






 本文探讨图像分类面临的挑战,如视角、比例变化等,并介绍数据驱动方法解决这些问题。重点讲解kNN分类器的工作原理及其在实际中的应用流程。
本文探讨图像分类面临的挑战,如视角、比例变化等,并介绍数据驱动方法解决这些问题。重点讲解kNN分类器的工作原理及其在实际中的应用流程。
本导论主要介绍了图像分类问题及数据驱动方法。
图像分类问题 image classification
图像的分类问题简单来说就是对选择一个给定label的过程。如下图:
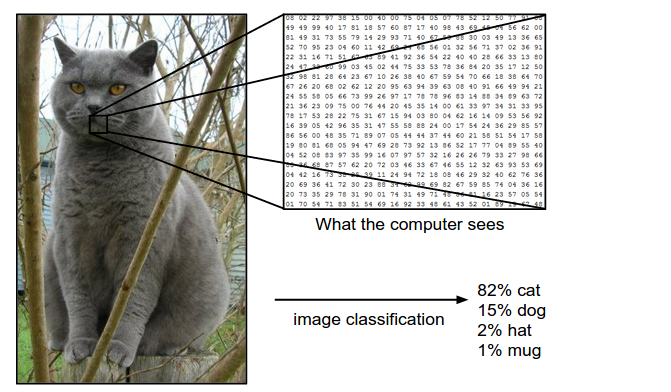
此图片为248×400像素的图片,对电脑来说他是一个248 x 400 x 3的3维数组,其中的3代表红绿蓝三色通道(这里文中默认是使用RGB格式),假设我们设定,这幅图片的label有四种可能,cat、dog、hat、mug,对他的分类就是通过这248 x 400 x 3=297,600个数字得出其中的一个标签比如cat。这与其他分类过程是相似的。
分类的挑战性
但是与机器学习中其他的分类问题不同是,图像分类还有许多的挑战,主要表现在以下几部分:
1. 视角的变化viewpoint variation,同一个物体在不同的视角下会有不同的表现,而视角的变化可以说是无穷多的。
2. 比例的变化scale variation ,比如同样是一个字,四号字体,和一号字体他们对应的比例是不同的。
3. 变形deformation,很多物体并非刚性,往往在不同时刻有不一样的展现形式,比如站着的人与坐着的人都是一个人,但是形状已经变了。
4. 遮挡occulsion,现实中的图片往往不是以此排列展开的,彼此遮挡的时候很多.
5. 光照变化 illumination condations,光照的角度不同往往会造成图片中物体的数值形式的差异。
6. 背景的影响 background clutter. 有时候图片的背景与目标物体很接近不易分辨,比如变色龙.
7. 概念的复杂性 intra-class variation,一个概念下往往会对应不同的物体,比如label为car的图片可能包含各种各样的汽车。
下图是上面概念的展示:
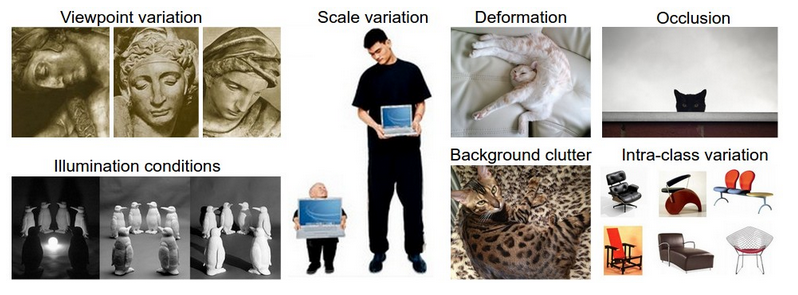
显示中这些不定的变化往往会同时出现,造成了识别的困难,一个比较好的分类法方法应该对上面面临的变化有一定的鲁棒性。
数据驱动方法
学过机器学习的对于这个概念应该比较容易理解,我们不会直接告诉电脑如何去分类,(其实我们也不知道如何写一段程序直接告诉电脑该如何对图片进行分类)我们要做的就是给电脑一些包含标签与图片的样例,让电脑自己学习如何分类,这里成这种依靠训练数据的方法为data-driven approach,如下图,我们给电脑数以千计的图片,每类图片都包含数以万计张不同的图片,让电脑学习:

图像分类流程
完整的图像分类流程如下:
1. 输入 input :输入n张包含一类标签的图片,这也是训练数据集。
2. 学习Learning:使用上面的训练数据,进行学习,得到这类标签对应的模型,这也叫训练一个分类器。
3. 评估 evaluation: 最后我们用其他的新图片和测试评估得到的分类器的效果,当让我们希望它的预测结果中有大多数与与真实结果(ground truth)相同。
最近邻分类器 nearest neighbor classifier
我们首先使用的方法是nearest neighbor,他与convolutional neural network没有啥关系,只是用来让我们明白什么叫做图片分类。
我们使用数据集是CIFAR-10,他是由5w张训练图片和1w张测试图片组成,一共6w张10类玩具图片。
所谓nearest neighbor就是比较图片之间的差别大小,认为差别小的就是一类,其中一种简单的方法就是计算每个像素之间的差别然后将所有的差别相加,可以用l1距离或者l2距离来衡量像素之间的差别,设输入数据为向量I1,待测试数据为向量I2。L1距离公式为:

它的含义是计算每个像素间的l1范数然后相加,形象化如下:
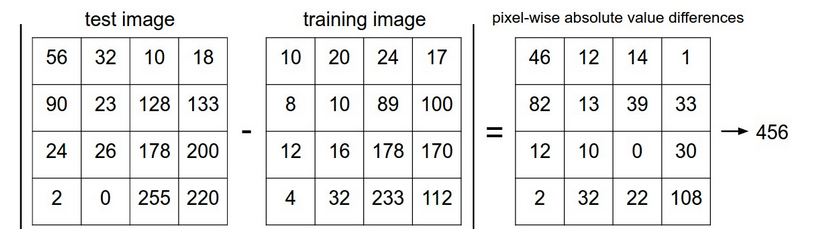
上面图片的差别是456,如果该待测试数据与所有的已知数据中的距离最小就是456,那么我们就认为他是与该已知的训练数图片最相似。
这种分类方法并不理想,文中说其测试结果为38.6%的测试结果正确,这与人类的识别能力(94%左右)相差甚远,而卷积神经网络能达到95%左右的精确度,而如果我们采取l2范数的方法来测试,得到的结果仅仅是35.4%,更低一点点,l2方法的公式是:
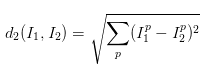
其他步骤与l1相同。
L2对大差距更为敏感如下例:
如三个向量分别为【2、3、4、1】【2、3、4、9】 【6、7、4、1】,测试第一个向量与另外两个的差距
l1结果为9-1=8 和6-2+7-3=8
l2结果为
8=64−−√
和
16+16−−−−−−√=32−−√
说明如果用l1范数来计算两者差距时认为后面的两个向量与第一个差不多,但是l2认为虽然第二个与第一个仅有一个值不同但是其值差距较大,所以认为第三个比第二个更像第一个。
KNN分类器
knn叫作k-nearest neighbor,他与nearest neighbor的区别就是不仅仅一看最接近的一个,而是取前k个最接近的,投票,比如与待测试图片想四的前5个图片的label分别是cat cat dog cat dog,那么我们就认为他是cat。
但是k到底选几好呢?我们可以使用验证(validation)的方法
Validation sets for Hyperparameter tuning 验证集参数调优
使用knn时我们需要知道k等于几的时候得到的值最好,或者使用l1还l2的效果比较好,如何得到我们想要的这些参数的值呢?首先要注意的是我们不能使用测试集来比较各个值的好处,因为现实生活中测试集是我们无法得到的,另外如果使用测试集得到的参数在应用的时候并不好,这也许就是造成了过拟合,过度的与测试集的数据拟合了。应该记住,测试集只能够作为最后的测试用,不能用来调整参数。
我们常使用调整参数的方法之一就是使用验证集validation sets来调优,以CIFAR-10为例:我们可以将50000个训练集人为划分为49000个训练集和1000个验证集,使用49000个训练集来训练模型用这1000个来查看不同参数时模型的表现,选择表现最好的模型。
如果你认为一个验证集数量太小可能不具有代表性,那么可以使用更科学的交叉验证的方法,交叉验证是将训练集分为n部分,然后每一部分都以此作为验证集来观察结果,例如将50000化为10fold,每次用一部分得到不同k值时的结果,最后对于每一个k值都可以得到10个准确度,可以使用其平均值最为最中的衡量标准,选择最好的k值。下图是将数据分为5部分后得到的不同k值的结果:
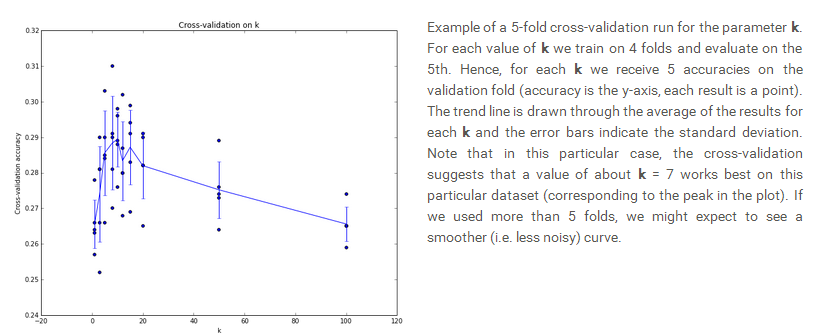
可以看出在k=7左右时精确度最高因此选择k等于7.
Pros and Cons of nearest neighbor nn方法的优缺点分析
由上面的介绍可以看到nearest neighbor的优点就是容易理解,容易实施,不用训练,但是在计算测试结果的时候需要将每一个结果与训练数据分别匹配计算,非常耗时但是我们一般在应用时需要较快的对目标图片进行判断分类,而我们后面将学到的深度神经网络虽然训练时间很长但是其应用时可以非常快的进行分类操作。
As an aside, 顺便说一句,很多人也在对nearest neighbor 的计算复杂度进行研究, 一些 Approximate Nearest Neighbor (ANN) 算法和数据库可以用来加速计算比如 FLANN).这些算法会对计算的精确度和检索的复杂度做一些权衡,通常会用些预处理比如建立 kdtree, 或者先进行聚类等(如 k-means algorithm)。
Nearest Neighbor Classifier 有时候在低纬度的一些数据集中表现较好,但是一般不适用于与图像的分类 ,他只对图像的颜色或者背景的值比较感兴趣,并不关注图像中的内容,比如下图的人像,在变换之后人还是一样的人可是用nearest neighbor得到的结果却相差很多:

为了更加突出表现使用像素间的差异不能用于很好的表现图片之间的差异,文中用t-SNE来将不同图片使用像素差异(l2)表现在下图中:

可见相似的图片主要是主色调和背景的相似,而不是图片中内容的相似。比如红色的车和在红色背景下的马被判断为相似。
由此看见利用像素间的区别来区分图片的类别的效果并不好。下节中我们会学习到一个准确度为90%左右,分类迅速的分类器。
Applying kNN in practice
knn的运用流程:
1. 预处理: 将特征标准化为均值为0,标准差为1的数据.
2. 降维,例如使用pca
3. 随机划分验证集
4. 保证训练数据在70%-90%左右. 使用交叉验证的时候越多folds 越好, 但是越 expensive.
5. 使用验证集选择参数和distance types (L1 and L2 are good candidates)
6. 如果knn花费时间比较长尝试使用FLANN等工具箱加速运算,但是可能会牺牲精确度。
7. 使用最佳参数在全部的数据集上训练,在test set上测试。


















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









