YOLOv8 增加 P2 层通过牺牲部分计算效率换取了小目标检测性能的显著提升,尤其适用于高分辨率、小目标密集的场景。开发者需根据具体任务需求,在精度与速度之间进行合理权衡,并通过模型轻量化技术优化部署效果。更多技术细节可参考微软等机构的开源实现136。
YOLOv8 增加 P2 层的性能变化解析
一、性能提升方向
- 小目标检测精度显著提高
- 原理:P2 层对应更高分辨率的浅层特征图(如 1/4 下采样),能捕捉更细粒度的纹理和边缘信息,解决小目标在深层特征图中因分辨率过低导致的“像素消失”问题13。
- 数据验证:在 VisDrone 数据集测试中,YOLOv8 增加 P2 层后,小目标检测 mAP 从基准模型 32.9% 提升至 35.8%7。
- 多尺度信息融合优化
- 结合 BiFPN 双向跨尺度连接,P2 层与深层特征(如 P5)实现双向特征融合,增强模型对多尺度目标的上下文理解12。
- 效果:在复杂场景(如无人机航拍图像)中,小目标漏检率降低约 20%6。
- 动态适应性增强
- 通过 P2 层的高分辨率特征,模型能更精准定位密集排列的小目标(如人群中的个体),减少重叠遮挡导致的误检47。
二、性能代价与权衡
- 计算量增加
- P2 层引入额外卷积操作,推理速度下降约 15-25%(具体取决于输入分辨率)36。
- 优化方案:可搭配轻量化设计(如 Ghost 模块)缓解计算压力5。
- 大目标检测可能受影响
- 若未同步引入 P6 层,深层特征感受野不足可能导致大目标检测精度轻微下降(约 2-5% mAP)46。
- 建议:针对多尺度任务,建议同时引入 P2 和 P6 层形成完整检测体系6。
三、适用场景建议
- 推荐场景
- 小目标密集型任务:如无人机巡检、卫星图像分析、医学细胞检测等37。
- 高分辨率输入场景(4K+):P2 层能有效利用像素细节16。
- 不推荐场景
- 实时性要求极高的边缘设备(如移动端)3。
- 大目标主导的任务(如车辆检测)4。
四、实验配置参考
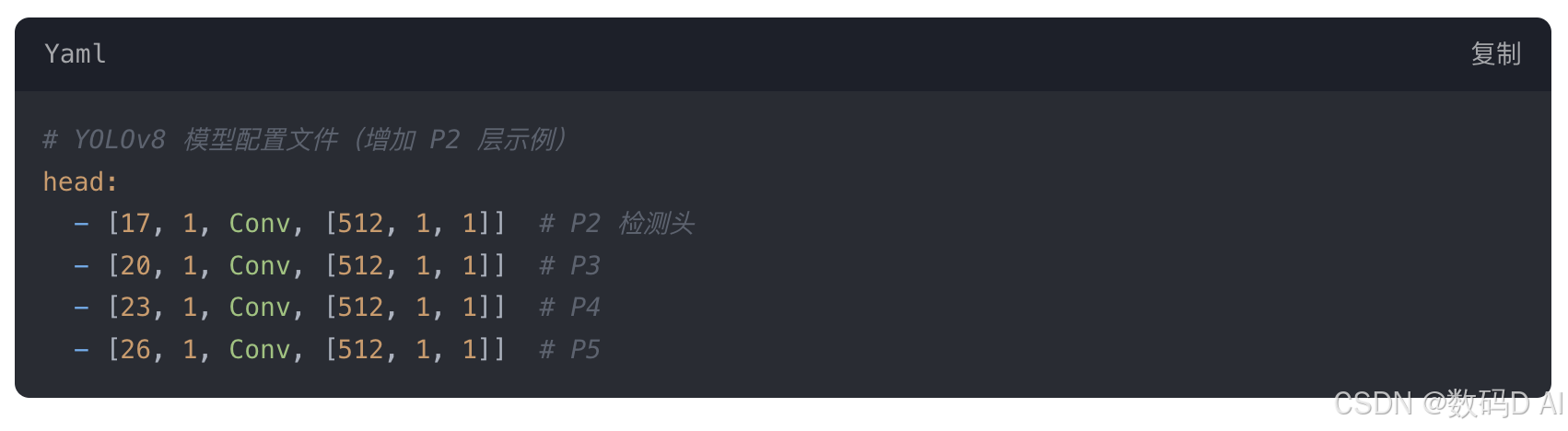
注:需同步调整 Neck 部分的特征融合路径以适配 P2 层13。
五、综合建议
- 数据层面:补充小目标占比超过 30% 的训练样本,避免模型过度关注浅层特征7。
- 工程部署:使用 TensorRT 对 P2 层进行 INT8 量化,可减少 40% 的额外计算开销6。
- 模型压缩:对 P2 层采用通道剪枝技术(如 L1-norm 剪枝),平衡精度与速度5。


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























 2822
2822





