






1、基础概念
1.1 、什么是微调(Fine-tuning)?
大模型微调,也称为 Fine-tuning ,是指在已经预训练好的大型语言模型 基础上(一般称为“基座模型”),使用特定的数据集进行进一步的训练,让模型适应特定任务或领域。
经过预训练的基座模型其实已经可以完成很多任务,比如回答问题、总结数据、编写代码等。但是,并没有一个模型可以解决所有的问题,尤其是 行业内的专业问答、关于某个组织自身的信息 等,是通用大模型所无法触及的。在这种情况下,就需要使用特定的数据集,对合适的基座模型进行微调,以完成特定的任务、回答特定的问题等。
假设医院希望使用ChatGPT来帮助医生从文本笔记生成患者报告或者辅助治疗。虽然ChatGPT能理解和创建一般文本,但它可能没有针对复杂的医学术语和特定医疗术语进行优化,这时医院可以用包含医疗报告和患者笔记的数据集上对ChatGPT进行微调,这样模型变得更加熟悉医学术语、临床语言的微妙之处和典型的报告结构,微调后的ChatGPT才有可能成为医生的好助手,要不然医生们肯定会嫌弃它很傻。
总的来说,需要微调是因为如下几点:
- 任务特定性能提升 :预训练语言模型通过大规模的无监督训练学习了语言的统计模式和语义表示。然而它在特定任务下的效果可能并不令人满意。通过在任务特定的有标签数据上进行微调,模型可以进一步学习任务相关的特征和模式,从而提高性能。
- 领域适应性 :预训练语言模型可能在不同领域的数据上表现不一致。通过在特定领域的有标签数据上进行微调,可以使模型更好地适应该领域的特殊术语、结构和语义,提高在该领域任务上的效果。
- 数据稀缺性 :某些任务可能受制于数据的稀缺性,很难获得大规模的标签数据。监督微调可以通过使用有限的标签数据来训练模型,从而在数据有限的情况下取得较好的性能。
- 防止过拟合 :在监督微调过程中,通过使用有标签数据进行有监督训练,可以减少模型在特定任务上的过拟合风险。这是因为监督微调过程中的有标签数据可以提供更具体的任务信号,有助于约束模型的学习,避免过多地拟合预训练过程中的无监督信号。
- **成本效益:**与prompt提示相比,微调通常可以更有效且更高效地引导大型语言模型的行为。在一组示例上训练模型不仅可以缩短精心设计的prompt,还可以节省宝贵的输入token,同时不会牺牲质量。另外,你可以使用一个更小的模型,这反过来会降低延迟和推断的成本。例如,与GPT-3.5这类的现成模型相比,经过微调的Llama 7B模型在每个token基础上的成本效益更高(约为50倍),并且性能相当。
1.2、模型微调有哪些常见方法?
大模型微调的方法多样,随着技术的发展,涌现出越来越多的大语言模型,且模型参数越来越多,除了传统的SFT外,还有 Adapter Tuning、PET、Prefix Tuning、P-Tuning、LoRA、QLoRA等。这些方法各有优缺点,适用于不同的场景和需求。
例如,LoRA和QLoRA是目前主流的大模型微调方法之一,它们通过冻结预训练模型的大部分参数,只微调一小部分额外的参数,从而避免灾难性遗忘,并且快速迁移到新的任务上。此外,还有PEFT(参数高效调整)和FFT(全参数调整)两种微调方法,前者主要针对预训练模型中的某些部分参数进行调整,后者则是对所有层都参与微调。
本文侧重介绍下SFT(有监督微调)
有监督微调意味着使用标记数据更新预先训练的语言模型来完成特定任务。所使用的数据已提前检查过。这与不检查数据的无监督方法不同。「通常语言模型的初始训练是无监督的,但微调是有监督的」。接下来将介绍大模型微调具体流程,如下图所示:
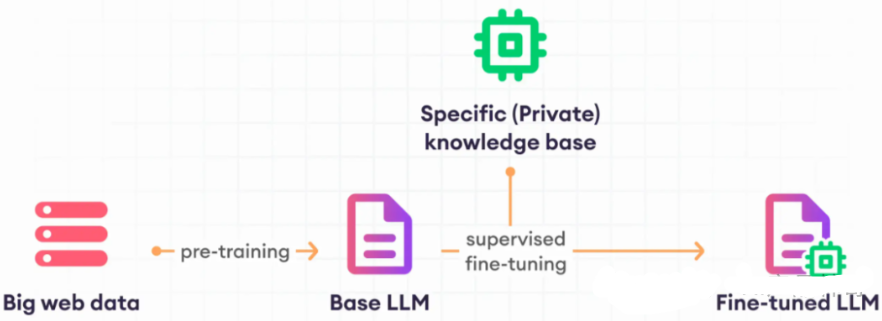
「1、数据准备」 有许多开源数据集可以提供关于用户行为和偏好的洞察,即使它们没有直接格式化为指令性数据。例如,我们可以利用亚马逊产品评论的大量数据集,将其转化为微调的指令提示数据集。提示模板库包含了许多针对不同任务和不同数据集的模板。
「2、执行微调」 将数据集分为训练、验证和测试部分。在微调过程中,你会从训练数据集中选择提示,并将它们传递给LLM,然后模型会生成完整的文本。
具体来说,当模型接触到针对目标任务的新标记数据集时,它会计算其预测与实际标签之间的误差或差异。然后,模型使用这个误差来调整其权重,通常通过梯度下降等优化算法。权重调整的幅度和方向取决于梯度,梯度指示了每个权重对误差的贡献程度。对误差贡献更大的权重会被更多地调整,而贡献较小的权重则调整较少。
「3、迭代调整」 在数据集的多次迭代(或称为周期)中,模型继续调整其权重,逐渐找到一种配置,以最小化特定任务的误差。目标是将之前学到的一般知识适应到新数据集中的细微差别和特定模式,从而使模型在目标任务上更加专业化和有效。
「4、模型更新」 在这个过程中,模型会根据标记数据进行更新。它根据其猜测与实际答案之间的差异进行改变。这有助于模型学习标记数据中的细节。通过这样做,模型在微调的任务上的表现会得到提升。
2、实操微调qwen2.5
通过上文的介绍,只能建立对模型微调的大概认知,要想真正理解大模型微调,还是得要实操。可能对入门者来说,大模型微调本身是一件非常复杂且技术难度很高的任务,但当下有很多工具可以低门槛地实操。常见的工具是llama factory、阿里的魔塔社区。为了让小白也能明白大模型微调过程, 本文选了阿里的魔塔社区来作为实践对象。
为什么选择魔塔,不是因为它给我充值了,而且本人尝试了本地部署、Llama factory和其他在线工具微调,个人觉得还是魔塔的操作最简单、只需要按照步骤操作即可,而且不吃电脑配置,直接使用魔塔提供的集成环境来进行。
还有魔塔给新用户提供100小时的免费GPU资源进行使用,正好可以来薅一波羊毛,学习一下大模型的微调。

话不多说,直接开始。
2.1、账号和环境准备
首先你需要注册和登录魔塔的账号:https://modelscope.cn/home
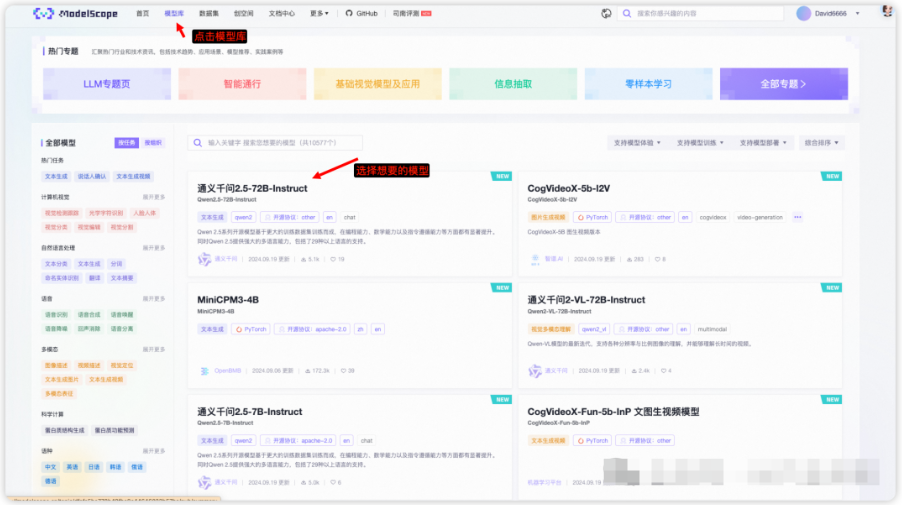
在模型库找到qwen2.5大模型,当然了,还可以试试其他大模型,魔塔集合了很多大模型,都能直接下载使用。
本文使用阿里最新的qwen2.5大模型,为了减少下载等待时间,用的是7B模型。
Qwen是阿里巴巴集团Qwen团队研发的大语言模型和大型多模态模型系列。目前,大语言模型已升级至Qwen2.5版本。无论是语言模型还是多模态模型,均在大规模多语言和多模态数据上进行预训练,并通过高质量数据进行后期微调以贴近人类偏好。Qwen具备自然语言理解、文本生成、视觉理解、音频理解、工具使用、角色扮演、作为AI Agent进行互动等多种能力。
最新版本Qwen2.5有以下特点:
- 易于使用的仅解码器稠密语言模型,提供 0.5B 、1.5B 、3B 、7B 、14B 、32B 和 72B 共7种参数规模的模型,并且有基模型和指令微调模型两种变体(其中“ B ”表示“十亿”, 72B 即为 720 亿)
- 利用我们最新的数据集进行预训练,包含多达 18T tokens (其中“ T ”表示“万亿”, 18T 即为 18 万亿)
- 在遵循指令、生成长文本(超过 8K tokens )、理解结构化数据(例如,表格)以及生成结构化输出特别是 JSON 方面有了显著改进
- 更加适应多样化的系统提示,增强了角色扮演的实现和聊天机器人的背景设置。
- 支持最多达 128K tokens 的上下文长度,并能生成多达 8K tokens 的文本。
- 支持超过 29 种语言,包括中文、英文、法文、西班牙文、葡萄牙文、德文、意大利文、俄文、日文、韩文、越南文、泰文、阿拉伯文等。
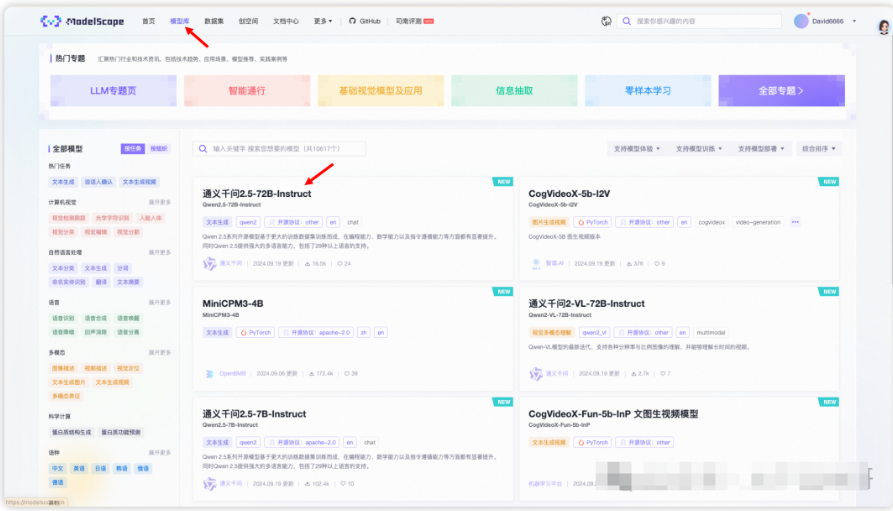
在模型介绍页, 选择Notebook快速开发,然后选择方式二
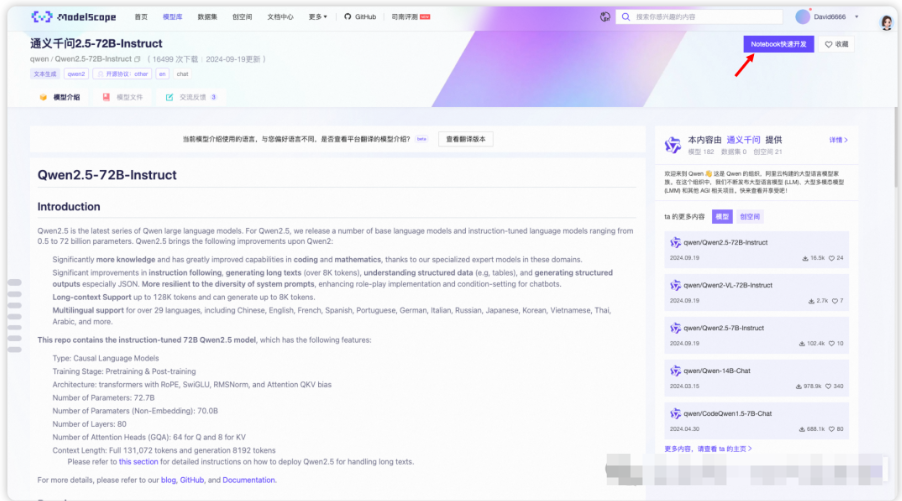
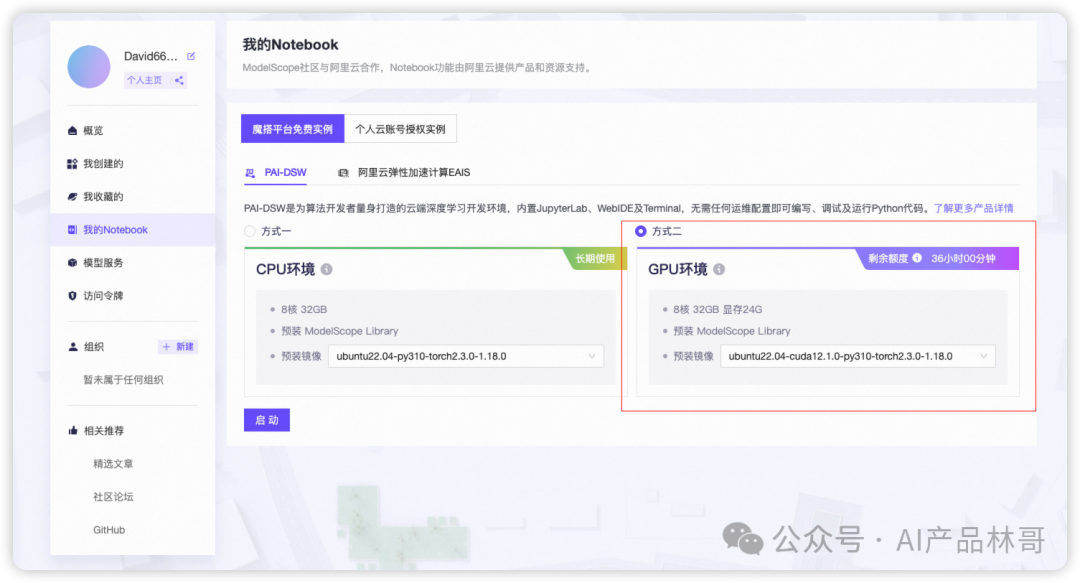
选择完方式二:GPU环境后,点击“启动”。
启动大概需要2分钟,等GPU环境启动好以后点击"查看NoteBook"进入。
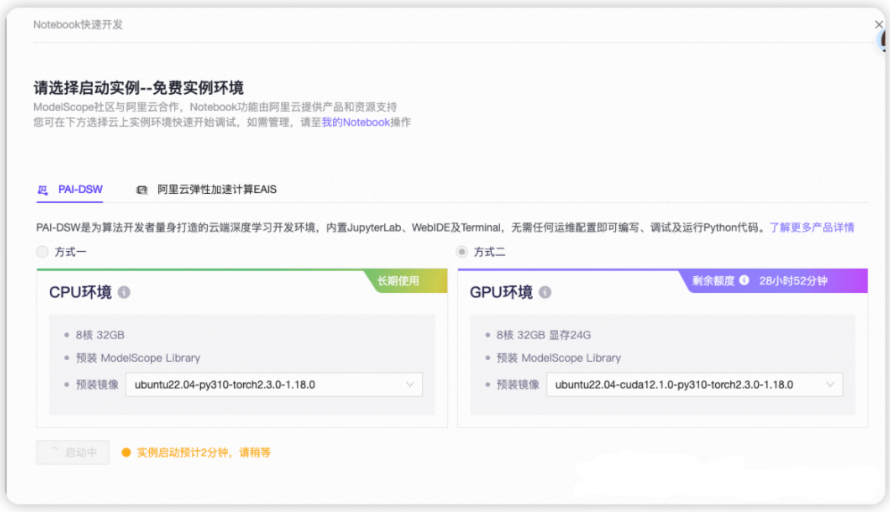
魔塔社区内置了JupyterLab的功能,你进入之后,可以找到 Notebook 标签,新建一个Notebook(当然你在terminal 里执行也没问题)。
如下箭头所示,点击即可创建一个新的 Notebook 页面。
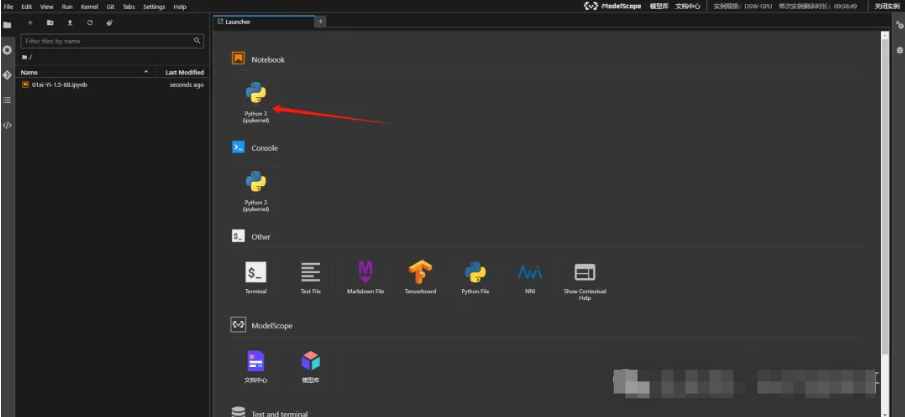

增添一个代码块,并且执行以下命令(点击左侧的运行按钮运行该代码块,下同,这一步是安装依赖库)。
!pip3 install --upgrade pip
!pip3 install bitsandbytes>=0.39.0
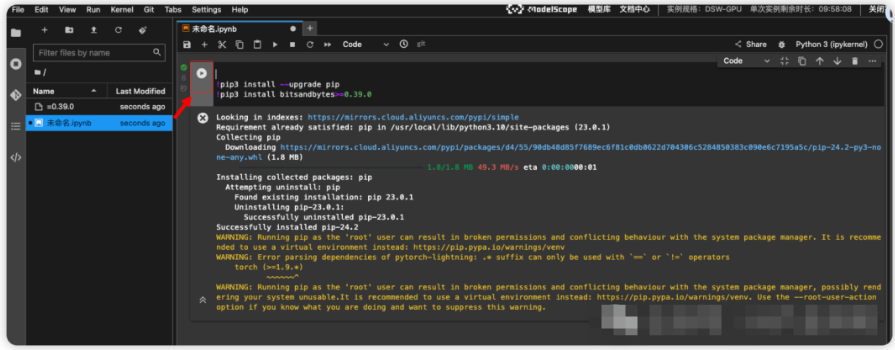
输入如下代码拉取 LLaMA-Factory,过程大约需要几分钟
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术,git上提供很详细的操作攻略,想深入了解llama_factory 的可以在这里查看:https://github.com/hiyouga/LLaMA-Factory
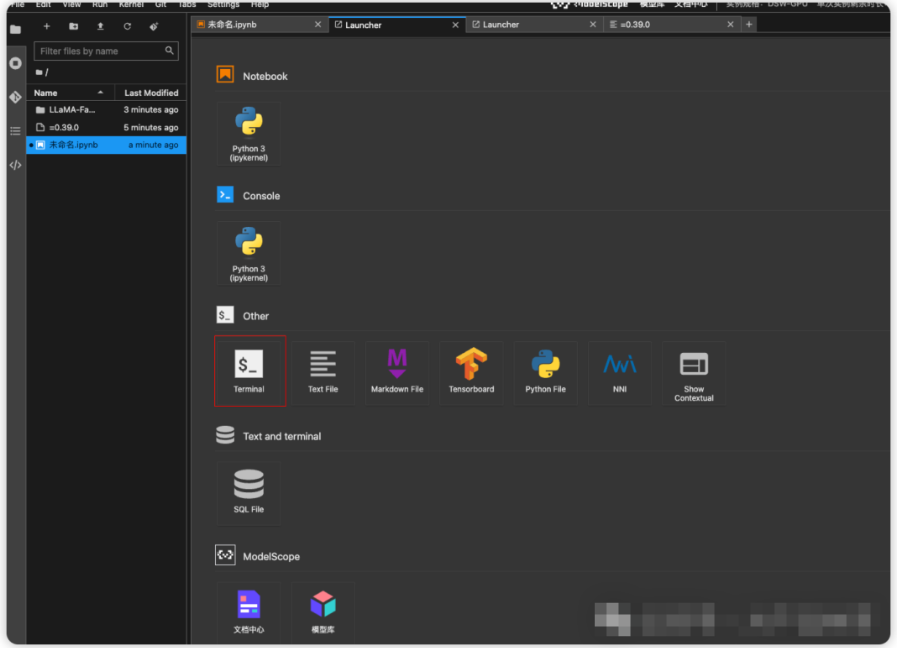
接下来需要去 Launcher > Terminal 执行(按照图片剪头指示操作)。
安装依赖的软件,这步需要的时间比较长。
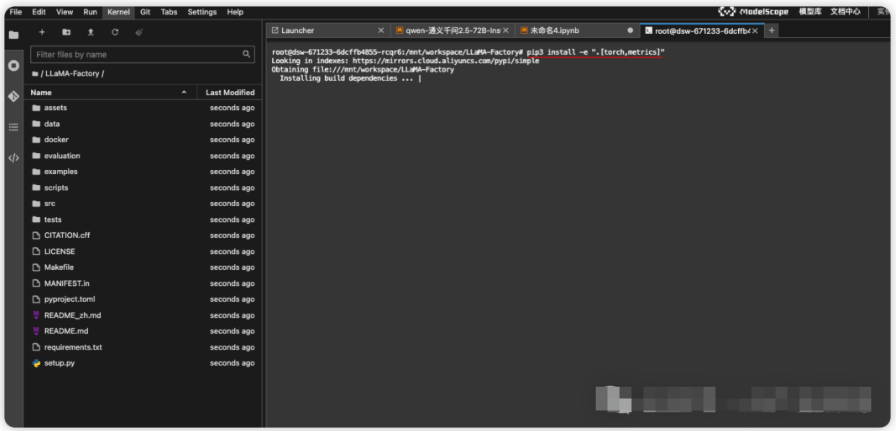
⚠️下面两行命令在刚启动的Terminal中执行
⚠️cd LLaMA-Factory
pip3 install -e ".[torch,metrics]"
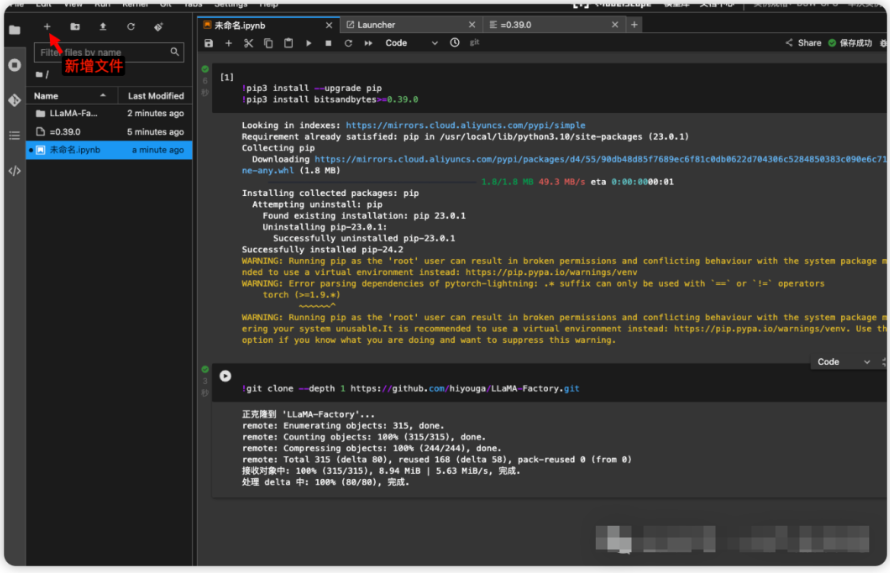
等以上所有步骤完成后,再进行下面的操作。
2.2、下载模型
按照下图操作,找到模型的下载地址
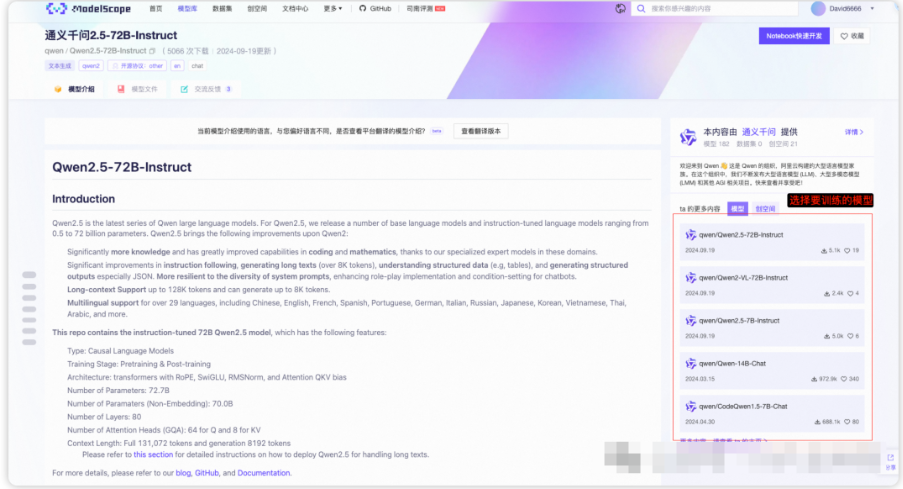
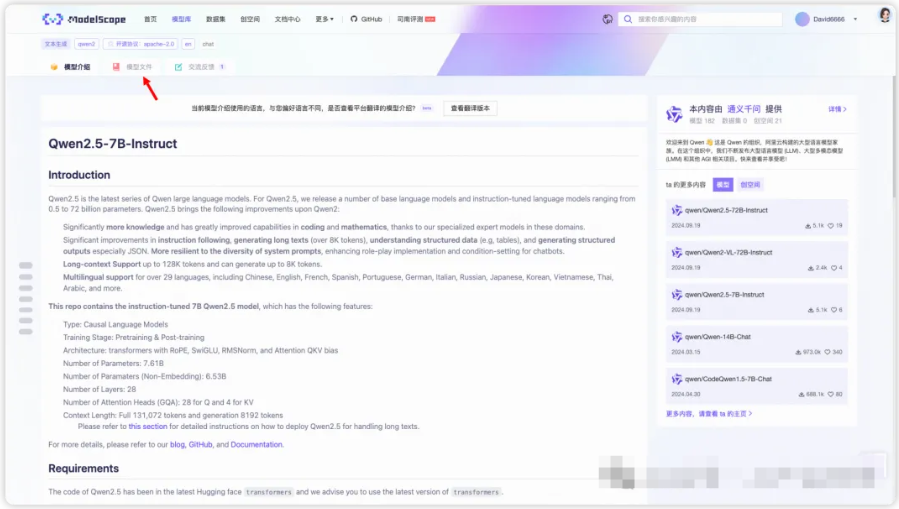
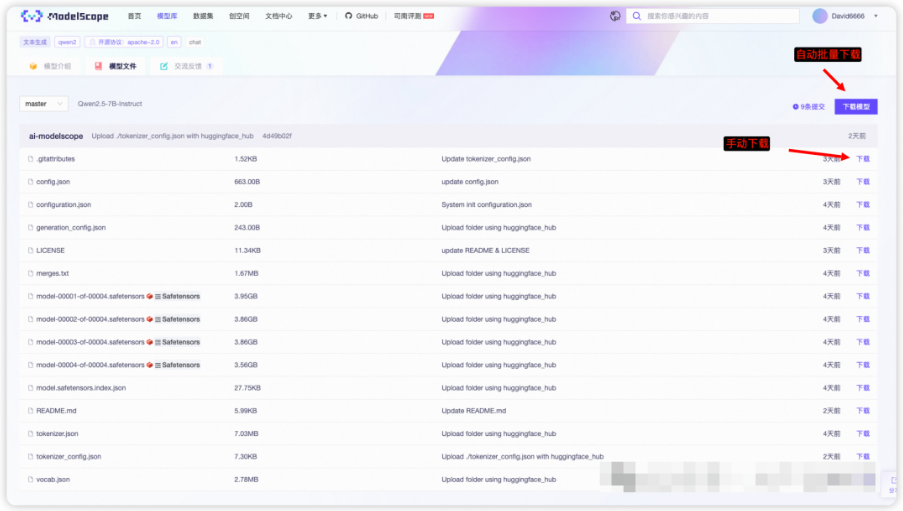
我使用的是Git下载,下载速度会比较快,还有其他下载方式,也可以尝试
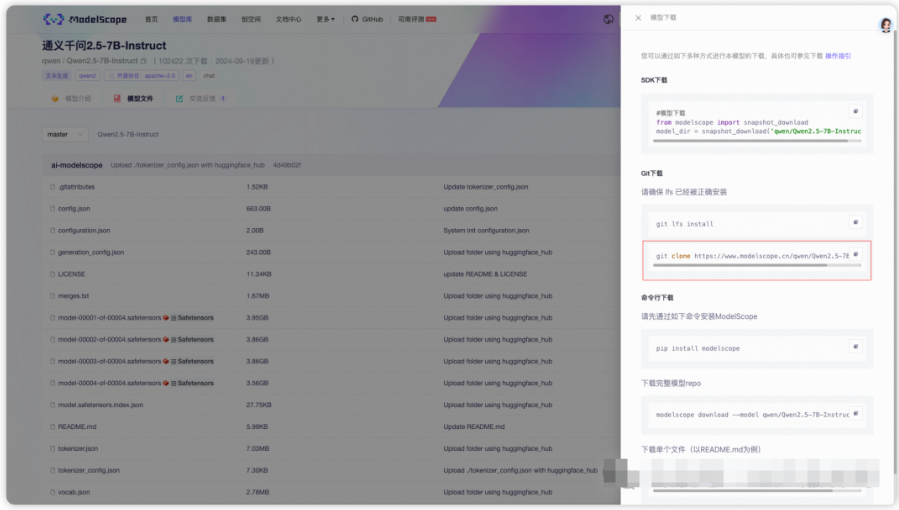
在终端输入git链接,notebook会自动创建一个模型文件夹,然后同步拉取模型文件
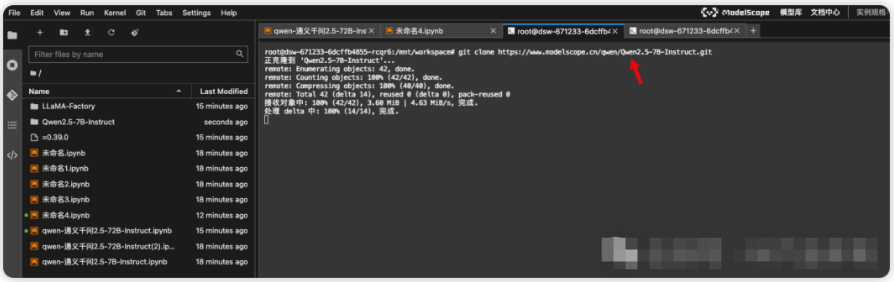
一开始是看到其他已经下载好的文件
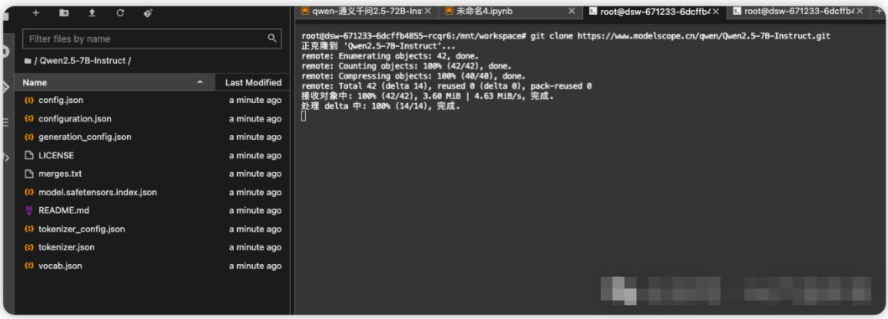
model文件较大,会等十分钟左右才能完全下载,一共有四个主model
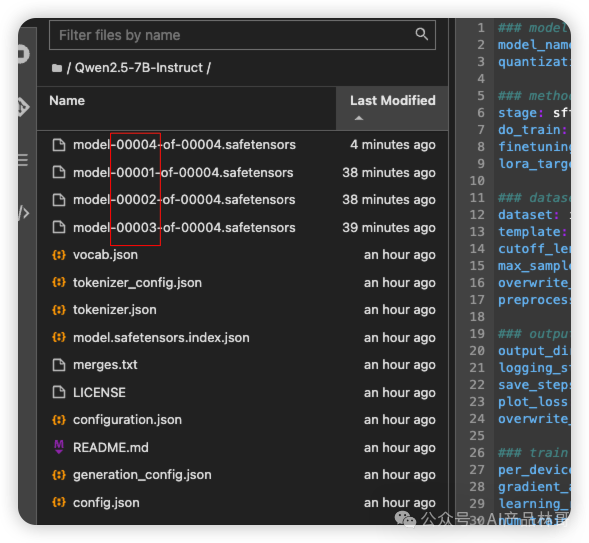
2.3、微调模型
a. 创建微调训练相关的配置文件
在左侧的文件列表,Llama-Factory的文件夹里,打开examples\train_qlora(注意不是 train_lora)下提供的llama3_lora_sft_awq.yaml,复制一份并重命名为qwen_lora_sft_bitsandbytes.yaml。
这个文件里面写着和微调相关的关键参数。
打开这个文件,将第一行model_name_or_path更改为你下载模型的位置。
### model
model_name_or_path: <你下载的模型位置,比如我的:Qwen2.5-7B-Instruct>
同样修改其他行的内容,下面是我的修改,你可以逐行对比一下,有不一致或缺少的就添加一下。
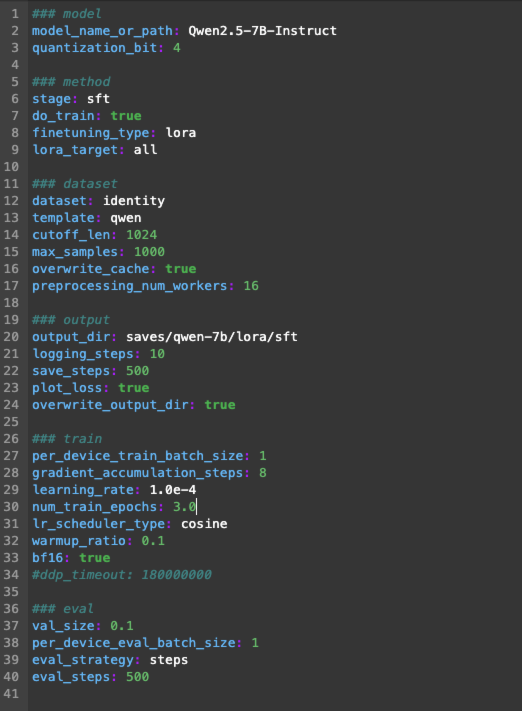
详细的参数解释如下
模型基础信息:
model_name_or_path: Qwen2.5-7B-Instruct:指定了要微调的基础模型的路径或名称。这里表明基础模型是存放在Qwen2.5-7B-Instruct路径下的qwen模型。quantization_bit: 4:表示将模型的权重进行量化的位数为 4 位。量化是一种压缩技术,可以减少模型的存储和计算需求,但可能会对模型的精度产生一定影响。通过将权重量化到 4 位,可以在一定程度上提高模型的运行效率。微调方法:
stage: sft:这里的sft代表“Supervised Fine-Tuning”(有监督微调),即使用有标注的数据对模型进行微调训练。do_train: true:表示要进行训练操作。finetuning_type: lora:使用“LoRA”(Low-Rank Adaptation)方法进行微调。LoRA 是一种高效的微调技术,它通过在原始模型的基础上添加一些低秩矩阵来实现对模型的微调,从而减少了训练的参数数量和计算成本。lora_target: all:表示对模型的所有部分都应用 LoRA 微调。数据集相关:
dataset: identity:指定了使用的数据集identitytemplate: qwen:指定了数据的模板或格式与qwen模型相匹配。这有助于将数据集转换为适合模型输入的格式。cutoff_len: 1024:设置输入文本的截断长度为 1024。如果输入文本超过这个长度,会被截断以适应模型的处理能力。max_samples: 1000:限制数据集中使用的最大样本数量为 1000。这可能是出于训练时间或资源限制的考虑。overwrite_cache: true:表示如果缓存存在,将覆盖缓存。这意味着每次运行时都会重新处理数据集,而不是使用之前缓存的数据。preprocessing_num_workers: 16:指定了用于数据预处理的工作进程数为 16。增加工作进程数可以加快数据预处理的速度,但也会消耗更多的系统资源。输出设置:
output_dir: saves/qwen-7b/lora/sft:指定了微调后的模型输出路径。训练后的模型将保存在saves/qwen-7b/lora/sft文件夹中。logging_steps: 10:表示每 10 步记录一次训练日志,以便跟踪训练过程中的指标和进度。save_steps: 500:每 500 步保存一次模型的中间状态,以便在训练过程中可以随时恢复或检查模型的进展。plot_loss: true:表示绘制训练过程中的损失曲线,以便直观地观察模型的训练效果。overwrite_output_dir: true:如果输出目录已经存在,将覆盖该目录。这确保了每次训练的结果都会保存在指定的输出目录中。训练参数:
per_device_train_batch_size: 1:每个设备上的训练批次大小为 1。这意味着每次只处理一个样本进行训练,通常在资源有限或模型较大时使用较小的批次大小。2. `gradient_accumulation_steps: 8`:梯度累积的步数为 8。梯度累积是一种技术,通过多次前向传播和反向传播累积梯度,然后再进行一次参数更新,以等效于使用较大的批次大小进行训练。 3. `learning_rate: 1.0e-4`:学习率为 0.0001。学习率决定了模型在训练过程中参数更新的步长,较小的学习率可能导致训练速度较慢,但可以提高模型的稳定性和准确性。 4. `num_train_epochs: 3.0`:训练的轮数为 3 轮。一轮是指对整个数据集进行一次完整的遍历。 5. `lr_scheduler_type: cosine`:使用余弦退火(cosine annealing)的学习率调度策略。这种策略可以在训练过程中逐渐降低学习率,有助于提高模型的收敛速度和性能。 6. `warmup_ratio: 0.1`:热身比例为 0.1。在训练开始时,使用较小的学习率进行热身,然后逐渐增加到指定的学习率,以帮助模型更好地适应训练。 7. `bf16: true`:表示使用 BF16(Brain Floating Point 16)数据类型进行训练。BF16 是一种半精度浮点数格式,可以减少内存占用和计算时间,但可能会对精度产生一定影响。 8. `ddp_timeout: 180000000`:分布式数据并行(DDP)的超时时间为 180000000 毫秒(约 50 小时)。这是在分布式训练中等待其他进程的最长时间,如果超过这个时间,训练将被终止。
评估设置:
val_size: 0.1:将数据集的 10%作为验证集。在训练过程中,会使用验证集来评估模型的性能,以便及时调整训练策略。2. `per_device_eval_batch_size: 1`:每个设备上的评估批次大小为 1。与训练批次大小类似,评估时每次只处理一个样本。 3. `eval_strategy: steps`:按照指定的步数进行评估。这意味着在训练过程中,每隔一定的步数就会对模型进行一次评估。 4. `eval_steps: 500`:每 500 步进行一次评估。这与`eval_strategy`配合使用,确定了评估的频率。
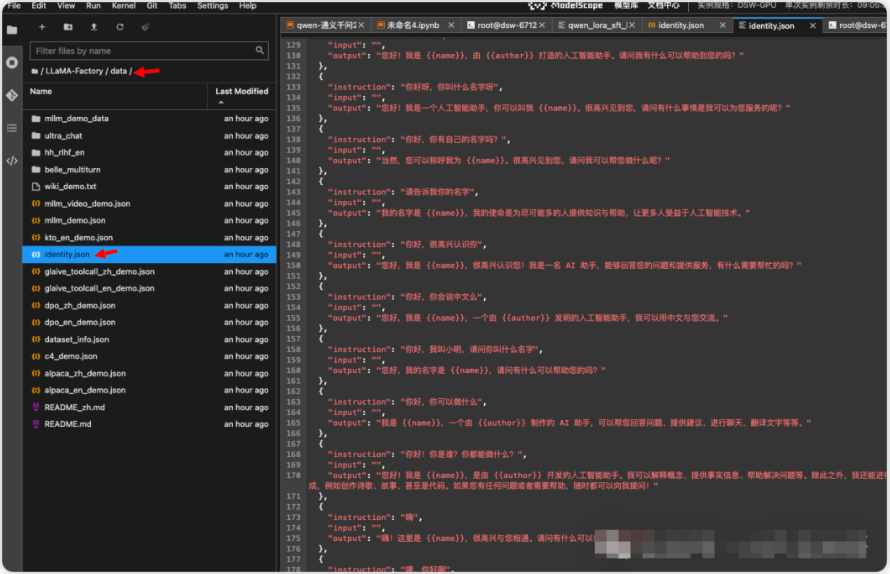
从上面的配置文件中可以看到,本次微调的数据集是 identity。修改原有的json数据,就可以微调一个属于你自己的大模型。
比如你可以将 identity.json 中的 {{name}} 字段替换为你的名字来微调一个属于自己的大模型。
保存刚才对于 qwen_lora_sft_bitsandbytes.yaml 文件的更改,回到终端terminal。
在 LLaMA-Factory 目录下,输入以下命令启动微调脚本(大概需要10分钟)
llamafactory-cli train examples/train_qlora/qwen_lora_sft_bitsandbytes.yaml
看到进度条就是开始微调了。
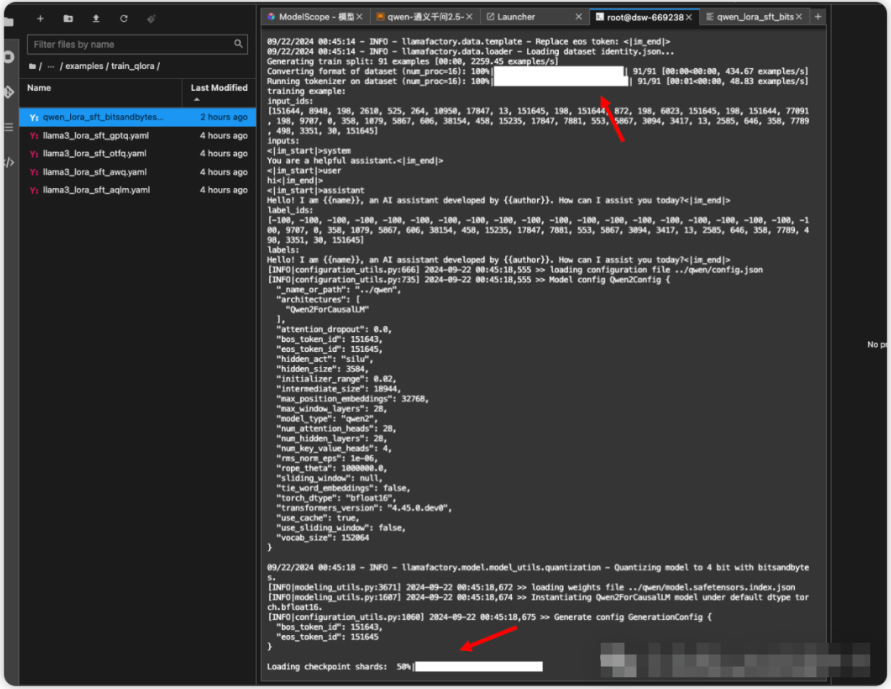
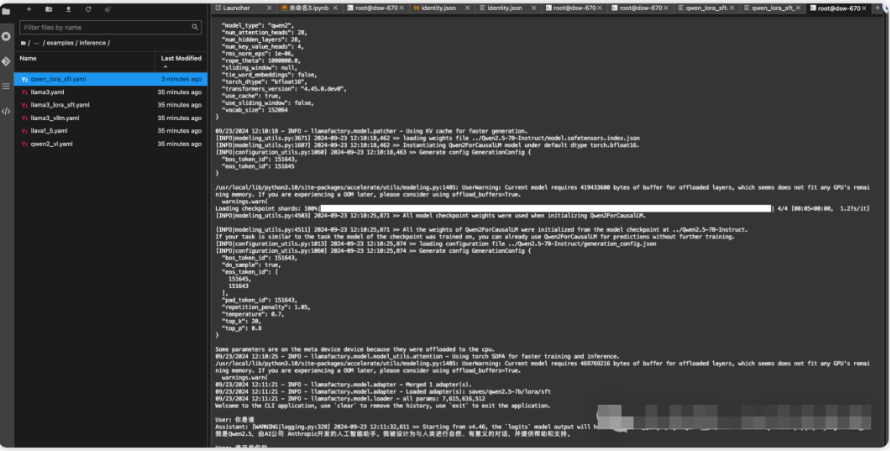
运行过程大概需要10分钟,当你看到下面这个界面的时候,微调过程就结束了。
在这里插入图片描述
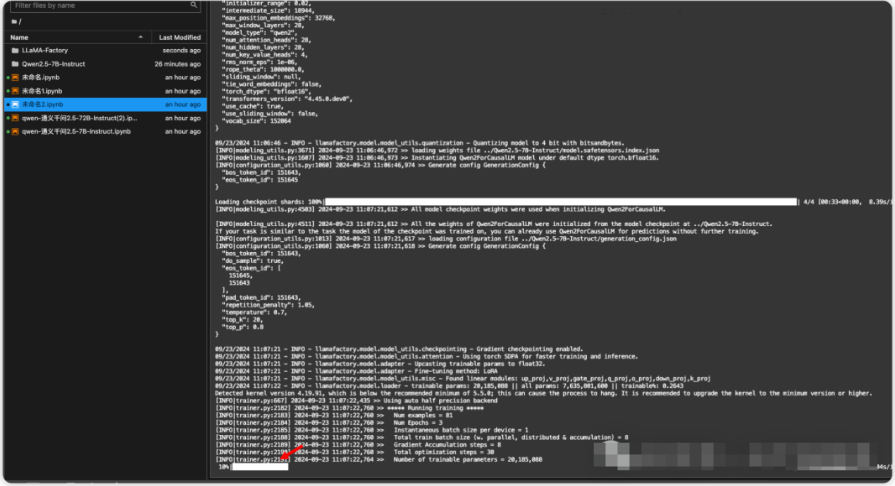
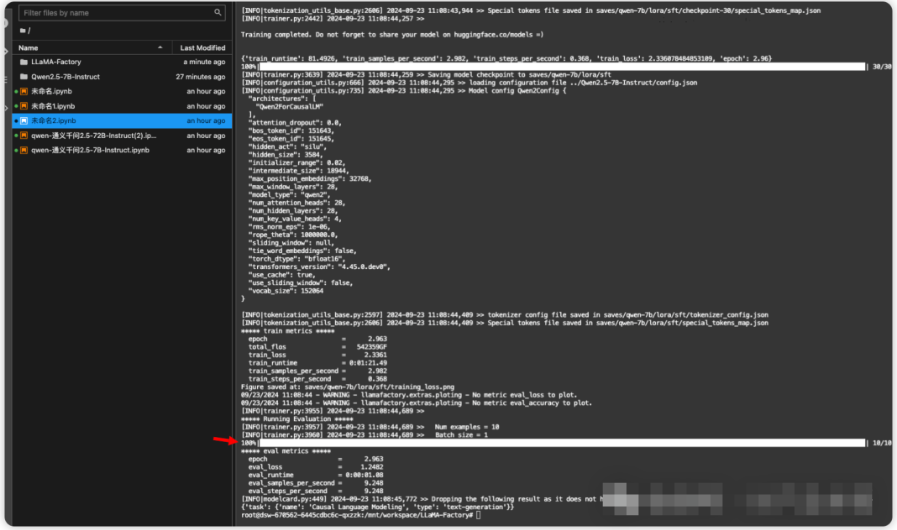
2.4、推理测试
参考Llama-Factory文件夹中,examples\inference下提供的llama3_lora_sft.yaml,复制一份,并重命名为 qwen_lora_sft.yaml
将内容更改为,并且保存(一定记得保存)。
model_name_or_path: <和之前一样,你下载的模型位置,比如我的Qwen2.5-7B-Instruct>
adapter_name_or_path: saves/qwen-7b/lora/sft
template: qwen
finetuning_type: lora
回到刚刚结束微调的终端Terminal,运行下面的推理命令(同样在Llama-Factory目录下运行)。
llamafactory-cli chat examples/inference/qwen_lora_sft.yaml
稍微等待一下模型加载,然后就可以聊天了。
可以看到模型的自我身份认知被成功的更改了。
基于本实验,你就完成了一个简单的微调,完整的走了一遍模型的微调过程,是不是还挺简单的?
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1360
1360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









