







本篇博文总仔细总结GBDT,RandomForest原理。
Boosting(提升)
提升是一个机器学习技术,可以用于回归和分类问 题,它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型生 成都是依据损失函数的梯度方向,则称之为梯度提升(Gradient boosting)。
梯度提升算法首先给定一个目标损失函数,它的定义域是所有可行的弱函数集合(基函数),即自变量就是每次加进来的基函数;提升算法 通过迭代的选择一个负梯度方向上的基函数来逐渐逼近局部极小值。(沿着梯度下降方向建立基函数)这种在函数域的梯度提升观点对机器学习的很多领域有深刻影响。
提升的理论意义:如果一个问题存在弱分类器,则 可以通过提升的办法得到强分类器。
提升算法
给定输入向量x和输出变量y组成的若干训练样本(x1,y1),(x2,y2),…,(xn,yn),目标是找到近似函数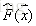
L(y,F(x))的典型定义为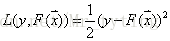
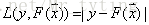
假定最优函数为
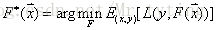
假定F(X)是一族基函数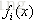
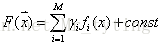
梯度提升方法寻找最优解F(x),使得损失函 数在训练集上的期望最小。方法如下:
首先,给定常函数
:
以贪心的思想扩展到
:
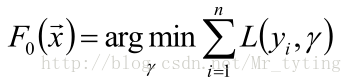
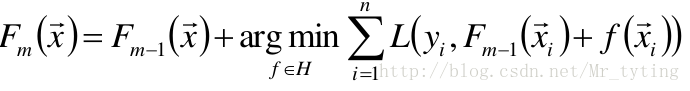
梯度近似
使用梯度下降法近似计算
将样本代入基函数f得到
,从而L退化为向量
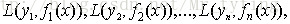
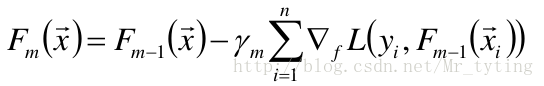
提升算法的一般步骤(GBDT):
- 给定初始模型为常数
对于m=1到M:
① 计算伪残差
注意:是对函数F求偏导,不是对x求导。
②使用数据
计算拟合残差的基函数
③给定一个步长
④更新模型
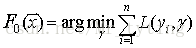
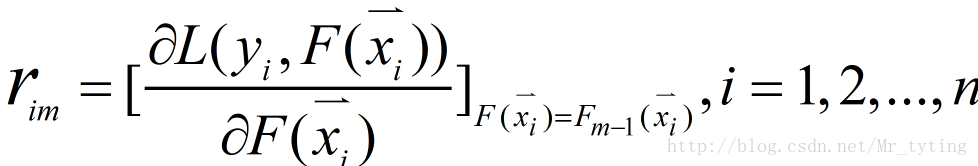
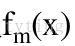
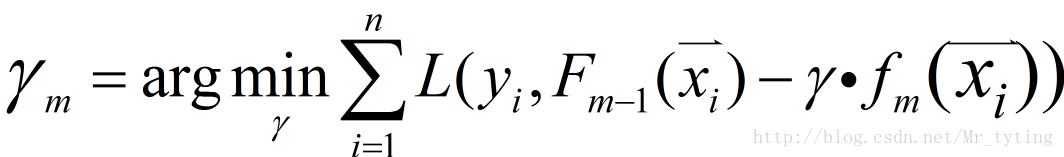
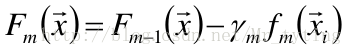
GBDT
梯度提升的典型基函数即决策树(尤其是CART) 。
在第m步的梯度提升是根据伪残差数据计算决策树 tm(x)。令树tm(x)的叶节点数目 为J,即树tm(x)将输入空间划分为J个不相交区域 R1m,R2m,…,RJm,并且决策树tm(x)可以在每个区域中给出某个类型的确定 性预测。使用指示记号I(x),对于输入x, tm(x) 为:
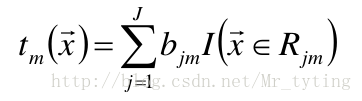
其中,bjm是样本x在区域Rjm的预测值。
使用线性搜索计算学习率,最小化损失函数:
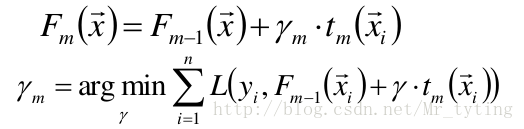
进一步:对树的每个区域分别计算步长,从 而系数bjm被合并到步长中,从而:
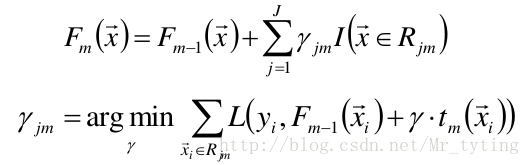
参数设置和正则化
对训练集拟合过高会降低模型的泛化能力,需要使 用正则化技术来降低过拟合。
- 对复杂模型增加惩罚项,如:模型复杂度正比于叶结点 数目或者叶结点预测值的平方和等。
- 用于决策树剪枝。
叶结点数目控制了树的层数,一般选择4≤J≤8。
叶结点包含的最少样本数目
- 防止出现过小的叶结点,降低预测方差
梯度提升迭代次数M:
- 增加M可降低训练集的损失值,但有过拟合风险
- 交叉验证
衰减因子、降采样
衰减Shrinkage
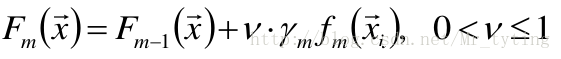
- 称ν为学习率
- ν=1即为原始模型;推荐选择v<0.1的小学习率。过小的 学习率会造成计算次数增多。
随机梯度提升Stochastic gradient boosting
- 每次迭代都对伪残差样本采用无放回的降采样,用部分 样本训练基函数的参数。令训练样本数占所有伪残差样本的比例为f;f=1即为原始模型:推荐0.5≤f≤0.8。
- 较小的f能够增强随机性,防止过拟合,并且收敛的快。
- 降采样的额外好处是能够使用剩余样本做模型验证。
GBDT总结
函数估计本来被认为是在函数空间而非参数空间的 数值优化问题,而阶段性的加性扩展和梯度下降手 段将函数估计转换成参数估计。
损失函数是最小平方误差、绝对值误差等,则为回 归问题;而误差函数换成多类别Logistic似然函数, 则成为分类问题。
Gradient Boost与传统的Adaboost的区别是,Gradient Boost会定义一个loassFunction,每一次的计算是为了减少上一次的loss,而为了消除loss,我们可以在loss减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的loss往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
RandomForest
RandomForest建立过程
- 从样本集中用Bootstrap采样选出n个样本;(Bootstrap即有放回的随机采样)
- 从所有属性中随机选择k个属性,选择最佳分割 属性作为节点建立CART决策树;
- 重复以上两步m次,即建立了m棵CART决策树;
这m个CART形成随机森林,通过投票表决结果, 决定数据属于哪一类。
随机森林是一个最近比较火的算法,它有很多的优点:
①在数据集上表现良好
②在当前的很多数据集上,相对其他算法有着很大的优势
③它能够处理很高维度(feature很多)的数据,并且不用做特征选择
④在训练完后,它能够给出哪些feature比较重要
⑤在创建随机森林的时候,对generlization error使用的是无偏估计
⑥训练速度快
⑦在训练过程中,能够检测到feature间的互相影响
⑧容易做成并行化方法
⑨实现比较简单
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
在建立每一棵决策树的过程中,有两点需要注意 - 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行(样例)、列(特征)的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。简而言之:就是可放回抽取样例,随机抽取部分特征。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
OOB数据
上面说到了,随机森林之“随机”
- 从原始样本集中随机有放回的抽样
- 从原始样本特征集中随机有放回的抽取一些特征出来
这里我们假设原始样本集中有n个样本,随机的有放回的从这n个样本集中抽取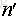
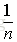
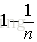
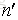

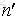
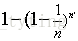

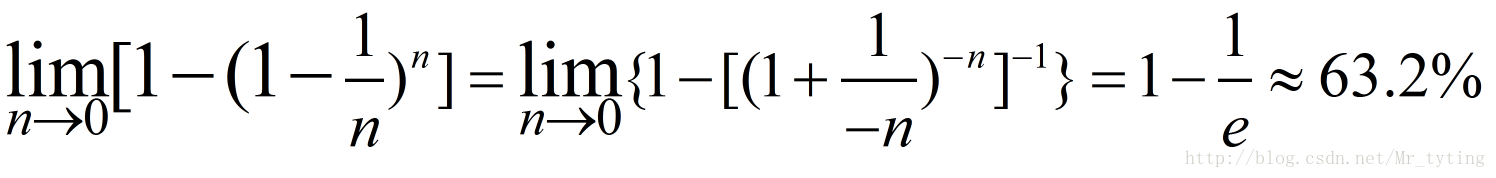
由此可得,在随机森林中,每次生成一颗决策树时,都会随机抽取63.2%的样本参与这棵树的生成,约有36.8%的样本没有参与到本次这棵树生成。我们把参与的63.2%的样本数据称为在bag中的数据,剩余的36.8%的样本数据称为out of Bag(OOB),即袋外数据,这些袋外数据可以取代测试集用于误差估计。每次生成一棵树时都会有袋外数据,就用袋外数据测试当前生成的这棵树的性能如何。
上面都是假定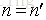
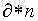
Breiman以经验性的实例形式证明袋外数据误差估计与同训练集一样大小的测试集精度相同。
clf = RandomForestClassifier(n_estimators=200, criterion='entropy', max_depth=3,oob_score=True) ##oob_score=True利用袋外数据验证模型性能
clf.fit(x, y.ravel())
print clf.oob_score_使用RF建立计算样本间相似度
原理:若两样本同时出现在相同叶结点的次数越多,则二者越相似。
算法过程:
记样本个数为N,初始化N×N的零矩阵S,S[i,j]表 示样本i和样本j的相似度。
对于m颗决策树形成的随机森林,遍历所有决策树 的所有叶子结点:
记该叶结点包含的样本为sample[1,2,…,k],则S[i][j]累加1。
样本i,j∈sample[1,2,…k]
样本i,j出现在相同叶结点的次数增加1次。遍历结束,则S为样本间相似度矩阵。
使用随机森林计算特征重要度
计算正例经过的结点,使用经过结点的数目、 经过结点的gini系数和等指标。或者,随机替换 一列数据,重新建立决策树,计算新模型的正 确率变化,从而考虑这一列特征的重要性。
总结
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。














 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









