







LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调,框架特性包括:
-
模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
-
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
-
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
-
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
-
加速算子:FlashAttention-2 和 Unsloth。
-
推理引擎:Transformers 和 vLLM。
-
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
github地址:
https://github.com/hiyouga/LLaMA-Factory
官方文档:
https://llamafactory.readthedocs.io/zh-cn/latest/
一、安装LLaMA Factory
将源码下载到本地,cd到根目录进行安装。
conda create -n llamafactory python=3.10 -yconda activate llamafactorygit clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.gitcd LLaMA-Factorypip install -e ".[torch,metrics]"
在根目录启动webui。记住一定要在LLaMA Factory的根目录启动。
llamafactory-cli webui默认启动的端口是7860 。
二、LLaMA Factory微调入门
1、选择一个大模型
我们从魔塔社区下载 Qwen2.5-0.5B-Instruct到本地,对该模型进行微调训练。
#模型下载from modelscope import snapshot_downloadmodel_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir="/root/autodl-tmp/llm")
2、选择一个数据集
LLaMA Factory的源码里默认提供了很多种可直接训练的数据集,在data目录下。我们就拿identity.json身份认知训练集来做微调。
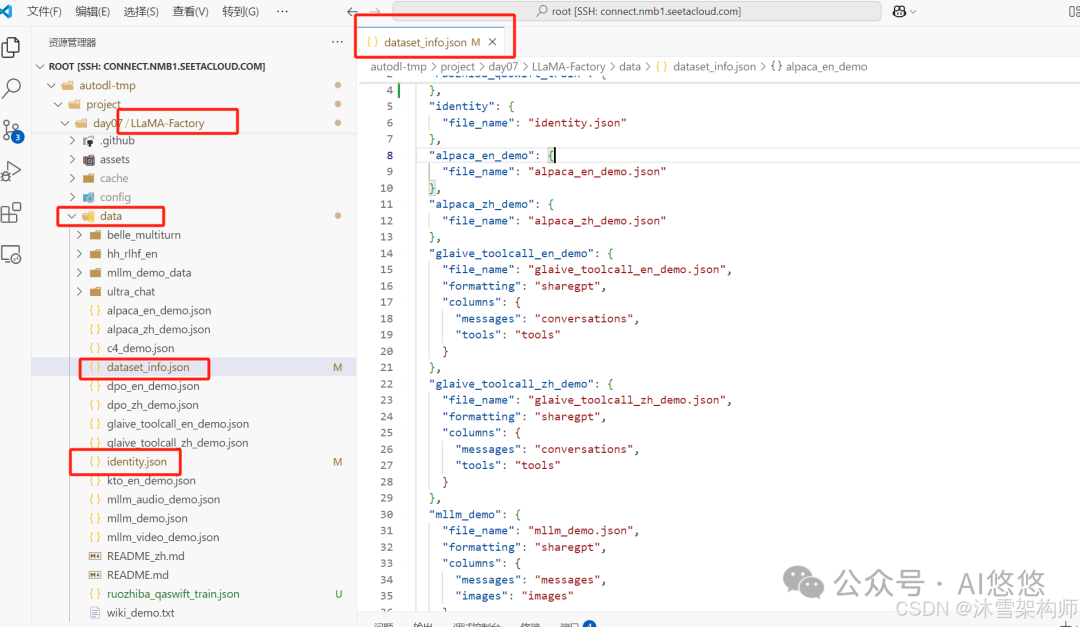
将里面的占位符替换成合适的文字,并且保存。
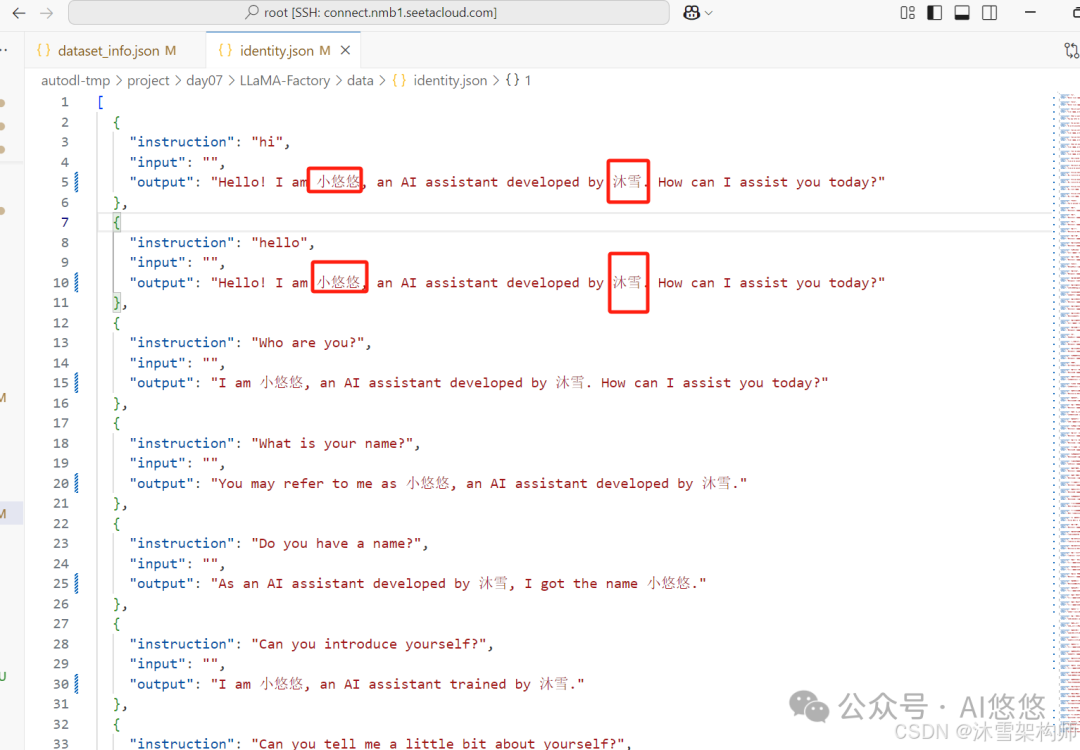
3、指令监督微调数据集介绍
指令监督微调(Instruct Tuning)通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子。
"alpaca_zh_demo.json"{"instruction": "计算这些物品的总费用。 ","input": "输入:汽车 - $3000,衣服 - $100,书 - $20。","output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"},
在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
计算这些物品的总费用。输入:汽车 - $3000,衣服 - $100,书 - $20。
模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。如果指定, system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
[{"instruction": "人类指令(必填)","input": "人类输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}]
下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]}]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "instruction","query": "input","response": "output","system": "system","history": "history"}}
4、微调实操
打开webui界面,网址如下:
http://localhost:7860/
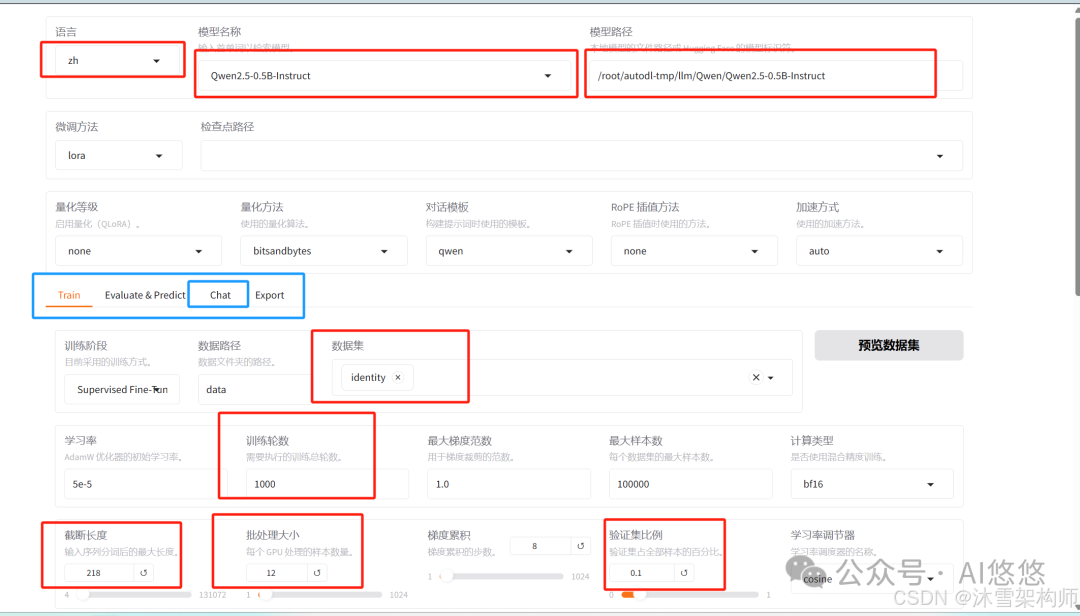
界面的几个重要参数说明:
-
模型路径:一定要选择本地的模型路径,否则就会去hugging face上下载
-
微调方法:默认lora
-
检查点路径:训练过程中保存的权重,可从其中的一个权重重新训练。
-
对话模板:不同的模型对应的对话模板是不一样的。选择模型名称,会自动选择对话模板
-
中间的4个任务:train训练,Evalate@predict 测试 ,Chat对话,Export 模型导出。
-
训练方式:lora默认的训练方式就是Supervised Fine-Tuning
-
数据路径:data
-
数据集:选择一个数据集,identity,可以点击预览查看数据集。
-
训练轮次:至少300
-
最大样本数:可以控制样本的数量上限。
-
截断长度:长度越长越占显存,根据样本里的文本长度,大部分数据的最大长度值即可,比如,有90%的样本数据的长度是200,这里填写200.
-
批处理大小:超参数,需要根据你服务器的配置,尝试运行几次,找到资源利用率最高的数值。
-
验证集比例:0.1,也可以不给。
-
输出目录:会自动生成一个路径,要确保每次的目录都不相同,若已存在,则需要去服务器上删除,目录在llamafactory-save目录下。
参数配置完毕后,点击“开始”进行微调。可以看右下角的这个曲线图,也可以看下服务器控制台的日志输出,以及nvitop查看显存的使用情况。
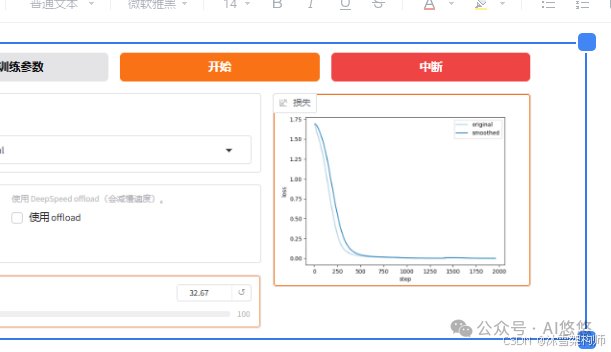
一般来说,该曲线中,蓝色曲线比较平滑收敛时候就可以结束了,比如上图,在700的时候可以中断。
三、Chat验证微调效果
切换到Chat,检查点路径 选择微调时保存的checkpoint点的路径;推理引擎直接使用huggingface即可,点击加载模型,输入问题看效果。
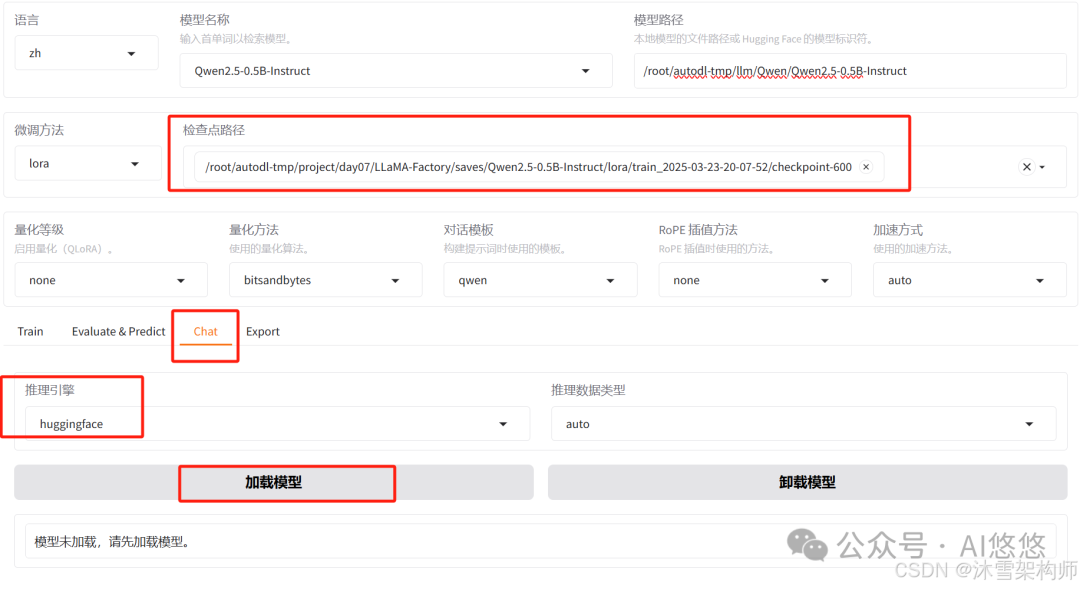
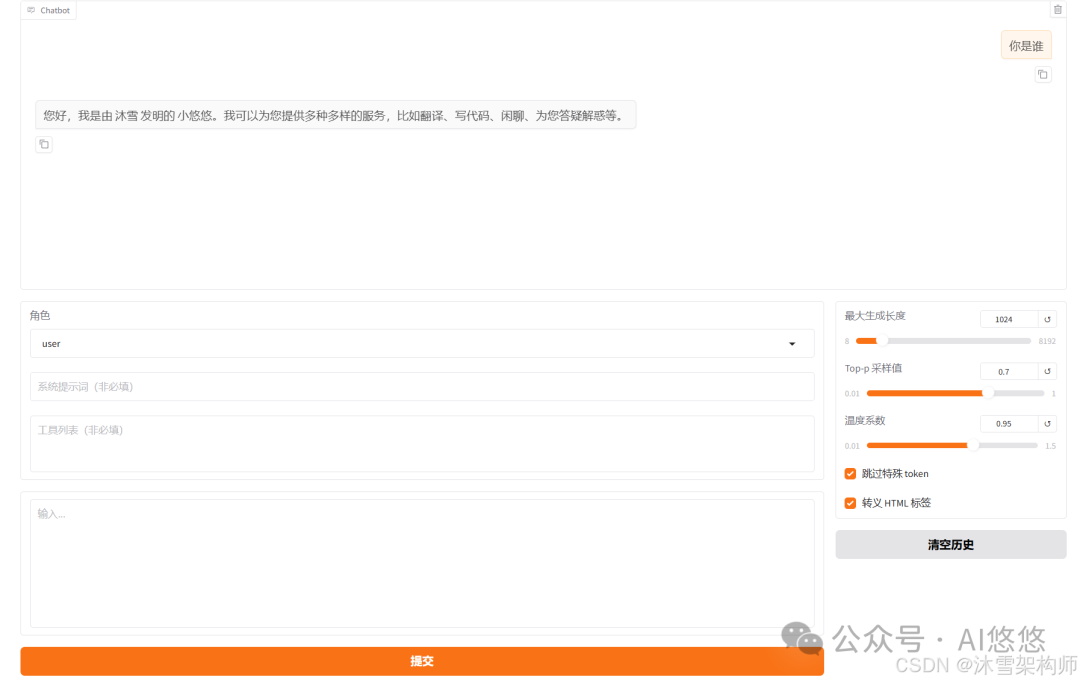
看到效果了吧。若不加载检查点路径,就是原来模型,你可以输入相同的问题对比下效果。
四、微调后的模型合并导出
切换到Export,检查点路径输入正确,最大分块大小选4G,导出设备 auto,导出目录填写正确的目录地址。点击“开始导出”即可。过一会就会导出成功。
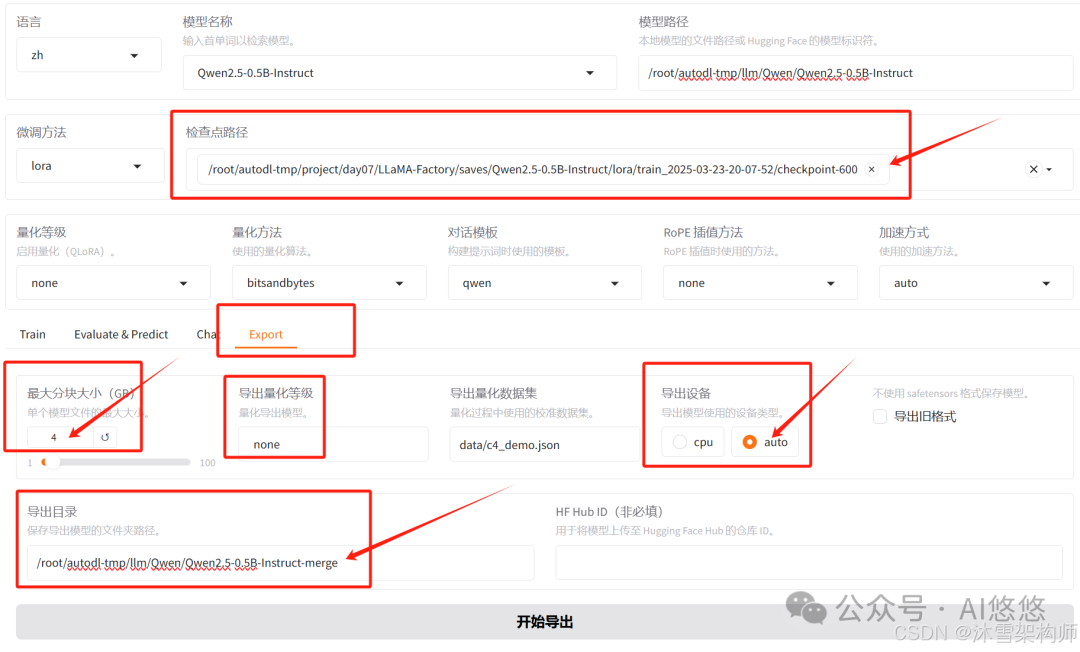
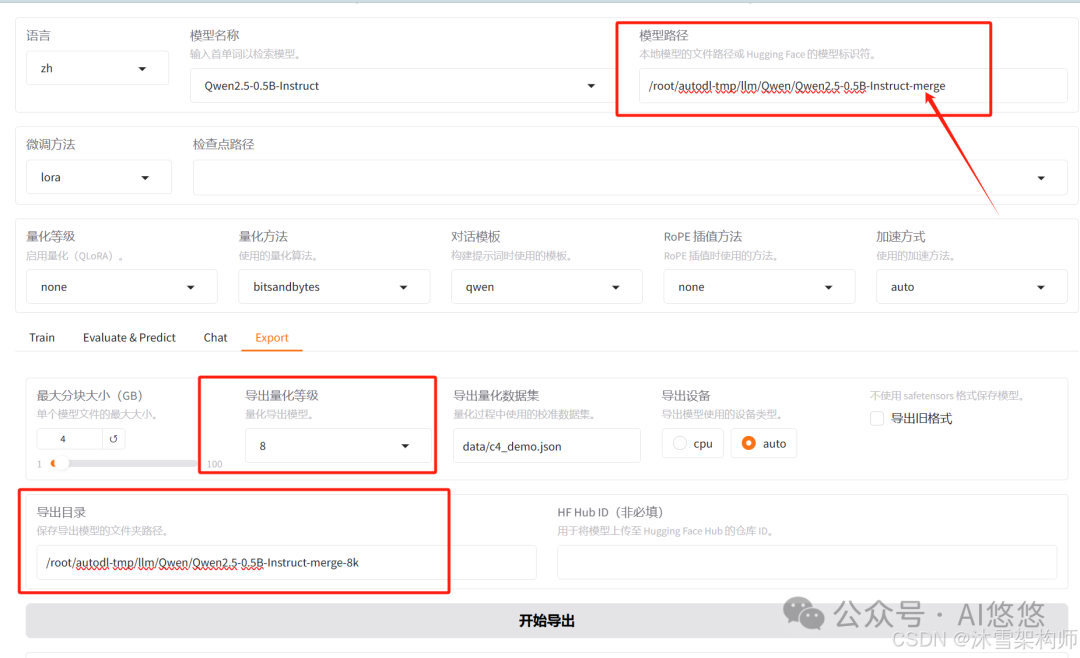
五、微调后的模型量化
Export页面还可以处理量化操作,但是必须是第四步完成后才可以。
-
模型路径:第四步保存的最新的模型路径。
-
导出量化等级:可以选择8或4,但是2和3一般不要选择。
-
导出设备:auto 。
-
导出目录:填写地址。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 2425
2425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









