









自然语言处理方向的论文仿真到现在,有以下想法:
1. 很多模型都为启发式算法,从直观上很好理解,但是对于大多数人来说,就是一个黑盒,70%时间都在处理数据和调参。
2. 在数据竞赛中,常用的模型就是CNN和RNN,先调出baseline,然后再进行模型融合(model ensemble)。在以上步骤的约束下,数据竞赛比的就是设备的计算能力和个人的调参能力。
3. 在自然语言处理与NLP实战的一系列文章中,参考brightmart的项目分别介绍了CNN、RNN、charCnn、charRNN、RCNN、ATTENTION、Dynamic Memory Network、EntityNetwork等模型。前一段时间周围同学都在参加知乎“看山杯”数据竞赛,现在刚好可以拿来将所积累的知识用在实战中。
4. 该比赛在笔记本或者台式机上根本玩不转,理想的实验环境肯定要有GPU。实验室只有一台128G内存的服务器。对我个人而言,已经进入到研二,等待实验室购买GPU肯定不现实了,但还是想努力地在一些数据竞赛中取得成绩。
数据集
数据特征
- 数据经过脱敏处理,看到的不是“如何评价2017知乎看山杯机器学习比赛”,而是“w2w34w234w54w909w2343w1”这种经过映射的词的形式,或者是”c13c44c4c5642c782c934c02c2309c42c13c234c97c8425c98c4c340”这种经过映射的字的形式。
- 因为词和字经过脱敏处理,所以无法使用第三方的词向量,官方特地提供了预训练好的词向量,即char_embedding.txt和word_embedding.txt ,都是256 维。
- 主办方提供了1999个类别的描述和类别之间的父子关系(比如机器学习的父话题是人工智能,统计学和计算机科学),但这个知识没有用上。
- 训练集包含约300万条问题的标题(title),问题的描述(description)和问题的话题(topic)
- 测试集包含21万条问题的标题(title),问题的描述(description),需要给出最有可能的5个话题(topic)
数据分析
拿到数据以后,首先要对数据进行分析。采用深度学习模型,需要对句子进行截断和填充,这个就需要找到一个合适的长度。
对title的word组成char组成进行长度分析,如下图:
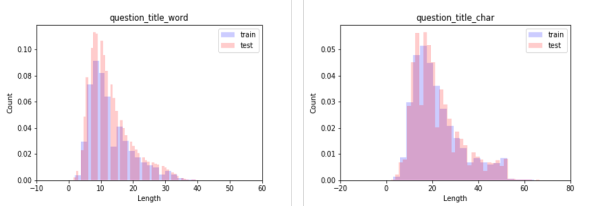
同理需要对content进行长度分析。综上,可以的到下表:
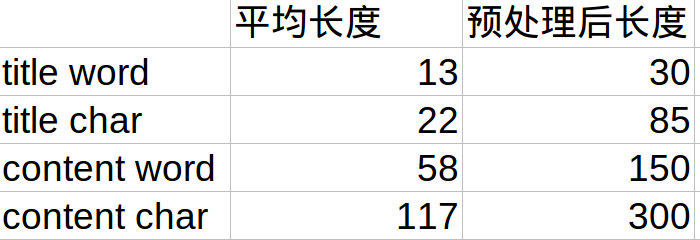
对数据进行预处理,即截断和补齐,长度大约为平均长度的两倍左右。另外,因为数据量很大,如果不能保证一次跑完整个预处理过程,最好还是需要将过程中需要的变量持久化,通过pickle进行保存。
数据处理
数据处理过程包括以下几步:
1. 得到word_embedding和char_embedding的变量,并保存成文件。源数据中给出的embedding的格式为:
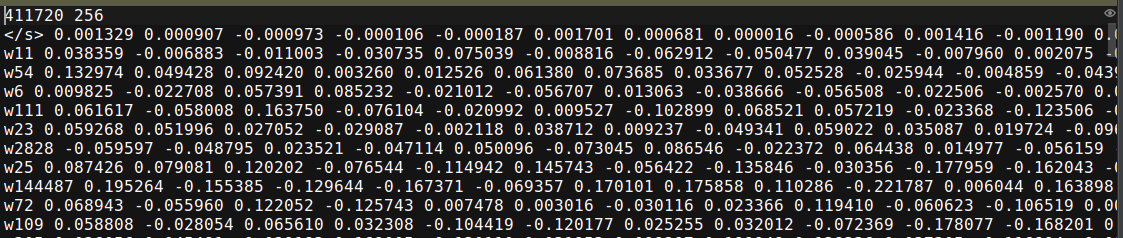
刚好是python中word2vec工具能处理的文件格式,所以通过:
wv = word2vec.load('../raw_data/word_embedding.txt')就能得到embedding变量,将数据持久化即可完成第一步。
2. 得到topic2id的变量。在数据处理中,pandas的Series非常好用。源文件中,每一个文本都对应着一个或多个topic,topic的总数为1999,也就是说总共包含1999类文本。将topic按出现频率从大到小进行排号,并保存在文件中。
3. 将title和content中的word或者char转换为对应的id。第一步我们得到word或者char转id的Series,第二步我们得到topic转id的Series,第三步我们就需要将问题的title和content中的word或者char转为id。这一步产生的中间变量会有大约4-5个G,所以需要在做项目之前就提前准备好至少100G的磁盘。
4. 将数据集分为train,valid和test,并进行打包存储。对于只有cpu的同学,训练一个epoch大约就需要一两天的时间,训练到理想效果可能七八天就过去了,所以最好还是将数据集都提前准备好,模型训练的时候直接进行提取。
注意:在对train数据进行处理时,对于没有content的数据,使用title进行填充。填充完以后没有title的数据就可以直接drop了。
对eval数据进行处理时,对于没有content的数据,使用title进行填充。对于没有title的数据,使用content进行填充。确保每一个最终提交的eval,都会有结果。
模型
1. FastText
fastText 是 word2vec 作者 Mikolov 转战 Facebook 后16年7月刚发表的一篇论文 Bag of Tricks for Efficient Text Classification。fastText极致简单,和word2vec中的CBOW模型思路很像,模型图见下:
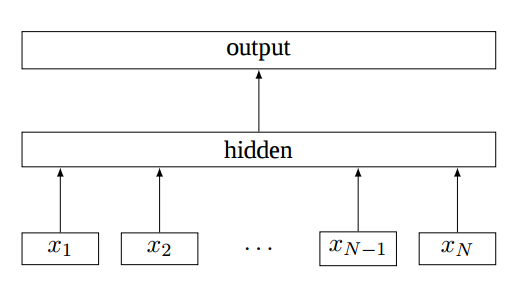
原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。文章倒没太多信息量,算是“水文”吧,带来的思考是文本分类问题是有一些“线性”问题的部分,也就是说不必做过多的非线性转换、特征组合即可捕获很多分类信息,因此有些任务即便简单的模型便可以搞定了。
2. TextCNN
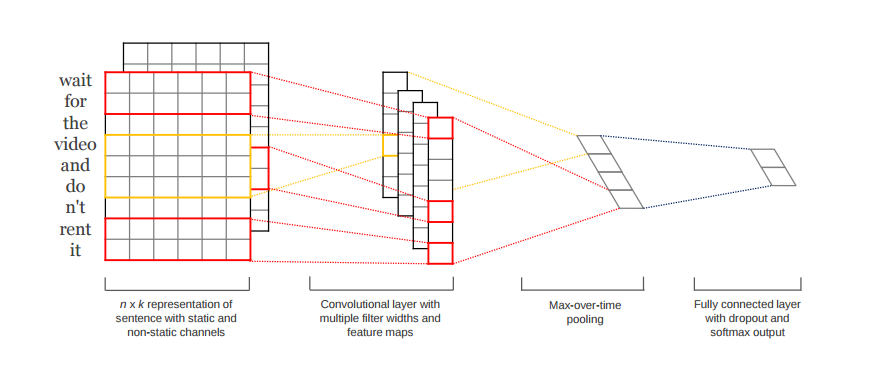
TextCNN的开篇之作是Convolutional Neural Networks for Sentence Classification,在github上实现代码。该代码符合tensorflow的编程规范,是入门自然语言处理与NLP很好的切入点。
14年的这篇文章提出TextCNN的结构如下图。fastText 中的网络结果是完全没有考虑词序信息的,而TextCNN用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络(CNN Convolutional Neural Network)最初在图像领域取得了巨大成功,CNN原理就不讲了,核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
3. TextRNN
TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。具体在文本分类任务中,Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 “n-gram” 信息。
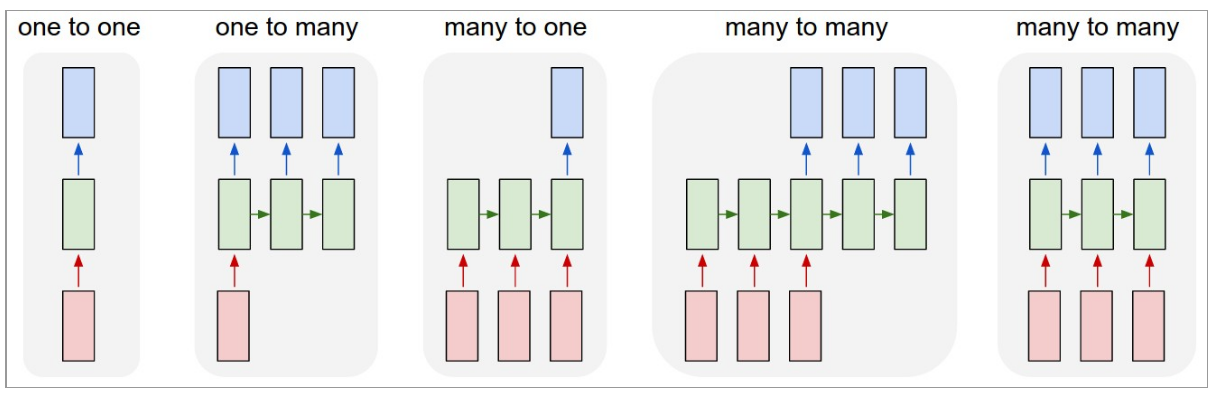
RNN算是在自然语言处理领域非常一个标配网络了,在序列标注/命名体识别/seq2seq模型等很多场景都有应用,Recurrent Neural Network for Text Classification with Multi-Task Learning文中介绍了RNN用于分类问题的设计。RNN(LSTM)在自然语言处理方向有多种结构,常用的如The Unreasonable Effectiveness of Recurrent Neural Networks中提到的下图。可以讲RNN的output直接再加一个隐层作为分类输出即可。
4. char-rnn和char-cnn
和RNN、CNN类似,只不过是基于字符级的embedding,具体讲解和实现可参照:
基于字符的卷积神经网络实现文本分类(char-level CNN)-论文详解及tensorflow实现
基于循环神经网络实现基于字符的语言模型(char-level RNN Language Model)-tensorflow实现
5. RCNN
RCNN最早由 Recurrent Convolutional Neural Networks for Text Classification论文提出,模型结构如图所示:
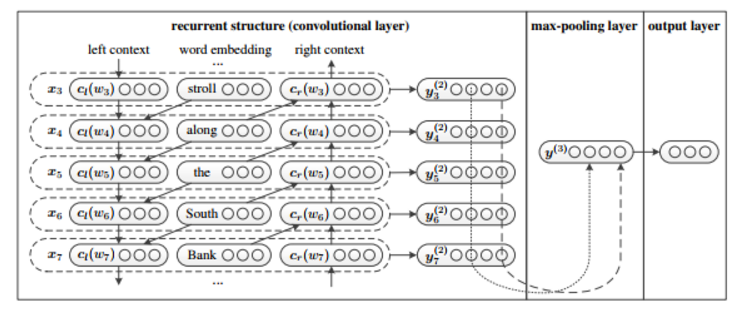
CNN的缺点刚才提到,是固定的filter_size。在文本表示方面,会有超过filter_size的上下文的语义缺失,因此本篇文章利用RNN来进行文本表示,中心词左侧和右侧的词设为trainable,然后将中心词左侧和右侧的词concat作为中心词的表示。
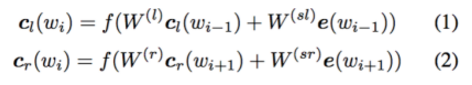
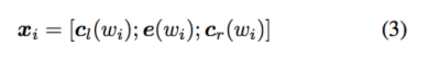
文本表示以后,通过一个隐层,然后再通过max-pooling层提取出重要的words,然后通过output层得到输出。论文中提到该模型能够提升文本分类的准确率,然而在实战中该模型对最终结果提升不高,并且耗时比CNN要长。
6. Hierarchical Attention Network
原论文为Hierarchical Attention Networks for Document Classification。模型结构如下图,框架可以分为四层,从下到上依次为:word encoder,word attention, sentence encoder, sentence attention。 Attention机制可以直观的解释出每个word对sentence或者sentence对document的重要性。详细的代码实现可以参照Implementation of Hierarchical Attention Networks for Document Classification的讲解与Tensorflow实现。
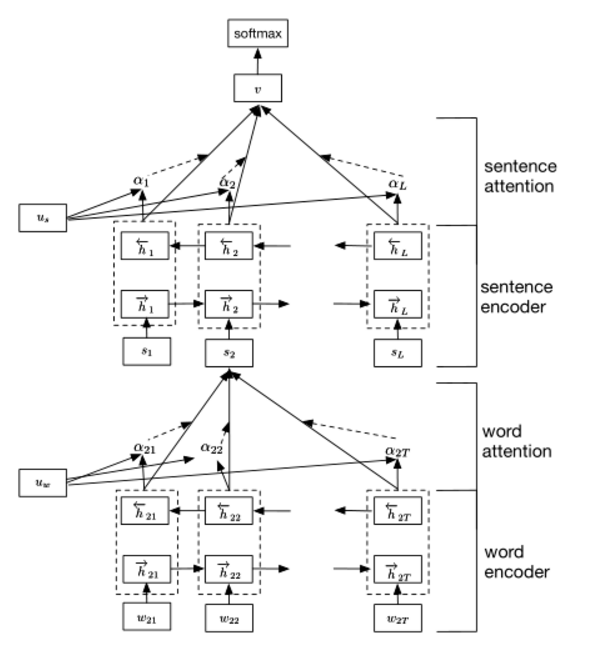
7. Dynamic Memory Network
[Ask Me Anything: Dynamic Memory Networks for Natural Language Processing] (https://arxiv.org/pdf/1506.07285.pdf)是DMN(Dynamic Memory Networks)的开端,在很多任务上都实现了state-of-the-art的结果,如:question answering (Facebook’s bAbI dataset), text classification for sentiment analysis (Stanford Sentiment Treebank) and sequence modeling for part-of-speech tagging (WSJ-PTB)。在github上有具体的代码实现。模型结构如下图所示,具体理解和代码实现参照Ask Me Anything: Dynamic Memory Networks for Natural Language Processing 阅读笔记及tensorflow实现。
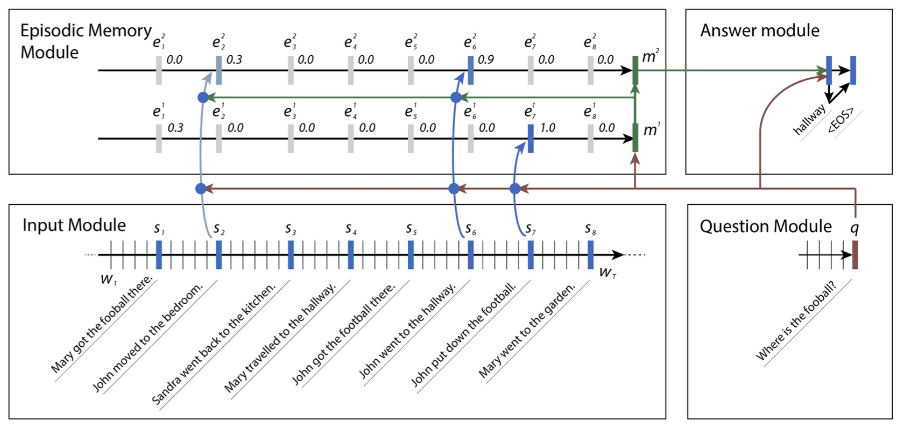
8. EntityNetwork: tracking state of the world
EntityNetwork由论文TRACKING THE WORLD STATE WITH RECURRENT ENTITY NETWORKS提出,发表于2017年ICLR。对比Dynamic Memory Network,该论文在babi数据集取得了更优秀的成绩,具体对比可参考论文。模型图如下:
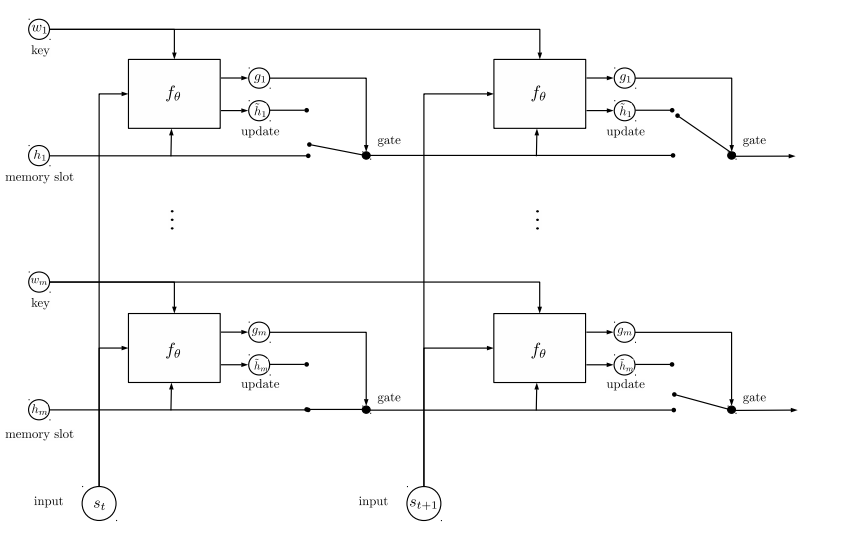
如果熟悉RNN或者GRU,就会发现该模型的框架和多层GRU模型相同,不同的只是GRUcell的公式不同,因此需要在dynamic_rnn函数之前,自行修改GRU_cell。所以文章本身可将的点不多,具体代码可参照entity-network。
模型融合
模型用时和score的对比结果参考brighmart的github:

无论什么样的数据比赛,模型融合都是比赛获胜的关键。在这里,第一名使用到了最简单的模型融合方法—–概率等权重融合。对于每个样本,单模型会给出一个1999维的向量,代表着这个模型属于1999个话题的概率。融合的方式就是把每一个模型输出的向量直接相加,然后选择概率最大的5个话题提交。
另外基于字符的模型虽然训练效果不如基于词的模型,但对于最后的模型效果提升效果很好,所以不能单独使用word而不使用char。
trick
模型显然并不是最重要的:不能否认,好的模型设计对拿到好结果的至关重要,也更是学术关注热点。但实际使用中,模型的工作量占的时间其实相对比较少。虽然再第二部分介绍了5种CNN/RNN及其变体的模型,实际中文本分类任务单纯用CNN已经足以取得很不错的结果了,我们的实验测试RCNN对准确率提升大约1%,并不是十分的显著。最佳实践是先用TextCNN模型把整体任务效果调试到最好,再尝试改进模型。
理解你的数据:虽然应用深度学习有一个很大的优势是不再需要繁琐低效的人工特征工程,然而如果你只是把他当做一个黑盒,难免会经常怀疑人生。一定要理解你的数据,记住无论传统方法还是深度学习方法,数据 sense 始终非常重要。要重视 badcase 分析,明白你的数据是否适合,为什么对为什么错。
关注迭代质量 - 记录和分析你的每次实验:迭代速度是决定算法项目成败的关键,学过概率的同学都很容易认同。而算法项目重要的不只是迭代速度,一定要关注迭代质量。如果你没有搭建一个快速实验分析的套路,迭代速度再快也只会替你公司心疼宝贵的计算资源。建议记录每次实验,实验分析至少回答这三个问题:为什么要实验?结论是什么?下一步怎么实验?
超参调节:超参调节是各位调参工程师的日常了,推荐一篇文本分类实践的论文 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,里面贴了一些超参的对比实验,如果你刚开始启动文本分析任务,不妨按文章的结果设置超参,怎么最快的得到超参调节其实是一个非常重要的问题,可以读读 萧瑟的这篇文章 深度学习网络调参技巧 - 知乎专栏。
一定要用 dropout:有两种情况可以不用:数据量特别小,或者你用了更好的正则方法,比如bn。实际中我们尝试了不同参数的dropout,最好的还是0.5,所以如果你的计算资源很有限,默认0.5是一个很好的选择。
fine-tuning 是必选的:上文聊到了,如果只是使用word2vec训练的词向量作为特征表示,我赌你一定会损失很大的效果。
未必一定要 softmax loss: 这取决与你的数据,如果你的任务是多个类别间非互斥,可以试试着训练多个二分类器,也就是把问题定义为multi lable 而非 multi class,我们调整后准确率还是增加了>1%。
类目不均衡问题:基本是一个在很多场景都验证过的结论:如果你的loss被一部分类别dominate,对总体而言大多是负向的。建议可以尝试类似 booststrap 方法调整 loss 中样本权重方式解决。
避免训练震荡:默认一定要增加随机采样因素尽可能使得数据分布iid,默认shuffle机制能使得训练结果更稳定。如果训练模型仍然很震荡,可以考虑调整学习率或 mini_batch_size。
最后,感谢北邮这些学长在文本分类领域做出的分享。














 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









