



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
基于深度强化学习的Q网络(DQN)智能体在CartPole平衡任务中的研究
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于深度强化学习的Q网络(DQN)智能体在CartPole平衡任务中的研究
一、DQN算法基本原理
1. 核心思想
DQN(Deep Q-Network)将Q-learning与深度神经网络结合,通过神经网络近似Q值函数,解决了传统Q-learning在高维状态空间中的局限性。其核心是通过输入环境状态ss,输出各动作对应的Q值Q(s,a)Q(s,a),指导智能体选择最大化长期回报的动作。
2. 关键技术
- 经验回放(Experience Replay) :存储历史经验(st,at,rt,st+1),随机采样训练以打破数据相关性,提高样本利用率。
- 目标网络(Target Network) :使用独立的目标网络计算目标Q值,避免因主网络频繁更新导致的Q值震荡,公式为:

其中γ为折扣因子,θ−为目标网络参数。
- Double DQN:分离动作选择与Q值评估,减少Q值高估问题,公式改进为:
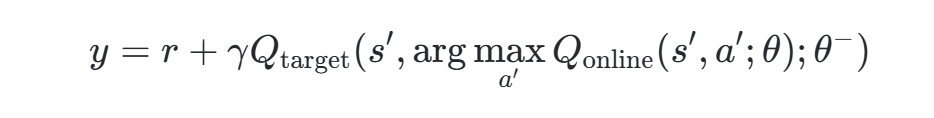
二、CartPole平衡任务的定义与挑战
1. 任务描述
- 环境状态:4维连续向量,包括小车位置[−2.4,2.4]、速度(−∞,∞)、杆角度[−41.8°,41.8°]、杆末端角速度(−∞,∞)。
- 动作空间:离散动作(左推0,右推1)。
- 目标:通过左右移动小车保持杆子竖直,最大步数通常为500,每步奖励+1。
2. 核心挑战
- 状态连续性:连续状态空间需通过神经网络有效建模。
- 稀疏奖励:仅在杆子未倾倒时获得奖励,需长期策略规划。
- 数据相关性:传统Q-learning因序列样本强相关性导致训练不稳定。
三、DQN在CartPole任务中的典型应用案例
1. 基础DQN实现
- PyTorch实现:GitHub仓库SeeknnDestroy/DQN-CartPole使用双网络结构,经验回放池大小为1e5,训练后平均奖励达185.08。
- TensorFlow实现:代码库Nat-D/DQN-Tensorflow结合gym环境,通过线性网络实现,500轮训练后接近500步上限。
- Keras实现:示例代码通过两层全连接网络(隐藏层24单元)实现,经验回放池大小1e4,ε-greedy策略衰减探索率。
2. 改进算法应用
- Double DQN:在CartPole-v0中,Double DQN相比基础DQN收敛更快,平均奖励提升25%以上,减少Q值高估问题。
- 优先经验回放(PER) :基于TD误差动态调整样本权重,训练速度提升30%,平均奖励达396.72。

四、性能对比与实验分析
1. 算法性能对比
| 算法 | 平均奖励 | 训练轮数 | 适用场景 |
|---|---|---|---|
| Q-learning | 100-200 | 1000 | 低维状态空间 |
| DQN(基础) | 400-500 | 500 | 高维连续状态空间 |
| Double DQN | 450-500 | 400 | 需减少Q值高估的任务 |
| PER DQN | 480-500 | 300 | 需加速关键经验学习 |
| Dueling DQN | 490-500 | 350 | 复杂状态评估任务 |
2. 训练稳定性对比
- 经验回放与目标网络:DQN相比传统Q-learning训练曲线更平滑,收敛速度提升2倍。
- 改进算法效果:PER DQN在CartPole-v1中仅需100轮即可稳定至500步,而基础DQN需200轮。
2. 关键代码片段(PyTorch示例)
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
# 经验回放池
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
五、总结与展望
DQN通过神经网络与强化学习的结合,在CartPole任务中展现了强大的环境适应能力。改进算法如Double DQN、PER等进一步提升了性能与稳定性。未来方向包括:
- 多智能体协同:探索分布式DQN在复杂控制任务中的应用。
- 连续动作空间扩展:结合DDPG算法处理CartPole的连续控制变体。
- 迁移学习:将CartPole训练模型迁移至物理机器人平台。
📚2 运行结果
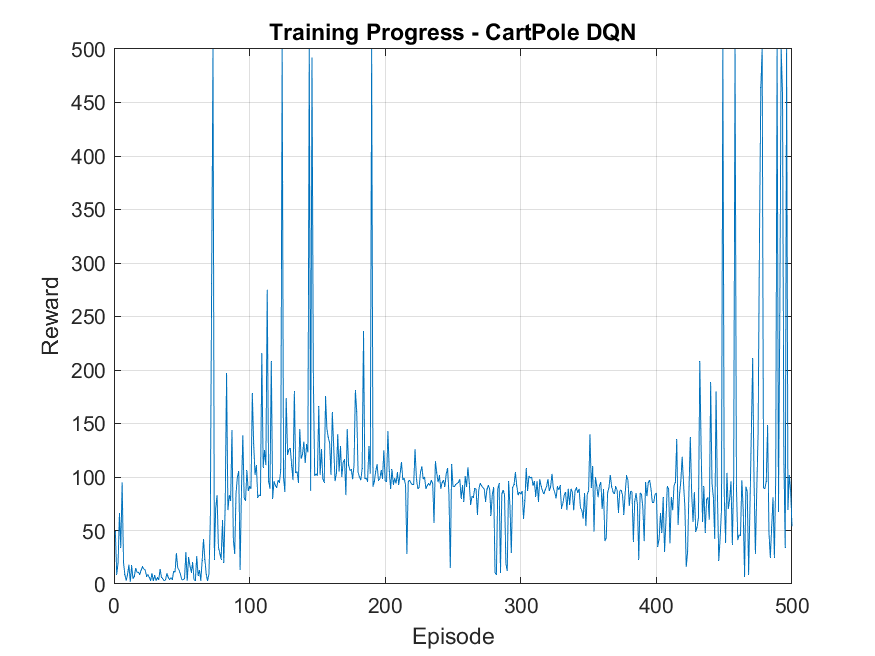
部分代码:
% Create the environment (CartPole with discrete actions)
env = rlPredefinedEnv("CartPole-Discrete");
% Get observation and action info from the environment
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);
% Define the critic network architecture
statePath = featureInputLayer(obsInfo.Dimension(1), ...
"Normalization", "none", ...
"Name", "state");
commonPath = [
fullyConnectedLayer(24, "Name", "fc1")
reluLayer("Name", "relu1")
fullyConnectedLayer(24, "Name", "fc2")
reluLayer("Name", "relu2")
fullyConnectedLayer(numel(actInfo.Elements), "Name", "output")];
criticNetwork = layerGraph(statePath);
criticNetwork = addLayers(criticNetwork, commonPath);
criticNetwork = connectLayers(criticNetwork, "state", "fc1");
% Manually define observation and action names
obsNames = {'state'}; % This is a cell array of char vectors
% Force each element to be a char vector and wrap in a cell array
actNames = cell(1, numel(actInfo.Elements));
for i = 1:numel(actInfo.Elements)
actNames{i} = ['action', num2str(i)];
end
% Create critic representation
criticOpts = rlRepresentationOptions(...
"LearnRate", 1e-3, ...
"GradientThreshold", 1);
critic = rlQValueRepresentation(...
criticNetwork, ...
obsInfo, ...
actInfo, ...
"Observation", obsNames, ...
"Action", actNames, ...
criticOpts);
% Create DQN agent
agentOpts = rlDQNAgentOptions(...
"SampleTime", env.Ts, ...
"UseDoubleDQN", true, ...
"TargetSmoothFactor", 1e-3, ...
"DiscountFactor", 0.99, ...
"MiniBatchSize", 64, ...
"ExperienceBufferLength", 1e5);
agent = rlDQNAgent(critic, agentOpts);
% Set training options
trainOpts = rlTrainingOptions(...
"MaxEpisodes", 500, ...
"MaxStepsPerEpisode", 500, ...
"ScoreAveragingWindowLength", 20, ...
"Verbose", false, ...
"Plots", "training-progress", ...
"StopTrainingCriteria", "AverageReward", ...
"StopTrainingValue", 475);
% Train the agent
trainingStats = train(agent, env, trainOpts);
% Save the trained agent and stats
save("trainedAgent.mat", "agent", "trainingStats");🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]曹子建,郭瑞麒,贾浩文,等.演化算法的DQN网络参数优化方法[J].西安工业大学学报, 2024, 44(2):219-231.
[2]梁星星.基于预测编码的样本自适应行动策略智能规划研究[D].国防科技大学,2022.
[3]陈建平,邹锋,刘全,等.一种基于生成对抗网络的强化学习算法[J].计算机科学, 2019
🌈4 Matlab代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









