






大家好!在之前的文章和想法中,作者介绍了很多关于RAG和工作流的知识,那么如何实战搭建一个RAG的应用呢?今天我们来聊聊如何使用 N8N 这个强大的自动化工具,快速搭建一个属于你自己的 RAG (Retrieval-Augmented Generation) 系统。
这个 RAG 系统不仅搭建起来方便,而且灵活性超高。你只需要稍作调整,就能轻松把它嵌入到自己的网站,实现智能客服功能;或者结合 Telegram 这类聊天软件,打造一个智能聊天机器人;甚至还能对接 Gmail,变身为自动回复邮件的智能助手!
我们会分两期内容详细介绍。本篇文章(上篇),我们将聚焦于 RAG 系统的核心搭建过程。下篇文章我们会接着探讨如何将搭建好的 RAG 系统应用到个人网站、Telegram 和 Gmail 中,构建能自动化解答用户提问的智能机器人。
废话不多说,让我们马上开始使用 N8N 搭建 RAG 系统!
一、 本地部署 N8N 服务:基础准备
首先,我们需要在本地把 N8N 环境跑起来。
- 打开 N8N 的 GitHub 项目页面。
- 向下滑动找到 "Quick Start" 部分。这里提供了 Node.js 和 Docker 两种部署方式。我们选择更方便快捷的 Docker 进行部署。
- 复制页面上提供的两条 Docker 命令。
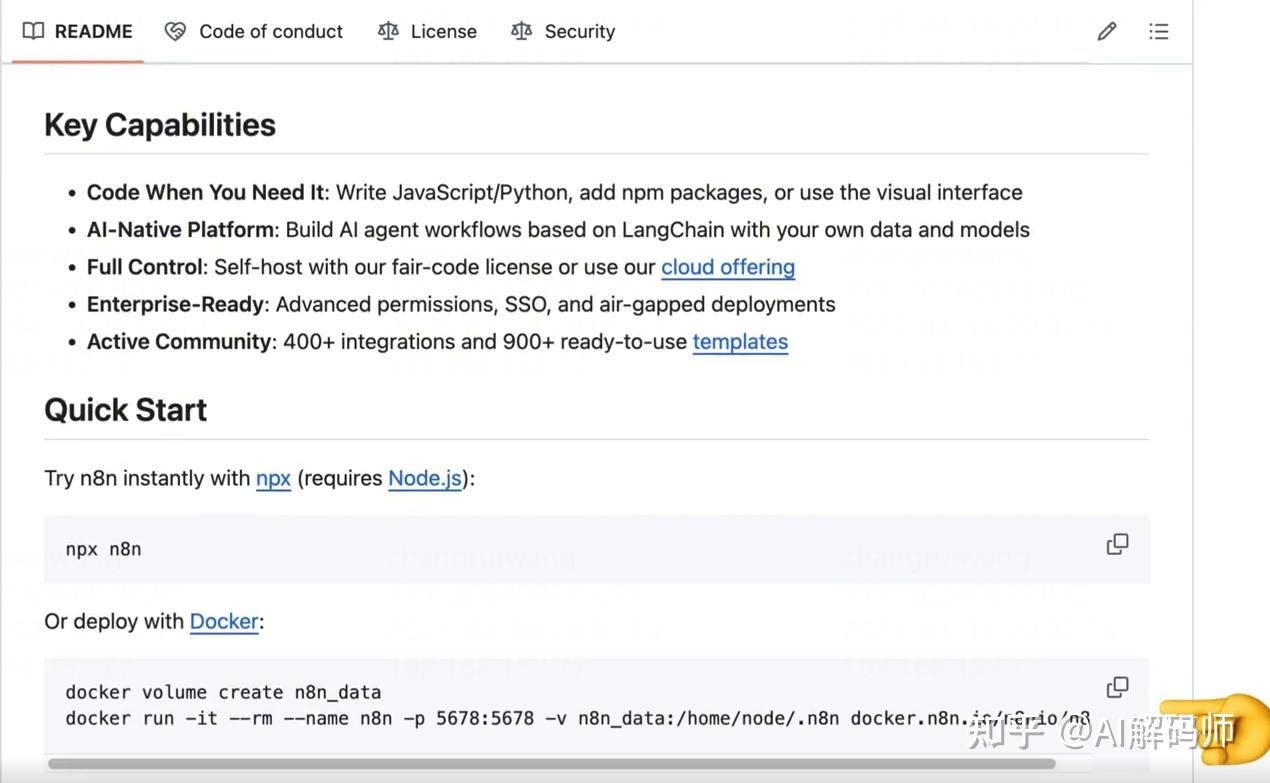
- 打开你的命令行终端(Terminal 或 CMD)。
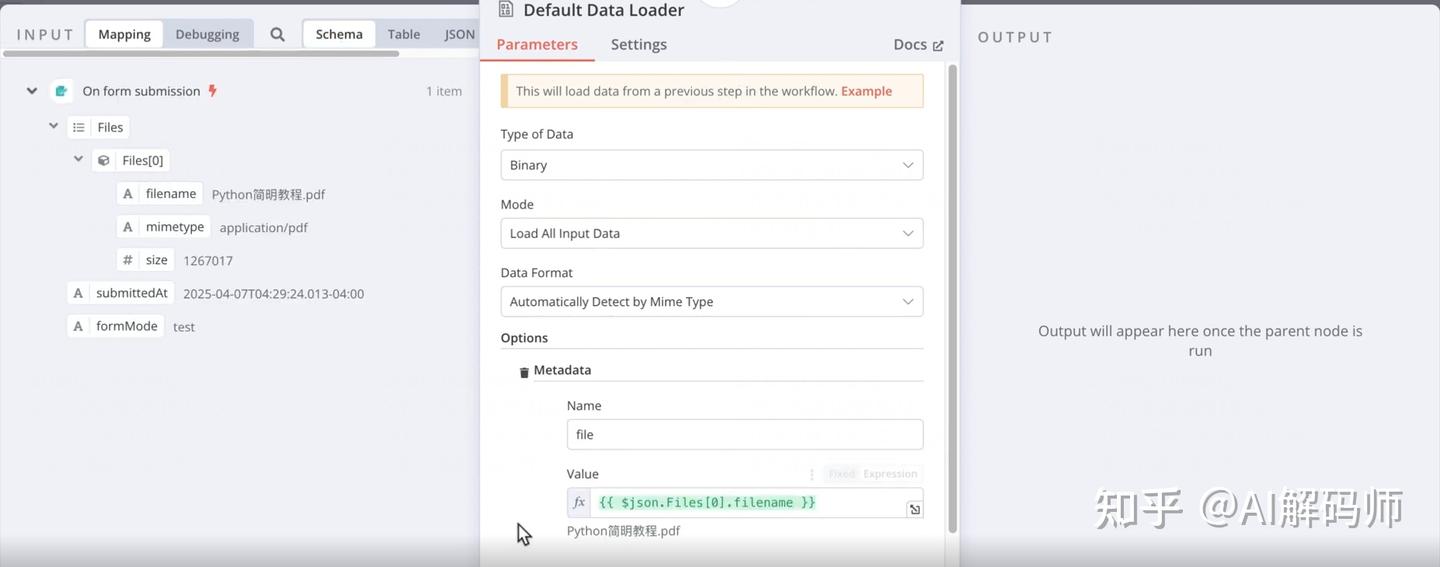
- 执行第一条命令: 这条命令的作用是创建一个名为
n8n_data的 Docker 数据卷。这个数据卷非常重要,它用于存储和持久化 N8N 容器的数据。这样一来,即使 Docker 容器重启甚至被删除了,你的工作流、凭证等数据也不会丢失。 - 接着执行第二条 Docker 启动命令: 等待命令执行完成,看到类似服务启动成功的日志。
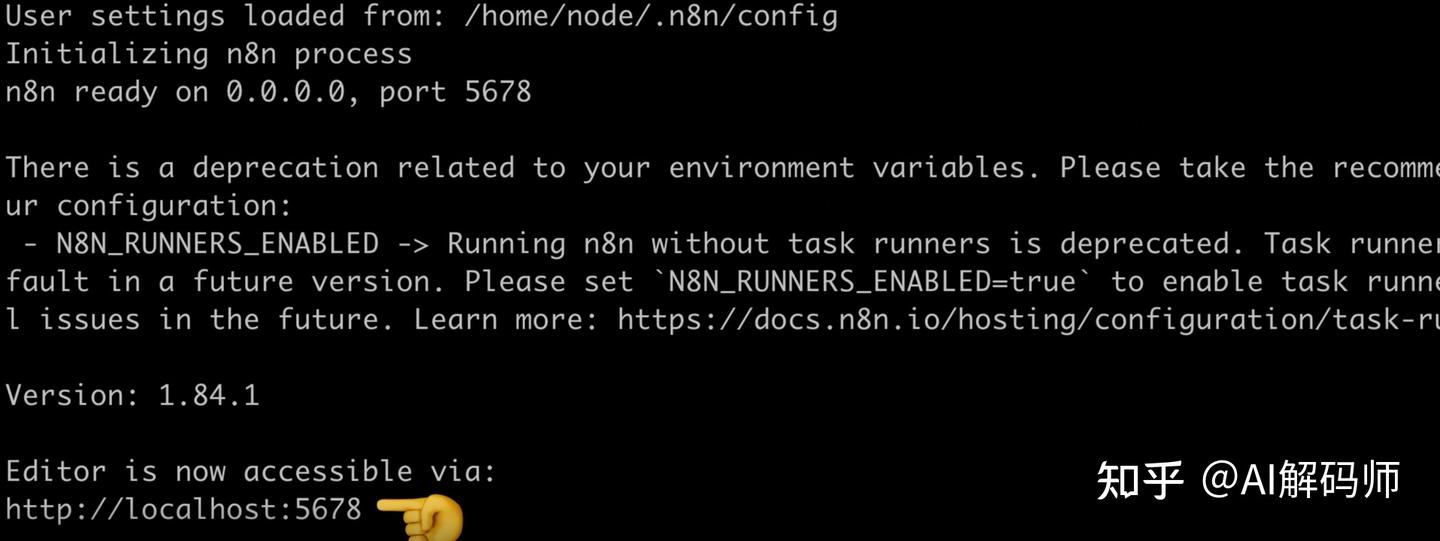
- 服务启动后,会监听在
5678端口。打开你的浏览器,访问http://localhost:5678。 - 首次访问 N8N,需要先注册一个管理员账号。完成注册后,我们就可以正式开始搭建 RAG 系统了。
二、 RAG 是什么?为什么需要它?
在动手之前,我们先简单理解一下 RAG 到底是什么。
想象一下,你问 AI 一个问题,比如:“什么是量子计算?”
- 普通的 AI (大语言模型 LLM):它会直接根据其内部知识库生成答案,然后返回给你。
- RAG 系统的工作流程:它比普通 AI 多了一个“检索增强”环节。
- 当你问:“什么是量子计算?”
- RAG 系统首先使用 嵌入模型 (Embedding Model) 将你的问题转换成数学上的向量 (Vector)。
- 然后,它拿着这个“问题向量”去一个专门的 知识库 (通常是向量数据库) 中,搜索与之最相关的内容片段。
- 接着,它把这些 检索到的相关内容 作为额外的 上下文信息 (Context),连同你原始的问题一起,提交给大语言模型 (LLM)。
- 最后,LLM 结合 你的问题 和 检索到的上下文 这两部分信息,生成最终的、更精准的答案,然后返回给你。
你会发现,RAG 系统引入了一个“外挂”——知识库。这个知识库通常存储在 向量数据库 (Vector Database) 中。
那么,数据是如何进入向量数据库的呢?
这就需要用到我们前面提到的 嵌入模型 (Embedding Model)。
- 数据存储阶段:原始数据(比如 PDF、文档、网页内容等)首先会被切分成小块,然后通过嵌入模型转换成向量,最后存入向量数据库。嵌入模型能捕捉文本的语义信息,并将其表示为计算机能理解的数字向量。
- 数据检索阶段:用户的提问也通过同一个(或兼容的)嵌入模型转换成向量,然后在向量数据库中查找语义上最接近的向量(也就是最相关的内容)。
使用 RAG 有什么好处?
- 缓解大模型的“幻觉”问题:大模型有时会在不熟悉的领域“一本正经地胡说八道”。通过 RAG 引入特定领域的专业知识库,可以有效约束模型的回答,提高准确性。
- 提升知识的时效性:大模型的知识通常截止于其训练日期。对于最新的信息或事件,模型可能无法很好地处理。RAG 允许我们将最新的知识构建成知识库,供模型随时调用,解决了信息滞后的问题。
- 保障数据隐私与安全:对于包含敏感信息的场景,可以使用自建的 RAG 系统配合本地部署的大模型。这样,数据无需传输到外部网络,避免了数据泄露的风险。即使是本地部署的模型,搭配 RAG 也能生成高质量的、基于私有知识的回答。
三、 动手!用 N8N 搭建 RAG 工作流
了解了 RAG 的原理和优势后,我们开始用 N8N 搭建它。整个 RAG 系统主要包含两条核心工作流:
- 工作流一:数据写入向量数据库 (构建知识库)
- 工作流二:结合知识库进行问答 (RAG 查询)
3.1 工作流一:构建知识库(数据处理与存储)
这条工作流的目标是读取文件,处理后存入向量数据库。
1、添加触发节点 (Trigger Node):
-
- 选择
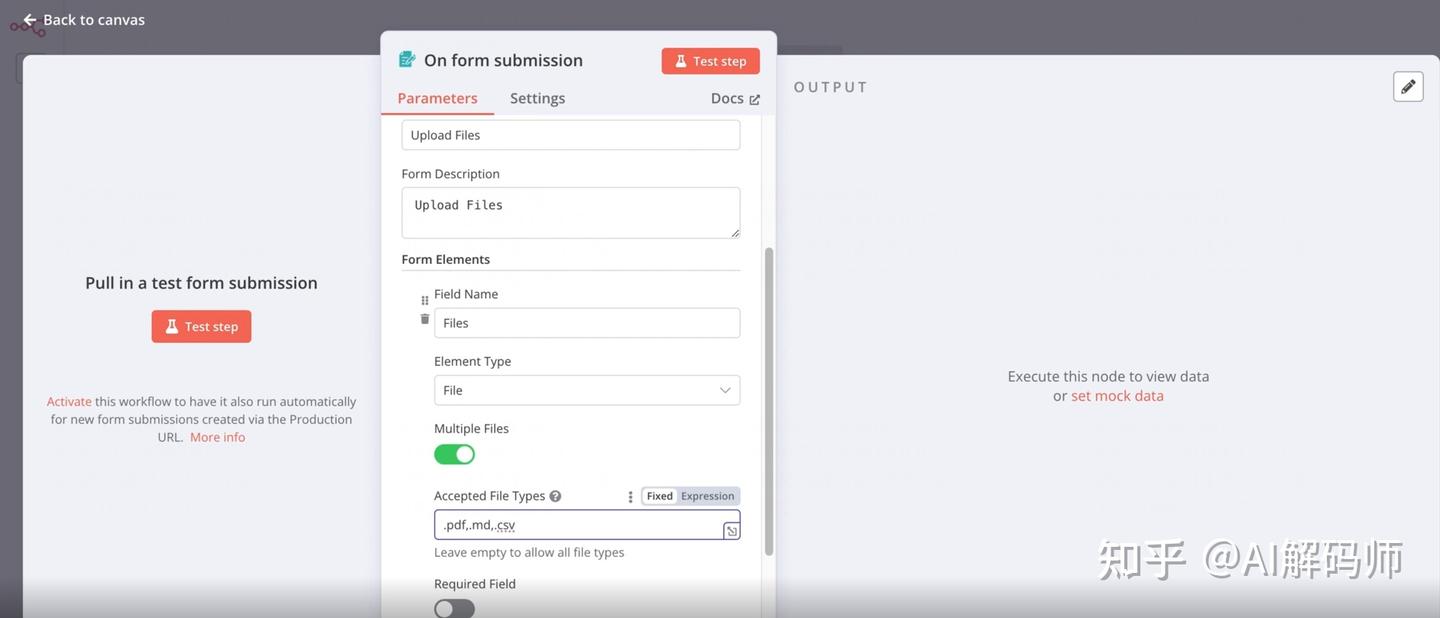
Form Trigger(表单触发器)。这个节点可以生成一个简单的网页表单,让我们用来上传需要处理的文件。 - 配置表单:
Title: 给表单起个标题,如 "上传知识库文件"。Description: 添加描述,如 "请上传 PDF, Markdown 或 CSV 文件"。- 添加一个字段 (Field):
Field Name: 比如knowledgeFiles。Type: 选择File(文件类型)。Allow Multiple Files: 勾选(或打开开关),允许一次上传多个文件。
Allowed File Extensions: 限制可上传的文件类型。使用英文逗号分隔,例如:.pdf,.md,.csv。
- (可选) 认证配置 (Authentication): 可以为这个表单接口添加基础认证 (用户名/密码),增加安全性。添加后,访问表单需要先登录。
- 点击
Test step(测试节点),然后点击生成的 URL 或Open Form,可以在浏览器中看到这个上传表单。尝试选择文件(你会发现只有指定后缀的文件可选),点击提交。在 N8N 中可以看到上传成功的文件信息。
- 选择
2、添加向量数据库节点 (Vector Database Node):
- 在节点搜索框中输入
vector。你会看到 N8N 支持的多种向量数据库。 - 我们这里选择 Pinecone。它提供了一定的免费额度,足够个人用户或测试使用。
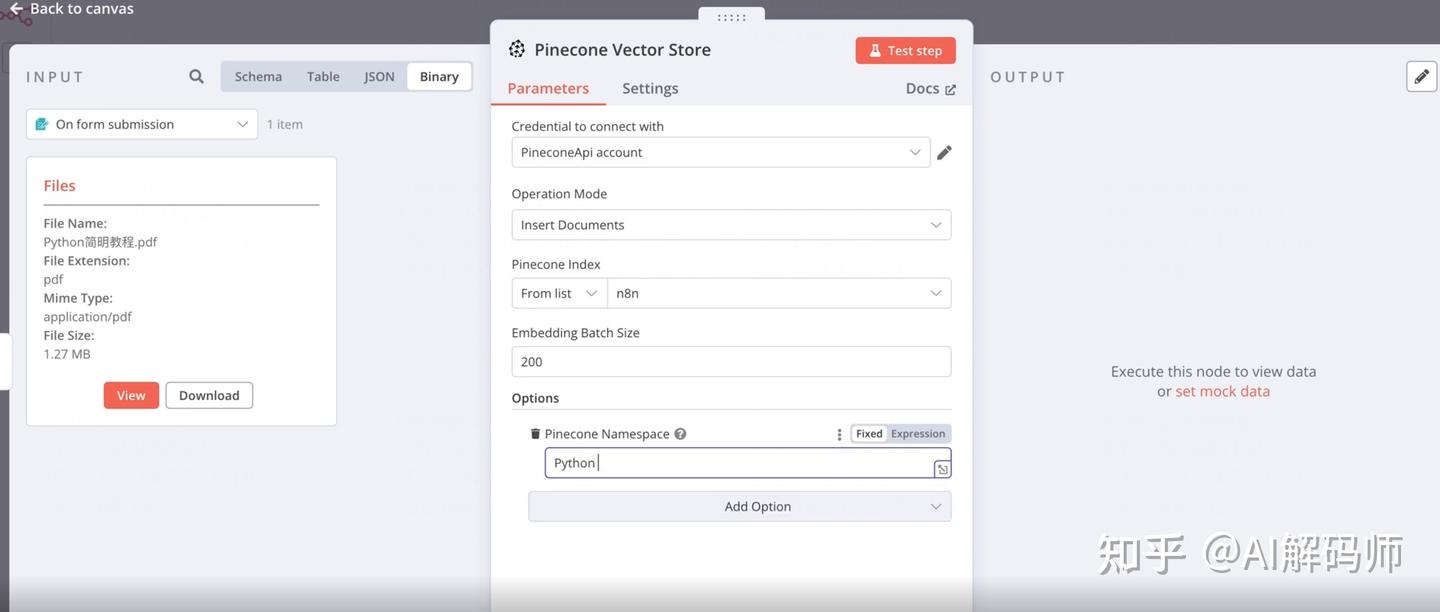
- 配置 Pinecone 节点:
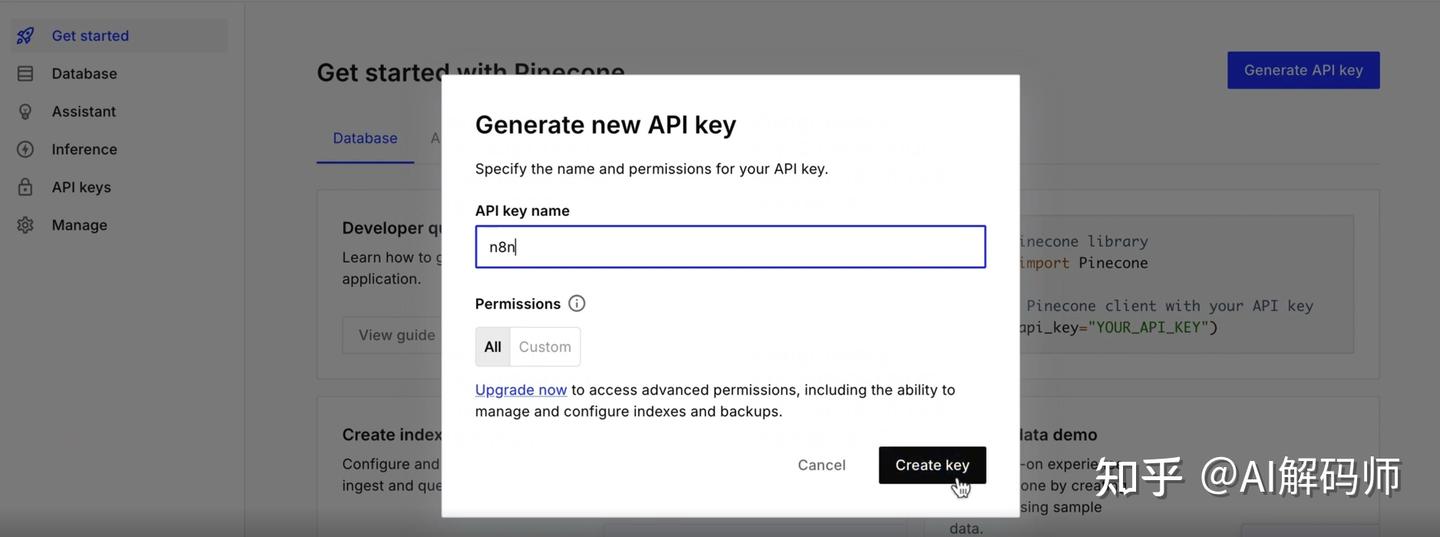
Authentication(凭证): 点击Create New Credential(创建新凭证)。这里需要填入你的 Pinecone API Key。- 获取 Pinecone API Key:
- 前往 Pinecone 官网并注册/登录。
- 在控制台中,通常在 "API Keys" 菜单下可以找到或创建一个新的 API Key。复制这个 Key。
- 回到 N8N,将 Key 粘贴到凭证配置中,保存。
- 获取 Pinecone API Key:
-
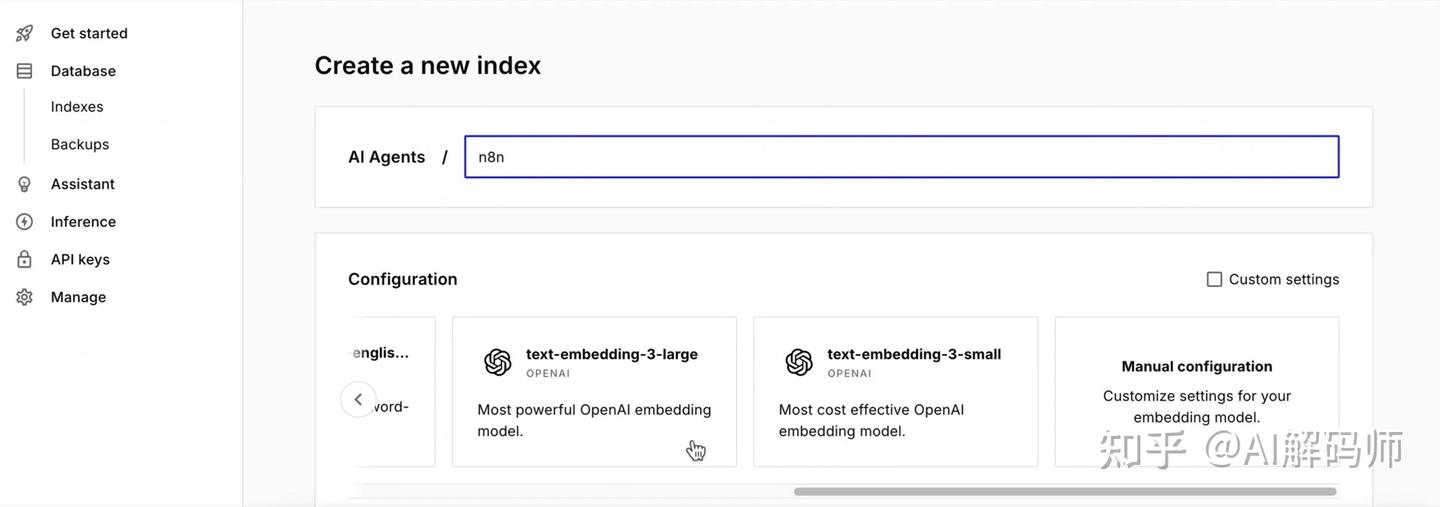
Resource: 选择Document(文档)。Operation: 选择Upsert(插入或更新文档)。Index Name: 输入你在 Pinecone 中创建的 索引 (Index) 名称。- 创建 Pinecone Index:
- 在 Pinecone 控制台,点击 "Indexes" -> "Create Index"。
- 输入一个索引名称,比如
n8n-rag-index。 - 选择维度 (Dimensions): 这个维度需要和你后面选择的 嵌入模型 (Embedding Model) 输出的向量维度一致。例如,OpenAI 的
text-embedding-3-small,text-embedding-3-large。先在这里确定好你要用哪个模型,然后填写对应的维度。我们这里先假设使用text-embedding-3-small。
- 创建 Pinecone Index:
-
-
-
- 点击创建。等待索引初始化完成。
- 回到 N8N,将创建好的索引名称填入
Index Name字段。
-
Namespace(命名空间): 输入一个命名空间,比如python-programming。Namespace 可以在同一个 Index 内逻辑地隔离数据。比如,你可以为 Python 知识创建一个 namespace,为 Java 知识创建另一个。这样检索时,只在对应的 namespace 里查找,更高效准确。
-
3、添加嵌入模型节点 (Embedding Model Node):
- 在 Pinecone 节点之前,我们需要一个节点来将文件内容转换为向量。搜索并添加
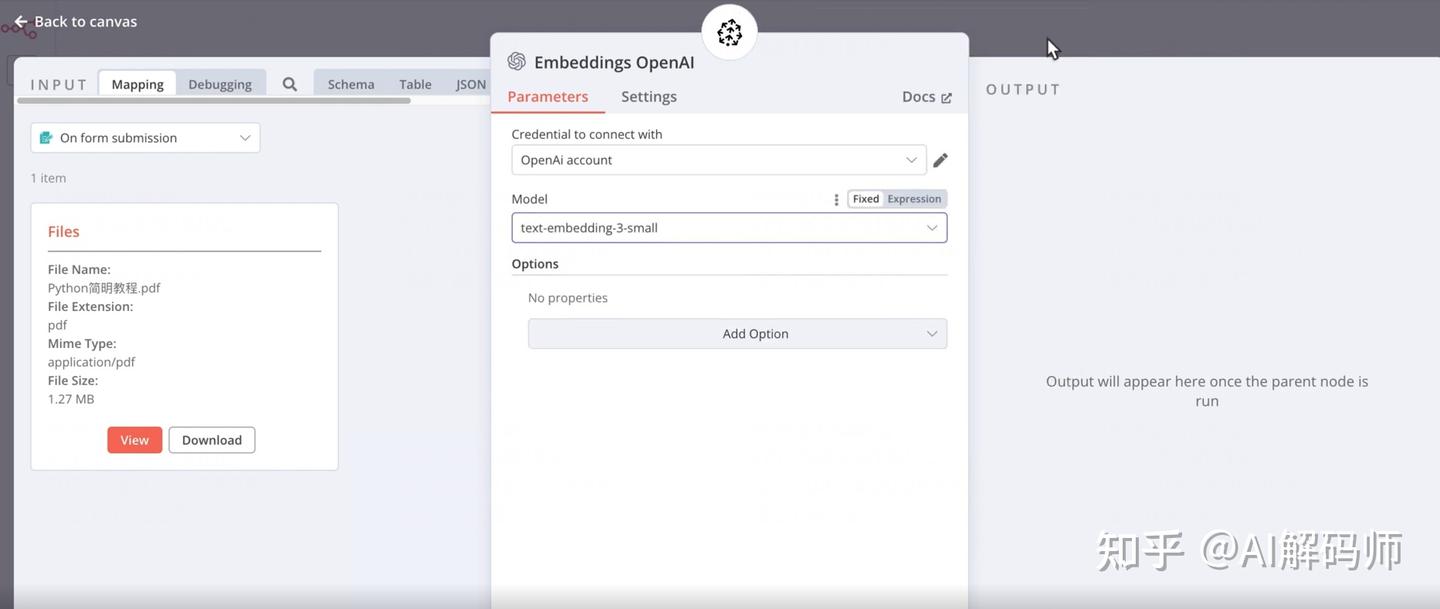
OpenAI节点 (或者你选择的其他嵌入模型提供商的节点)。 - 配置 OpenAI 节点 (用于 Embedding):
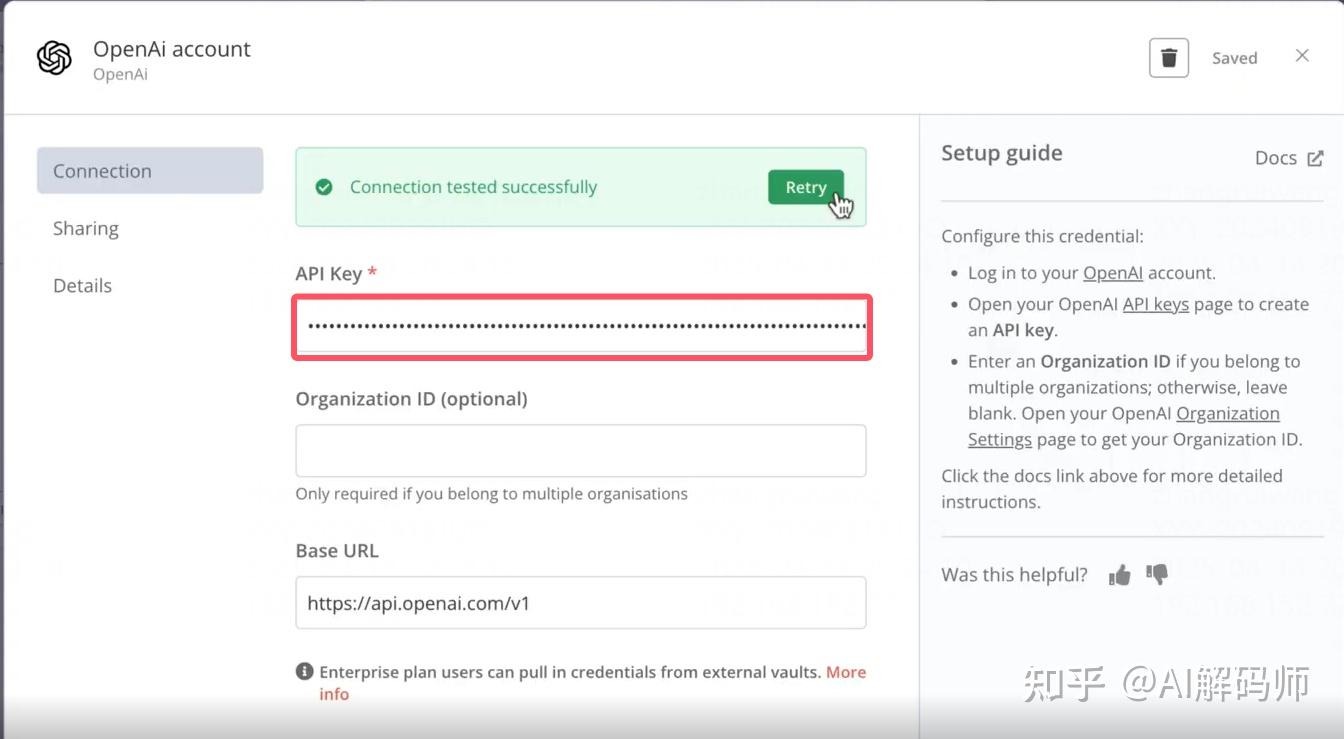
Authentication: 点击Create New Credential。这里需要你的 OpenAI API Key。- 获取 OpenAI API Key:
- 访问 OpenAI Platform并注册/登录。
- 进入 "API Keys" 菜单,创建一个新的 Secret Key。注意:这个 Key 只会显示一次,请立即复制并妥善保存。
- 回到 N8N,将获取到的 OpenAI API Key 填入凭证配置中,保存。
- 获取 OpenAI API Key:
-
Model: 选择与你在 Pinecone Index 中设定的维度相匹配的模型。我们之前假设是text-embedding-3-small,这里就选择它。
-
-
- 模型选择补充:
text-embedding-3-small性价比高,适合多数场景;text-embedding-3-large精度更高,向量维度更大,适合需要高精度语义检索的场景,但成本也更高。按需选择。- 价格参考:可以去 OpenAI 官网的文档 (Docs) 查看最新的 API 定价。嵌入模型通常按 Token 数量计费,价格相对便宜。
- 模型选择补充:
-
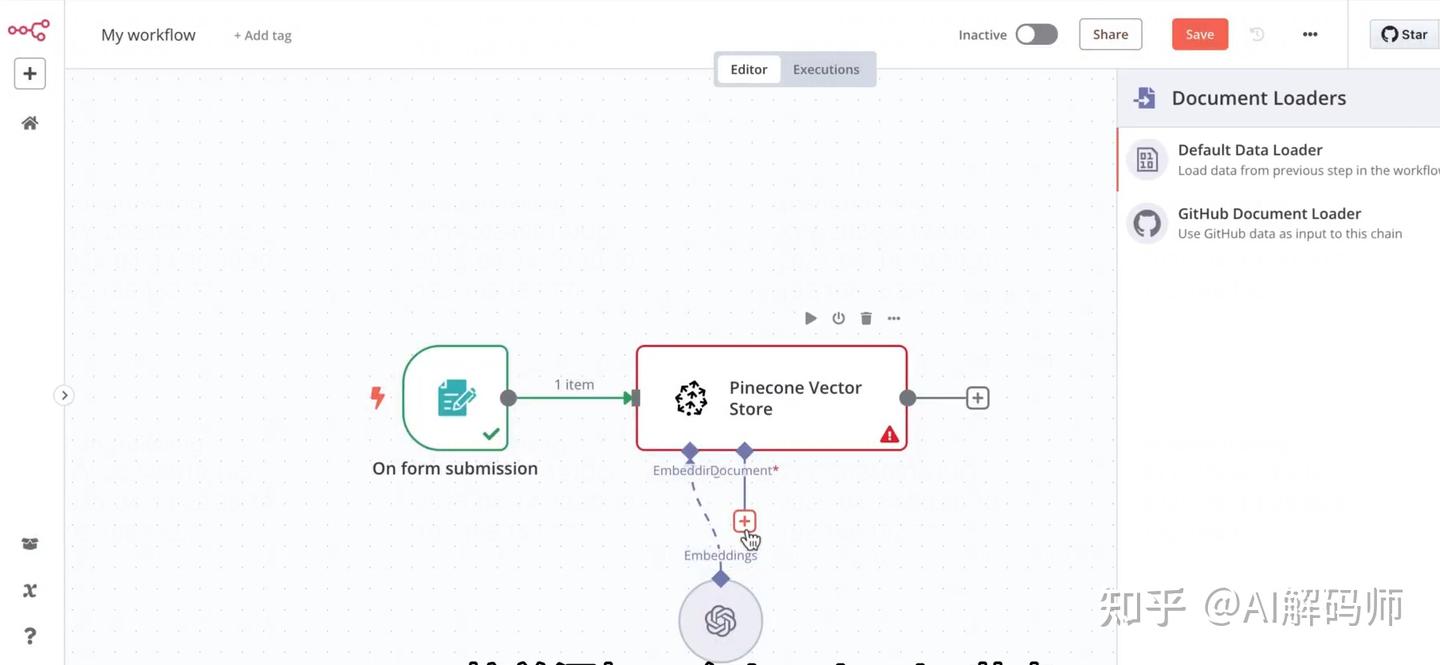
3、添加数据加载与分割节点 (Data Loader & Splitter):
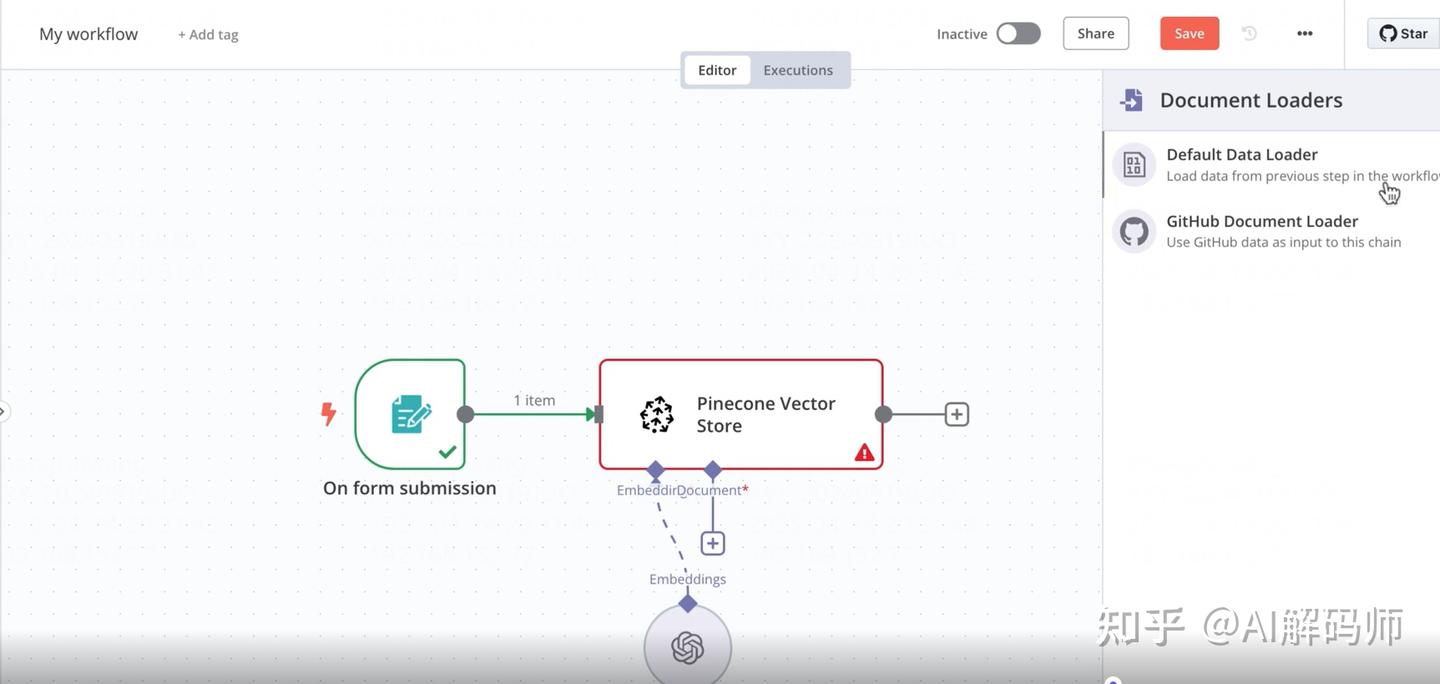
- 添加
Read Binary Files(读取二进制文件) 节点:将表单触发器的输出连接到这个节点。它会读取上传的文件内容。
- 添加
Split Text(文本分割) 或类似功能的节点 (具体节点名称可能随 N8N 版本变化,查找处理文本分块的节点):将Read Binary Files的输出连接到此节点。
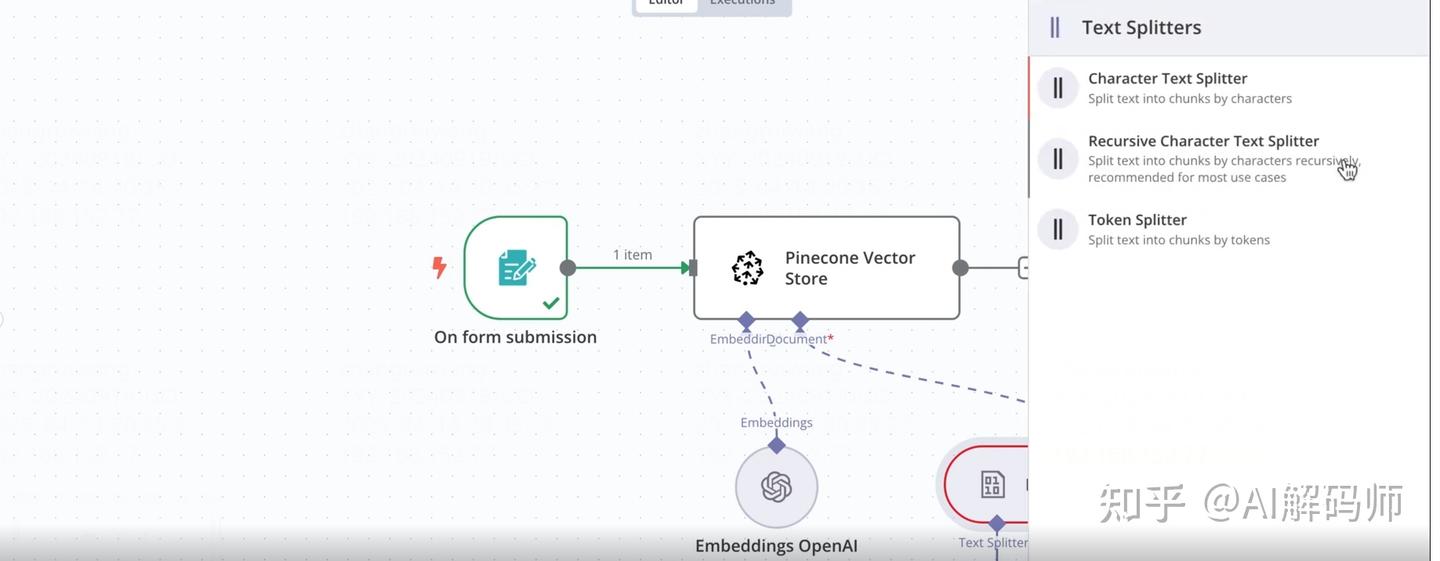
-
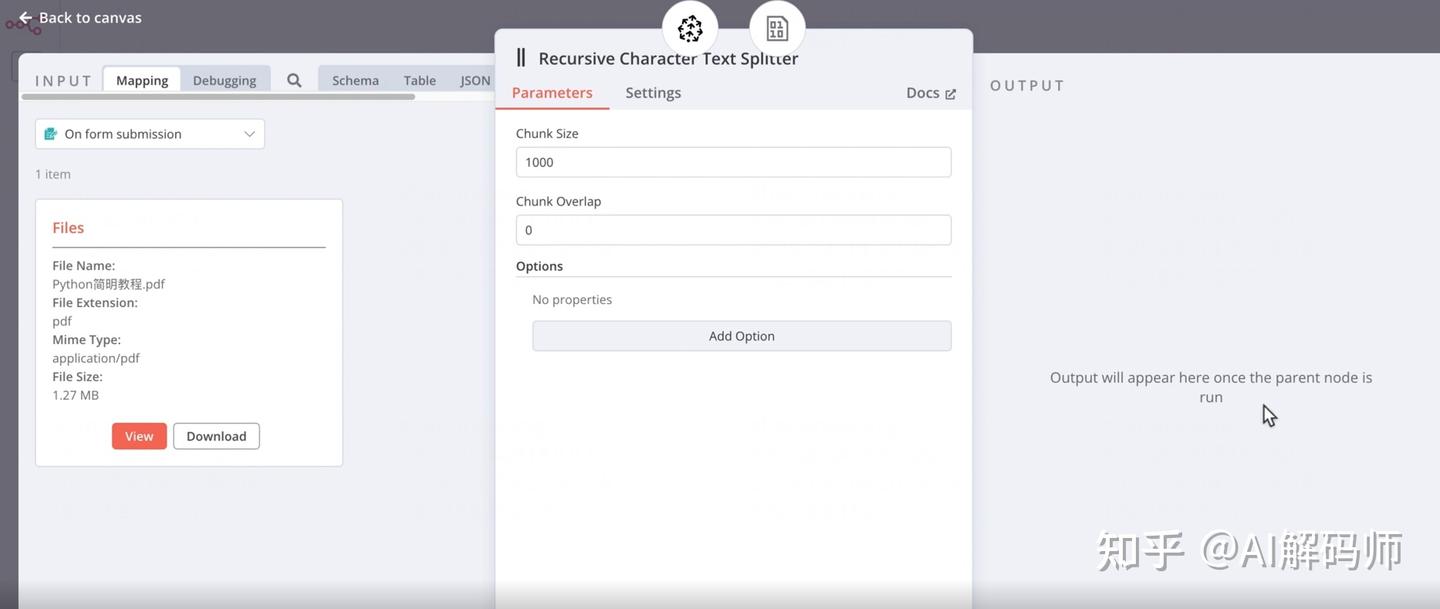
- 这个节点的作用是将大文件内容切分成适合嵌入模型处理的小块 (Chunks)。
Chunk Size: 设置每个文本块的大小(通常以字符数或 Token 数计)。Chunk Overlap: 设置相邻文本块之间重叠的大小。设置一定的重叠有助于保留块与块之间的上下文联系。默认值通常是 0 或一个较小的值。
- (可选) 添加
Set(设置) 或Edit Fields(编辑字段) 节点:在分割后、发送给 OpenAI 节点之前,可以添加一个节点来整理数据结构。特别是,我们需要确保传递给 OpenAI Embedding 节点的输入是文本内容。同时,我们可以在这里添加元数据 (Metadata),比如将文件名附加到每个文本块上。这样存入向量数据库后,我们就能追溯每个向量片段来源于哪个原始文件。- 配置示例:将分割后的文本块映射到名为
text(或 OpenAI 节点期望的输入字段名) 的字段。添加一个metadata字段,其值为一个对象,包含fileName属性,值为来自触发器的文件名。
- 配置示例:将分割后的文本块映射到名为
4、测试与验证:
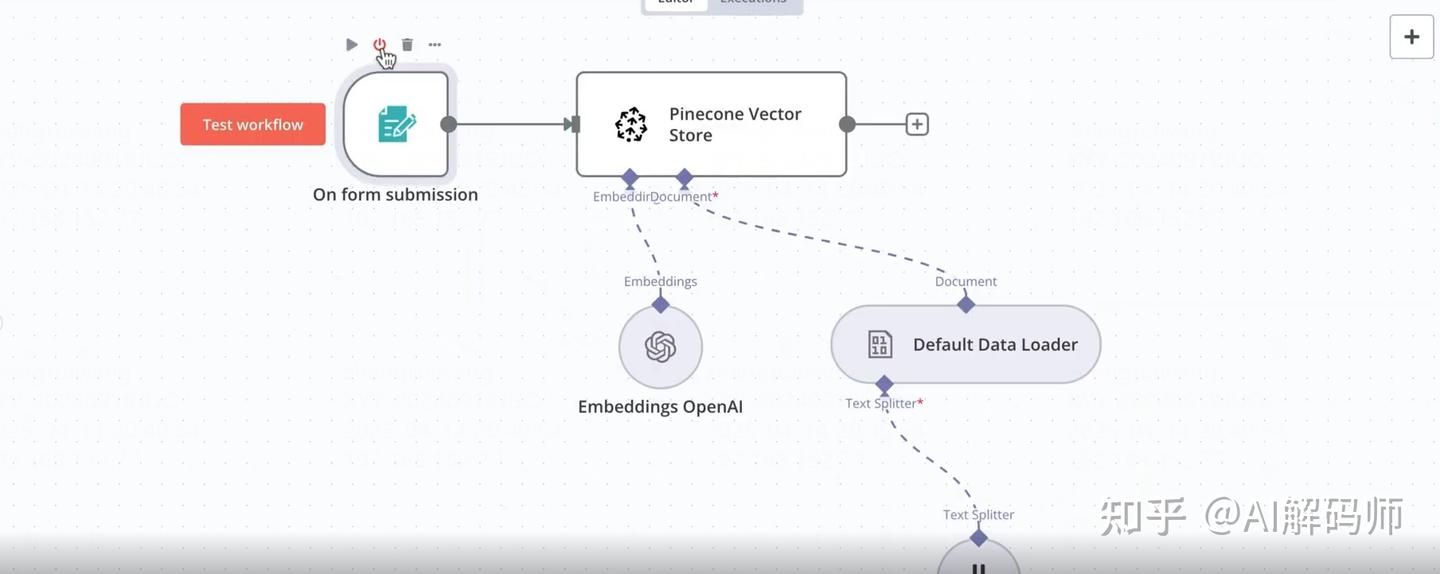
- 激活 (Activate) 这个工作流。
- 回到之前测试表单生成的 URL,上传一个 PDF 文件(比如一个 Python 教程 PDF)。
- 观察 N8N 界面,工作流应该会依次执行。
- 执行成功后,检查
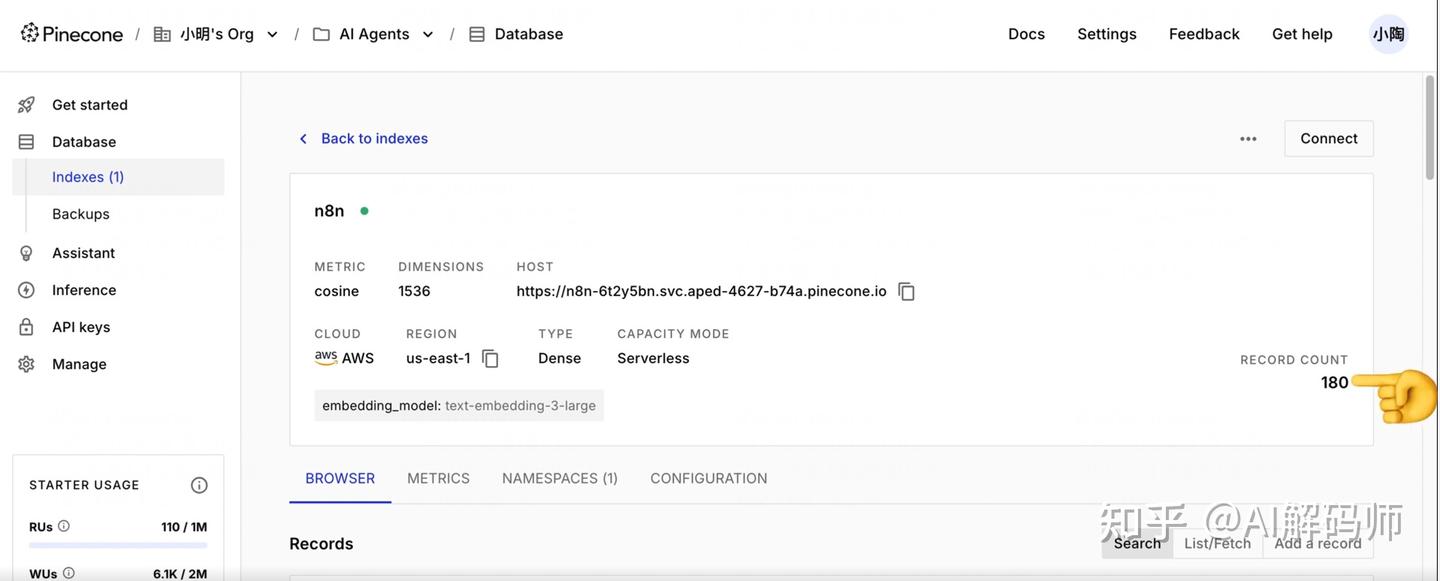
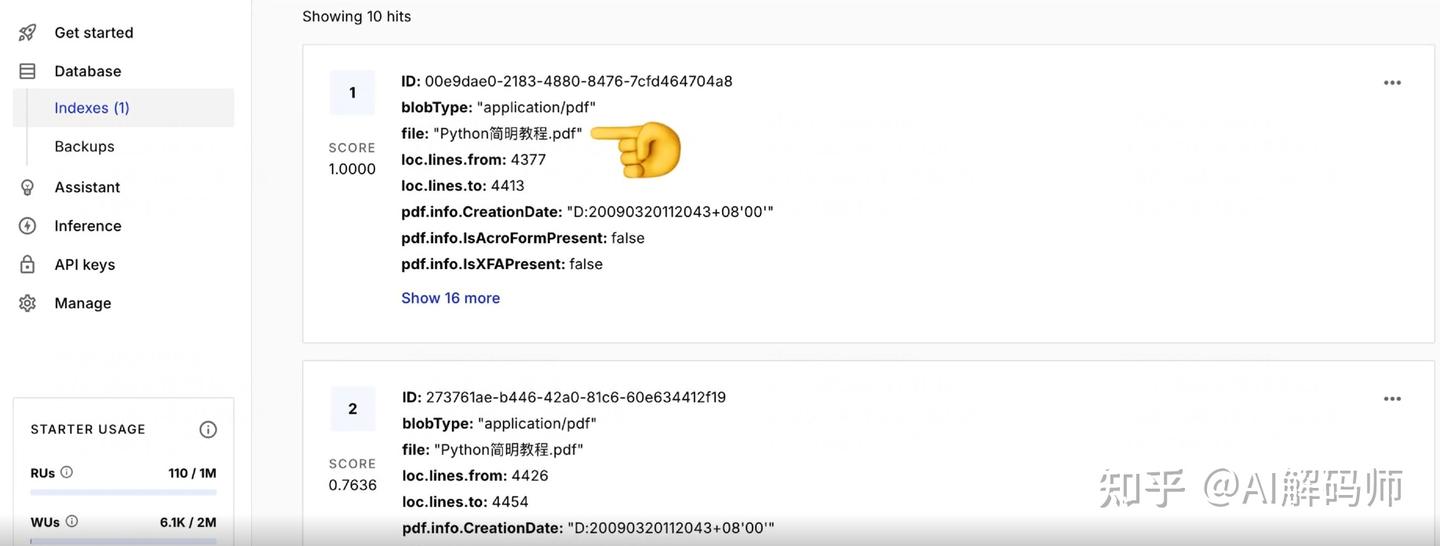
Pinecone节点的输出,可以看到插入操作的结果。 - 登录 Pinecone 控制台,查看你创建的 Index 和 Namespace (
python-programming),应该能看到数据条目被成功写入了。每个条目会包含一个向量和我们之前添加的元数据(如文件名)。 - (Pinecone 免费额度提示):留意 Pinecone 控制台显示的免费额度使用情况,如存储空间、读写次数限制等,对于个人项目通常是足够的。
至此,我们构建知识库的第一条工作流就搭建完成了!
3.2 工作流二:实现 RAG 问答
这条工作流接收用户提问,从 Pinecone 检索相关知识,然后让 LLM 基于这些知识生成回答。
- 添加触发节点 (Trigger Node):
- 选择
On Chat Message(当收到聊天消息时) 或类似的触发器,这允许我们通过 N8N 内置的聊天界面进行测试。
- 选择
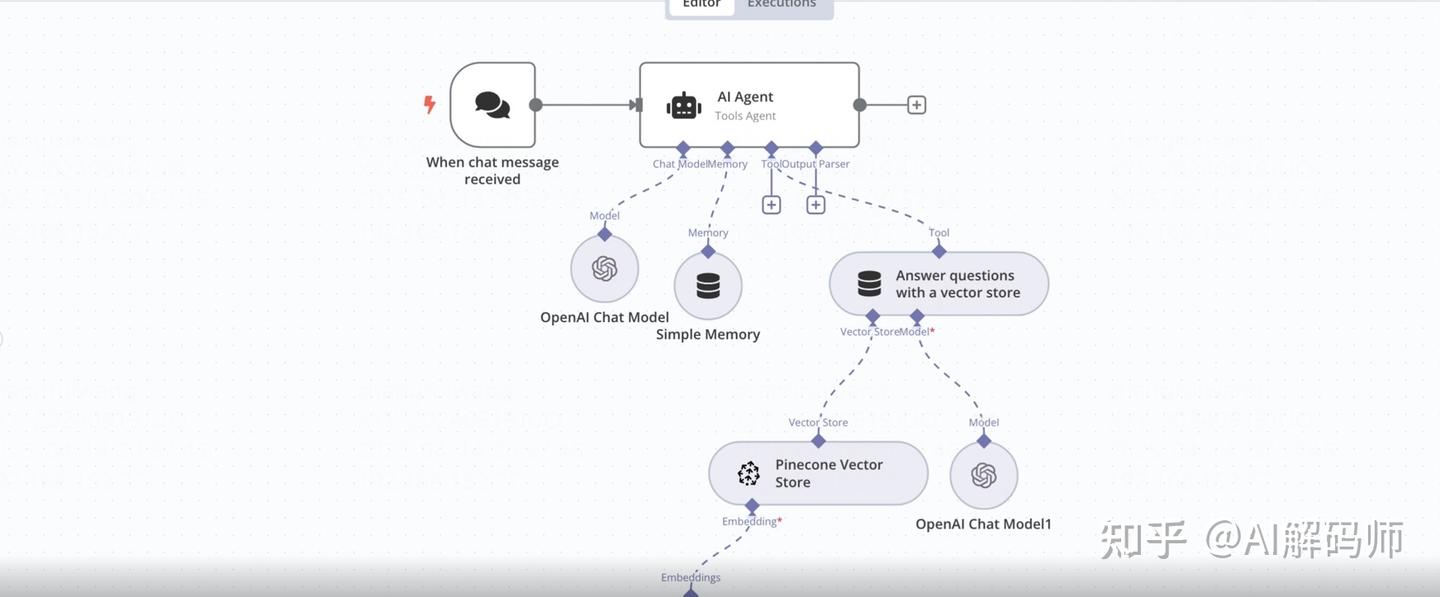
- 添加 AI Agent 节点:
- 搜索并添加
AI Agent节点。这是一个强大的节点,可以协调 LLM、工具 (如向量数据库检索) 和内存。 AI Prompt(AI 提示词):
- 搜索并添加
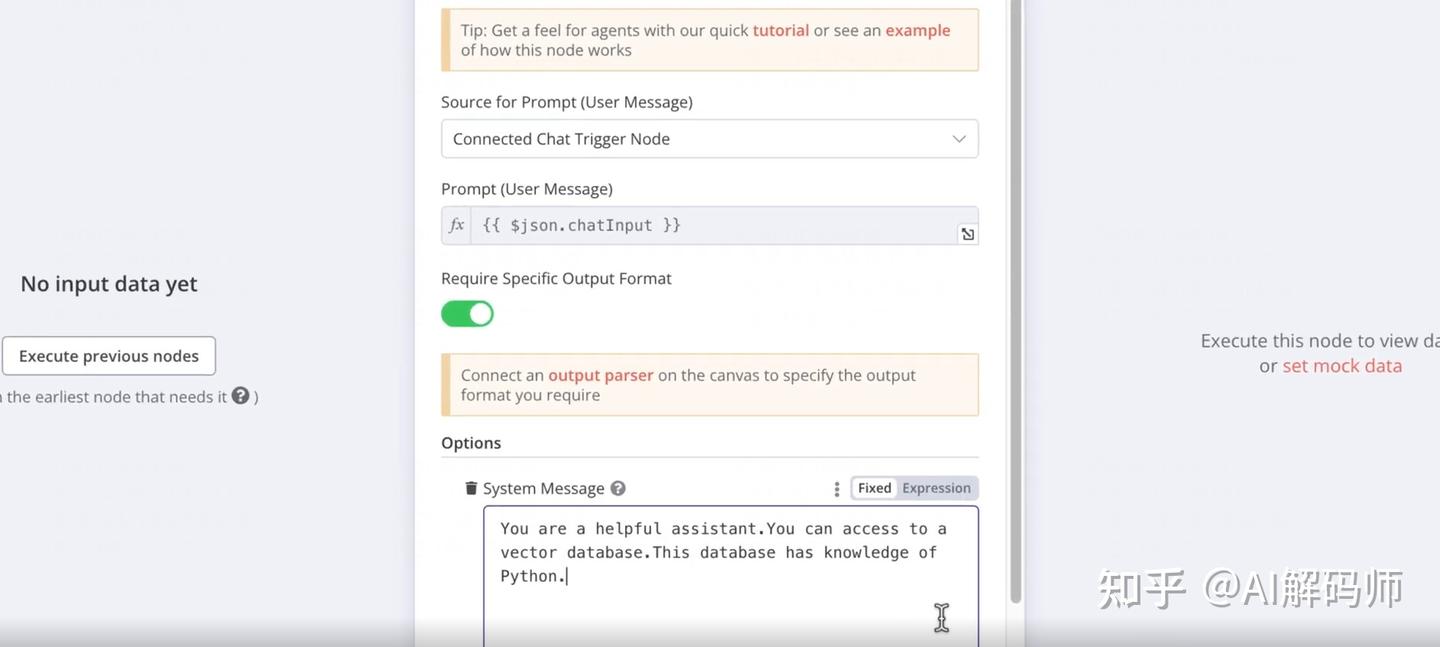
-
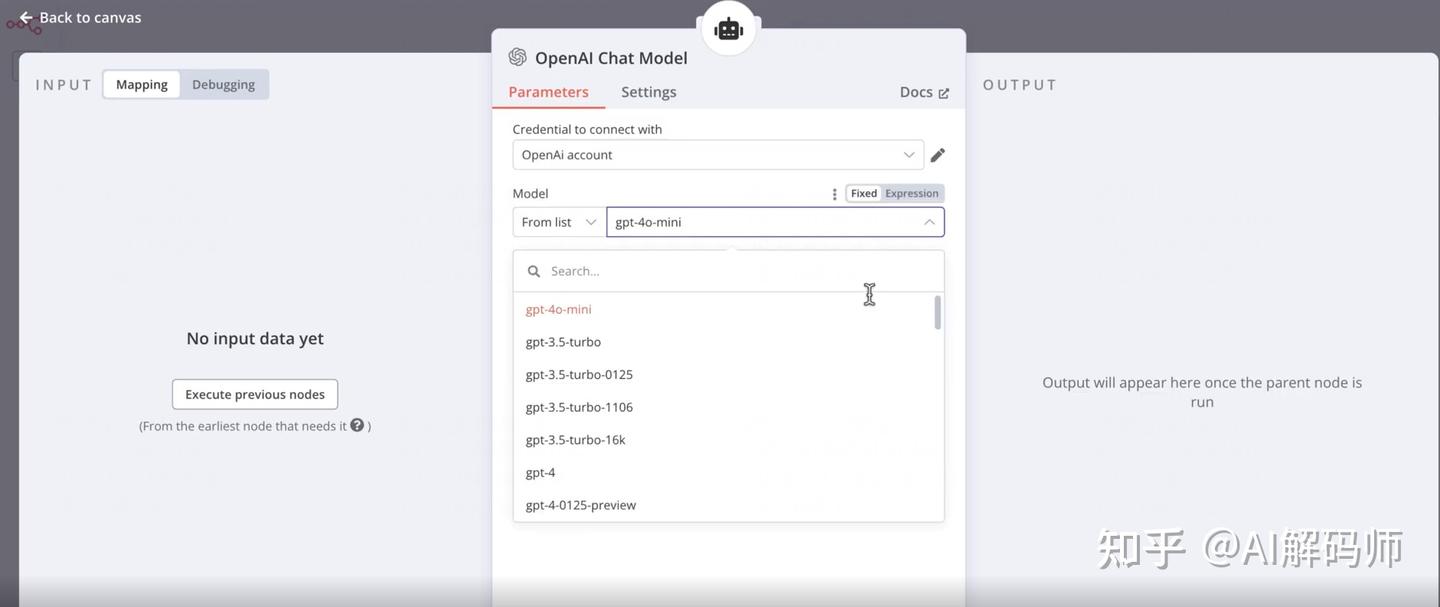
AI Model: 点击Add AI Model。- 选择
OpenAI Chat Model。 Model: 选择一个合适的聊天模型。gpt-4o-mini是一个性价比很高的选择,速度快且能力足够满足 RAG 需求。
- 选择
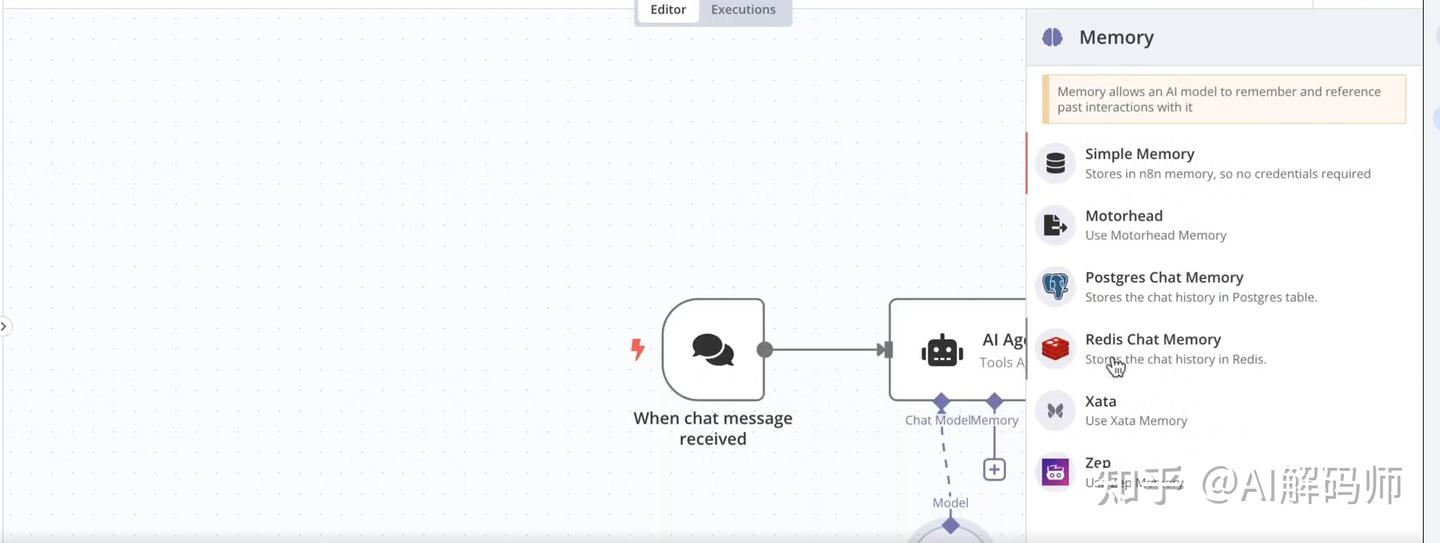
-
Memory: 点击Add Memory。- 选择
Simple Memory。这会保留最近几轮的对话历史,让对话更连贯。
- 选择
- 添加工具 (Tool) - Pinecone 检索:
- 在 AI Agent 节点内,点击
Add Tool。 - 选择
Pinecone。 - 配置 Pinecone 工具:
Credential: 选择之前创建的 Pinecone 凭证。Operation: 选择Query(查询) 或Retrieve Documents(检索文档)。Index Name: 选择我们之前创建的索引n8n-rag-index。Namespace: 输入我们之前使用的命名空间python-programming。Embedding Model: 非常重要! 这里需要配置一个嵌入模型,用于将用户的提问转换为向量,以便在 Pinecone 中进行相似性搜索。- 点击
Add Embedding Model。 - 选择
OpenAI Embedding Model。 - 选择凭证。
Model: 必须选择与数据入库时使用的嵌入模型相同或兼容的模型。我们之前用的是text-embedding-3-small,这里也要选择它。
- 点击
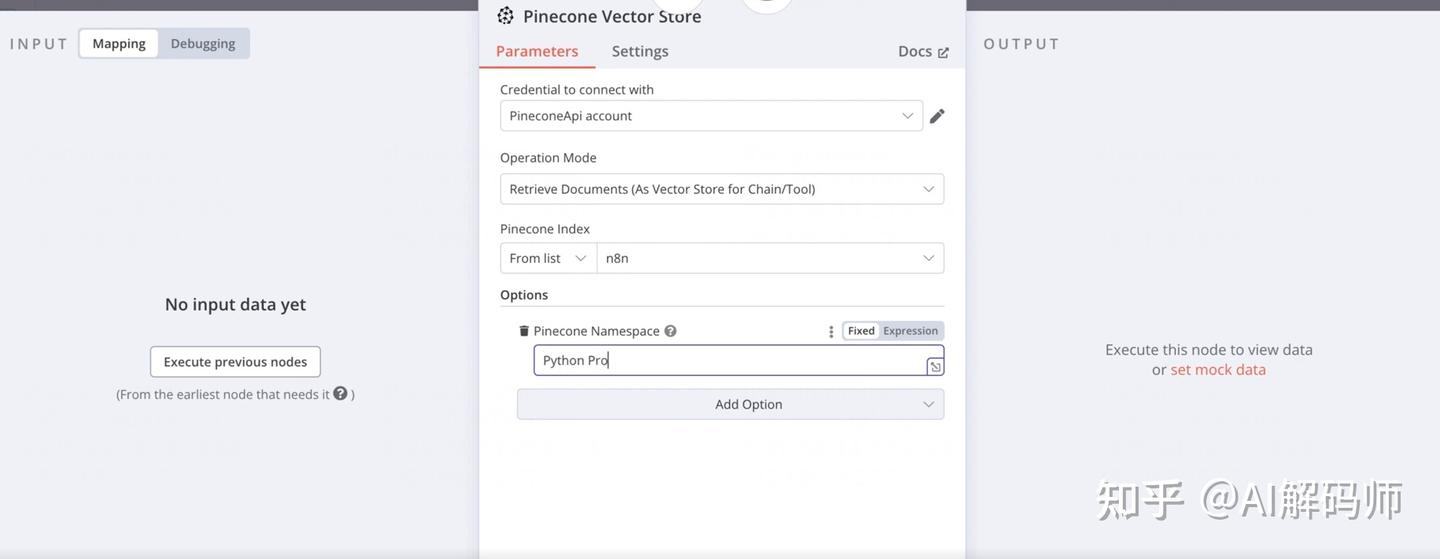
-
Number of Results (Top K): 设置希望从向量数据库检索回多少条最相关的文档片段,比如 3 或 5。
Tool Name: 给这个工具起个名字,比如python_knowledge_retriever。Tool Description: 描述这个工具的作用,帮助 AI Agent 理解何时调用它。例如:"用于从 Python 编程知识库中检索相关信息以回答用户问题"。- (AI Agent 内部的 LLM 调用):AI Agent 会自动处理:当用户提问时,它判断是否需要使用工具。如果需要,它会调用 Pinecone 工具(使用配置好的 Embedding Model 对问题编码,然后在 Pinecone 查询),获取检索结果,然后将原始问题和检索到的上下文一起发送给配置好的
AI Model(gpt-4o-mini) 来生成最终答案。 - 修复节点配置问题:如果在配置过程中遇到类似 "data name 字段不能使用空格" 的错误提示,根据提示修改对应字段的名称,去除空格或使用下划线等。仔细检查所有配置项是否符合要求。
- 测试工作流:
- 激活 (Activate) 这个工作流。
- 点击 N8N 右上角的聊天图标 (Chat Panel)。
- 在聊天框中输入一个与你上传的知识库内容相关的问题。例如,如果上传了 Python 教程,可以问:“在 Python 中字典 (dictionary) 数据结构如何使用?”
- 观察 N8N,工作流应该开始执行。AI Agent 会调用 Pinecone Tool,然后调用 LLM。
- 执行成功后,你应该会在聊天框中收到一个由 LLM 生成的、结合了知识库信息的回答。比如,关于 Python 字典的回答会很全面,可能包括创建、访问、添加、删除、遍历等操作方法,这些信息很可能就是从你上传的 PDF 中检索出来的。
四、 总结与展望
到这里,我们已经成功使用 N8N 搭建了一个基本的 RAG 系统!它包括了数据处理入库和 RAG 问答两条核心工作流。
与某些开箱即用的知识库工具(如原稿提到的“Cherry studio”可能是指类似 Chatbase、Dify 等平台)相比,这种用 N8N 搭建的方式提供了极高的灵活性。你可以自由组合不同的嵌入模型、向量数据库和大语言模型,并且对数据处理流程有完全的控制权。
最激动人心的是,这个 RAG 核心只需要稍作调整,就能集成到各种实际应用场景中。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









