






目录
BERT and its family
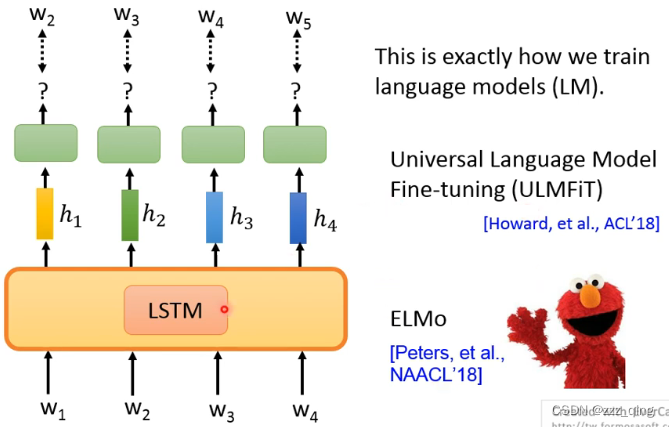
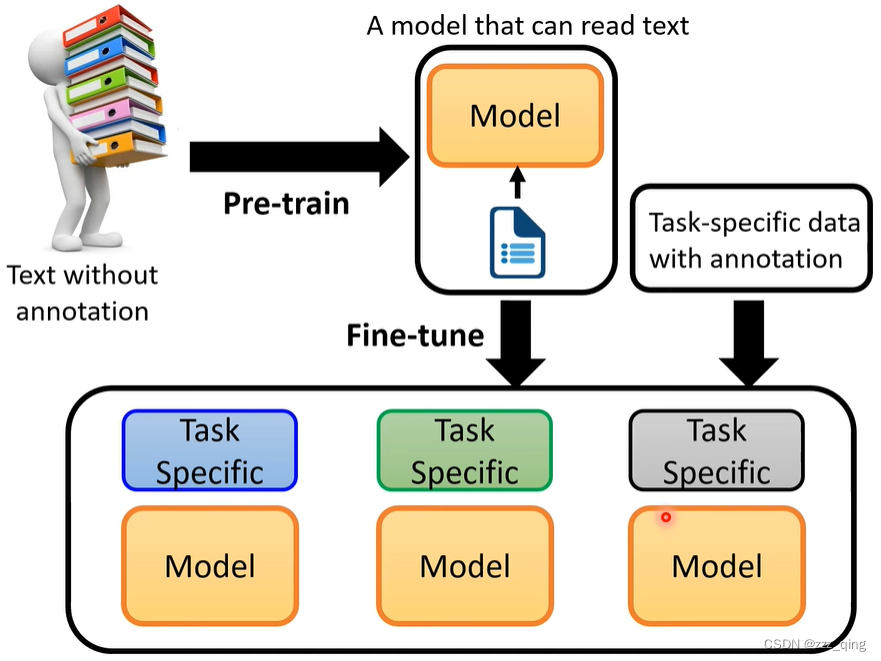
NLP领域所追求的目标,是和人类学习语言差不多的一个过程。先从整体上去了解学习语言(Pre-train),然后再针对性的学一些Downstream Task的相关资料(Fine-tune,这里是对模型进行一个微调)。从而就能够从一个Pre-train的模型,经过不同的微调后,去解不同的Downstream Task。
Pre-train的model中,最知名的是BERT,Pre-train的model喜欢用芝麻街的人物命名。
What is pre-train model
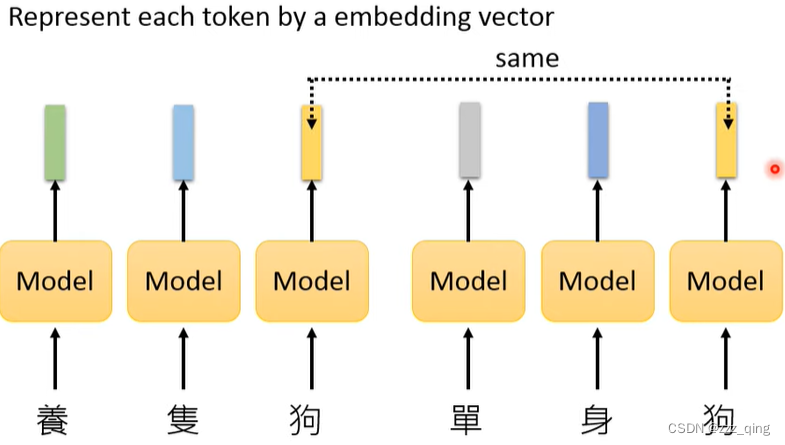
在以前的Pre-train model中,不考虑上下文,一个token用一个embedding vector表示,比如哈巴狗和单身狗的狗,都用同一个embedding vector表示,但这两个狗的意思又是不完全相同的:
然后就出现了Contextualized Word Embedding的概念(例如BERT),它产生的embedding vector考虑了token的上下文:
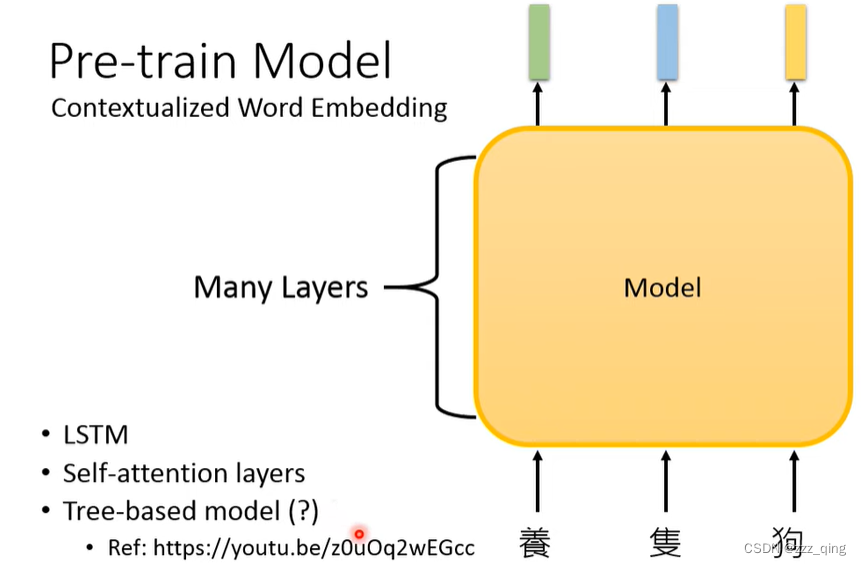
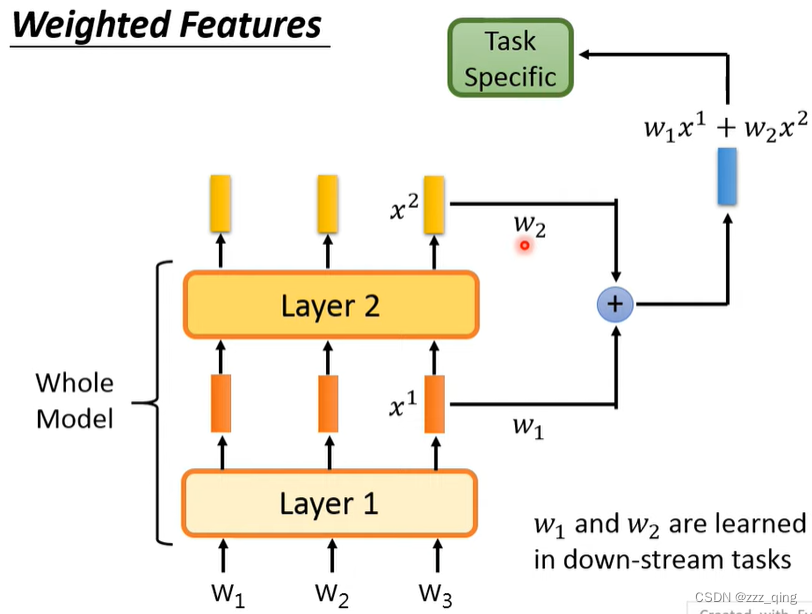
除了使用Pre-train model最后一层layer的输出当做embedding vector,也可以抽出各层layer的输出做weighted sum当做embedding vector:
流行趋势:model越来越大,Bigger Model
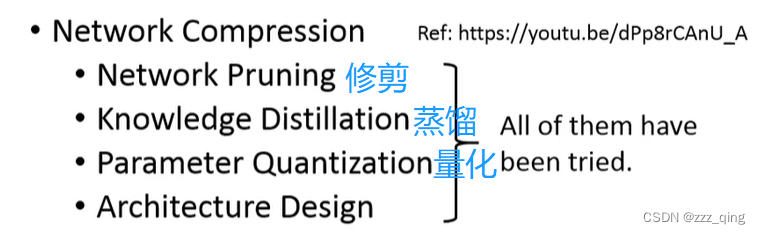
但是Bigger Model只有大公司才能做起来,所以还有Smaller Model:

如何把model变小:
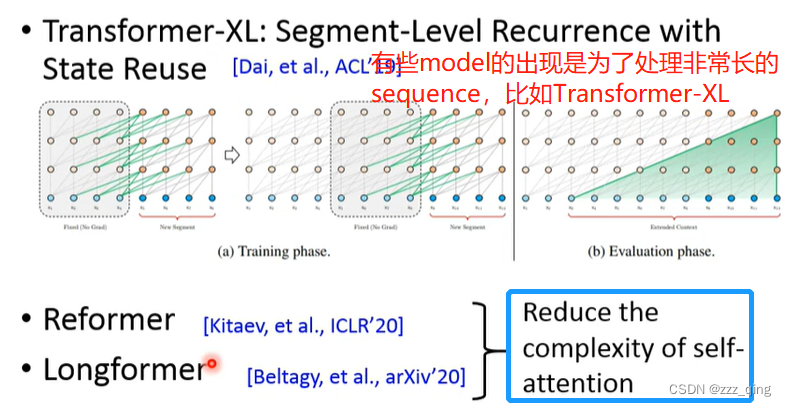
Network Architecture近年来新的进展:
How to fine-tune
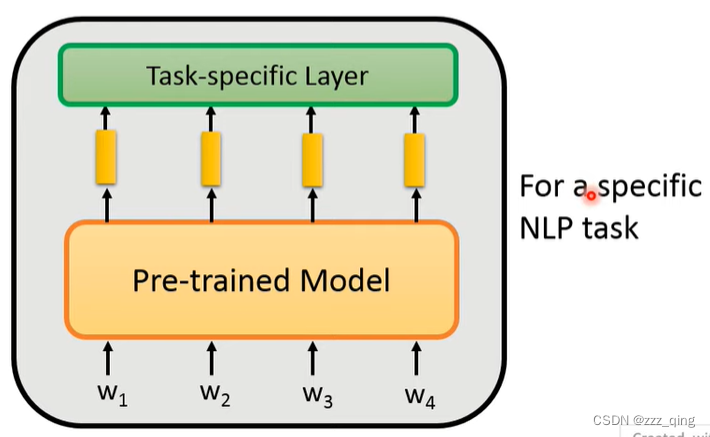
在Pre-train的model上叠一些Task-specific Layer,这个model就可以用在特定的NLP任务上:
NLP tasks分类如下:
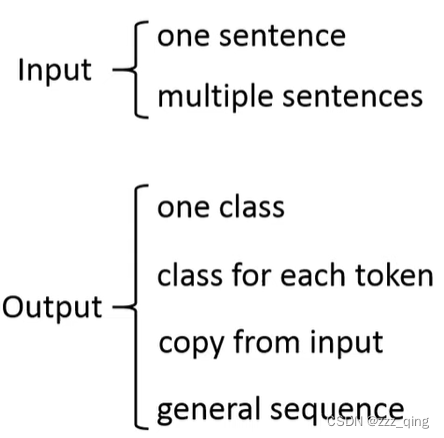
处理不同类型的NLP task的做法:
①Input是multiple sentence:
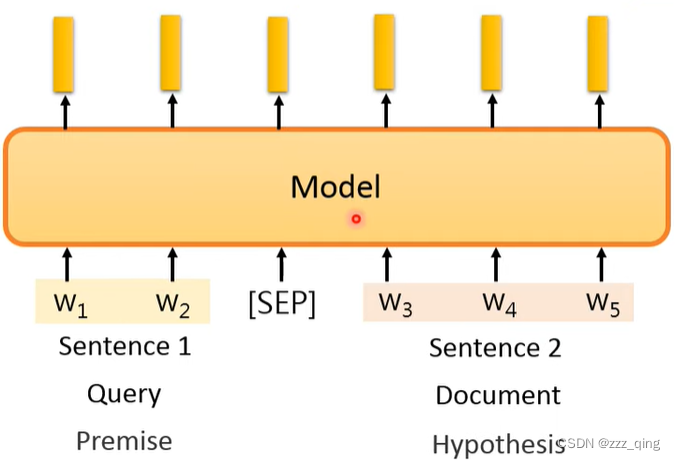
②Output是one class:
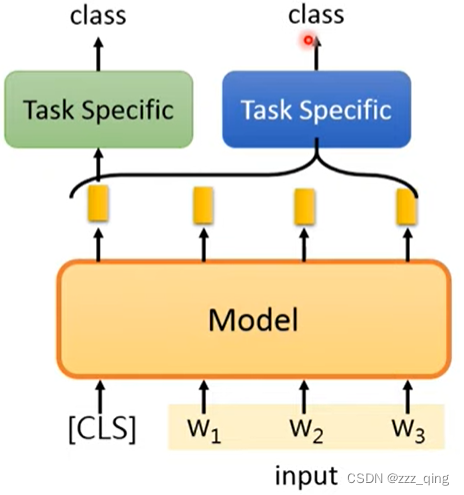
③Output是class for each token:
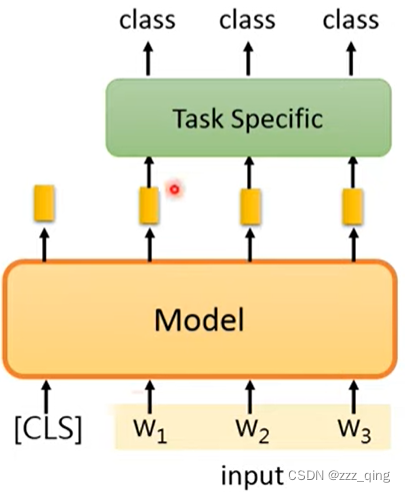
④Output是copy from input:

BERT中做法如下:
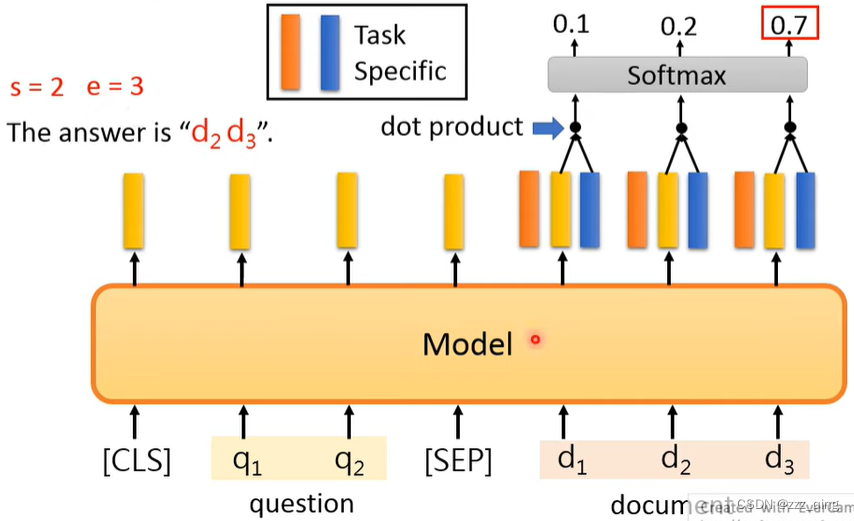
⑤Output是general sequence:
如何把pre-train的model用在seq2seq的model中,第一种做法(v1)是把pre-train的model当做encoder,把Task Specific的model当做decoder。但这样的话Task Specific的model较大,它没有经过预训练,训练时用的Downstream Task的相关资料又比较少,所以Task Specific的model不会被训练的很好:
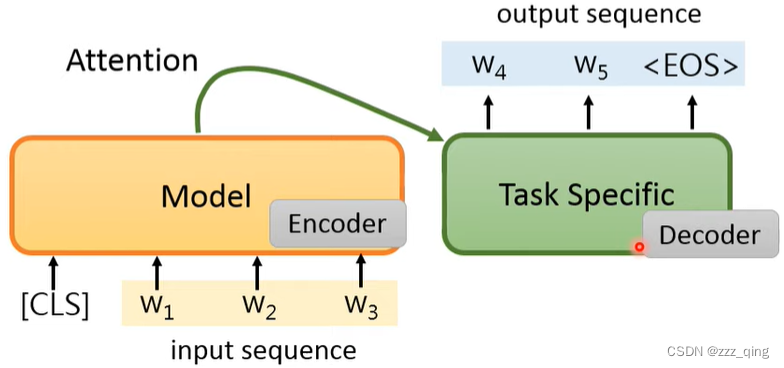
另一种做法(v2)如下,有可能把pre-train的model当做decoder来使用:
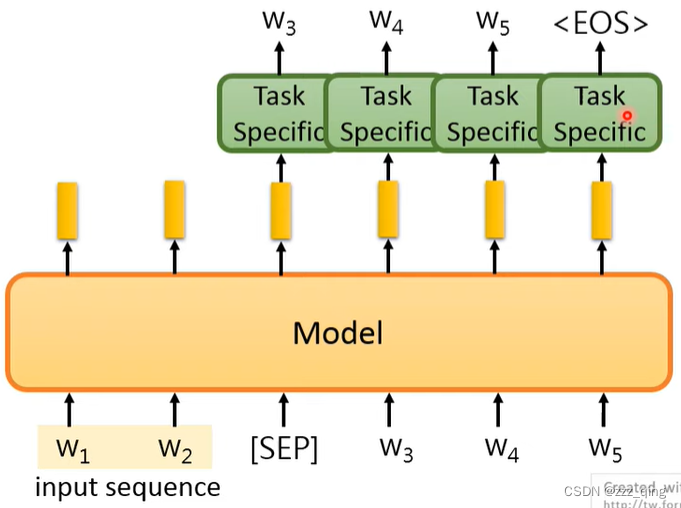
How to fine-tune:
有两种做法,第一种做法固定Pre-trained Model,只对Task Specific进行Fine-tune:
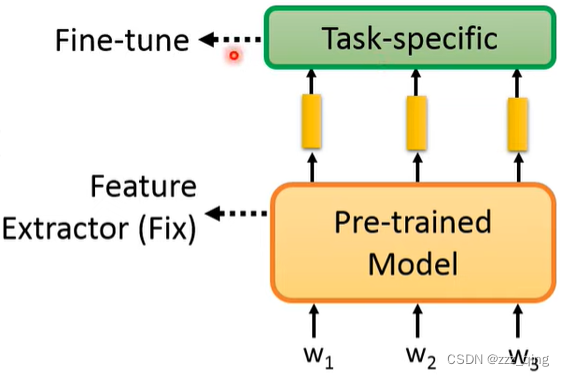
第二种做法把Pre-trained和Task Specific一起进行Fine-tune:
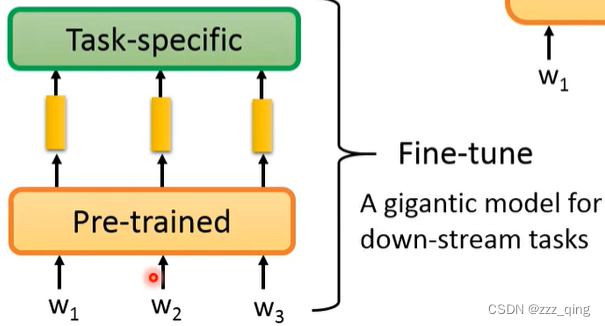
第二种做法的performance往往更好,但是第二种做法对每个Downstream Task都要储存一整个model,因为它们的Pre-trained model经过Fine-tune后都会变得不同。
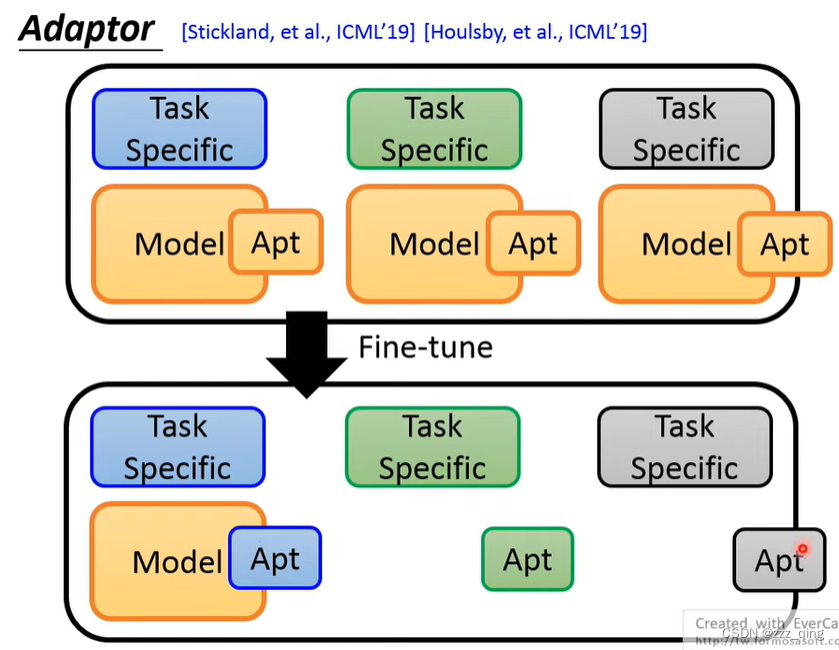
由此提出Adaptor,不对整个Pre-trained model进行Fine-tune,只对Pre-trained model中的一部分进行Fine-tune,那么储存model时,只需要储存Apt以及Task Specific部分,储存的参数量大大减少:
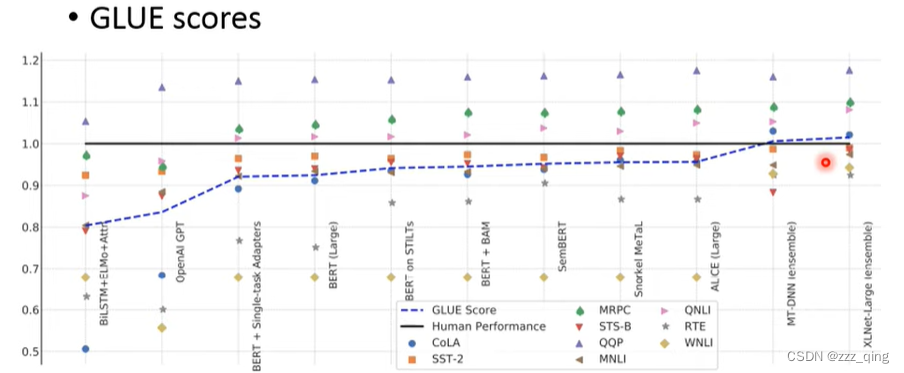
Why Pre-train Models:Pre-train Models真的很有用
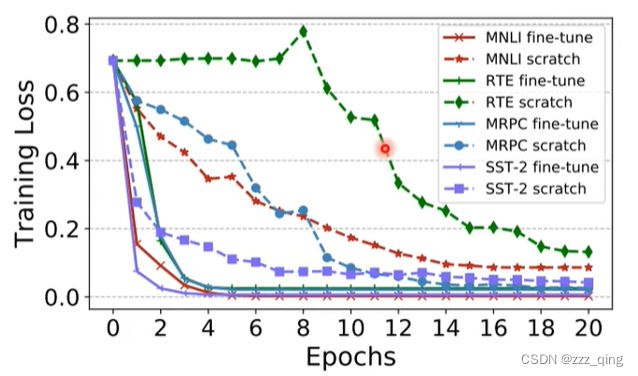
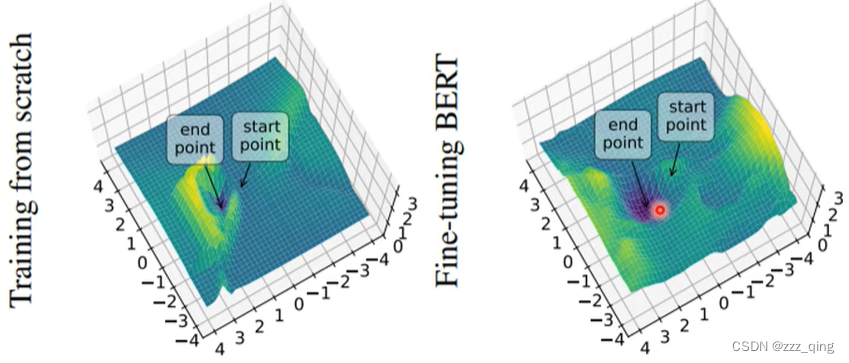
How to pre-train
Self-Supervised Learning
Self-Supervised Learning,又称为自监督学习。一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。
最早的Unsupervised pre-train的model都使用Predict Next Token这样的技术。如果Predict Next Token使用的是Self-attention的方法,要对Self-attention进行限制,使得当前token的输出不能看到右边输入的token的资讯:
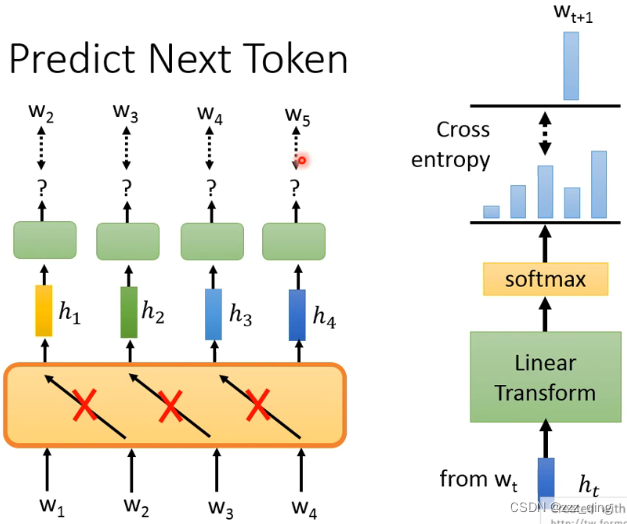
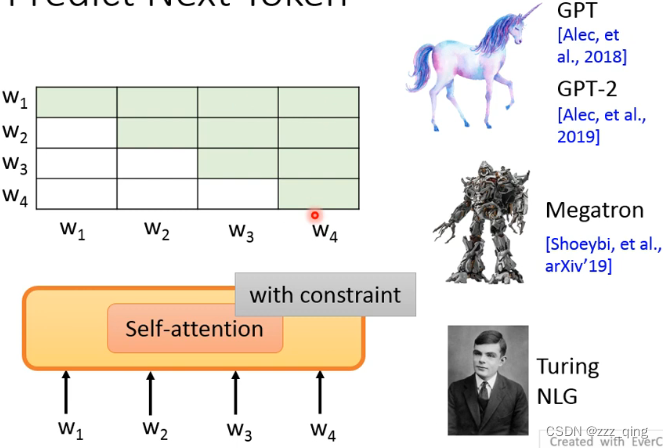
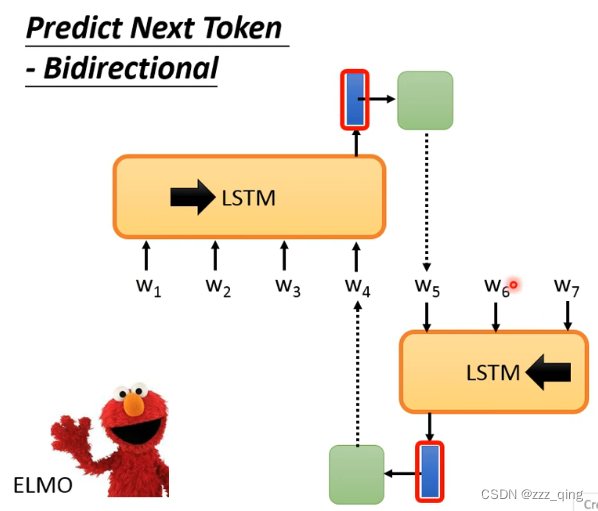
Predict Next Token通常只能看到左边的context的资讯,ELMO能看到左边和右边的资讯,但是不能同时看到完整的左边和右边的资讯,而BERT可以做到同时看整个context的资讯,它不再使用的Predict Next Token的技术。
BERT
BERT是一个Transformer的Encoder。
BERT训练的时候对输入的某些token进行Mask:
Randomly masking some tokens.
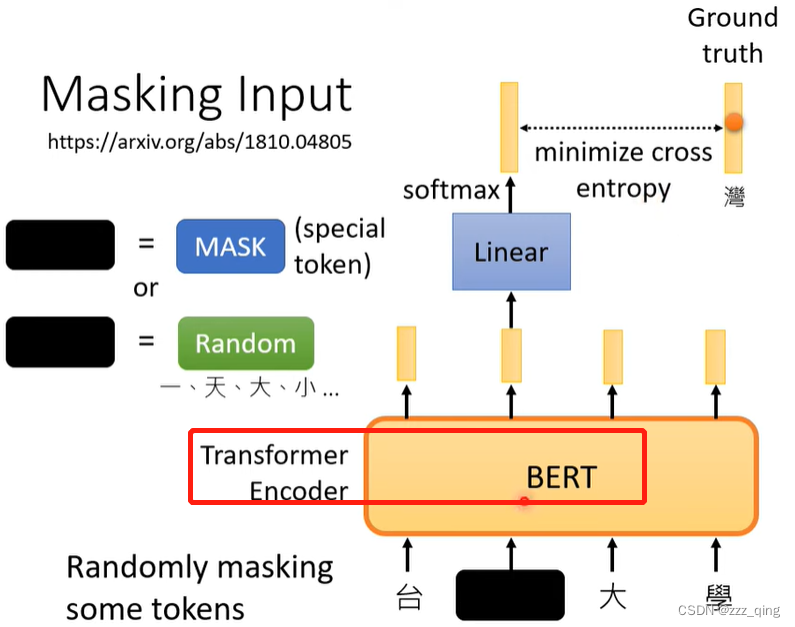
Masking Input的时候,有如下几种选择被Mask掉的token的方式:
① 原始的BERT中,要Mask掉的token是随机选择的
② Whole Word Masking(WWM):一次Mask一个whole word
③ Phrase-level & Entity-level:一次Mask好几个whole word
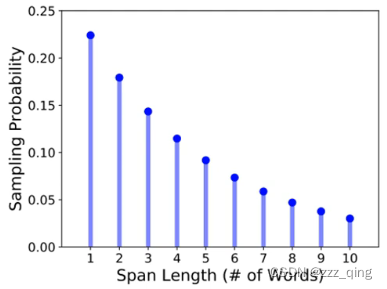
④ SpanBert:一次Mask掉一排token,token长度按下图几率分布
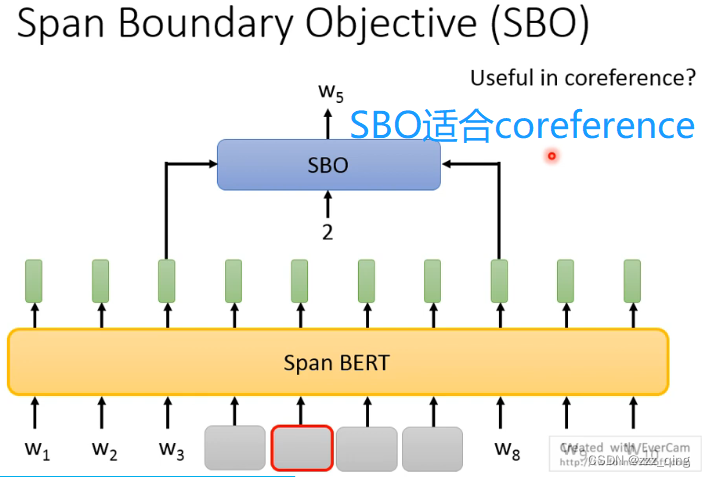
SpanBert还提出了一种训练的方法——SBO
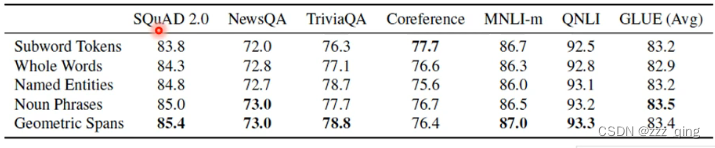
不同Mask的方法对比如下:
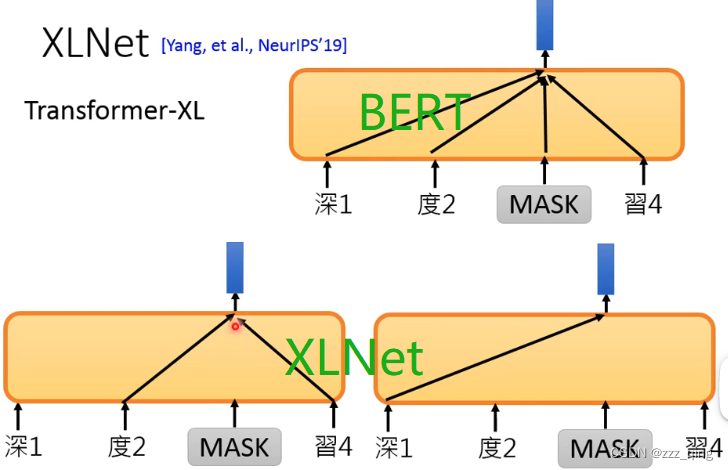
XLNet
XL指的是Transformer-XL,XLNet用的不是一般的Transformer,而是Transformer-XL。
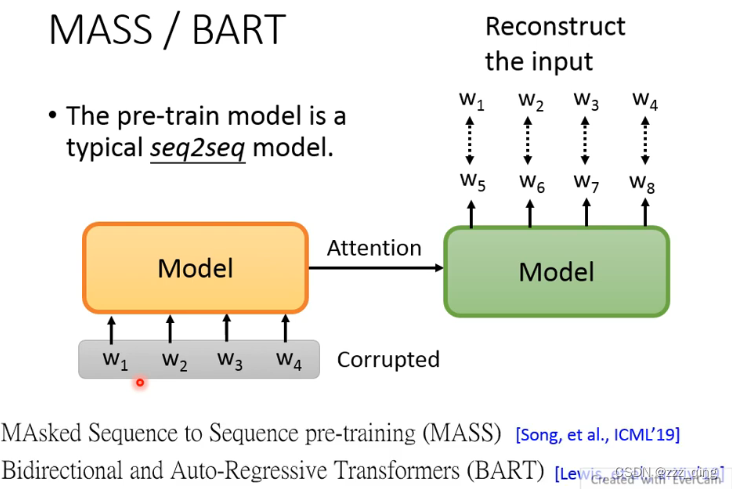
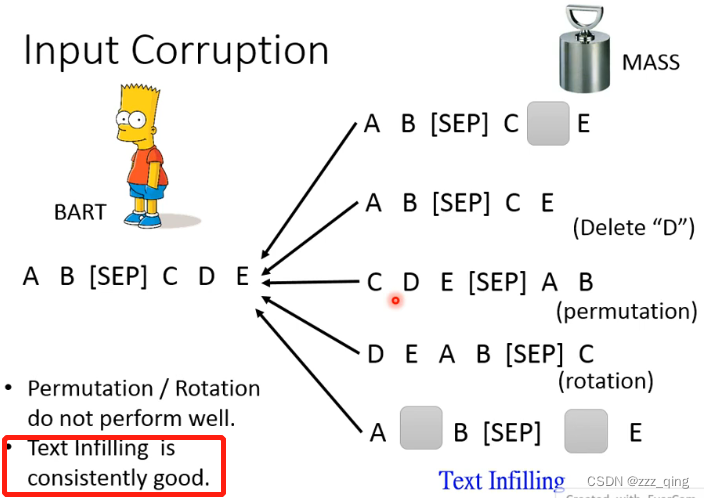
MASS / BART
BERT不擅长做generation的task(Limited to autoregressive model):
BERT训练的时候都是看一整个context,但是generation的task只能根据左边的context来生成输出的embedding,这和BERT的训练模式不太一样。
BERT不太适合用来做seq2seq的model,所以直接用self-supervised learning的方法pre-train一个seq2seq的model——MASS/BART:
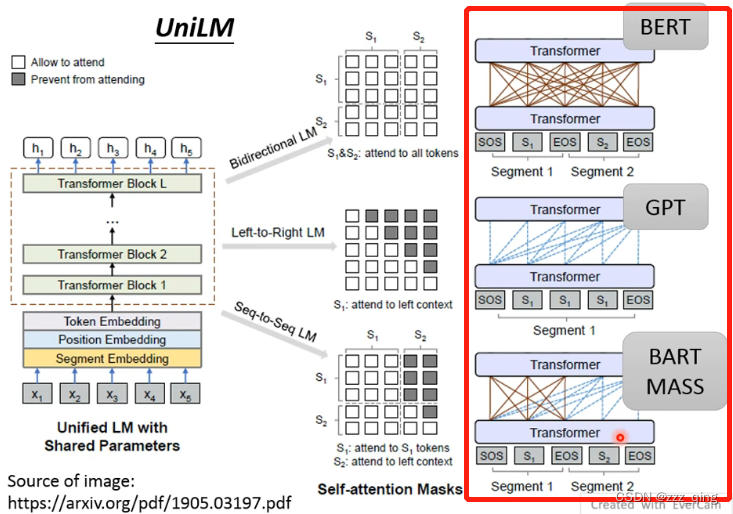
UniLM
UniLM是一个神奇的model,它既是encoder,也是decoder,也是encoder+decoder:
ELECTRA
——Efficiently Learning an Encoder that ClassifiesToken Replacements Accurately
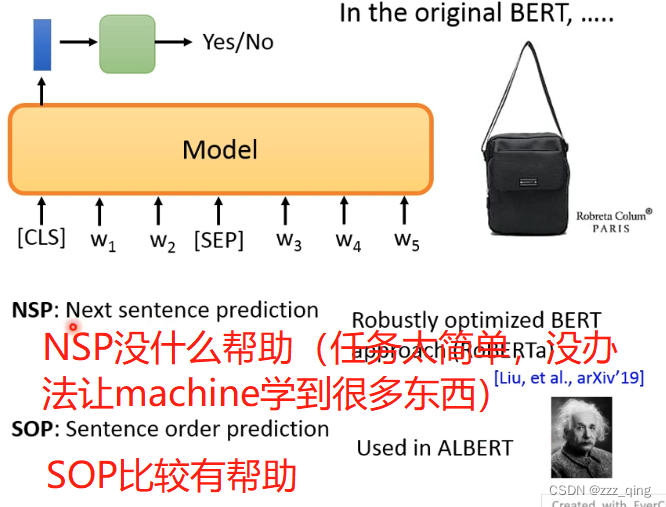
上面讲的pre-train的方法都是要预测一些失去的资讯,预测下一个token或预测被mask的部分。预测需要的运算量很大,所以ELECTRA这个方法避开了预测这件事情。
把输入中的一些token用意思相近的token进行替换,ELECTRA要做的任务就是判断输入的token是否被替换过:
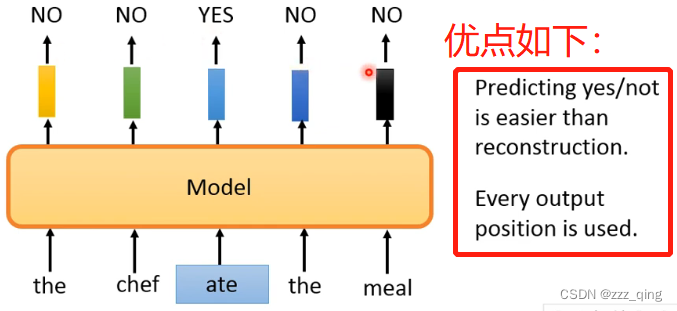
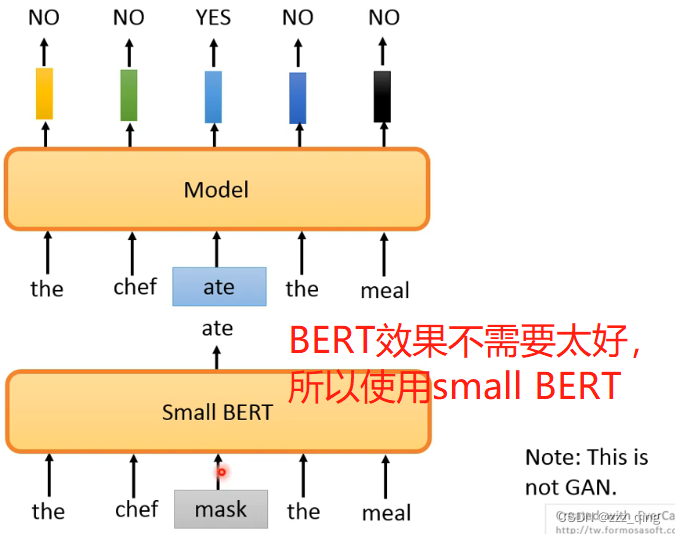
ELECTRA做的事情比预测简单,所以在同样等级的运算量下,训练的比别的模型更好:
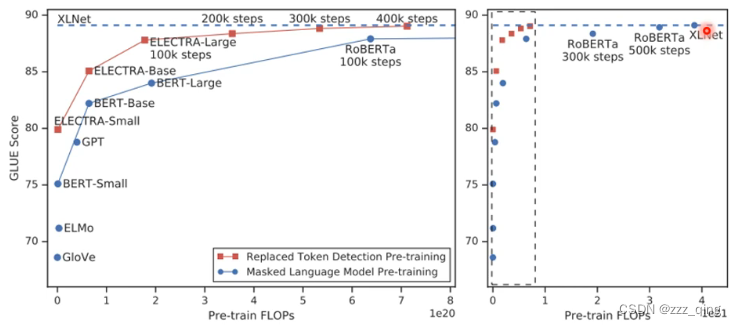
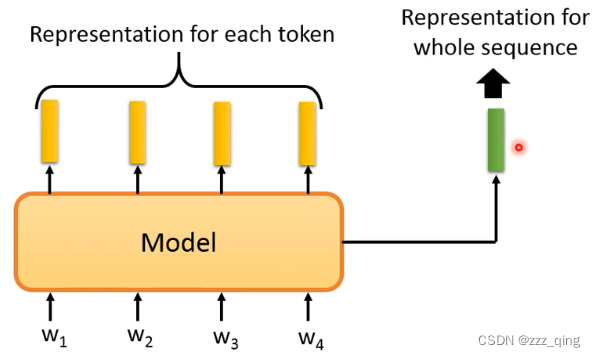
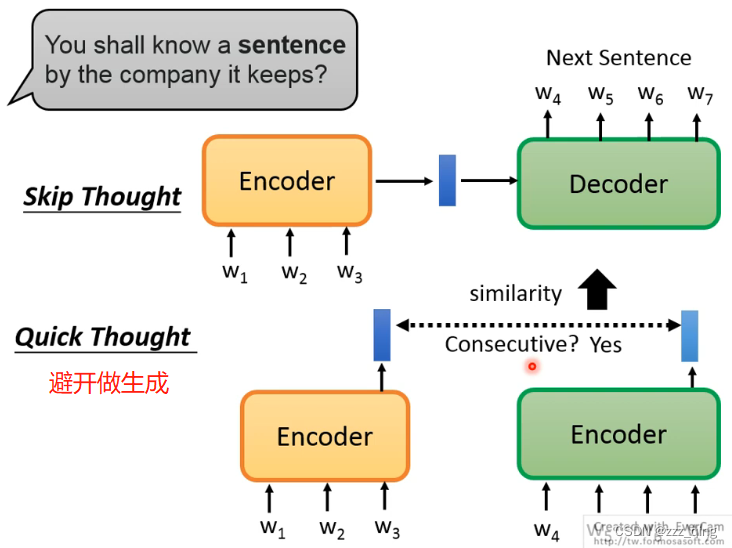
上面都是给input的每一个token生成一个embedding
如果给整个input的token sequence生成一个embedding:
GPT-3
GPT-3是一个非常巨大的model
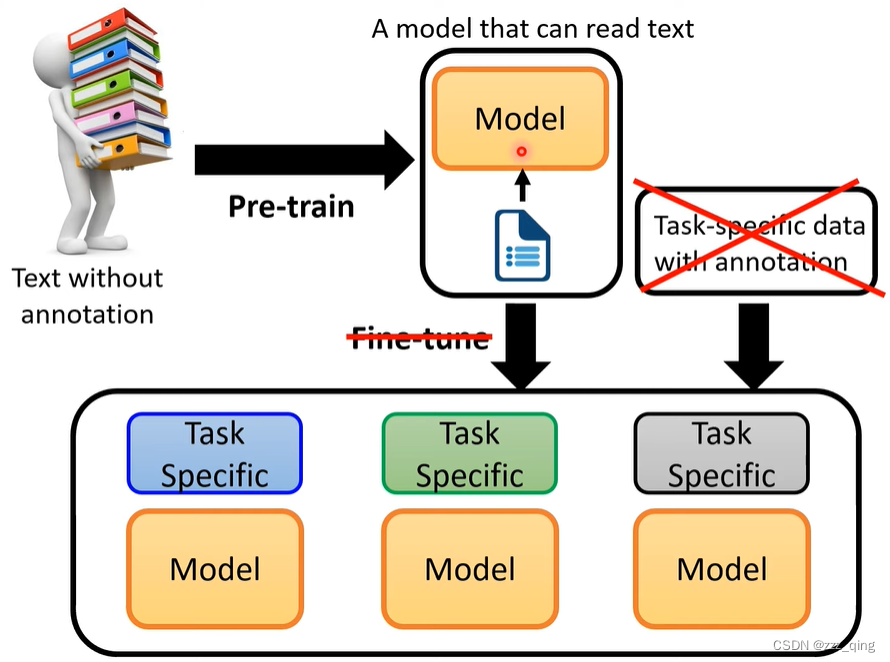
对于BERT这一类型的model,还是需要收集一些Downstream Task的资料才能让BERT学会解这些Downstream Tasks:
GPT系列想要做的work:zero-shot的learning
GPT系列想要直接Pre-train一个模型,不需要进行Fine-tune,就可以直接做Downstream Tasks。在下面第二张图中,Few-shot Learning和以往的Few-shot Learning是不同的,它的example是用来当做输入,而不是用于训练过程中去Fine-tune model。

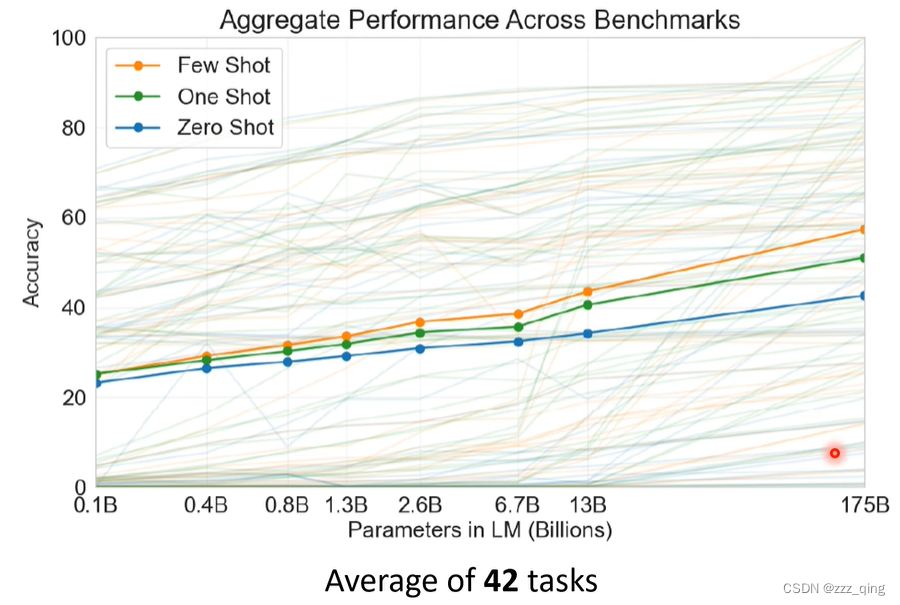
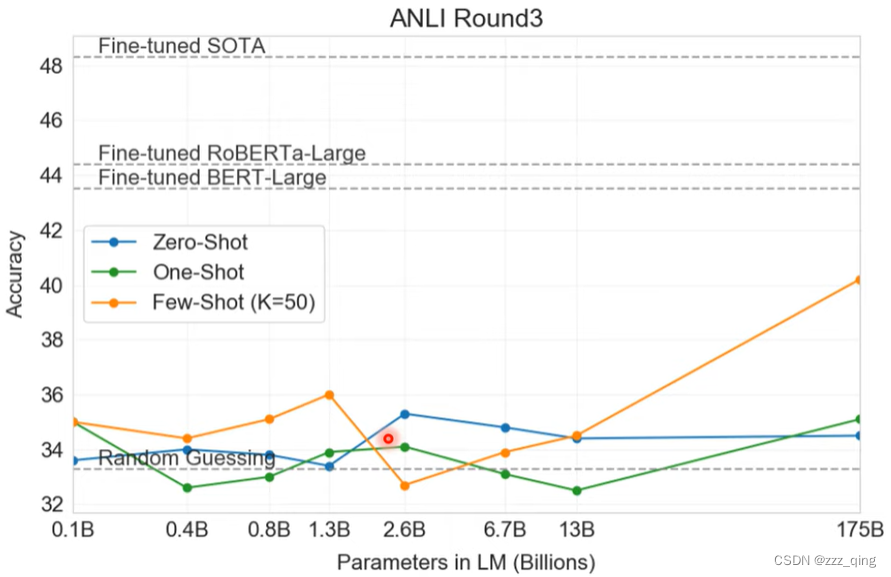
下图是GPT-3在不同大小的model上进行Few shot、One shot、Zero shot这三个任务的accuracy:
GPT-3的一些神奇之处:
① 可以做Closed Book QA
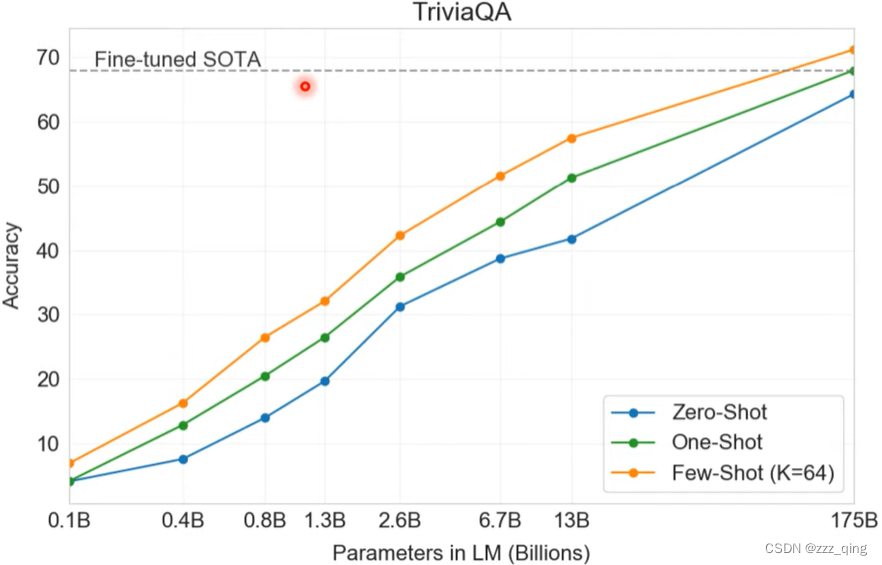
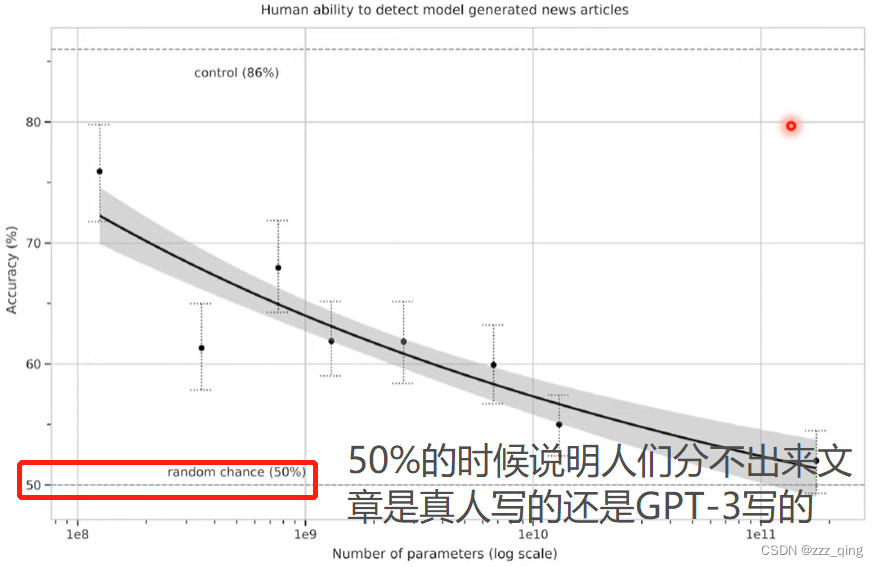
② 可以做generation
③ 可以造句
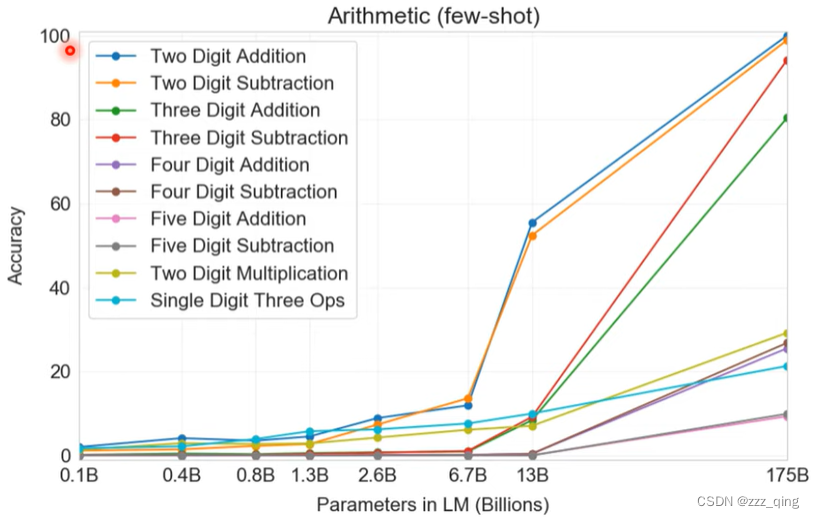
④ 学会做数学问题(掌握了两位数内的加减法)
GPT-3一些不work的地方:GPT-3做NLI问题(给出两个句子,让模型判断它们有没有矛盾)不太行















 4320
4320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









