






0.前言
科研鼠研0,0基础第一次复现论文,不喜勿喷,有错误👻求指正。。。

Paper:灵活计算分配和内容感知的双路动态稀疏注意力
1.核心概要 | 文章的idea
前置知识:了解什么是ViT、Patch、Query、Key、value
论文目标:针对ViT中的注意力机制要把所有像素都两两配对比较计算量大的问题,本论文提出先找到相关的像素块,再进行比较,从而减少计算量的方法。
本篇论文的核心方法:
- 第一步:在粗粒度的区域级别过滤掉不相关的键值对,使用的是区域-至-区域的路由方法(region-to-region routing approach),就是将图分为较大的几块过滤掉不相关的键值对,而不是分成很小的几块,这样可以高效率在全范围内定位有价值的键值对。
- 第二步:然后在剩余候选区域(即路由区域)的联合中应用细粒度的令牌间注意力。
以上两步叫:双路动态稀疏注意力(Bi-Level Routing Attention),简称 BRA。基于这个注意力机制,论文又搭建了一个 “BiFormer”网络。
2.注意力模型
先来看论文中给出的6种注意力机制:
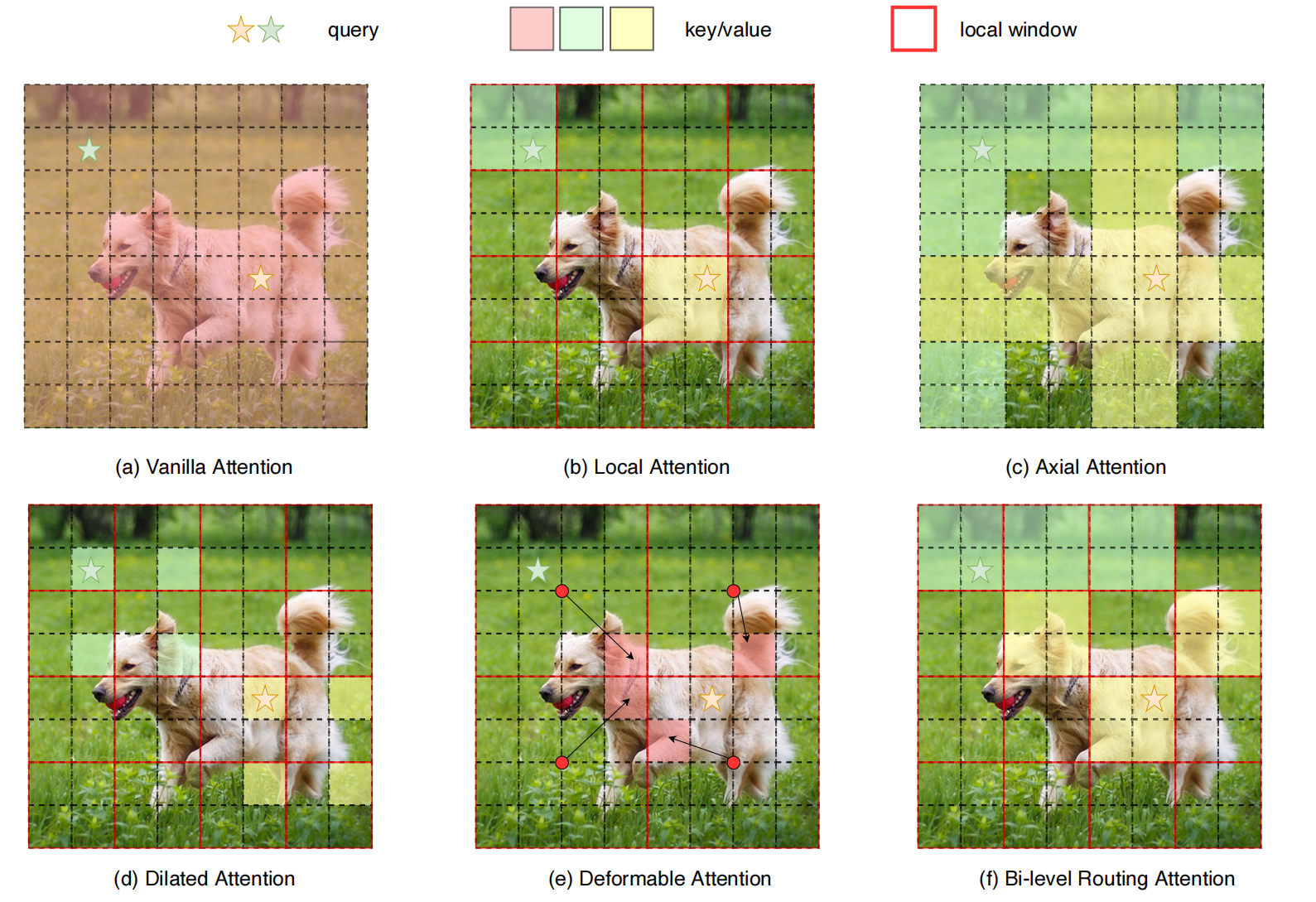
- 图(a)展示了原始 ViT 中的注意力机制:它在全局范围对所有像素两两计算注意力,从而带来极高的计算复杂度和巨量的内存消耗。
- 图(f)为本文所使用的BRA双路动态稀疏注意力:a和f对比可以明显对比出计算量的减少。
- 图(b) Local Attention(局部注意力):每个像素(或 Patch)只“看”它周围的一个小窗口区域内的其他像素,而非整张图。
- 图(c) Axial Attention(轴向注意力):将二维注意力拆成两个一维注意力——先在行(horizontal)方向上做自注意力,再在列(vertical)方向上做自注意力。
- 图(d) Dilated Attention(空洞注意力):在自注意力的窗口或采样中引入“空洞”跳跃,使得注意力感受野既能覆盖局部,也能穿透到更远位置。
- 图(e) Deformable Attention(可变形注意力):为每个 Query 动态地“预测”一组关键位置,而非在固定窗口或轴向中采样,最大程度聚焦最相关的 patches。
总结:
图b-f都是稀疏注意力(Sparse Attention)的不同变体,用来减少注意力的计算量。
图b-d注意机制是手工设计的静态模式。
图e注意机制是在图像上共享采样的键值对子集。
图f是本文的双路动态稀疏注意力,是一种动态的、查询感知的稀疏注意力机制。
3.双路动态注意力(BRA)实现
下面来看具体计算:
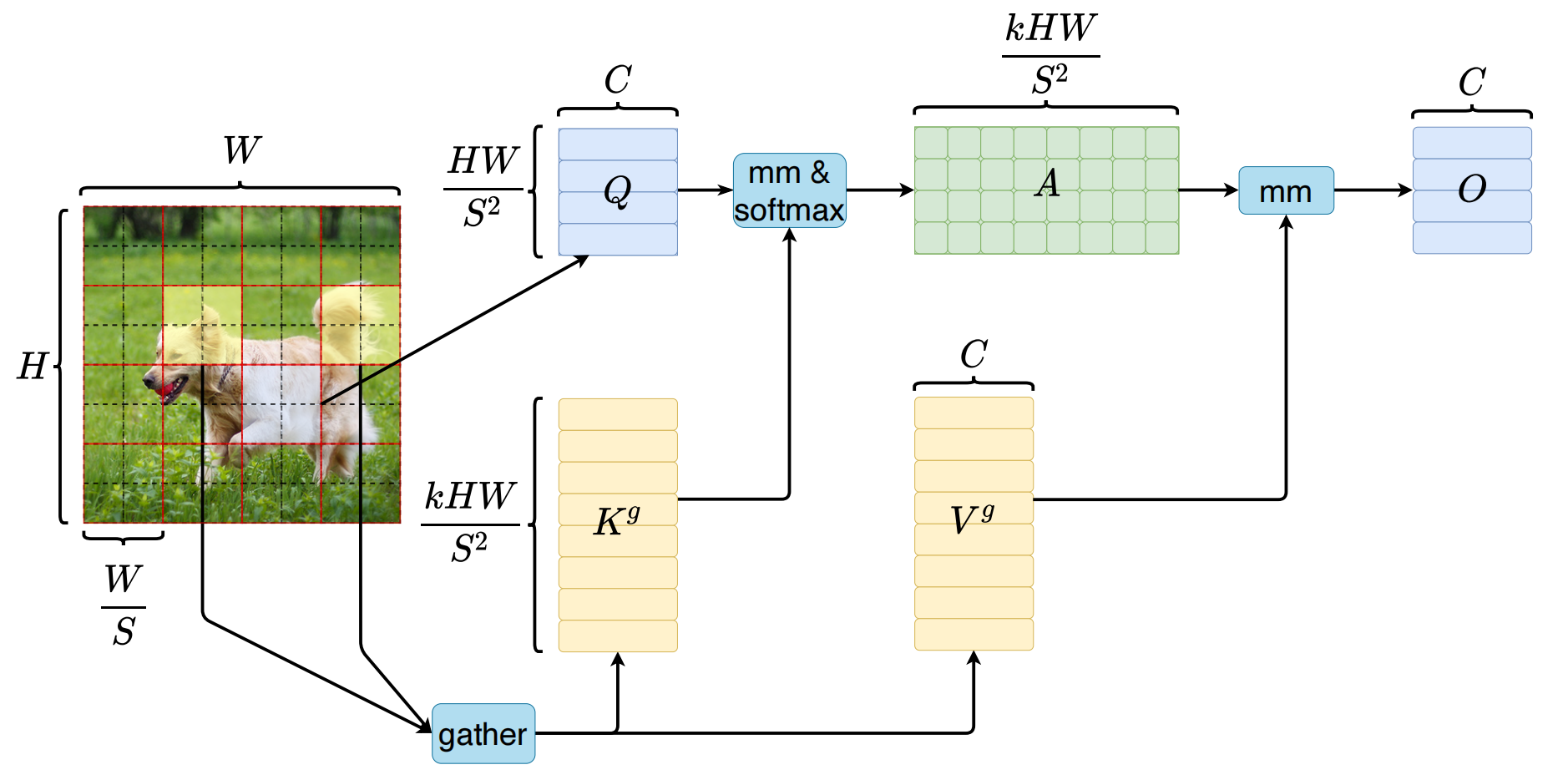
首先将输入的二维特征图分成
个非重叠区域,即上图中
个红边方块,每个红边方块为
。
然后对Q、K、V 进行线性投影得到查询、键、值向量,计算公式如下:
![]()
接下来计算attention注意力值:
设
是 token 数,(例如把图像分成
个区域,每个区域里有
个 Patch)
- 先对Q和K分别进行区域级平均得到区域级查询和键
,就是把原本要在所有 N个 token 上计算的注意力,先“粗粒度”地压缩到只有
- 然后通过对
相乘得到区域间亲和力图的邻接矩阵
。
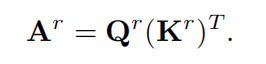
这个邻接矩阵的作用:其实就是用于找到两个语义相关的区域。
接下来,通过上面的邻接矩阵找到与其亲和力高(相似度高)的其他区域,并取前k个(top-k),然后将这k个的索引存进一个向量里面得到路由索引矩阵:
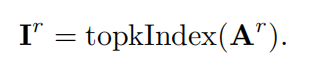
有了这个路由索引矩阵我们就可以计算每个区域与其关联度最高的k个区域计算细粒度的注意力权重,并对这些区域对应的Value向量加权求和,从而得到该区域的最终输出表示。但是这k个区域可能会很分散,且GPU依赖于合并内存操作,即一次加载几十个连续字节的块,所以下面收集键和Value的值:
![]()
所以attention注意力表示为:
![]()
注意力中引入了局部上下文增强项LCE(V)。
LCE(V) 就是对 Value 特征 V 应用一个5×5 的深度可分离卷积,用以在每个 token 周围提取并增强局部上下文信息,从而补足纯注意力机制对局部细节的感知能力
总结一下双路动态注意力的计算步骤:
- 将输入的状特征图进行划分
- 计算Q、K、V
- 计算attention注意力
- 压缩区域向量
- 计算亲和力邻接矩阵
- 计算路由索引矩阵
- 键和Value的合并
- 计算attention注意力
4. BRA的复杂度分析
前置知识:
FLOPs: 表示完成某一任务所需执行的浮点运算(加、减、乘、除等)的总次数,与硬件性能无关,仅反映计算任务的理论复杂度。
1 FLOPS 就是每秒进行 1 次浮点运算
1 MFLOPS(megaFLOPS)等于每秒一百万(=10^6)次的浮点运算。
1 GFLOPS = 10^3 MFLOPS(gigaFLOPS)等于每秒十亿(=10^9)次的浮点运算。
1 TFLOPS = 10^3 GFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算,(1太拉)。
通过第3节我们可以得到BRA计算包括三个部分:线性投影、区间路由、注意力计算
![]()
4.1线性投影计算
-
单次投影的FLOPs为:
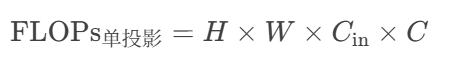
解释:每个空间位置(共 H×W 个)需将 C 个输入通道通过全连接层映射到 C 个输出通道,每个输出通道的计算需要 C 次乘法(输入通道与权重矩阵的对应元素相乘)。
-
三项投影的叠加
由于需要独立生成 Q、K、V 三个矩阵,总计算量为: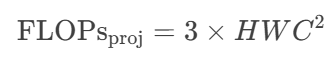
4.2区间路由计算
若将输入划分为 S×S的块(共个块),路由需计算块间相似度矩阵,维度为 N×N。
每个相似度计算需 C次点积操作,总计 。
其中2C为简化处理:在实际FLOPs统计中,常将一次乘加视为 2次浮点操作(乘法和加法各计1次)。因此,单个点积的FLOPs为 2C。
4.3注意力计算
每个块内进行多头注意力(设k个头),每个头的计算量为2×块大小×C。
总块数为,整体计算量为
。
4.4合并和下界优化
将上述三个计算合并并优化下界:
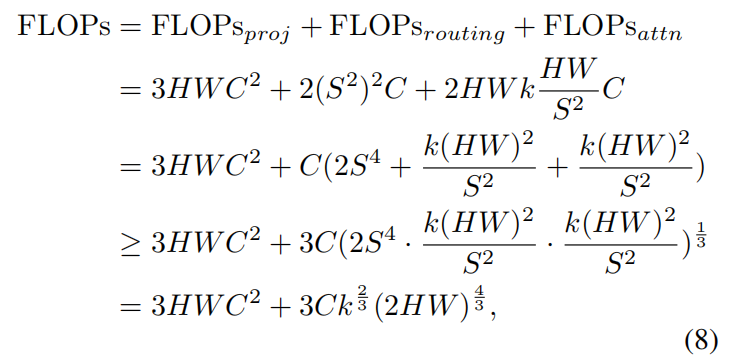
优化部分使用均值不等式,巧妙的约掉分母,当且仅当,等号成立。至于数2的次方为4/3,不是1/3,可能是作者做了近似处理。
我们将HW当成一个整体,其他都为常数,所以最后的时间复杂度为,相较于原始注意力的复杂度为
,提高的速度非常可观。
5.伪代码理解
# 输入: features (H, W, C). 假设 H==W.
# 输出: features (H, W, C).
# S: square root of number of regions.
# k: number of regions to attend.
# patchify input (H, W, C) -> (Sˆ2, HW/Sˆ2, C)
x = patchify(input, patch_size=H//S) # 将特征图分成区域块
# linear projection of query, key, value
query, key, value = linear_qkv(x).chunk(3, dim=-1) # 线性投影
# regional query and key (Sˆ2, C)
query_r, key_r = query.mean(dim=1), key.mean(dim=1) # 区域级压缩(粗粒度)Q和K
# adjacency matrix for regional graph (Sˆ2, Sˆ2)
A_r = mm(query_r, key_r.transpose(-1, -2)) # key_r.transpose表示K的转置,计算每个区域与其他所有区域之间的点积相似度
# compute index matrix of routed regions (Sˆ2, K)
I_r = topk(A_r, k).index # topk函数返回前k个最大相似度的索引
# gather key-value pairs
key_g = gather(key, I_r) # (Sˆ2, kHW/Sˆ2, C)
value_g = gather(value, I_r) # (Sˆ2, kHW/Sˆ2, C) # 聚合路由块
# token-to-token attention
# 细粒度 token-to-token 注意力计算
A = bmm(query, key_g.transpose(-2, -1)) # 计算每个query与所选k个路由块之间的点积相似度
A = softmax(A, dim=-1) # 对相似度进行softmax归一化
output = bmm(A, value_g) + dwconv(value) # 加权求+LCE局部增强
# recover to (H, W, C) shape
output = unpatchify(output, patch_size=H//S) # 还原图像形状6.BiFormer网络架构
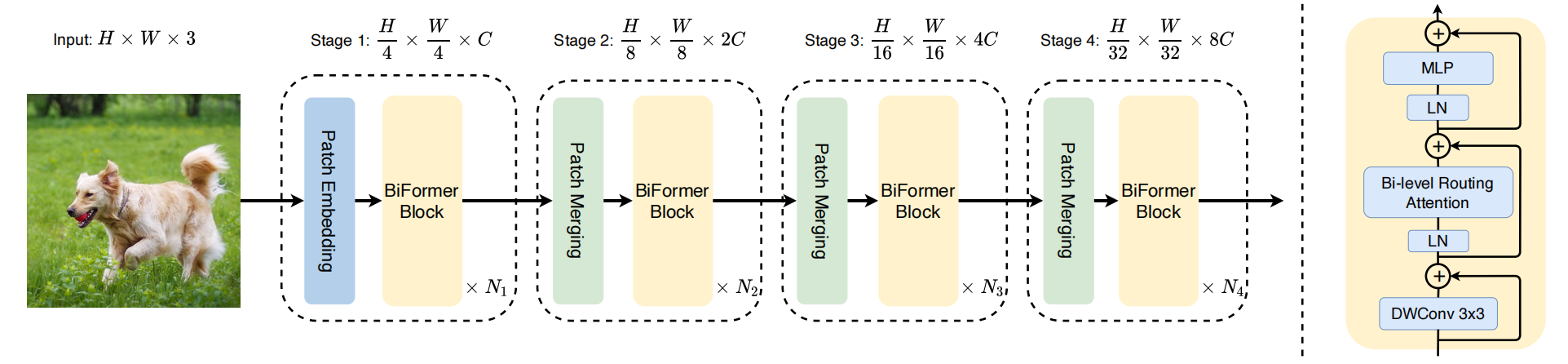
6.1总体结构
四阶段金字塔架构:图中最左边是输入图像,经过四个阶段的处理,每个阶段都由:
-
降采样(Patch Embedding 或 Patch Merging)
-
多个 BiFormer Block(带 BRA 的核心模块)
6.2各阶段详细解读
Stage 1
-
Patch Embedding:就是把图像拆分成一堆小 patch(小块),并把每个 patch 映射为一个向量(称为 token),变换成一组低分辨率、高通道数的特征图。
-
接着连续堆叠 N1层BiFormer Block进行进一步特征提取。
Stage 2、3、4
-
Patch Merging:每阶段开始通过下采样操作。
-
每个阶段接上 N2,N3,N4个BiFormer Block。
6.3BiFormer Block 内部结构(右侧图)
每个BiFormer Block包含以下模块:
1)DWConv 3x3:Depth-wise Convolution(深度卷积),用于隐式位置编码,引入局部感知能力,增强对空间相邻像素的建模。
2)LN:LayerNorm,对输入做归一化。
3)Bi-level Routing Attention:BRA本文所提出的核心模块,用于区域路由选择和注意力计算。
4)MLP:多层感知机,对每个位置(token)单独做的两层全连接(Fully Connected, FC)网络。
- FC1:第一层全连接,把通道维度从C扩展到eC
- GELU:激活函数(比ReLU平滑),引入非线性
- FC2:第二层再把通道维度从eC压回C
5)+ :残差连接,模块的输入 + 模块的输出,然后再传给下一层。
本文中,多层感知机的扩展比e=3,四个阶段top-k分别取1,4,16,
。
并且对于分类,语义分割,目标检测任务的区域划分因子取S=7,8,16
文章提供了三种不同规模的模型,如下表:
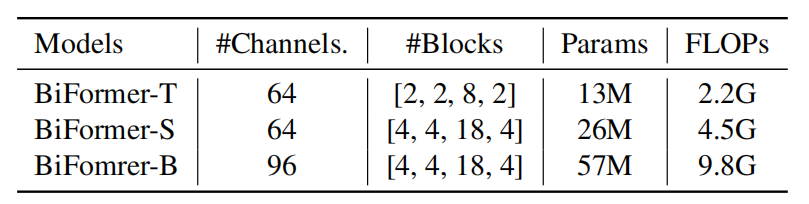
| 模型名称 | 含义 |
|---|---|
| BiFormer-T | Tiny 模型(小型) |
| BiFormer-S | Small 模型(中等规模) |
| BiFormer-B | Base 模型(大规模) |
7.实验
更新中.....

















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









