







本篇博文主要总结线性回归,线性回归虽然简单,但是却是很重要,我将沿着以下几个主题总结
- 最小二乘法
- 使用极大似然估计来解释最小二乘
的解析式的求解过程
- 线性回归的复杂度惩罚因子(LASSO,Ridge)
- 梯度下降法
- 实战
最小二乘法
线性回归,线性是指回归方程在空间中表现为直线形式,其决策边界是线性的.回归在数学上来说是给定一个点集,能够用一条曲线去拟合之,如果这个曲线是一条直线,那就被称为线性回归,
基本形式:
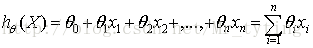
给定数据集”线性回归”试图学得一个线性模型以尽可能地预测实际输出值.这个不断学习的过程实际上就是不断调整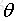
然而有一个问题,在这个学习过程中如何评价衡量他学习的效果?因此我们需要定义一个损失函数,来衡量学习过程中他的效果。
均方误差是回归任务中最常用的性能度量,因此我们可以试图让均方误差最小化.
cost Function:
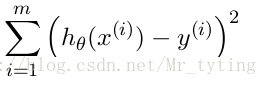
学习的目标:
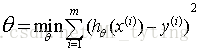
均方误差有非常好的几何意义,类似与常用的欧几里得距离.基于均方误差最小化的进行模型求解方法称为”最小二乘法“(least square method),在线性回归中,最小二乘法就是找到一条直线,使所有样本到直线的距离之和最小.
使用极大似然估计来解释最小二乘
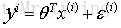
上面公式中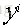
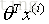
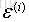
误差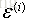
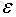
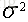
似然函数
上面说了误差服从高斯分布,那么可得:
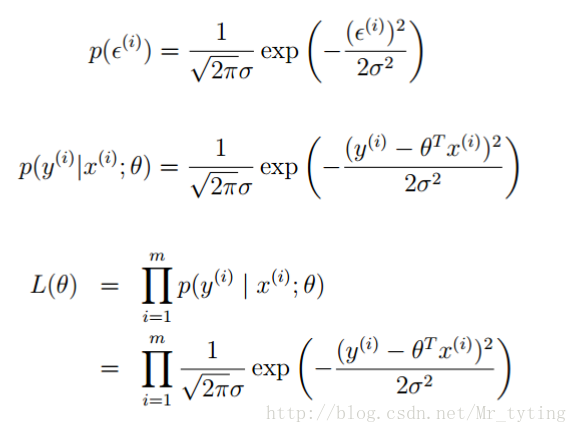
再求最大似然函数:
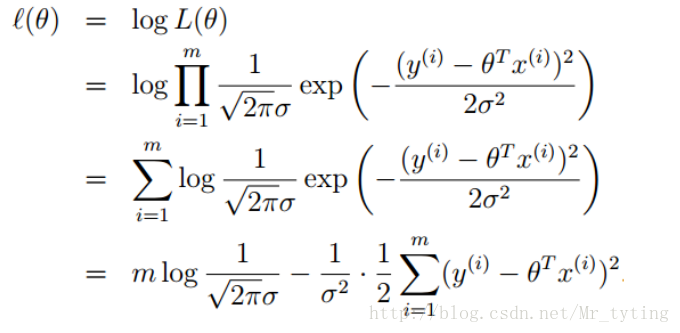
我们要求出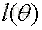
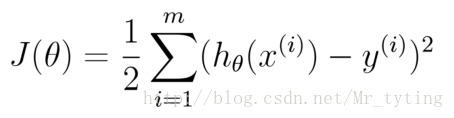
这样我们就通过了最大似然估计来解释了最小二乘估计的由来,其实最小二乘估计就是假定误差服从高斯分布,认为样本是独立,使用最大似然估计就能得出的结论。
的解析式的求解过程
将M个N维样本组成矩阵X:
- X的每一行对应一个样本,共M个样本(measurements)
- X的每一列对应样本的一个维度,共N维(regressors)
- 还有额外的一维常数项,全为1
那么目标函数:
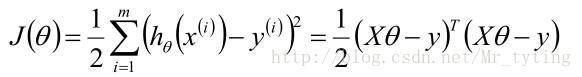
梯度:
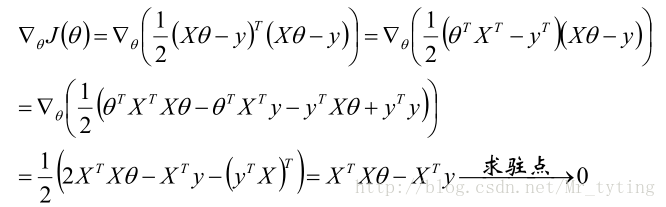
关于矩阵如何求导请看我的另外一篇博文机器学习–>矩阵和线性代数里面相关内容。
那么可得参数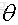
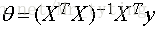
若X为可逆矩阵,则有:
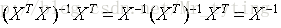
因此可以定义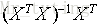
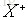
由此可以推出: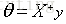
对于m*n的矩阵X,若它的SVD分解为: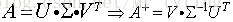
若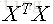
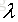
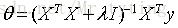
可以如下的简便记忆:
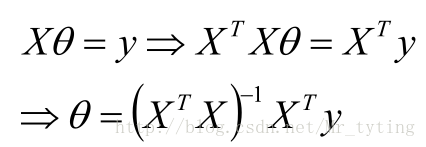
线性回归的复杂度惩罚因子(LASSO,Ridge)
线性回归的目标函数为:
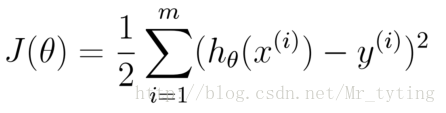
为了防止参数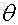
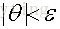
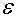
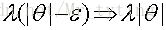
那么加上不同的正则项来防止过拟合:
Ridge:在目标函数后加上L2正则项:
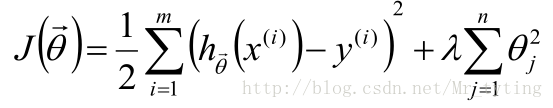
LASSO:在目标函数后加上L1正则项:
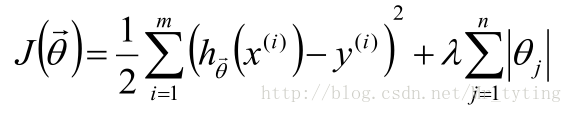
ELastic Net:L1正则项与L2正则项混合使用:
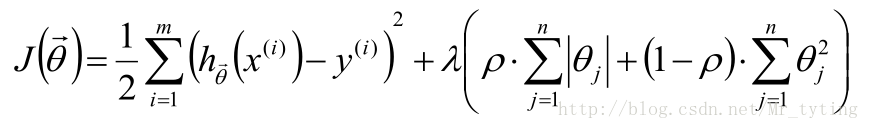
那么在目标函数后面加上正则项,正则项就是关于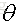
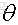
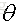
我们在训练一个线性模型时,这个模型越简单越好,就是希望参数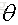
对比L1正则化和L2正则化,来看看为什么L1正则化能使参数变得稀疏。
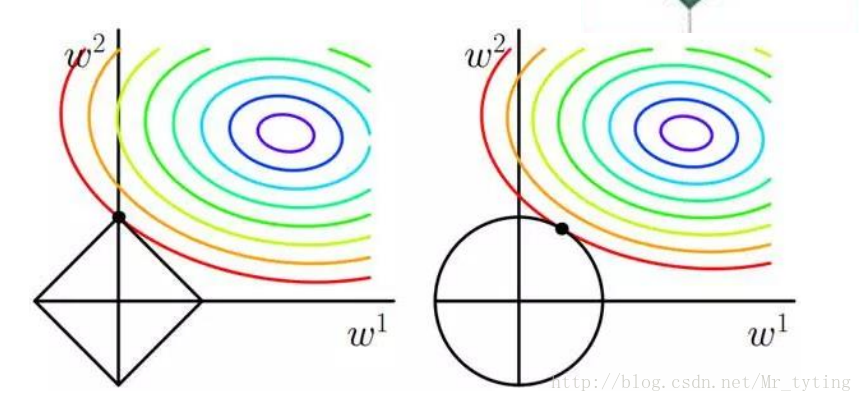
这里假设目标函数里面只有两个参数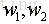
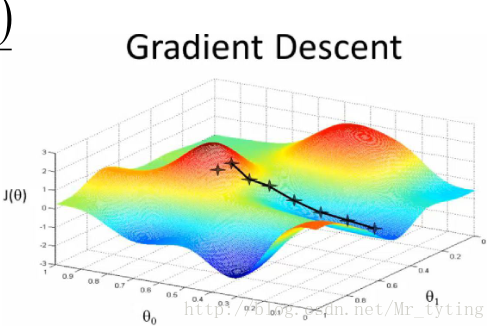
梯度下降法
在实际情景中,
于是我们要用一种逼近的办法来求解参数:梯度下降法.
梯度下降法一般流程:
- 首先对参数赋值,这个值可以是随机的,也可以
让是一个全零的向量.
改变
的值,使其损失函数按照梯度下降的方向进行减少,这个方向其实就是减少最快的方向
这时目标函数是关于参数的函数,需要不断的沿着参数的梯度方向下降,才能到达最低点。
- 不断重复2)步骤,使其误差在给定范围内.
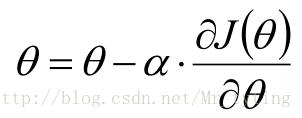
梯度方向:
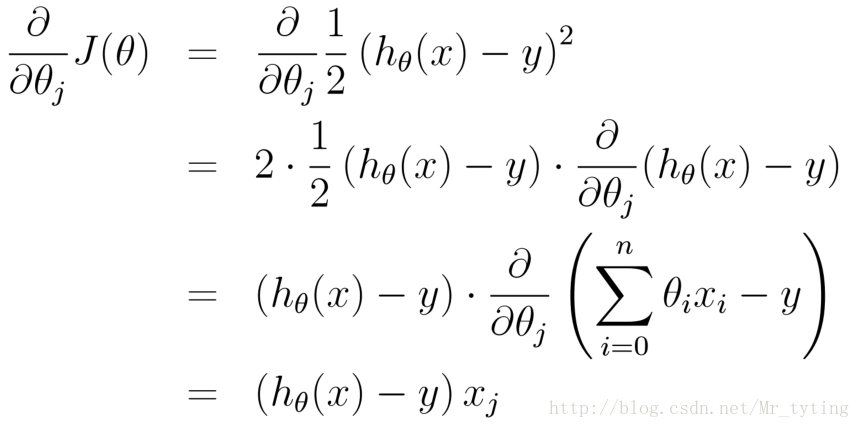
这里需要注意:当我们以损失函数进行参数估计时(例如线性回归里面的最小二乘估计),因为是求损失函数最小时的参数(是一个不断下降地逼近最低值),故采用梯度下降法,当我们用最大似然函数进行参数估计时,是求似然函数最大时对应的参数(是一个不断上升地逼近最高值),那么这时时梯度上升法。其实道理都是一样,只是前面正负号的问题。
批量梯度下降算法(GD):每次迭代拿出所有样本来更新参数
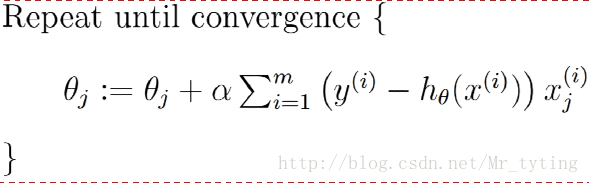
凸函数肯定能利用批量梯度下降法达到全局最优值(前提选择合适学习速率)
随机梯度下降算法(SGD):每次迭代随机拿出一个样本来更新参数
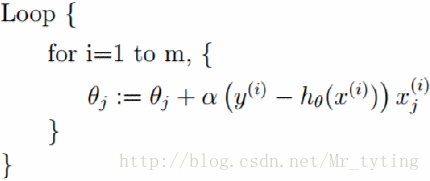
有时候随机梯度下降法比起批量梯度下降法更不容易陷入局部最优。
折中:mini-batch(mini-batchGD):每次迭代随机拿出一部分样本来更新参数
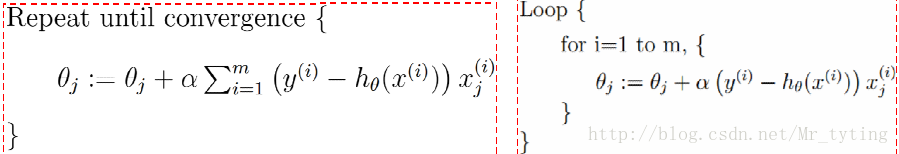
现在一般把mini-batchGD直接叫做SGD。
一步步更新w,b,一步步的迭代,那么这个更新迭代的过程什么时候结束呢?通常采用以下办法来判断什么时候停止更新迭代
1)定义一个最大迭代步数,当迭代次数大于等于这个最大迭代步数时,停止迭代
2)定义一个最小误差,当你更新得到的w,b代入到均方误差中得出的误差小于定义的最小误差,则停止迭代。
从泰勒公式解释随机梯度下降法
我们知道对于一个连续函数 h(x) h ( x ) ,在可导的某点处 x0 x 0 ,都可以展开近似,逼近 h(x) h ( x ) 。

显然,当
x
x
很接近 时:

同理多变量的泰勒展开式:

回到机器学习中的 lossFunction l o s s F u n c t i o n ,我们假设该 lossFunction l o s s F u n c t i o n 只有两个参数决定,分别是 θ1,θ2 θ 1 , θ 2 。则 loss l o s s 的等高线可如下:

那么在点(a,b) 处,我们可以利用泰勒展式来逼近
L(θ)
L
(
θ
)
。


注意:上式中的约等于号要成立,则点 (θ1,θ2) ( θ 1 , θ 2 ) 必须在点 (a,b) ( a , b ) 附近,两点距离越近越相等。
好了,我们得到了
L(θ)
L
(
θ
)
的公式,希望能
minimize loss
m
i
n
i
m
i
z
e
l
o
s
s
:

上式中的
s
s
与 无关,可以忽略,那么有:
将其看成向量内积的形式,则在最小化 loss l o s s 时有:

(\theat1,θ2) ( \theat 1 , θ 2 ) 取向量 (u,v) ( u , v ) 的反方向,但是其向量长度不能太大,我们需要保证其距离向量 (a,b) ( a , b ) 较近的地方,这样其上面的约等于号才能成立。
最后需要注意一点:线性回归可以是对样本非线性的,只要是对参数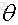
例如: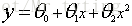
实战:
根据以上所学的我们来做一道题:
预测2014年南京市的房价,下面给出其历史数据:
Year X=[2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013]
Price Y=[2.000,2.500,2.900,3.147,4.515,4.903,5.365,5.704,6.853,7.971,8.561,10.000,
11.280,12.900]
这里写代码片
#coding:utf-8
import numpy as np
def geData():
X=[0,1,2,3,4,5,6,7,8,9,10,11,12,13]
Y=[2.000,2.500,2.900,3.147,4.515,4.903,5.365,5.704,6.853,7.971,8.561,10.000,11.280,12.900]
points=np.array((X,Y)).T
return points
def errors(w,b,points):
totalError=0
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
totalError+=(y-(w*x+b))**2
return totalError
def step_gradient(b_current,w_current,points,alpha):
b_gradient=0
w_gradient=0
N=float(len(points))
for i in range(0,len(points)):
x=points[i,0]
y=points[i,1]
b_gradient+=(((w_current*x)+b_current)-y)
w_gradient+=(((w_current*x)+b_current)-y)*x
new_b=b_current-(alpha*b_gradient)
new_w=w_current-(alpha*w_gradient)
return [new_b,new_w]
def gradient_descent_runner(points,starting_b,starting_w,alpha,max_iterations):
b=starting_b
w=starting_w
display=15000
count=1
lasterror = 0
for i in range(max_iterations):
b,w=step_gradient(b,w,points,alpha)
if i%display==0:
print errors(w,b,points)
count+=1
if count%2==0:
lasterror = errors(w, b, points)
elif count%2!=0 and np.abs(errors(w,b,points)-lasterror)<0.00000001:
break
return [b,w]
def run():
points=geData()
alpha=0.00001
initial_b=0
initial_w=0
max_iterations=100000000
params=gradient_descent_runner(points,initial_b,initial_w,alpha,max_iterations)
return params
if __name__=='__main__':
params=run()
res=params[1]*14+params[0]
print "预测结果:",res
输出结果:
700.156721871
7.12061861319
6.22403703469
5.94082542635
5.85136472694
5.82310593914
5.81417957156
5.81135991635
5.81046924549
5.81018790095
5.81009903002
5.81007095753
5.81006209001
5.81005928894
5.81005840414
5.81005812465
5.81005803637
5.81005800848
5.81005799967
5.81005799689
预测结果: 12.321043198
















 2511
2511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









