







1 自编码神经网络
所谓自编码神经网络,就是如下图的神经网络
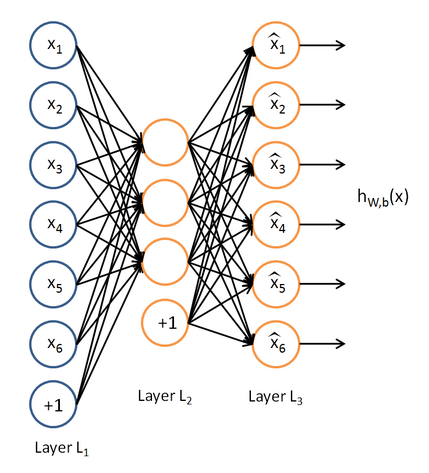
简单来说,输入输出都尽量是同样的输入值,但是其中的隐含层要尽量的少
其中不需要labels也就是无监督学习
其中的意义是:
将很多输入的特征,转化为很少的隐含层,然后这少量的隐含层还能转化为原来的样子,其中得到的隐含层是最重要的,他抓住了输入特征的本质,像这样简单的神经网络,其效果类似与主成分分析法得到的结果。
2 稀疏性
上面说了隐含层节点很少,上图中我们设置的节点为3,可是能不能不用手动设置神经网络的结构,即使隐含层数量很多也可以起到这样的效果呢?
我们的方法就是,通过添加限制,使众多的神经元中只有一部分在同时工作,或者使一个神经元在大多数时候都处于休眠状态。(棒棒哒)
怎么才能达到这个效果呢
以sigmoid函数为例
我们知道一般在被激活时,其输出值应该趋近于1
如果有多个输入未被激活,此时的输出值接近于0
精彩的地方:
先计算样本的输入之后某一个隐含层神经单元的输出
a(2)j
(激活时此值接近1,未被激活时接近0),所有的样本对应的该值相加得到了和,求平均值
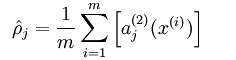
如果这个平均值接近于0,说明,只有很少的样本能让这个神经元工作

完美!
这样的限制就叫做稀疏性限制
如果让
ρ^j=ρ
,比如
ρ=0.05
,这时
ρ
叫做稀疏性参数
问题又来了,如何让
ρ^j=ρ
呢
还记得神经网络的损失函数么?
如果当
ρ^j≠ρ
时损失函数非常大,就可以了。
这里引入了一个可以使
ρ^j=ρ
的约束:相对熵,如果两个数不一样,或者说相差很大的时候,他会变的非常大,趋向于无穷
他的公式是这样的
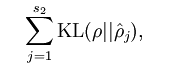
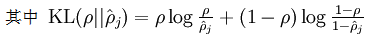
s2代表隐含层单元数量
可以不用纠结这是怎么来的,知道它的作用就可以了
这是它的图像
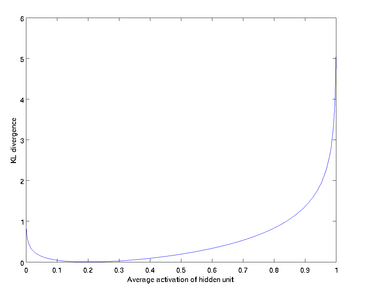
设
ρ=0.2
可以看到,在
ρ^j≠0.2
时会KL逐渐变得非常大
好了稀疏性的问题也愉快的解决了
这是的总体的损失函数成了这个样子
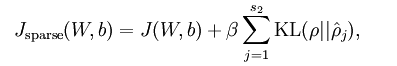
注意到上面的
ρ
的计算也用到了
aj
也就是需要利用W,b来计算
另外
β
是稀疏性的惩罚因子,越大,越稀
还有一个问题没有解决噢
如果要用反向传递算法计算,还需要知道现在反向传递的参数
改变之后只需要将
δ
改变就好
他变成了这个样子
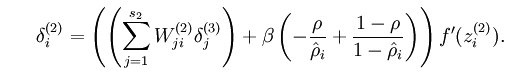
现在就可以利用反向传递算法来计算中间的隐含层的函数了,它是抓住了输入主要特征的,知道它就知道了主要的特征,这样在分类或者其他处理就简单了!
















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









