







metrics.classification_report用来输出评价指标,其主要参数如下
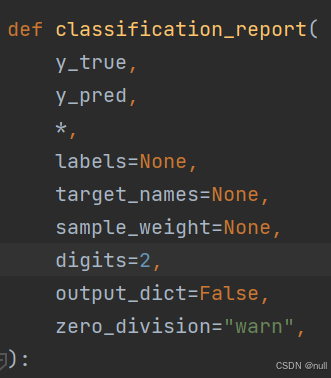
参数名与对应用途如下
| labels | 分类报告中显示的类标签的索引列表 |
| target_names | 字符串列表,显示与labels对应的名称 |
| sample_weight | 数组样本权重。 |
| digits | 输出浮点值的位数. |
| output_dict: | 如果为True,则返回一个字典格式的分类报告 |
设定目标值 y_true与估计值y_pred并代入metrics.classification_report函数
from sklearn.metrics import classification_report
y_true = [0,1,2,3,4,5,4,3,2,1]
y_pred = [0,2,2,3,4,5,4,3,2,1]
print(classification_report(y_true, y_pred))结果为
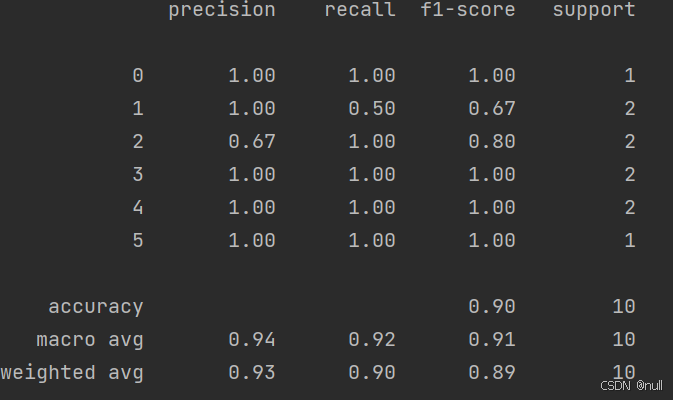
precision(精度) = 正确预测的个数(TP)/被预测正确的个数(TP+FP)
recall(召回率) = 正确预测的个数(TP)/预测个数(TP+FN)
f1-score = 2*精度*召回率/(精度+召回率)
support = 标签出现次数
accuracy:准确率,即正确预测样本量与总样本量的比值,9/10=0.9
macro avg:宏平均,表示所有类别对应指标的平均值,以recall为例
(1.0+0.5+1.0+1.0+1.0+1.0)/6=0.92
weight avg:带权重平均,表示类别样本占总样本的比重与对应指标的乘积的累加和,同样以recall为例
(1.0*1+0.5*2+1.0*2+1.0*2+1.0*2+1.0*1)/10=0.90















 951
951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









