







神经网络编程基础
1、向量化时间效益的比较
2、激活函数的生成
3、梯度输出
4、重塑矩阵/向量尺寸
5、规范化数据
第一门课:神经网络和深度学习
第二周:神经网络的编程基础
一、向量化时间效益的比较
在矩阵/向量运算中,使用np.dot(a,b)可以大大减少时间
# 神经网络的编程基础---向量化
import numpy as np
import time # 导入时间库
a = np.array([1, 2, 3, 4]) # 创建一个数组
print(a)
a = np.random.rand(1000000)
b = np.random.rand(1000000) # 通过round随机得到两个一百万维度的数组
tic = time.time() # 测量一下当前时间
# 向量化版本
c = np.dot(a,b)
toc = time.time()
print("向量化的版本时间:" + str(1000*(toc-tic)) + "ms")
# 非向量化版本
c = 0
tic = time.time()
for i in range(1000000):
c+= a[i]*b[i]
toc = time.time()
print("循环版本时间:" + str(1000*(toc-tic)) + "ms")
二、激活函数的生成
比较math.exp(x)和np.exp(x)的不同,激活函数𝑠𝑖𝑔𝑚𝑜𝑖𝑑(𝑥)=1/(1+𝑒−𝑥次方)

# 使用激活函数sigmoid(x),分别用math.exp()和np.exp()
import math
import numpy as np
# 用exp()表示指数函数,在"math"库下
def math_sigmoid(x):
s = 1 / (math.exp(-x) + 1)
return s
print(math_sigmoid(1))
# 在numpy下使用激活函数---由于深度学习中大多使用矩阵和向量,用math无法满足需求
# 在numpy下输出将会广播成与输入同样的尺寸
def np_sigmoid(y):
w = 1 / (np.exp(-y) + 1)
return w
y = np.array([1, 2, 3])
print(np_sigmoid(y))
三、梯度输出

# 𝑠𝑖𝑔𝑚𝑜𝑖𝑑_𝑑𝑒𝑟𝑖𝑣𝑎𝑡𝑖𝑣𝑒(𝑥)=𝜎′(𝑥)=𝜎(𝑥)(1−𝜎(𝑥))
import numpy as np
def sigmoid(x):
s = 1/(np.exp(-x)+1)
return s
def sigmoid_derivative(x):
ds = sigmoid(x)*(1-sigmoid(x))
return ds
x = np.array([1,2,3])
print(str(sigmoid_derivative(x)))
四、重塑矩阵/向量尺寸

# 使用np.shape()和np.reshape()
# X.shape 用来得到矩阵/向量X的尺寸;X.reshape用来重塑尺寸
# 例如:将v(a,b,c)重塑成v(a*b,c)---> v=v.reshape((v.shape[0]*v.shape[1],v.shape[2]))
import numpy as np
# task:将(length,height,3) 变成 (length*height*3 , 1)
def image2vector(image):
v = image.reshape((image.shape[0] * image.shape[1] * image.shape[2], 1)) # 不要忘记双层括号
return v
image = np.array(
[[[0.67826139, 0.29380381],
[0.90714982, 0.52835647],
[0.4215251, 0.45017551]],
[[0.92814219, 0.96677647],
[0.85304703, 0.52351845],
[0.19981397, 0.27417313]],
[[0.60659855, 0.00533165],
[0.10820313, 0.49978937],
[0.34144279, 0.94630077]]])
print(str(image2vector(image)))
五、规范化数据

# 规范化数据,本例指归一化x -->𝑥/‖𝑥‖
import numpy as np
# 实现normalizeRows()以规范化矩阵的行,将此函数应用于输入矩阵 x 后,x 的每一行都应该是单位长度(即长度 1)的向量
def normalizeRows(x):
x_norm = x / (np.linalg.norm(x, axis=1, keepdims=True)) # 计算每一行的长度,得到一个列向量
return x_norm
x = np.array([[0, 3, 4], [1, 6, 4]])
print(str(normalizeRows(x)))
六、python中的广播

# 使用numpy实现softmax函数-需要对两个或多个类进行分类时使用的规范化函数
import numpy as np
def softmax(x):
# 对矩阵的每一元素指数化成softmax所需形式x_exp
x_exp = np.exp(x)
# 创造一个x_sum,对于每一行的x_exp使用求和np.sum(...,axis=1,keepdims=True)
x_sum = np.sum(x_exp,axis=1,keepdims=True)
# 通过x_exp除以x_sum,计算出softmax(x)
s = x_exp/x_sum
return s
x = np.array([[9,2,5,0,0],[7,5,0,0,0]])
print(str(softmax(x)))
七、损失函数
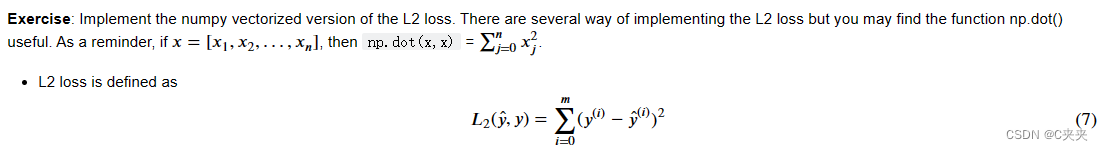
# 损失函数用于评估模型的性能,在深度学习中,可以使用梯度下降等优化算法来训练模型并最大限度地降低成本
import numpy as np
# 𝐿1(𝑦̂ ,𝑦)=∑|𝑦(𝑖)−𝑦̂ (𝑖)| ,使用abs()绝对值
def L1(yhat, y):
loss = np.sum(np.abs(y - yhat))
return loss
yhat = np.array([0.9, 0.2, 0.1, 0.4, 0.9])
y = np.array([1, 0, 0, 1, 1])
print(L1(yhat, y))
# 𝐿2(𝑦̂ ,𝑦)=∑(𝑦(𝑖)−𝑦̂ (𝑖))2 ,使用power(x,y)---计算x的y次方
def L2(yhat,y):
loss = np.sum(np.power((y-yhat),2))
return loss
print(str(L2(yhat,y)))















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









