







角色级语言模型 - 恐龙乐园
1、基本递归神经网络的前向传播
2、长短期记忆(LSTM)网络
3、循环神经网络中的反向传播
第五门课:序列模型
第一周:循环序列模型
欢迎来到恐龙岛!6500万年前,恐龙就存在了,在这项任务中,它们又回来了。你负责一项特殊任务。领先的生物学研究人员正在创造新品种的恐龙,并将它们带到地球上,而你的工作就是给这些恐龙起名字。如果恐龙不喜欢它的名字,它可能会变得讨厌,所以要明智地选择!
幸运的是,你已经学会了一些深度学习,你会用它来挽救局面。您的助手已经收集了他们能找到的所有恐龙名称的列表,并将它们编译到这个数据集中。(请随时点击上一个链接查看。若要创建新的恐龙名称,您将构建字符级语言模型以生成新名称。您的算法将学习不同的名称模式,并随机生成新名称。希望这个算法能保护你和你的团队免受恐龙的愤怒!
将学习:
1、如何存储文本数据以使用 RNN 进行处理
2、如何合成数据,在每个时间步对预测进行采样并将其传递给下一个 RNN 单元
3、如何构建字符级文本生成递归神经网络
4、为什么剪裁渐变很重要
我们将首先加载我们在rnn_utils中为您提供的一些功能。具体而言,您可以访问rnn_forward和rnn_backward等功能,这些功能等同于您在上一个分配中实现的功能。
import numpy as np
from utils import *
import random
from random import shuffle
一、问题描述
1、数据集及预处理
data = open('dinos.txt', 'r').read()
data= data.lower()
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
字符是 a-z(26 个字符)加上“n”(或换行符),在此作业中,它的作用类似于我们在讲座中讨论过的(或“句子结尾”)标记,只是在这里它表示恐龙名称的结尾而不是句子的结尾。在下面的单元格中,我们创建一个 python 字典(即哈希表)以将每个字符映射到 0-26 之间的索引。我们还创建了第二个 python 字典,将每个索引映射回相应的字符字符。这将帮助您确定哪个索引对应于 softmax 层的概率分布输出中的哪个字符。下面,char_to_ix 和 ix_to_char 是 python 字典。
char_to_ix = { ch:i for i,ch in enumerate(sorted(chars)) }
ix_to_char = { i:ch for i,ch in enumerate(sorted(chars)) }
print(ix_to_char)
2、模型概述
您的模型将具有以下结构:
1、初始化参数
2、运行优化循环
前向传播以计算损失函数
反向传播,用于计算相对于损失函数的梯度
剪裁渐变以避免渐变爆炸
使用梯度,使用梯度下降更新规则更新参数。
3、返回学习到的参数
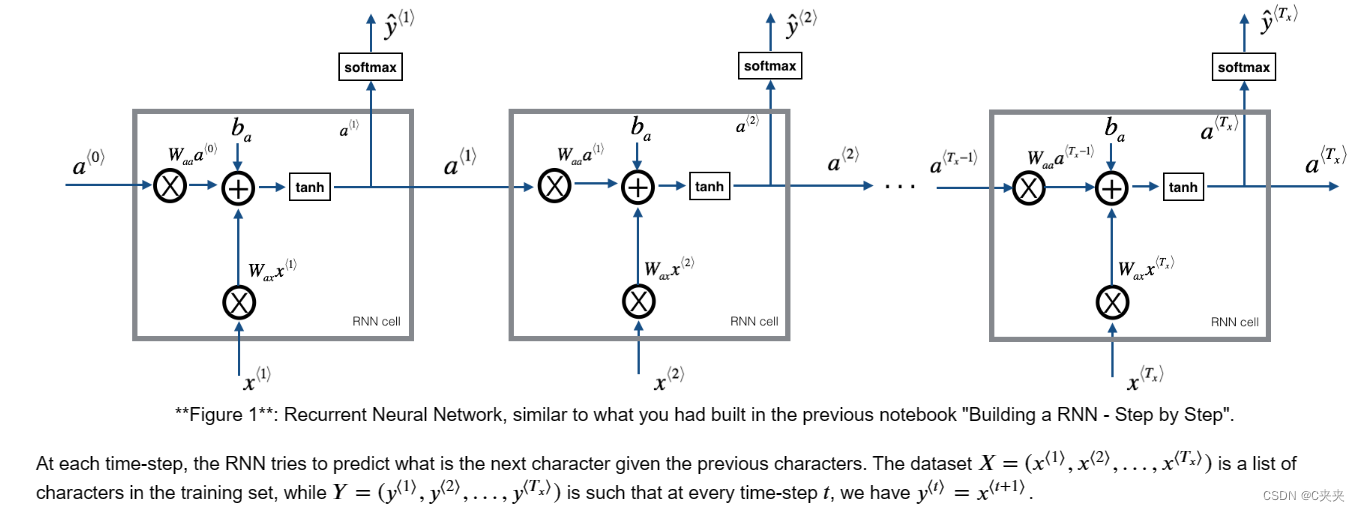
二、模型的构建基块
在这一部分中,您将构建整个模型的两个重要块:
1、渐变剪裁:避免渐变爆炸
2、采样:一种用于生成字符的技术
然后,您将应用这两个函数来构建模型。
1、在优化循环中剪裁梯度
在本节中,您将实现将在优化循环中调用的 clip 函数。回想一下,您的整体循环结构通常由前向传递、成本计算、后向传递和参数更新组成。在更新参数之前,您将在需要时执行梯度裁剪,以确保梯度不会“爆炸”,这意味着采用过大的值。
在下面的练习中,您将实现一个函数剪辑,该剪辑接收渐变字典,并在需要时返回渐变的剪辑版本。有多种方法可以剪裁渐变;我们将使用一个简单的元素剪裁过程,其中梯度向量的每个元素都被剪裁到位于某个范围 [-N, N] 之间。更一般地说,您将提供一个 maxValue(比如 10)。在此示例中,如果梯度向量的任何分量大于 10,则将其设置为 10;如果梯度向量的任何分量小于 -10,则将其设置为 -10。如果它介于 -10 和 10 之间,则不予理睬。
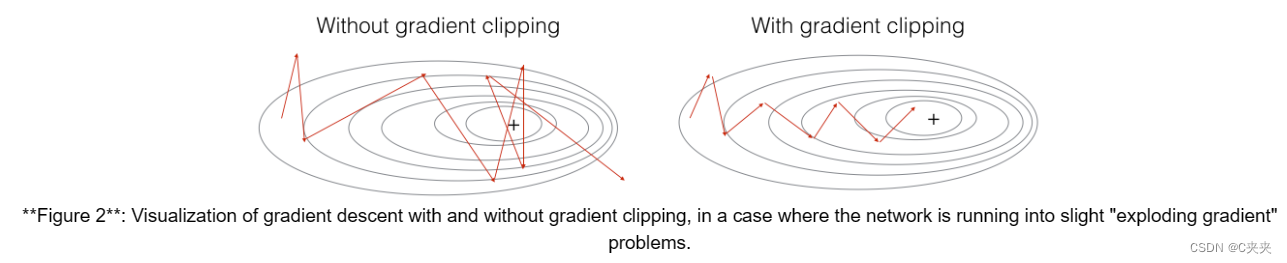
练习:实现以下函数以返回字典渐变的裁剪渐变。您的函数采用最大阈值并返回渐变的裁剪版本。你可以看看这个提示。
在最小值和最大值之间裁剪渐变值。
参数:
gradients -- 包含梯度 “dWaa”, “dWax”, “dWya”, “db”, “dby” 的字典
maxValue -- 高于此数字的所有内容都设置为此数字,小于 -maxValue 的所有内容都设置为 -maxValue
返回:gradients -- 包含剪裁渐变的字典。
### GRADED FUNCTION: clip
def clip(gradients, maxValue):
dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines)
for gradient in [dWax, dWaa, dWya, db, dby]:
np.clip(gradient, -maxValue, maxValue, out=gradient)
gradients = {"dWaa": dWaa, "dWax": dWax, "dWya": dWya, "db": db, "dby": dby}
return gradients
np.random.seed(3)
dWax = np.random.randn(5,3)*10
dWaa = np.random.randn(5,5)*10
dWya = np.random.randn(2,5)*10
db = np.random.randn(5,1)*10
dby = np.random.randn(2,1)*10
gradients = {"dWax": dWax, "dWaa": dWaa, "dWya": dWya, "db": db, "dby": dby}
gradients = clip(gradients, 10)
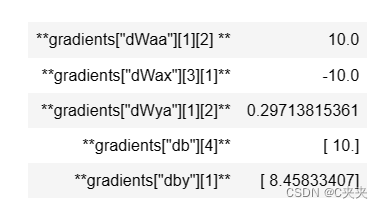
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
2、采样
现在假设您的模型已训练。您想要生成新文本(字符)。生成过程如下图所示:
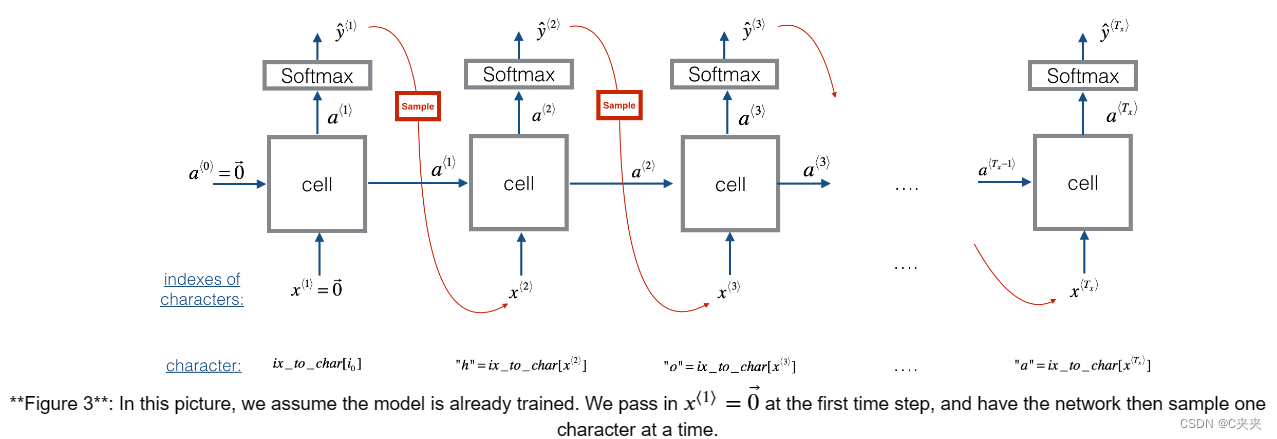
练习:实现以下示例函数以对字符进行采样。您需要执行 4 个步骤:
第 1 步:将第一个“虚拟”输入传递给网络 x⟨1⟩=0⃗(零的向量)。这是我们生成任何字符之前的默认输入。我们还设置了 a⟨0⟩=0⃗
第 2 步:运行一个步骤的前向传播以获得 a⟨1⟩和 ŷ ⟨1⟩以下是方程式:

请注意,⟨t+1⟩是一个 (softmax) 概率向量(其条目介于 0 和 1 之间,总和为 1)。 ⟨T+1⟩i表示由“i”索引的字符为下一个字符的概率。我们提供了一个您可以使用的 softmax() 函数。
第 3 步:进行抽样:根据 ŷ ⟨t+1 指定的概率分布选择下一个字符的索引⟩.这意味着,如果 ŷ ⟨t+1⟩i=0.16,您将以 16% 的概率选择指数“i”。要实现它,您可以使用 np.random.choice。
以下是如何使用 np.random.choice() 的示例:
np.random.seed(0)
p = np.array([0.1, 0.0, 0.7, 0.2])
index = np.random.choice([0, 1, 2, 3], p = p.ravel())
这意味着您将根据分布选择索引:P(index=0)=0.1,P(index=1)=0.0,P(index=2)=0.7,P(index=3)=0.2
第 4 步:在 sample() 中实现的最后一步是覆盖当前存储 x⟨t 的变量 x⟩ ,值为 x⟨t+1⟩.您将代表 x⟨t+1⟩通过创建一个与你选择的预测字符相对应的独热向量。然后,您将向前传播 x⟨t+1⟩并不断重复该过程,直到您得到一个“n”字符,表示您已经到达恐龙名称的末尾。
根据 RNN 输出的概率分布序列对字符序列进行采样
参数:
parameters -- 包含参数 Waa、Wax、Wya、by 和 b 的 python 字典。
char_to_ix -- 将每个字符映射到索引的 Python 字典。
种子 -- 用于分级目的。不用担心。
返回:索引 (indices) -- 长度为 n 的列表,包含采样字符的索引。
# GRADED FUNCTION: sample
def sample(parameters, char_to_ix, seed):
# Retrieve parameters and relevant shapes from "parameters" dictionary
Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b']
vocab_size = by.shape[0]
n_a = Waa.shape[1]
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). (≈1 line)
x = np.zeros((vocab_size, 1))
# Step 1': Initialize a_prev as zeros (≈1 line)
a_prev = np.zeros((n_a, 1))
# Create an empty list of indices, this is the list which will contain the list of indexes of the characters to generate (≈1 line)
indices = []
# Idx is a flag to detect a newline character, we initialize it to -1
idx = -1
# Loop over time-steps t. At each time-step, sample a character from a probability distribution and append
# its index to "indexes". We'll stop if we reach 50 characters (which should be very unlikely with a well
# trained model), which helps debugging and prevents entering an infinite loop.
counter = 0
newline_character = char_to_ix['\n']
while (idx != newline_character and counter != 50):
# Step 2: Forward propagate x using the equations (1), (2) and (3)
a = np.tanh(np.dot(Wax, x) + np.dot(Waa, a_prev) + b)
z = np.dot(Wya, a) + by
y = softmax(z)
# for grading purposes
np.random.seed(counter+seed)
# Step 3: Sample the index of a character within the vocabulary from the probability distribution y
idx = np.random.choice(range(len(y)), p = y.ravel())
# Append the index to "indices"
indices.append(idx)
# Step 4: Overwrite the input character as the one corresponding to the sampled index.
x = np.zeros((vocab_size, 1))
x[idx] = 1
# Update "a_prev" to be "a"
a_prev = a
# for grading purposes
seed += 1
counter +=1
if (counter == 50):
indices.append(char_to_ix['\n'])
return indices
np.random.seed(2)
n, n_a = 20, 100
a0 = np.random.randn(n_a, 1)
i0 = 1 # first character is ix_to_char[i0]
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
indexes = sample(parameters, char_to_ix, 0)
print("Sampling:")
print("list of sampled indices:", indexes)
print("list of sampled characters:", [ix_to_char[i] for i in indexes])
list of sampled indices: [18, 2, 26, 0]
list of sampled characters: [‘r’, ‘b’, ‘z’, ‘\n’]
三、建立语言模型
1、梯度下降
在本节中,您将实现一个函数,该函数执行随机梯度下降的一个步骤(使用剪裁梯度)。您将一次完成一个训练示例,因此优化算法将是随机梯度下降。提醒一下,以下是 RNN 常见优化循环的步骤:
1、通过 RNN 进行前向传播以计算损失
2、随时间向后传播,以计算相对于参数的损失梯度
3、如有必要,剪裁渐变
4、使用渐变下降更新参数
练习:实施此优化过程(随机梯度下降的一个步骤)。
我们为您提供以下功能:
def rnn_forward(X, Y, a_prev, parameters):
""" Performs the forward propagation through the RNN and computes the cross-entropy loss.
It returns the loss' value as well as a "cache" storing values to be used in the backpropagation."""
....
return loss, cache
def rnn_backward(X, Y, parameters, cache):
""" Performs the backward propagation through time to compute the gradients of the loss with respect
to the parameters. It returns also all the hidden states."""
...
return gradients, a
def update_parameters(parameters, gradients, learning_rate):
""" Updates parameters using the Gradient Descent Update Rule."""
...
return parameters
执行优化的一个步骤来训练模型。
参数:
X -- 整数列表,其中每个整数都是一个数字,映射到词汇表中的字符。
Y -- 整数列表,与 X 完全相同,但向左移动了一个索引。
a_prev -- 以前的隐藏状态。
参数 -- Python 字典包含:
Wax -- 权重矩阵乘以输入,形状的numpy数组(n_a,n_x)
Waa -- 权重矩阵乘以隐藏状态,形状的 numpy 数组 (n_a, n_a)
Wya -- 将隐藏状态与输出的 numpy 形状数组(n_y、n_a)相关联的权重矩阵
b -- 偏差,形状的 numpy 数组 (n_a, 1)
by -- 将隐藏状态与输出 numpy 数组(n_y, 1) 相关联的偏差
learning_rate -- 模型的学习率。
返回:
loss -- 损失函数的值(交叉熵)
梯度 -- Python 字典包含:
dWax -- 输入到隐藏权重的梯度,形状(n_a、n_x)
dWaa -- 隐藏到隐藏权重的梯度,形状(n_a、n_a)
dWya -- 隐藏到输出权重的梯度,形状(n_y,n_a)
db -- 偏置向量的梯度,形状为 (n_a, 1)
dby -- 输出偏置矢量的梯度,形状为 (n_y, 1)
a[len(X)-1] -- 形状为 (n_a, 1) 的最后一个隐藏状态
# GRADED FUNCTION: optimize
def optimize(X, Y, a_prev, parameters, learning_rate = 0.01):
# Forward propagate through time (≈1 line)
loss, cache = rnn_forward(X, Y, a_prev, parameters)
# Backpropagate through time (≈1 line)
gradients, a = rnn_backward(X, Y, parameters, cache)
# Clip your gradients between -5 (min) and 5 (max) (≈1 line)
gradients = clip(gradients, 5)
# Update parameters (≈1 line)
parameters = update_parameters(parameters, gradients, learning_rate)
return loss, gradients, a[len(X)-1]
np.random.seed(1)
vocab_size, n_a = 27, 100
a_prev = np.random.randn(n_a, 1)
Wax, Waa, Wya = np.random.randn(n_a, vocab_size), np.random.randn(n_a, n_a), np.random.randn(vocab_size, n_a)
b, by = np.random.randn(n_a, 1), np.random.randn(vocab_size, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "b": b, "by": by}
X = [12,3,5,11,22,3]
Y = [4,14,11,22,25, 26]
loss, gradients, a_last = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
print("Loss =", loss)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("np.argmax(gradients[\"dWax\"]) =", np.argmax(gradients["dWax"]))
print("gradients[\"dWya\"][1][2] =", gradients["dWya"][1][2])
print("gradients[\"db\"][4] =", gradients["db"][4])
print("gradients[\"dby\"][1] =", gradients["dby"][1])
print("a_last[4] =", a_last[4])

2、训练一个模型
给定恐龙名称数据集,我们使用数据集的每一行(一个名称)作为一个训练示例。每 100 步随机梯度下降,您将对 10 个随机选择的名称进行采样,以查看算法的表现。请记住对数据集进行随机排序,以便随机梯度下降以随机顺序访问示例。
练习:按照说明操作并实现 model()。当 examples[index] 包含一个恐龙名称(字符串)时,要创建一个示例 (X, Y),您可以使用以下命令:
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
请注意,我们使用:index= j % len(examples),其中 j = 1…num_iterations,以确保 examples[index] 始终是有效的语句(index 小于 len(examples))。X 的第一个条目为 None,rnn_forward() 将解释为设置 x⟨0⟩=0⃗ .此外,这确保了 Y 等于 X,但向左移动了一步,并附加了一个额外的“n”来表示恐龙名称的结束。
训练模型并生成恐龙名称。
参数:
数据 -- 文本语料库
ix_to_char -- 将索引映射到字符的字典
char_to_ix -- 将字符映射到索引的字典
num_iterations -- 训练模型的迭代次数
n_a -- softmax 层中隐藏神经元的数量
dino_names -- 在每次迭代中要采样的恐龙名称数。
vocab_size -- 文本中唯一字符的数量,词汇的大小
返回:parameters -- 学习参数
# GRADED FUNCTION: model
def model(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27):
# Retrieve n_x and n_y from vocab_size
n_x, n_y = vocab_size, vocab_size
# Initialize parameters
parameters = initialize_parameters(n_a, n_x, n_y)
# Initialize loss (this is required because we want to smooth our loss, don't worry about it)
loss = get_initial_loss(vocab_size, dino_names)
# Build list of all dinosaur names (training examples).
with open("dinos.txt") as f:
examples = f.readlines()
examples = [x.lower().strip() for x in examples]
# Shuffle list of all dinosaur names
shuffle(examples)
# Initialize the hidden state of your LSTM
a_prev = np.zeros((n_a, 1))
# Optimization loop
for j in range(num_iterations):
# Use the hint above to define one training example (X,Y) (≈ 2 lines)
index = j % len(examples)
X = [None] + [char_to_ix[ch] for ch in examples[index]]
Y = X[1:] + [char_to_ix["\n"]]
# Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters
# Choose a learning rate of 0.01
curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters, learning_rate = 0.01)
# Use a latency trick to keep the loss smooth. It happens here to accelerate the training.
loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly
if j % 2000 == 0:
print('Iteration: %d, Loss: %f' % (j, loss) + '\n')
# The number of dinosaur names to print
seed = 0
for name in range(dino_names):
# Sample indexes and print them
sampled_indexes = sample(parameters, char_to_ix, seed)
print_sample(sampled_indexes, ix_to_char)
seed += 1 # To get the same result for grading purposed, increment the seed by one.
print('\n')
return parameters
parameters = model(data, ix_to_char, char_to_ix)
结论
你可以看到,你的算法在训练结束时已经开始生成合理的恐龙名称。起初,它生成随机字符,但到最后,你可以看到带有酷结局的恐龙名称。随意运行算法更长时间并使用超参数,看看是否可以获得更好的结果。我们的实施产生了一些非常酷的名字,如maconucon,marloralus和macingsersaurus。希望你的模型也了解到恐龙的名字往往以saurus、don、aura、tor等结尾。
如果你的模型生成了一些不酷的名字,不要完全责怪模型——并不是所有实际的恐龙名字听起来都很酷。(例如,dromaeosauroides 是一个实际的恐龙名称,位于训练集中。但是这个模型应该给你一组候选人,你可以从中挑选最酷的!
这个任务使用了一个相对较小的数据集,因此你可以在 CPU 上快速训练 RNN。训练英语模型需要更大的数据集,通常需要更多的计算,并且可以在 GPU 上运行数小时。我们用恐龙的名字已经有一段时间了,到目前为止,我们最喜欢的名字是伟大、不可战胜和凶猛的名字:芒果龙!
四、像莎士比亚一样写作
一个类似(但更复杂)的任务是创作莎士比亚诗歌。与其从恐龙名称数据集中学习,不如使用莎士比亚诗歌集。使用 LSTM 单元格,您可以了解跨越文本中许多字符的长期依赖关系——例如,出现在序列某处的字符可能会影响序列中更晚应该不同的字符。这些长期依赖关系对于恐龙名称来说并不那么重要,因为这些名字很短。
我们已经用Keras实现了一个莎士比亚诗歌生成器。运行以下单元以加载所需的包和模型。这可能需要几分钟时间。
from __future__ import print_function
from keras.callbacks import LambdaCallback
from keras.models import Model, load_model, Sequential
from keras.layers import Dense, Activation, Dropout, Input, Masking
from keras.layers import LSTM
from keras.utils.data_utils import get_file
from keras.preprocessing.sequence import pad_sequences
from shakespeare_utils import *
import sys
import io
为了节省您的时间,我们已经在名为*“十四行诗”*的莎士比亚诗集上训练了一个~1000个时代的模型。
让我们再训练一个 epoch 的模型。当它完成一个 epoch 的训练时—这也需要几分钟时间—您可以运行 generate_output,这将提示您输入(<40 个字符)。这首诗将从你的句子开始,我们的RNN-莎士比亚将为你完成这首诗的其余部分!例如,尝试“Forsooth this maketh no sense”(不要输入引号)。根据是否在末尾包含空格,结果也可能有所不同 - 尝试两种方式,并尝试其他输入。
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y, batch_size=128, epochs=1, callbacks=[print_callback])
# Run this cell to try with different inputs without having to re-train the model
generate_output()
RNN-Shakespeare模型与您为恐龙名称构建的模型非常相似。唯一的主要区别是:
1、LSTM 代替基本 RNN,以捕获更长距离的依赖关系
2、该模型是一个更深的堆叠 LSTM 模型(2 层)
3、使用 Keras 而不是 python 来简化代码
如果您想了解更多信息,还可以在 GitHub 上查看 Keras 团队的文本生成实现:https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py。
引用:
1、这个练习的灵感来自安德烈·卡帕西(Andrej Karpathy)的实现:https://gist.github.com/karpathy/d4dee566867f8291f086。要了解有关文本生成的更多信息,请查看 Karpathy 的博客文章。
2、对于莎士比亚诗歌生成器,我们的实现基于 Keras 团队对 LSTM 文本生成器的实现:https://github.com/keras-team/keras/blob/master/examples/lstm_text_generation.py















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









