







 本文深入探讨Logistic回归的梯度下降法,通过计算图阐述前向和反向传播过程,利用链式法则求导,并详细解释如何应用于m个样本的梯度下降,最终展示算法的编程实现流程。
本文深入探讨Logistic回归的梯度下降法,通过计算图阐述前向和反向传播过程,利用链式法则求导,并详细解释如何应用于m个样本的梯度下降,最终展示算法的编程实现流程。
计算图
可以说,一个神经网络的计算都是按照前向或者反向传播过程来实现的,首先计算出神经网络的输出,紧接着一个反向传播的操作。后者,我们用来计算出对应的梯度或者导数。这个流程图解释了为什么用这样的方式来实现。
我们举一个更为简单的函数为例,如何计算该函数。具体流程如下:
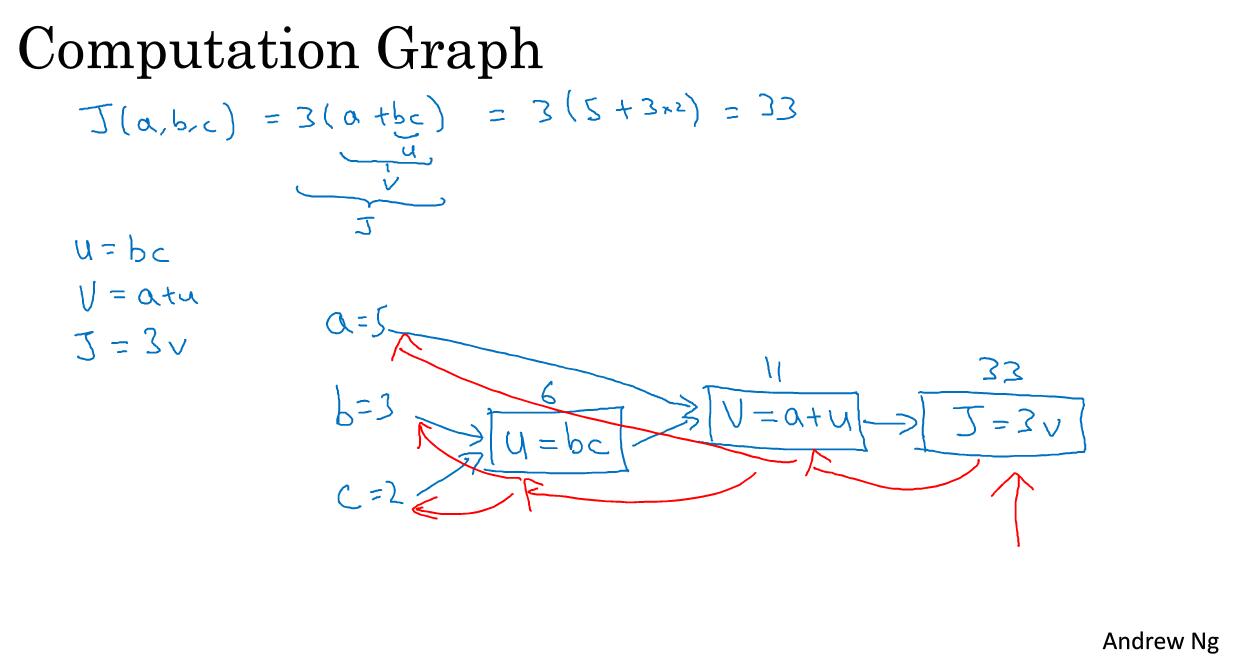
流程图是用蓝色箭头画出来的,从左到右的计算过程。那么红色箭头是从右到左的导数计算过程。
计算图的导数计算
反向传播算法的实质实际上就是用微积分的链式法则求导的过程。
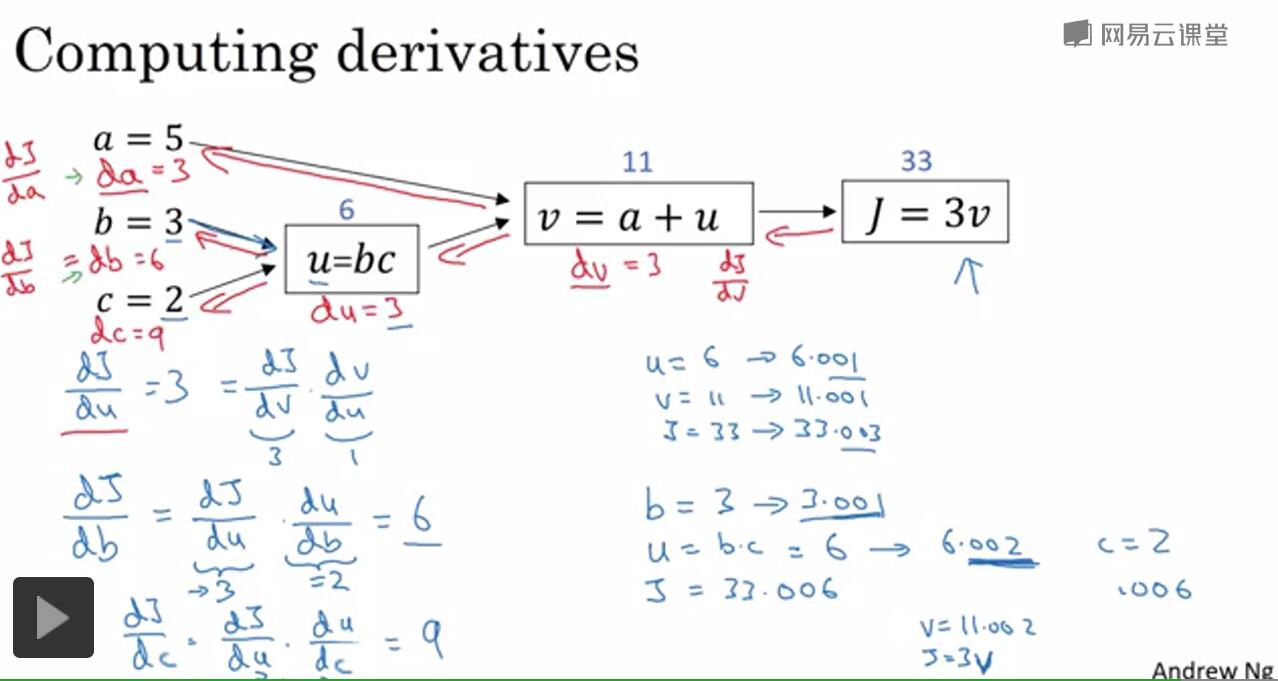
比如说我们算dJ/da的大小,就用链式法则反过来算一下。
logistic回归的梯度下降法
这一部分将介绍如何用导数流程图来计算梯度。
我们回忆一下逻辑回归公式,注意这里的a是预测值的意思等于y
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











