






前言
小伙伴们五一快乐鸭,Qwen3已经发布好几天,热度依然不减;五一期间笔者尝试在本地体验Qwen3的能力,将所有过程分享给大家,大家一起动手试一试,一起玩转Qwen3;
当然除了本地这种模式,也可以选择云端的API,这里就不赘述了。

知识点
通过本文大家需要掌握以下知识点
- Qwen3 相关知识
- Ollama
- Open WebUI (一个和ChatGPT类似的聊天的Web页面,支持ollama)
- MCP 相关知识
MCP相关知识可以看这里: xxxx
Qwen3
阿里推出 Qwen3,这是 Qwen 系列大型语言模型的最新成员。我们的旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
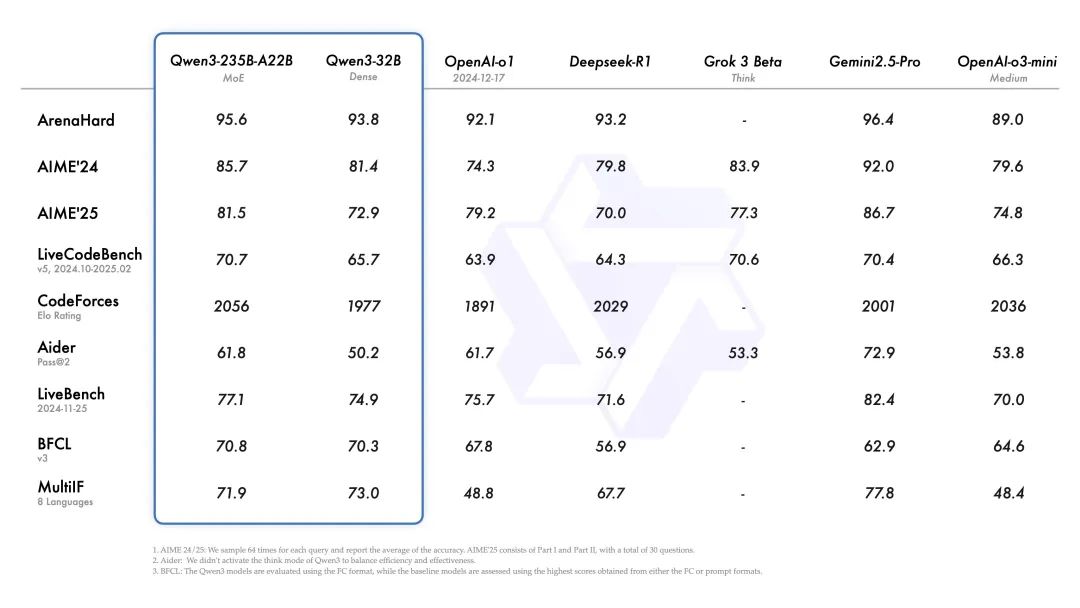
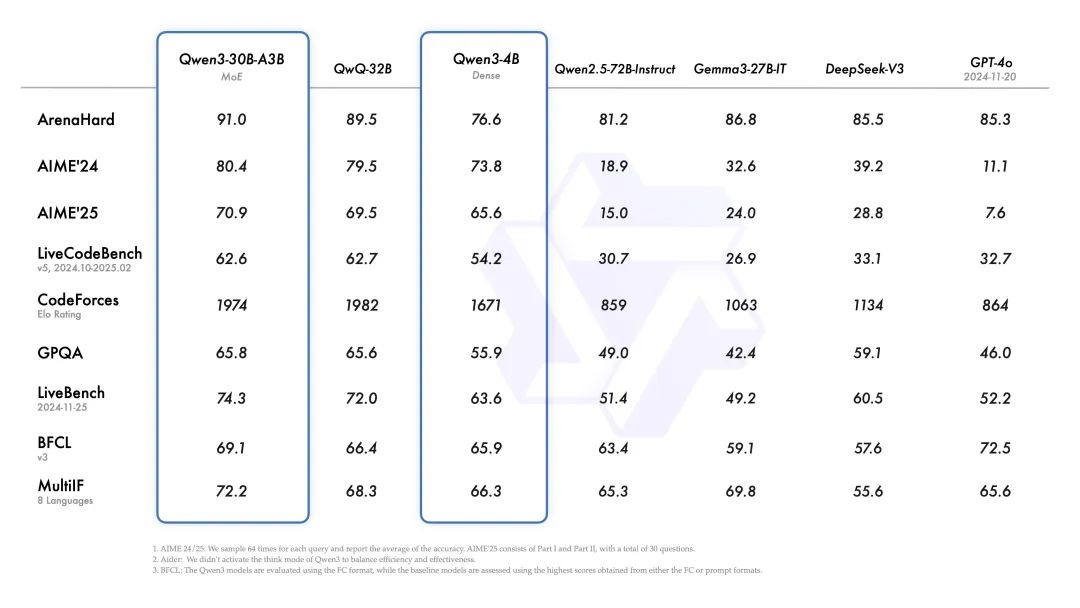
开源了两个 MoE 模型的权重:Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。此外,六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
| Models | Layers | Heads (Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
| Models | Layers | Heads (Q / KV) | # Experts (Total / Activated) | Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 28K |
经过后训练的模型,例如 Qwen3-30B-A3B,以及它们的预训练基座模型(如 Qwen3-30B-A3B-Base),现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,我们推荐使用 SGLang 和 vLLM 等框架;而对于本地使用,像 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 这样的工具也非常值得推荐。这些选项确保用户可以轻松将 Qwen3 集成到他们的工作流程中,无论是用于研究、开发还是生产环境。
官网地址:https://qwenlm.github.io/zh/blog/qwen3/ 下文将使用Ollama进行Qwen3本地化
Ollama
Ollama 是一个轻量级、用户友好的框架,旨在让用户在本地运行开源大型语言模型,如 Llama 3、DeepSeek-R1、Gemma、Mistral、Qwen 等。它通过 Modelfile 将模型权重、配置和数据打包成一个统一包,类似于 Docker 镜像的概念,优化了模型的设置和 GPU 使用。Ollama 的核心优势在于隐私性、灵活性和离线可用性,特别适合对数据安全有高要求的场景。
主要特点
本地运行:
- 所有数据处理都在本地进行,无需将敏感数据发送到云端,保障隐私和安全。
- 支持离线使用,无需互联网连接即可运行模型,适合无网络环境下的应用。
广泛的模型支持:
- 支持多种开源模型,包括 Llama 3.2、Gemma 2、Mistral、Codestral 等,适用于文本生成、代码生成、翻译等任务。
- 用户可从官方模型库拉取预训练模型,或通过 Modelfile 创建自定义模型。
跨平台兼容性:
- 支持 macOS、Linux 和 Windows(Windows 支持为预览版)。
- 可在本地设备或虚拟专用服务器(VPS)上运行,适合个人项目或团队协作。
用户友好的接口:
- 主要通过命令行界面(CLI)操作,适合技术用户快速拉取、运行和管理模型。
- 支持第三方图形用户界面(如 Open WebUI),提供更直观的操作体验。
API 集成:
- 提供 REST API,支持 Python、JavaScript 等编程语言集成。
- 与 LangChain、LlamaIndex 等框架无缝集成,方便构建复杂 AI 应用。
安装和使用步骤
下载和安装:访问 Ollama 官网 或 GitHub 页面,下载适用于您操作系统的安装包。 Linux 和 macOS 用户可通过以下命令快速安装:
curl -fsSL https://ollama.com/install.sh | sh
Windows 用户需下载安装程序并按提示操作。
拉取模型:
使用 CLI 拉取所需模型,例如:
ollama pull llama3.2
可从 Ollama 模型库 查看可用模型。
运行模型:
通过命令运行模型并直接交互:
ollama run llama3.2
输入提示(如“解释机器学习基础”),模型将生成响应。
API 调用:
启动 Ollama 服务器:
ollama serve
使用 cURL 或编程语言调用 API,例如:
curl http://localhost:11434/api/generate -d '{"model": "llama3.2", "prompt": "Why is the sky blue?"}'
相关资源
官方网站:https://ollama.com/ GitHub 仓库:https://github.com/ollama/ollama 模型库:https://ollama.com/library 社区支持:Ollama 的 Discord 社区或 GitHub Issues 页面
Ollama 是一个强大的工具,通过简化本地运行大型语言模型的流程,为用户提供了隐私、安全和灵活的 AI 解决方案。无论您是想开发 AI 应用、进行研究,还是仅想探索开源模型的潜力,Ollama 都是一个值得尝试的平台。通过其 CLI、API 和丰富的模型支持,您可以轻松将尖端 AI 技术带到本地设备上。
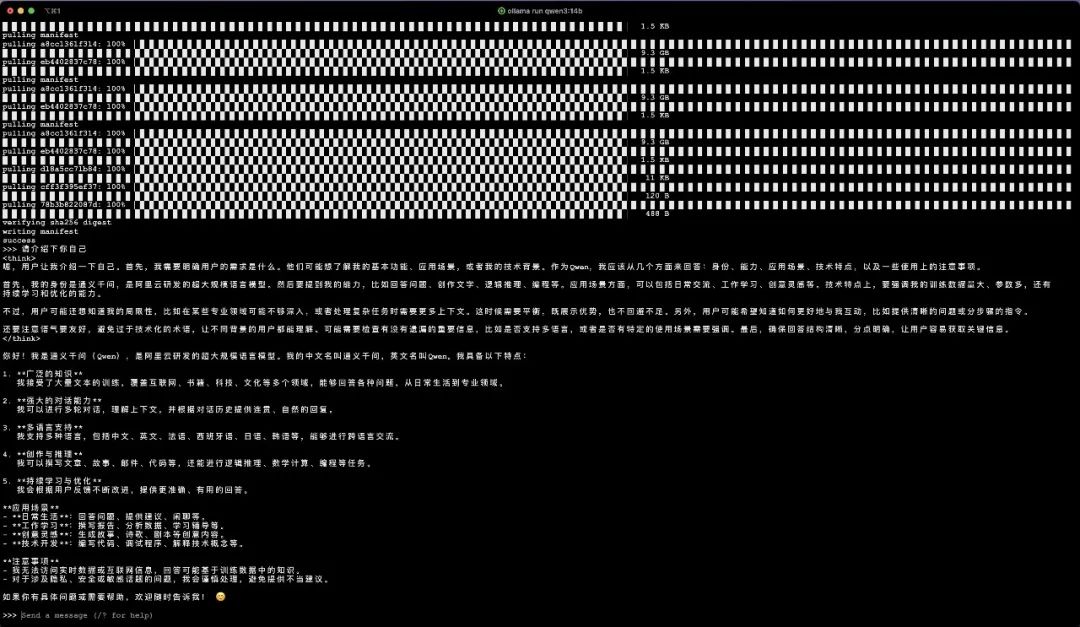
Ollama安装Qwen3
通过对ollama的学习,我们已经知道如何通过它安装模型,以下是安装Qwen3的命令
ollama run qwen3:14b
在ollama官网 Qwen3提供了
- 0.6b
- 1.7b
- 4b
- 8b
- 14b
- 30b
- 32b
- 235b
笔者的运行情况如下

当然你要运行其他模型可以在这里查找: https://ollama.com/search
Open WebUI
Open WebUI 是一个自托管的 Web 界面,旨在简化与大型语言模型的交互。它通过直观的 GUI 提供对模型的管理、配置和使用支持,特别适合希望在本地或私有环境中运行 AI 的用户。Open WebUI 支持多种模型运行器(如 Ollama)和 OpenAI 兼容的 API,并内置了检索增强生成(RAG)功能,可通过文档或网页增强模型的响应质量。它的核心优势包括完全离线运行、强大的扩展性和社区驱动的开发模式。
这里我本地运行qwen3:14已经能正常显示,可以用这个模型进行沟通对话
Open WebUI 的设计目标是“将 AI 技术普及化”,通过降低技术门槛,让非技术用户也能轻松使用尖端 AI 模型,同时为开发者提供灵活的定制选项。
Github地址:https://github.com/open-webui/open-webui
它提供了Docker等安装方式,笔者因为之前用过,使用的是本地源码运行;故之类不展示如何运行,更多资料参考官网地址。
Open WebUI支持MCP
最新版本的Open WebUI已支持MCP
Open WebUI开放了mcpo代理服务器(全称为MCP-to-OpenAPI proxy server),该协议允许你通过标准的 REST/OpenAPI 接口,直接使用基于 MCP(Model Context Protocol,模型上下文协议)实现的工具服务器——无需处理陌生或复杂的自定义协议。
如果你是终端用户或应用开发者,这意味着你可以通过熟悉的 REST 风格接口,轻松地与强大的 MCP 工具进行交互。
我们按照官方示例运行如下代码:
uvx mcpo --port 8010-- uvx mcp-server-time --local-timezone=America/New_YorkStarting MCP OpenAPIProxy on 0.0.0.0:8010with command: uvx mcp-server-time --local-timezone=America/New_YorkINFO:Started server process [5752]INFO:Waitingfor application startup.INFO:Application startup complete.INFO:Uvicorn running on http://0.0.0.0:8010 (Press CTRL+C to quit)
这段代码的意思在本地起一个时间转换的MCP服务;可以通过Open WebUI直接调用这个服务,为用户进行服务 如果你想自定义MCP服务,请参考这里: https://docs.openwebui.com/openapi-servers/mcp/
在Open WebUI配置在web页面的设置中,选择“tools” 配置上面启动的地址+端口就行

在配置好大模型(选择Qwen3模型)后,在聊天框中会出现工具图标,点击该图标,显示如下:

这表明我们基于MCP的工具服务已连接成功。
在Open WebUI进行对话,如下:
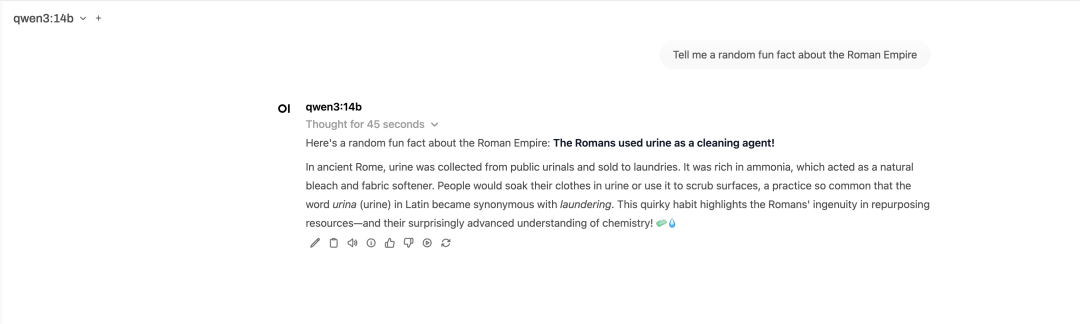
从上述的对话中可以看到,大模型调用了基于MCP的gutcurrenttime工具,并给出了正确回复。
总结
通过将 Qwen3 与 Ollama 结合进行本地部署,我成功体验了 MCP(模型-计算-平台)架构的强大潜力。这一过程不仅让我深入了解了 Qwen3 作为开源大型语言模型的卓越性能,还展示了 Ollama 在简化本地模型运行方面的便捷性和灵活性。从安装 Ollama、拉取 Qwen3 模型到优化硬件配置,整个部署流程清晰且高效,尤其适合注重数据隐私的开发者与企业用户。
在实际使用中,Qwen3 展现了出色的自然语言处理能力,无论是文本生成、问答还是代码补全,都表现得游刃有余。Ollama 的命令行界面和 API 支持让模型管理与集成变得简单,而其对 GPU 加速的优化显著提升了推理速度。通过 Open WebUI 的图形界面,我进一步体验了用户友好的交互方式,RAG 功能更是为定制化知识查询提供了便利。
然而,本地部署也面临一些挑战,例如硬件要求较高(推荐 16GB+ RAM 和独立 GPU)以及模型文件占用较大存储空间。对于初学者,配置环境和调试可能需要一定学习成本,但 Ollama 的文档和活跃社区提供了充足支持。
总的来说,Qwen3 与 Ollama 的组合为本地 AI 部署提供了高效、隐私安全的解决方案。无论是用于开发、研究还是个人探索,这一初体验让我对本地化 AI 应用的未来充满期待。未来,我计划进一步探索 Qwen3 的微调功能,并结合更复杂的 RAG 场景,为实际项目打造更强大的 AI 能力。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









