







 这篇论文提出了一种半监督学习方法,利用“平滑”理论,在标签样本和无标签样本间传递类标信息,通过迭代优化达到全局稳定状态。核心思想是样本分类的平滑性和对原始标签的保留,适用于图像分类等任务,算法简单而有效。
这篇论文提出了一种半监督学习方法,利用“平滑”理论,在标签样本和无标签样本间传递类标信息,通过迭代优化达到全局稳定状态。核心思想是样本分类的平滑性和对原始标签的保留,适用于图像分类等任务,算法简单而有效。
该论文被NIPS2003收录,目前已被引用3011次,无疑是经典中的经典。提出了一种基于“smooth”理论的半监督学习方法,方法实现简单、有效。
这里所说的“smooth”是指:在半监督学习问题中,算法学习到的分类目标函数,相对于标签样本和无标签样本所共同显示的内在结构,应该足够平滑(smooth)。
算法基于两个重要的假设:(1)空间中距离越近的点,越倾向于拥有同样的标签;(2)处于同一个结构(簇、流形等)的样本,倾向于拥有同样的标签。算法的核心思想:让每一个样本的类标信息在空间中进行传递,直到达到某种合适的全局状态。
算法内容
设样本集合X={x1,...,xl,xl+1,...,xn},标签集合L={1,...,c}。样本集合中前l个为带标签样本,其余为不带标签样本。算法的目标就是预测不带标签样本的标签。
设一个nxc的矩阵F,每行代表一个样本,且每行中最大的元素的位置就是该样本的标签。定义一个nxc的标签矩阵Y,若Yij = 1,则表明标签yi=j。
定义一个迭代算法,具体步骤为:
a)定义一个关联矩阵W,用来表示样本之间的空间位置关系,且其对角线元素为0。
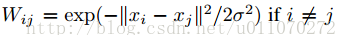
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









