






3.1 大模型概括
为了更好的了解整体的功能结构(而不从一开始就陷入局部的结构细节),我们一开始先将语言模型(model)的看作一个黑箱(black box)(在后续的内容中再逐步的拆解),从形象化的概念理解上来说当前大语言模型(大:体现中模型的规模上)的能力,其可以根据输入需求的语言描述(prompt)生成符合需求的结果(completion),形式可以表达为:
prompt⇝modelcompletion or model(prompt)\=completionprompt \\overset{model}{\\leadsto} completion \\ \\ or \\ \\ model(prompt) = completionprompt⇝modelcompletion or model(prompt)\=completion
接下来我们将从大语言模型的训练数据(traning data)分析开始接下来的内容,首先给出如下的形式化描述
training data⇒p(x1,…,xL).training\ data \Rightarrow p(x_{1},…,x_{L}).training data⇒p(x1,…,xL).
3.2 模型架构
到目前为止,我们已经将语言模型定义为对词元序列的概率分布 p(x1,…,xL)p(x_{1},…,x_{L})p(x1,…,xL),我们已经看到这种定义非常优雅且强大(通过提示,语言模型原则上可以完成任何任务,正如GPT-3所示)。然而,在实践中,对于专门的任务来说,避免生成整个序列的生成模型可能更高效。
上下文向量表征 (Contextual Embedding): 作为先决条件,主要的关键发展是将词元序列与相应的上下文的向量表征:
\[the,mouse,ate,the,cheese\]⇒ϕ\[(10.1),(01),(11),(1−0.1),(0−1)\].\[the, mouse, ate, the, cheese\] \\stackrel{\\phi}{\\Rightarrow}\\left\[\\left(\\begin{array}{c} 1 \\\\ 0.1 \\end{array}\\right),\\left(\\begin{array}{l} 0 \\\\ 1 \\end{array}\\right),\\left(\\begin{array}{l} 1 \\\\ 1 \\end{array}\\right),\\left(\\begin{array}{c} 1 \\\\ -0.1 \\end{array}\\right),\\left(\\begin{array}{c} 0 \\\\ -1 \\end{array}\\right)\\right\]. \[the,mouse,ate,the,cheese\]⇒ϕ\[(10.1),(01),(11),(1−0.1),(0−1)\].
正如名称所示,词元的上下文向量表征取决于其上下文(周围的单词);例如,考虑mouse的向量表示需要关注到周围某个窗口大小的其他单词。
-
符号表示:我们将 ϕ:VL→Rd×Lϕ:V{L}→ℝ{d×L}ϕ:VL→Rd×L 定义为嵌入函数(类似于序列的特征映射,映射为对应的向量表示)。
-
对于词元序列 x1:L=[x1,…,xL]x1:L=[x_{1},…,x_{L}]x1:L=[x1,…,xL],ϕϕϕ 生成上下文向量表征 ϕ(x1:L)ϕ(x_{1:L})ϕ(x1:L)。
3.3 大模型分类
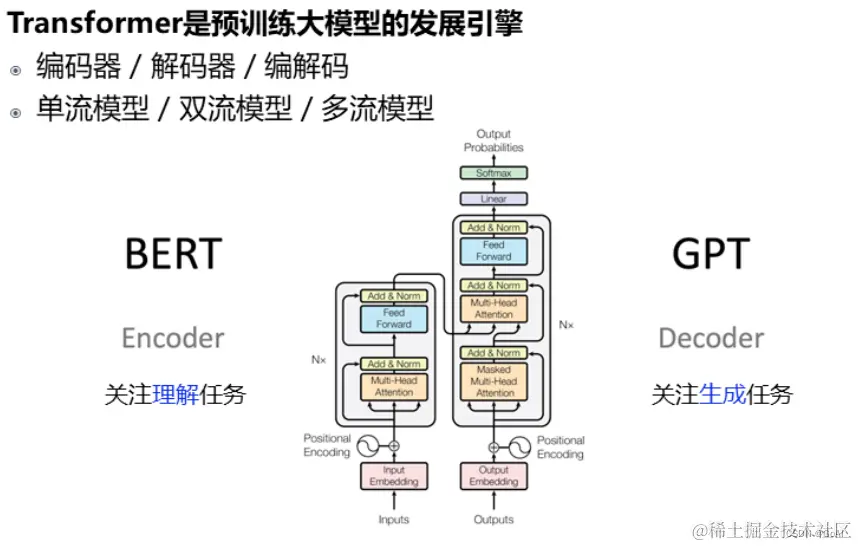
基于Transformer结构的模型又可以分为编码端(Encoder-Only),解码端(Decoder-Only)和编码-解码端(Encoder-Decoder)三类,具体如下图所示。

1.Encoder-Only架构:
定义与特点:这类模型仅包含编码器部分,主要用于从输入数据提取特征或表示。例如,在BERT (Bidirectional Encoder Representations from Transformers) 中,它是一个双向Transformer编码器,被训练来理解文本上下文信息,并输出一个固定长度的向量表示,该表示包含了原始输入序列的丰富语义信息。 用途:主要用于预训练模型,如BERT、RoBERTa等,常用于各种下游任务的特征提取,比如分类、问答、命名实体识别等,但不直接用于生成新的序列。
仅编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。
2.Decoder-Only架构:
定义与特点:解码器仅架构专注于从某种内部状态或先前生成的内容生成新的序列,通常用于自回归式预测任务,其中每个时刻的输出都依赖于前面生成的所有内容。 优点:强大的序列生成能力,能够按顺序逐个生成连续的元素(如单词、字符),适用于诸如文本生成、自动摘要、对话系统等生成性任务。典型的Decoder-Only模型包括GPT系列(如GPT-3)。
仅解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。
3.Encoder-Decoder架构:
定义与特点:这种架构由两个主要部分组成:编码器和解码器。编码器负责将输入序列转换为压缩的中间表示,解码器则基于这个中间表示生成目标输出序列。这种结构非常适合翻译、摘要生成、图像描述等任务,需要理解和重构输入信息后生成新序列的任务。 工作原理:编码器对源序列进行处理并生成上下文向量,解码器根据此上下文向量逐步生成目标序列。例如,经典的Seq2Seq(Sequence-to-Sequence)模型和Transformer中的机器翻译模型就采用了这样的结构。
编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于基于条件的生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
3.3.1 结构详细介绍
编码端(Encoder-Only)架构
编码端架构的著名的模型如BERT、RoBERTa等。这些语言模型生成上下文向量表征,但不能直接用于生成文本。可以表示为, x1:L⇒ϕ(x1:L)x_{1:L}⇒ϕ(x_{1:L})x1:L⇒ϕ(x1:L) 。这些上下文向量表征通常用于分类任务(也呗称为自然语言理解任务)。任务形式比较简单,下面以情感分类/自然语言推理任务举例:
情感分析输入与输出形式:[[CLS],他们,移动,而,强大]⇒正面情绪情感分析输入与输出形式:[[CLS], 他们, 移动, 而, 强大]\Rightarrow 正面情绪情感分析输入与输出形式:[[CLS],他们,移动,而,强大]⇒正面情绪
自然语言处理输入与输出形式:[[CLS],所有,动物,都,喜欢,吃,饼干,哦]⇒蕴涵自然语言处理输入与输出形式:[[CLS], 所有, 动物, 都, 喜欢, 吃, 饼干, 哦]⇒蕴涵自然语言处理输入与输出形式:[[CLS],所有,动物,都,喜欢,吃,饼干,哦]⇒蕴涵
该架构的优势是对于文本的上下文信息有更好的理解,因此该模型架构才会多用于理解任务。该架构的有点是对于每个 xix{i}xi ,上下文向量表征可以双向地依赖于左侧上下文 (x1:i−1)(x_{1:i−1})(x1:i−1) 和右侧上下文 (xi+1:L)(x_{i+1:L})(xi+1:L) 。但是缺点在于不能自然地生成完成文本,且需要更多的特定训练目标(如掩码语言建模)。
解码器(Decoder-Only)架构
解码器架构的著名模型就是大名鼎鼎的GPT系列模型。这些是我们常见的自回归语言模型,给定一个提示 x1:ix_{1:i}x1:i ,它们可以生成上下文向量表征,并对下一个词元 xi+1x_{i+1}xi+1 (以及递归地,整个完成 xi+1:Lx_{i+1:L}xi+1:L) 生成一个概率分布。 x1:i⇒ϕ(x1:i),p(xi+1∣x1:i)x_{1:i}⇒ϕ(x_{1:i}),p(x_{i+1}∣x_{1:i})x1:i⇒ϕ(x1:i),p(xi+1∣x1:i) 。我们以自动补全任务来说,输入与输出的形式为, [[CLS],他们,移动,而]⇒强大[[CLS], 他们, 移动, 而]⇒强大[[CLS],他们,移动,而]⇒强大 。与编码端架构比,其优点为能够自然地生成完成文本,有简单的训练目标(最大似然)。缺点也很明显,对于每个 xixixi ,上下文向量表征只能单向地依赖于左侧上下文 (x1:i−1x_{1:i−1}x1:i−1) 。
编码-解码端(Encoder-Decoder)架构
编码-解码端架构就是最初的Transformer模型,其他的还有如BART、T5等模型。这些模型在某种程度上结合了两者的优点:它们可以使用双向上下文向量表征来处理输入 x1:Lx_{1:L}x1:L ,并且可以生成输出 y1:Ly_{1:L}y1:L 。可以公式化为:
x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。x1:L⇒ϕ(x1:L),p(y1:L∣ϕ(x1:L))。
以表格到文本生成任务为例,其输入和输出的可以表示为:
[名称:,植物,∣,类型:,花卉,商店]⇒[花卉,是,一,个,商店]。[名称:, 植物, |, 类型:, 花卉, 商店]⇒[花卉, 是, 一, 个, 商店]。[名称:,植物,∣,类型:,花卉,商店]⇒[花卉,是,一,个,商店]。
该模型的具有编码端,解码端两个架构的共同的优点,对于每个 xix_{i}xi ,上下文向量表征可以双向地依赖于左侧上下文 x1:i−1x_{1:i−1}x1:i−1 ) 和右侧上下文 ( xi+1:Lx_{i+1:L}xi+1:L ),可以自由的生成文本数据。缺点就说需要更多的特定训练目标。
总结:
Encoder-Only用于理解输入并生成其抽象表示,不涉及序列生成。 Decoder-Only专门用于根据之前的信息自动生成新序列,不接收外部输入。 Encoder-Decoder结合了两者的功能,首先对输入进行编码,然后基于编码结果解码生成新序列。
3.3.2 语言模型理论
下一步,我们会介绍语言模型的模型架构,重点介绍Transformer架构机器延伸的内容。另外我们对于架构还会对于之前RNN网络的核心知识进行阐述,其目的是对于代表性的模型架构进行学习,为未来的内容增加知识储备。
深度学习的美妙之处在于能够创建构建模块,就像我们用函数构建整个程序一样。因此,在下面的模型架构的讲述中,我们能够像下面的函数一样封装,以函数的的方法进行理解:
TransformerBlock(x1:L)TransformerBlock(x_{1:L})TransformerBlock(x1:L)
为了简单起见,我们将在函数主体中包含参数,接下来,我们将定义一个构建模块库,直到构建完整的Transformer模型。
3.3.2.1 基础架构
首先,我们需要将词元序列转换为序列的向量形式。 EmbedTokenEmbedTokenEmbedToken 函数通过在嵌入矩阵 E∈R∣v∣×dE∈ℝ^{|v|×d}E∈R∣v∣×d 中查找每个词元所对应的向量,该向量的具体值这是从数据中学习的参数:
def EmbedToken(x1:L:VL)→Rd×LEmbedToken(x_{1:L}:V{L})→ℝ{d×L}EmbedToken(x1:L:VL)→Rd×L :
- 将序列 x1:Lx_{1:L}x1:L 中的每个词元 xixixi 转换为向量。
- 返回[Ex1,…,ExL]。
以上的词嵌入是传统的词嵌入,向量内容与上下文无关。这里我们定义一个抽象的 SequenceModelSequenceModelSequenceModel 函数,它接受这些上下文无关的嵌入,并将它们映射为上下文相关的嵌入。
defSequenceModel(x1:L:Rd×L)→Rd×Ldef SequenceModel(x_{1:L}:ℝ{d×L})→ℝ{d×L}defSequenceModel(x1:L:Rd×L)→Rd×L :
- 针对序列 x1:Lx_{1:L}x1:L 中的每个元素xi进行处理,考虑其他元素。
- [抽象实现(例如, FeedForwardSequenceModelFeedForwardSequenceModelFeedForwardSequenceModel , SequenceRNNSequenceRNNSequenceRNN , TransformerBlockTransformerBlockTransformerBlock )]
最简单类型的序列模型基于前馈网络(Bengio等人,2003),应用于固定长度的上下文,就像n-gram模型一样,函数的实现如下:
def FeedForwardSequenceModel(x1:L:Rd×L)→Rd×LFeedForwardSequenceModel(x_{1:L}:ℝ{d×L})→ℝ{d×L}FeedForwardSequenceModel(x1:L:Rd×L)→Rd×L :
- 通过查看最后 nnn 个元素处理序列 x1:Lx_{1:L}x1:L 中的每个元素 xixixi 。
- 对于每个 i=1,…,Li=1,…,Li=1,…,L :
- 计算 hih_{i}hi=FeedForward(xi−n+1,…,xi)FeedForward(x_{i−n+1},…,x_{i})FeedForward(xi−n+1,…,xi) 。
- 返回[ h1,…,hLh_{1},…,h_{L}h1,…,hL ]。
3.3.2.2 递归神经网络
第一个真正的序列模型是递归神经网络(RNN),它是一类模型,包括简单的RNN、LSTM和GRU。基本形式的RNN通过递归地计算一系列隐藏状态来进行计算。
def SequenceRNN(x:Rd×L)→Rd×LSequenceRNN(x:ℝ{d×L})→ℝ{d×L}SequenceRNN(x:Rd×L)→Rd×L :
- 从左到右处理序列 x1,…,xLx_{1},…,x_{L}x1,…,xL ,并递归计算向量 h1,…,hLh_{1},…,h_{L}h1,…,hL 。
- 对于 i=1,…,Li=1,…,Li=1,…,L :
- 计算 hi=RNN(hi−1,xi)h_{i}=RNN(h_{i−1},x_{i})hi=RNN(hi−1,xi) 。
- 返回 [h1,…,hL][h_{1},…,h_{L}][h1,…,hL] 。
实际完成工作的模块是RNN,类似于有限状态机,它接收当前状态h、新观测值x,并返回更新后的状态:
def RNN(h:Rd,x:Rd)→RdRNN(h:ℝd,x:ℝd)→ℝ^dRNN(h:Rd,x:Rd)→Rd :
- 根据新的观测值x更新隐藏状态h。
- [抽象实现(例如,SimpleRNN,LSTM,GRU)]
def SimpleRNN(h:Rd,x:Rd)→RdSimpleRNN(h:ℝd,x:ℝd)→ℝdSimpleRNN(h:Rd,x:Rd)→Rd :
- 通过简单的线性变换和非线性函数根据新的观测值 xxx 更新隐藏状态 hhh 。
- 返回 σ(Uh+Vx+b)σ(Uh+Vx+b)σ(Uh+Vx+b) 。
正如定义的RNN只依赖于过去,但我们可以通过向后运行另一个RNN来使其依赖于未来两个。这些模型被ELMo和ULMFiT使用。
def BidirectionalSequenceRNN(x1:L:Rd×L)→R2d×LBidirectionalSequenceRNN(x_{1:L}:ℝ{d×L})→ℝ{2d×L}BidirectionalSequenceRNN(x1:L:Rd×L)→R2d×L :
- 同时从左到右和从右到左处理序列。
- 计算从左到右: [h→1,…,h→L]←SequenceRNN(x1,…,xL)[h→_{1},…,h→_{L}]←SequenceRNN(x_{1},…,x_{L})[h→1,…,h→L]←SequenceRNN(x1,…,xL) 。
- 计算从右到左: [h←L,…,h←1]←SequenceRNN(xL,…,x1)[h←_{L},…,h←_{1}]←SequenceRNN(x_{L},…,x_{1})[h←L,…,h←1]←SequenceRNN(xL,…,x1) 。
- 返回 [h→1h←1,…,h→Lh←L][h→_{1}h←_{1},…,h→_{L}h←_{L}][h→1h←1,…,h→Lh←L] 。
注:
- 简单RNN由于梯度消失的问题很难训练。
- 为了解决这个问题,发展了长短期记忆(LSTM)和门控循环单元(GRU)(都属于RNN)。
- 然而,即使嵌入h200可以依赖于任意远的过去(例如,x1),它不太可能以“精确”的方式依赖于它(更多讨论,请参见Khandelwal等人,2018)。
- 从某种意义上说,LSTM真正地将深度学习引入了NLP领域。
3.4 Transformer组成
Transformer是一种由谷歌在2017年提出的深度学习模型,主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如机器翻译、文本生成等。Transformer彻底改变了之前基于循环神经网络(RNNs)和长短期记忆网络(LSTMs)的序列建模范式,并且在性能上取得了显著提升。Transformer模型将其分解为Decoder-Only(GPT-2,GPT-3)、Encoder-Only(BERT,RoBERTa)和Encoder-Decoder(BART,T5)模型的构建模块。Transformer结构如下图所示:
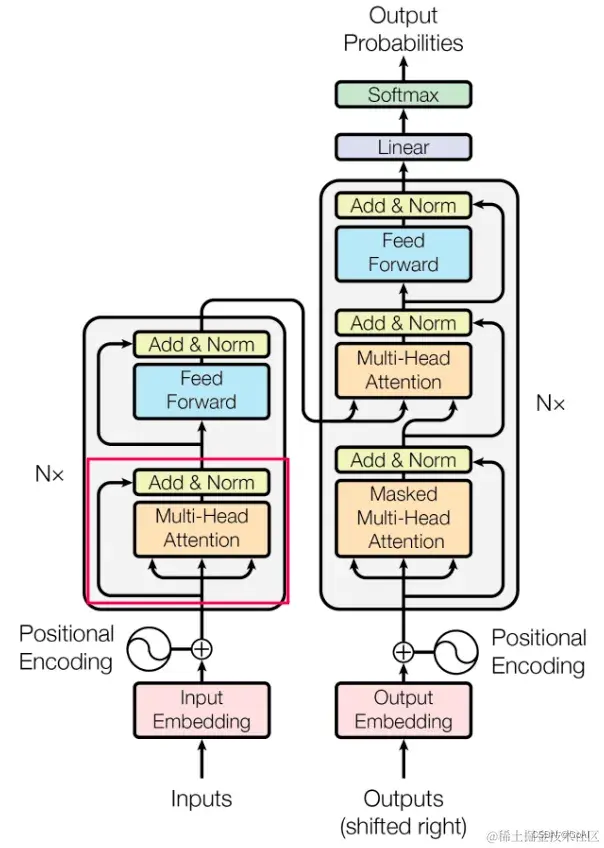
Transformer的核心创新点包括:
自注意力机制(Self-Attention Mechanism):Transformer模型摒弃了传统RNN结构的时间依赖性,通过自注意力机制实现了对输入序列中任意两个位置之间的直接关联建模。每个词的位置可以同时关注整个句子中的其他所有词,计算它们之间的相关性得分,然后根据这些得分加权求和得到该位置的上下文向量表示。这种全局信息的捕获能力极大地提高了模型的表达力。
多头注意力(Multi-Head Attention):Transformer进一步将自注意力机制分解为多个并行的“头部”,每个头部负责从不同角度对输入序列进行关注,从而增强了模型捕捉多种复杂依赖关系的能力。最后,各个头部的结果会拼接并经过线性变换后得到最终的注意力输出。
位置编码(Positional Encoding):由于Transformer不再使用RNN那样的顺序处理方式,为了引入序列中词的位置信息,它采用了一种特殊的位置编码方法。这种方法对序列中的每个位置赋予一个特定的向量,这个向量的值与位置有关,确保模型在处理时能够区分不同的词语顺序。
编码器-解码器架构(Encoder-Decoder Architecture):Transformer采用了标准的编码器-解码器结构,其中编码器负责理解输入序列,将其转换成高级语义表示;而解码器则依据编码器的输出并结合自身产生的隐状态逐步生成目标序列。在解码过程中,解码器还应用了自注意力机制以及一种称为“掩码”(Masking)的技术来防止提前看到未来要预测的部分。
残差连接(Residual Connections):Transformer沿用了ResNet中的残差连接设计,以解决随着网络层数加深带来的梯度消失或爆炸问题,有助于训练更深更复杂的模型。
层归一化(Layer Normalization):Transformer使用了层归一化而非批量归一化,这使得模型在小批量训练时也能获得良好的表现,并且有利于模型收敛。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









