




相关文章:
- 李航《统计学习方法》第二章——用Python实现感知器模型(MNIST数据集)
- 李航《统计学习方法》第三章——用Python实现KNN算法(MNIST数据集)
- 李航《统计学习方法》第四章——用Python实现朴素贝叶斯分类器(MNIST数据集)
- 李航《统计学习方法》第五章——用Python实现决策树(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现逻辑斯谛回归(MNIST数据集)
- 李航《统计学习方法》第六章——用Python实现最大熵模型(MNIST数据集)
- 李航《统计学习方法》第八章——用Python+Cpp实现AdaBoost算法(MNIST数据集)
- 李航《统计学习方法》第十章——用Python实现隐马尔科夫模型
在我看来,SVM的基本思想其实就是找一个超平面,这个超平面能正确划分训练数据集并且几何间距最大!
必须承认,我的SVM效果不好,且训练速度很慢,以至于不能用MNIST数据集进行测试。
支持向量机
我实现的是SMO算法
这里先贴上书上的算法

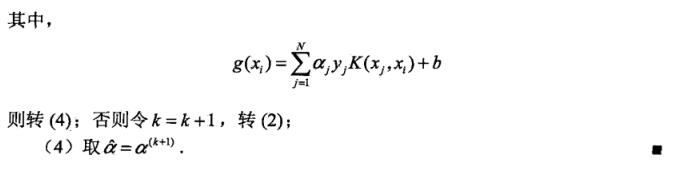
数据集
MNIST数据集特征太多,训练集也太大,导致SVM在计算初始E值得时候代价太高,运行时间太长,因此放弃使用MNIST数据集而选择使用伪造数据集。
数据集是伪造的二维的数据集,定义域为[0,1],值域为{-1,1},代码来自water1990一篇博客,稍微改了一下
代码
代码已放到Github上,这边也贴出来
# encoding=utf-8
# @Author: WenDesi
# @Date: 12-11-16
# @Email: wendesi@foxmail.com
# @Last modified by: WenDesi
# @Last modified time: 13-11-16
import time
import random
import logging
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from generate_dataset import *
class SVM(object):
def __init__ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 794
794









 到【灌水乐园】发言
到【灌水乐园】发言







