







http://blog.csdn.net/pipisorry/article/details/39076957
常见离散概率分布
Bernoulli、Binomial、Poisson
:几种常见的概率分布")
伯努利分布
对单次抛硬币的建模,X~Bernoulli(p)的PDF为
随机变量X只能取{0, 1}。
对于所有的pdf,都要归一化!而对于伯努利分布,已经天然归一化了,因此归一化参数就是1。
现在我们假设我们有一个 x 的观测值的数据集 D = {x 1 , . . . , x N } 。假设每次观测都是独立地从 p(x | μ) 中抽取的,因此我们可以构造关于 μ 的似然函数如下
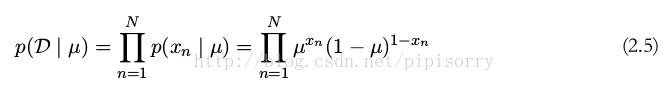
mle得出 μ = m/N。
二项分布
很多次抛硬币的建模就是二项分布了。二项分布是n次独立的伯努利试验的和(故根据中心极限定理可知,二项分布的极限分布为高斯分布)。它的期望值和方差分别等于每次单独试验的期望值和方差的和。
注意二项分布有两个参数,n和p,要考虑抛的次数。
二项分布的取值X一般是出现正面的次数,其PDF为:
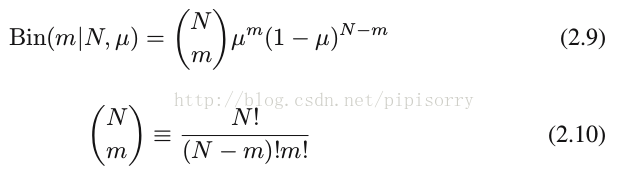
2.10就是二项分布pdf的归一化参数。
mle式2.9亦得出μ = m/N,故式 2.5和式2.9是等价的。lz:二项分布相当于是通过伯努利分布直接构造出的似然函数(没有归一化)的归一化分布。
beta分布
如果是beta分布,把归一化项换成beta函数分之一即可,这样可以从整数情况推广为实数情况。所以beta分布是二项分布的实数推广!
多项式分布Multinomial
多项分布则更进一层,抛硬币时X只能有两种取值,当X有多种取值时,就应该用多项分布建模。
这时参数p变成了一个向量 p⃗ =(p1,…,pk) 表示每一个取值被选中的概率,那么X~Multinomial(n,p)的PDF为:
f(x)=P(x1, …, xk|n,p⃗ )=(nx1, …, xk)px11…pxkk=n!∏ki=1xi!∏pxix二元变量可以用来描述只能取两种可能值中的某一种这样的量。然而,我们经常会遇到可以取 K 个互斥状态中的某一种的离散变量。虽然有多种方式来表达这种变量,但是我们稍后会看到,一种比较方便的表示方法是“1- of - K ”表示法。这种表示方法中,变量被表示成一个 K 维向量 x ,向量中的一个元素 x k 等于1,剩余的元素等于0。例如,如果我们有一个能够取 K = 6 种状态的变量,这个变量的某次特定的观测恰好对应于 x 3 = 1 的状态,那么 x 就可以表示为x = (0, 0, 1, 0, 0, 0) T。注意,这样的向量满足∑ xk=1
我们可以考虑 m 1 , . . . , m K 在参数 μ 和观测总数 N 条件下的联合分布。根据似然函数,这个分布的形式为

归 一 化 系 数 是 把 N 个 物 体 分 成 大 小为 m 1 , . . . , m K 的 K 组的方案总数,定义为

注意, m k 满足下面的限制

或者通过概率直接推出

常见连续概率分布
常见的概率分布_文库下载http://www.wenkuxiazai.com/doc/e14db3d233d4b14e852468c0.html
常见的概率分布_文库下载http://www.wenkuxiazai.com/doc/e14db3d233d4b14e852468c0.html
常见的连续分布的概率密度函数和累积分布度函数:
均匀分布

指数分布

正态分布与卡方分布
:几种常见的概率分布")
[概率论:高斯分布]
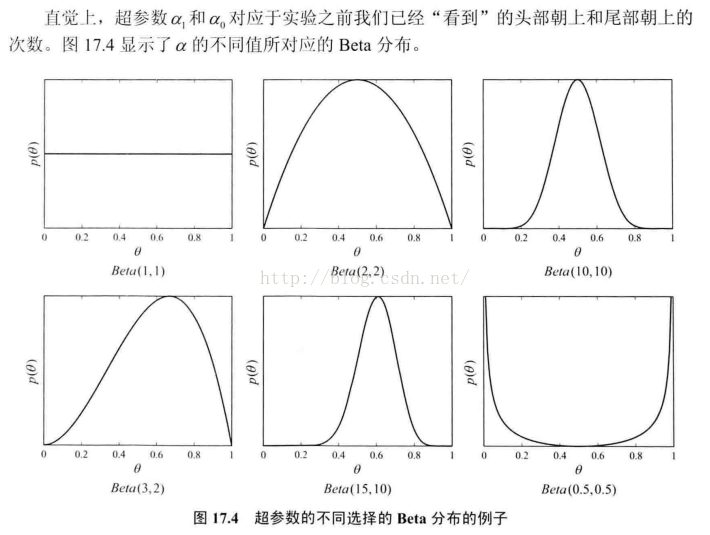
Beta分布



拉普拉斯分布 Laplace Dist
在概率论与统计学中,拉普拉斯分布是以皮埃尔-西蒙·拉普拉斯的名字命名的一种连续概率分布。由于它可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作双指数分布。当数据分布的波峰比正态分布更尖锐时使用 Laplace 分布。例如,Laplace 分布用于生物、金融和经济学方面的建模。
两个相互独立同概率分布指数随机变量之间的差别是按照指数分布的随机时间布朗运动,所以它遵循拉普拉斯分布。


概率分布、概率密度以及分位数函数
如果随机变量的概率密度函数分布为
-
f
(
x
|
μ
,
b
)
=
1
2
b
exp
(
−
|
x
−
μ
|
b
)
{\displaystyle f(x|\mu ,b)={\frac {1}{2b}}\exp \left(-{\frac {|x-\mu |}{b}}\right)\,\!}
-
=
1
2
b
{
exp
(
−
μ
−
x
b
)
if
x
<
μ
exp
(
−
x
−
μ
b
)
if
x
≥
μ
{\displaystyle ={\frac {1}{2b}}\left\{{\begin{matrix}\exp \left(-{\frac {\mu -x}{b}}\right)&{\mbox{if }}x<\mu \\[8pt]\exp \left(-{\frac {x-\mu }{b}}\right)&{\mbox{if }}x\geq \mu \end{matrix}}\right.}
-
=
1
2
b
{
exp
(
−
μ
−
x
b
)
if
x
<
μ
exp
(
−
x
−
μ
b
)
if
x
≥
μ
{\displaystyle ={\frac {1}{2b}}\left\{{\begin{matrix}\exp \left(-{\frac {\mu -x}{b}}\right)&{\mbox{if }}x<\mu \\[8pt]\exp \left(-{\frac {x-\mu }{b}}\right)&{\mbox{if }}x\geq \mu \end{matrix}}\right.}

![= \frac{1}{2b} \left\{\begin{matrix} \exp \left( -\frac{\mu-x}{b} \right) & \mbox{if }x < \mu \\[8pt] \exp \left( -\frac{x-\mu}{b} \right) & \mbox{if }x \geq \mu \end{matrix}\right.](https://wikimedia.org/api/rest_v1/media/math/render/svg/4af44a4a16a26cd390e42188ad06c5d23e9d6a73)
那么它就是拉普拉斯分布。其中,μ 是位置参数,b > 0 是尺度参数。如果 μ = 0,那么,正半部分恰好是尺度为 1/2 的指数分布。
拉普拉斯分布的概率密度函数让我们联想到正态分布,但是,正态分布是用相对于 μ 平均值的差的平方来表示,而拉普拉斯概率密度用相对于平均值的差的绝对值来表示。因此,拉普拉斯分布的尾部比正态分布更加平坦。
根据绝对值函数,如果将一个拉普拉斯分布分成两个对称的情形,那么很容易对拉普拉斯分布进行积分。它的累积分布函数为:
F
(
x
)
{\displaystyle F(x)\,}
 |
=
∫
−
∞
x
f
(
u
)
d
u
{\displaystyle =\int _{-\infty }^{x}\!\!f(u)\,\mathrm {d} u}
 |
=
{
1
2
exp
(
−
μ
−
x
b
)
if
x
<
μ
1
−
1
2
exp
(
−
x
−
μ
b
)
if
x
≥
μ
{\displaystyle =\left\{{\begin{matrix}&{\frac {1}{2}}\exp \left(-{\frac {\mu -x}{b}}\right)&{\mbox{if }}x<\mu \\[8pt]1-\!\!\!\!&{\frac {1}{2}}\exp \left(-{\frac {x-\mu }{b}}\right)&{\mbox{if }}x\geq \mu \end{matrix}}\right.}
![= \left\{\begin{matrix} &\frac12 \exp \left( -\frac{\mu-x}{b} \right) & \mbox{if }x < \mu \\[8pt] 1-\!\!\!\!&\frac12 \exp \left( -\frac{x-\mu}{b} \right) & \mbox{if }x \geq \mu \end{matrix}\right.](https://wikimedia.org/api/rest_v1/media/math/render/svg/c403da990d5c1bd5c8147f9821c465afc744ff97) | |
=
0.5
[
1
+
sgn
(
x
−
μ
)
(
1
−
exp
(
−
|
x
−
μ
|
/
b
)
)
]
{\displaystyle =0.5\,[1+\operatorname {sgn}(x-\mu )\,(1-\exp(-|x-\mu |/b))]}
![=0.5\,[1 + \sgn(x-\mu)\,(1-\exp(-|x-\mu|/b))]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d88a06d233cba19a43a8d9ba11894acdc28354fd) |
逆累积分布函数为
-
F
−
1
(
p
)
=
μ
−
b
sgn
(
p
−
0.5
)
ln
(
1
−
2
|
p
−
0.5
|
)
{\displaystyle F^{-1}(p)=\mu -b\,\operatorname {sgn}(p-0.5)\,\ln(1-2|p-0.5|)}

拉普拉斯分布的数字特征
| 参数 |
μ
{\displaystyle \mu \,}
 位置参数(实数) 位置参数(实数)b > 0 {\displaystyle b>0\,}  尺度参数(实数) 尺度参数(实数) |
|---|---|
| 支撑集 |
x
∈
(
−
∞
;
+
∞
)
{\displaystyle x\in (-\infty ;+\infty )\,}
 |
| 概率密度函数 |
1
2
b
exp
(
−
|
x
−
μ
|
b
)
{\displaystyle {\frac {1}{2\,b}}\exp \left(-{\frac {|x-\mu |}{b}}\right)\,}
 |
| 期望值 |
μ
{\displaystyle \mu \,}
|
| 中位数 |
μ
{\displaystyle \mu \,}
|
| 众数 |
μ
{\displaystyle \mu \,}
|
| 方差 |
2
b
2
{\displaystyle 2\,b^{2}}
 |
| 偏度 |
0
{\displaystyle 0\,}
 |
| 峰度 |
3
{\displaystyle 3\,}
 |
| 信息熵 |
1
+
ln
(
2
b
)
{\displaystyle 1+\ln(2\,b)}
 |
| 动差生成函数 |
exp
(
μ
t
)
1
−
b
2
t
2
{\displaystyle {\frac {\exp(\mu \,t)}{1-b^{2}\,t^{2}}}\,\!}
 for
|
t
|
<
1
/
b
{\displaystyle |t|<1/b\,} for
|
t
|
<
1
/
b
{\displaystyle |t|<1/b\,}
 |
| 特性函数 |
exp
(
μ
i
t
)
1
+
b
2
t
2
{\displaystyle {\frac {\exp(\mu \,i\,t)}{1+b^{2}\,t^{2}}}\,\!}
 |
拉普拉斯分布的性质
- 如果
Y
=
|
X
−
μ
|
{\displaystyle Y=|X-\mu |}
并且 X ∼ L a p l a c e {\displaystyle X\sim \mathrm {Laplace} }
,则 Y ∼ E x p o n e n t i a l {\displaystyle Y\sim \mathrm {Exponential} }
是指数分布。
- 如果
Y
=
X
1
−
X
2
{\displaystyle Y=X_{1}-X_{2}}
与 X 1 , X 2 ∼ E x p o n e n t i a l {\displaystyle X_{1},\,X_{2}\sim \mathrm {Exponential} }
,则 Y ∼ L a p l a c e {\displaystyle Y\sim \mathrm {Laplace} }
。
Gaussian-Exponential Mixture
laplace分布可以看成是高斯分布和指数分布的混合体。
from: http://blog.csdn.net/pipisorry/article/details/3907695
ref: [PRML]















 8302
8302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









