






随着,ChatGPT 迅速爆火,引发了大模型的时代变革。然而对于普通大众来说,进行大模型的预训练或者全量微调遥不可及。由此,催生了各种参数高效微调技术,让科研人员或者普通开发者有机会尝试微调大模型。
因此,该技术值得我们进行深入分析其背后的机理,之前分享了大模型参数高效微调技术原理综述的文章。下面给大家分享大模型参数高效微调技术实战系列文章,相关代码均放置在GitHub:llm-action。
本文为大模型参数高效微调技术实战的第七篇。本文将结合使用 LoRA 来训练用于图生文的blip2-opt-2.7b模型。
数据集和模型准备
数据集使用6名足球运动员的虚拟数据集,带有可用于微调任何图像描述模型的文字说明。数据集下载地址:https://huggingface.co/datasets/ybelkada/football-dataset
image.png
模型为利用 OPT-2.7B 训练的 BLIP-2 模型,其由三个模型组成,下面会详细介绍,模型下载地址:https://huggingface.co/Salesforce/blip2-opt-2.7b
BLIP-2 简介
BLIP-2 通过利用预训练的视觉模型和语言模型来提升多模态效果和降低训练成本,预训练的视觉模型能够提供高质量的视觉表征,预训练的语言模型则提供了强大的语言生成能力。如下图所示,由一个预训练的 Image Encoder,一个预训练的 Large Language Model 和一个可学习的 Q-Former 组成。
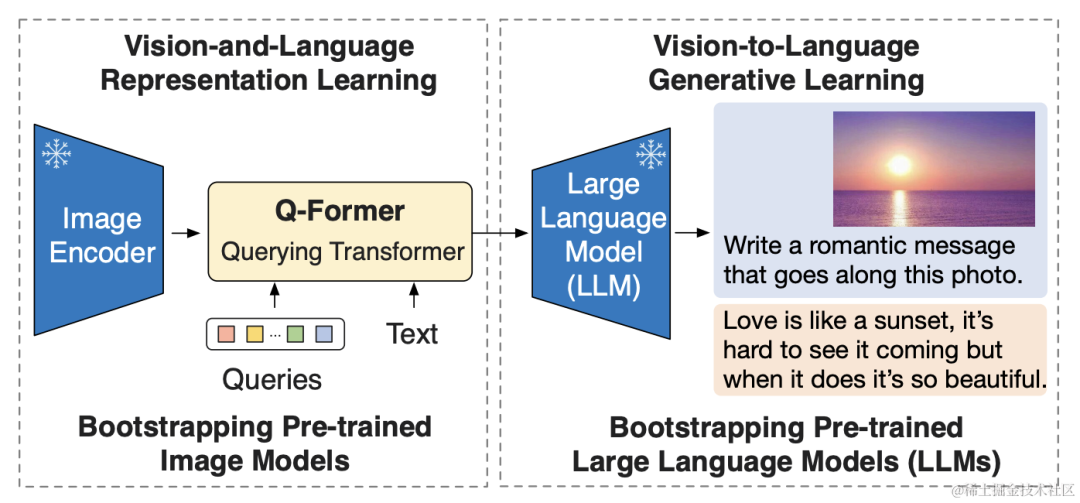
image.png
-
Image Encoder:负责从输入图片中提取视觉特征。
-
Large Language Model:负责文本生成。
-
Q-Former:负责弥合视觉和语言两种模态的差距,由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层,如下图所示。
-
Image Transformer通过与图像编码器进行交互提取视觉特征,它的输入是可学习的 Query,这些Query通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互,还可以通过共享的自注意力层与文本进行交互。
-
Text Transformer作为文本编码器和解码器,它的自注意力层与Image Transformer共享,根据预训练任务,应用不同的自注意力掩码来控制Query和文本的交互方式。
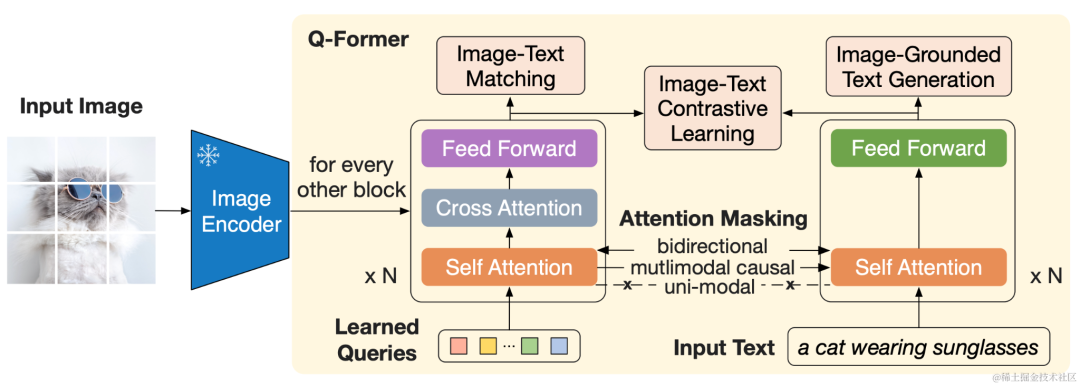
image.png
为了减少计算成本并避免灾难性遗忘的问题,BLIP-2 在预训练时冻结预训练图像模型和语言模型,但是,简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐,为此BLIP-2提出两阶段预训练 Q-Former 来弥补模态差距:表示学习阶段和生成学习阶段。
表示学习阶段
在表示学习阶段,将 Q-Former 连接到冻结的 Image Encoder,训练集为图像-文本对,通过联合优化三个预训练目标,在Query和Text之间分别采用不同的注意力掩码策略,从而控制Image Transformer和Text Transformer的交互方式。
生成学习阶段
在生成预训练阶段,将 Q-Former连接到冻结的 LLM,以利用 LLM 的语言生成能力。这里使用全连接层将输出的 Query 嵌入线性投影到与 LLM 的文本嵌入相同的维度,然后,将投影的Query嵌入添加到输入文本嵌入前面。由于 Q-Former 已经过预训练,可以提取包含语言信息的视觉表示,因此它,可以有效地充当信息瓶颈,将最有用的信息提供给 LLM,同时删除不相关的视觉信息,减轻了 LLM 学习视觉语言对齐的负担。
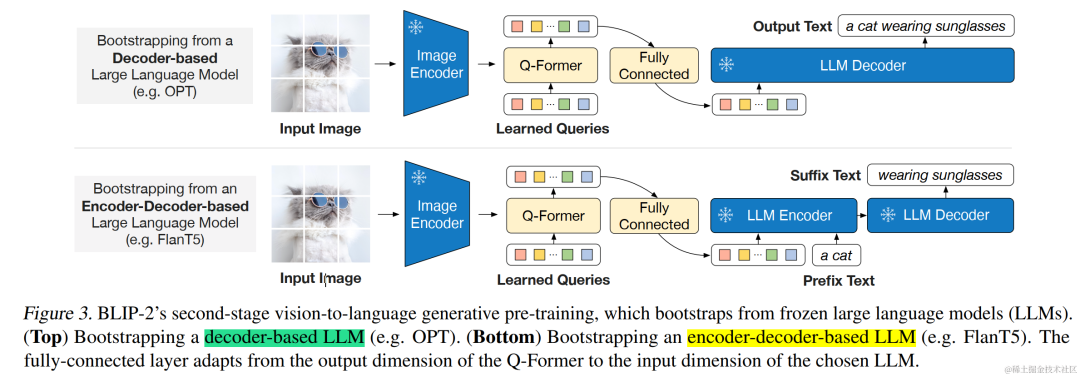
image.png
该模型可用于如下的任务:图像描述生成、视觉问答任务、通过将图像和之前的对话作为提示提供给模型来进行类似聊天的对话。
先预先准备Processor、模型和图像输入。
from PIL import Image import requests from transformers import Blip2Processor, Blip2ForConditionalGeneration import torch device = "cuda" if torch.cuda.is_available() else "cpu" processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b") model = Blip2ForConditionalGeneration.from_pretrained( "Salesforce/blip2-opt-2.7b", load_in_8bit=True, device_map={"": 0}, torch_dtype=torch.float16 ) # doctest: +IGNORE_RESULT url = "http://images.cocodataset.org/val2017/000000039769.jpg" image = Image.open(requests.get(url, stream=True).raw)
对于图像描述生成任务示例如下:
inputs = processor(images=image, return_tensors="pt").to(device, torch.float16) generated_ids = model.generate(**inputs) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text) # two cats laying on a couch
对于视觉问答任务(VQA)示例如下:
prompt = "Question: how many cats are there? Answer:" inputs = processor(images=image, text=prompt, return_tensors="pt").to(device="cuda", dtype=torch.float16) generated_ids = model.generate(**inputs) generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip() print(generated_text) # two
LoRA 简介
LoRA方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
模型微调
为了不影响阅读体验,详细的微调代码放置在GitHub:llm-action 项目中 blip2_lora_int8_fine_tune.py文件,这里仅列出关键步骤。
第一步,加载预训练Blip-2模型以及processor。
`from transformers import AutoModelForVision2Seq, AutoProcessor # We load our model and processor using `transformers` model = AutoModelForVision2Seq.from_pretrained(pretrain_model_path, load_in_8bit=True) processor = AutoProcessor.from_pretrained(pretrain_model_path) `
第二步,创建 LoRA 微调方法对应的配置;同时,通过调用 get_peft_model 方法包装基础的 Transformer 模型。
from peft import LoraConfig, get_peft_model # Let's define the LoraConfig config = LoraConfig( r=16, lora_alpha=32, lora_dropout=0.05, bias="none", ) # Get our peft model and print the number of trainable parameters model = get_peft_model(model, config) model.print_trainable_parameters()
第三步,进行模型微调。
# 设置优化器 optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5) device = "cuda" if torch.cuda.is_available() else "cpu" model.train() for epoch in range(11): print("Epoch:", epoch) for idx, batch in enumerate(train_dataloader): input_ids = batch.pop("input_ids").to(device) pixel_values = batch.pop("pixel_values").to(device, torch.float16) outputs = model(input_ids=input_ids, pixel_values=pixel_values, labels=input_ids) loss = outputs.loss print("Loss:", loss.item()) loss.backward() optimizer.step() optimizer.zero_grad() if idx % 10 == 0: # 根据图像生成文本 generated_output = model.generate(pixel_values=pixel_values) # 解码 print(processor.batch_decode(generated_output, skip_special_tokens=True))
最后,保存训练的Adapter模型权重及配置文件。
model.save_pretrained(peft_model_id)
模型推理
为了不影响阅读体验,详细的代码放置在GitHub:llm-action 项目中blip2_lora_inference.py文件。直接运行CUDA_VISIBLE_DEVICES=0 python blip2_lora_inference.py即可完成图生文。
结语
本文介绍了基于LoRA微调BLIP-2多模态大模型。码字不易,如果觉得我的文章能够能够给您带来帮助,期待您的点赞收藏加关注~~
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 2000
2000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











