模拟了真实表格数据的复杂性。这一方法不仅规避了真实数据收集中的隐私与版权问题,还通过控制生成参数实现了数据分布的全面覆盖,为模型预训练提供了高质量的算法学习环境。实验表明,由此生成的合成数据能够有效支持模型在未知真实任务上的强泛化能力。


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











