






前言
为什么要离线部署,好处有: 1.数据安全,可以部署自己私有大模型,避免数据泄露。2.可以进行功能定制,实现更多自定义的功能。3.随时随地可用,无需联网。
之前给大家分享利用python代码来部署DeepSeek-R1模型: [【好强!在数学领域 1.5B参数超过GPT-4o!】Deepseek-R1开源啦!本文实战部署推理代码,效果着实惊艳!]由不少小伙伴反馈说python代码需要配置各种库环境比较麻烦,有没有傻瓜式的部署方式,有!
今天我将手把手带大家部署大模型(以DeepSeek R1大模型为例子),分别实操部署在linux端、windows端 、手机安卓端;下面进入今天的主题~
本文目录
-
linux端部署: DeepSeek-R1离线部署到电脑linux系统
-
ollama支持的显卡型号介绍
-
第1步: 下载ollama
-
第2步: 下载DeepSeek-R1大模型
-
第3步: 运行DeepSeek-R1大模型进行推理聊天
-
windows系统部署: DeepSeek-R1离线部署到电脑windows系统
-
第1步: 下载ollama.exe软件到本地进行安装
-
第2步:修改ollama的路径和模型路径
-
第3步:下载DeepSeek-R1模型
-
第4步:运行DeepSeek-R1 蒸馏1.5B模型进行推理聊天
-
安卓手机离线部署: DeepSeek-R1离线部署到安卓手机上
-
第1步: 下载termux软件
-
第2步: 配置ollama软件运行环境
-
第3步:下载deepseek-R1模型
-
第4步:运行DeepSeek-R1 蒸馏1.5B模型进行推理聊天
-
参考链接
linux端部署: DeepSeek-R1离线部署到电脑linux系统
本文主要是使用ollama在linux端、windows端、安卓端分别实现离线部署大模型,以DeepSeek-R1大模型为例;也可以是其他大模型。如果你有显卡资源当然是最好的,可以对模型进行加速!
ollama支持的显卡型号介绍
A卡支持的型号汇总
 目前ollama关于AMD显卡支持的型号如下:
目前ollama关于AMD显卡支持的型号如下: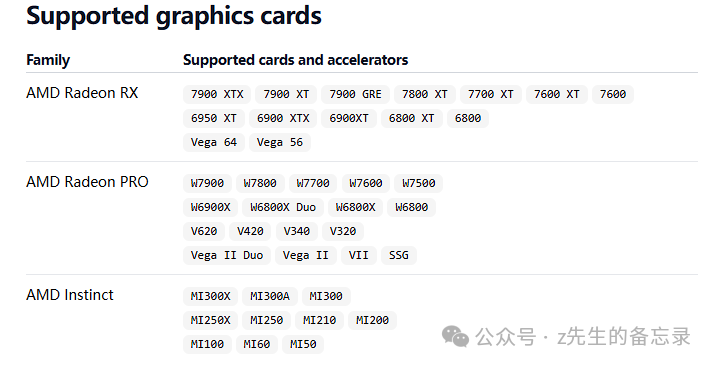
N卡支持的型号汇总
cuda支持的显卡:Ollama 支持计算能力 5.0 及以上的 Nvidia GPU;如何查看自己的显卡对应的计算能力,可以查看nvidia的官网:https://developer.nvidia.com/cuda-gpus
第1步: 下载ollama
!sudo apt install pciutils lshw -y !curl -fsSL https://ollama.com/install.sh | sh # 执行该命令会自动安装ollama,会自动检查是否存在GPU资源。 !ollama -v
安装完成后,输出对应的版本信息如下:
第2步: 下载DeepSeek-R1大模型
你可以下载其他任何大模型,这里以deepseek-ai/DeepSeek-R1-Distill-Qwen-7B模型为例子,详情见:https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.
!ollama serve & #开启ollama服务默认后台运行 !ollama pull deepseek-r1:7b #如何查找对应ollama模型名称, 查看网址:https://ollama.com/library/deepseek-r1:1.5b !ollama list
安装完成后,输出的效果如下:
查看 deepseek-r1:7b模型的信息: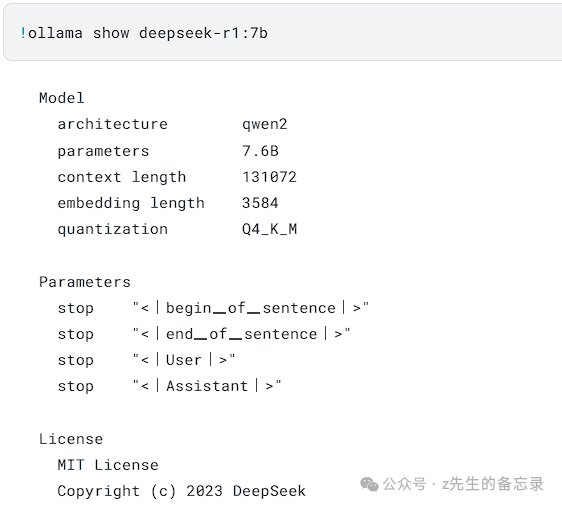
第3步: 运行DeepSeek-R1大模型进行推理聊天
方式1: 在命令行中直接进行对话聊天
# 直接在命令行中输入 ollama run deepseek-r1:7b
就可以直接进行对话聊天啦
方式2: 通过openai库来进行调用DeepSeek-R1大模型进行推理聊天
!pip install openai """ 首先确保ollama serve命令已经启动,可以通过下面的命令验证 # 方式1: !lsof -i -P -n | grep ollama # 输出的结果如下: ollama 452 root 3u IPv4 49029 0t0 TCP 127.0.0.1:11434 (LISTEN) ollama 452 root 17u IPv4 54015 0t0 TCP 127.0.0.1:11434->127.0.0.1:56014 (ESTABLISHED) # 方式2 !curl http://127.0.0.1:11434/ # Ollama is running """ from openai import OpenAI def ollama_deepseek_r1_infer(query): client = OpenAI( base_url = 'http://127.0.0.1:11434/v1', # 注意这块ollama serve 启动默认的地址和端口 api_key='ollama', # required, but unused ) response = client.chat.completions.create( model="deepseek-r1:7b", messages=[ {"role": "user", "content": query} ], temperature=0.7, top_p=0.8, max_tokens=4096, extra_body={ "repetition_penalty": 1.05, }, stream=True # 启用流式响应 ) # 逐块打印响应 for chunk in response: if chunk.choices[0].delta.content: # 检查是否有内容 print(chunk.choices[0].delta.content, end="", flush=True)
执行的效果如下:
就可以尽情的玩耍啦!如果你有更多的内存和显卡资源,可以下载8B,32B等更大版本的模型~
windows系统部署: DeepSeek-R1离线部署到电脑windows系统
这里给大家介绍如何快速将 DeepSeek-R1大模型部署在windows系统中。
第1步: 下载ollama.exe软件到本地进行安装
进入https://ollama.com/download/windows页面,点击download进行下载,注意需要windows10及以上的系统; 下载完成后,点击安装。注意这块软件默认安装是在C盘。下载的模型权重也在C盘。
下载完成后,点击安装。注意这块软件默认安装是在C盘。下载的模型权重也在C盘。
第2步:修改ollama的路径和模型路径
为了长久使用ollama,需要将ollama路径移动到其他盘路径下; 步骤如下;
将默认安装C盘的ollama路径移动到其他盘中
- 找到已安装好ollama软件对应的路径,将其整体剪切复制到F:\ollama下面(你可以切换到其他盘)
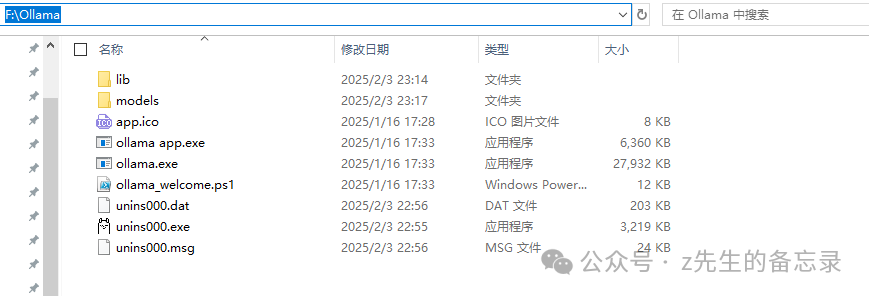
添加环境变量 :
-
右键点击“此电脑”或“我的电脑”,选择“属性”。
-
进入“高级系统设置” -> “环境变量”。
-
在“系统变量”部分,找到 Path,点击“编辑”。
-
添加一个新的路径,指向 Ollama 的解压目录(例如 D:\Ollama)。
-
点击“确定”保存更改。
修改ollama模型下载的路径
Ollama 默认会将模型文件存储在系统的用户目录下(例如 C:\Users<用户名>.ollama)。如果你希望修改模型存储路径,可以按照以下步骤操作:
-
创建新的存储目录 :在目标磁盘上创建一个新的文件夹,例如 D:\Ollama\Models。
-
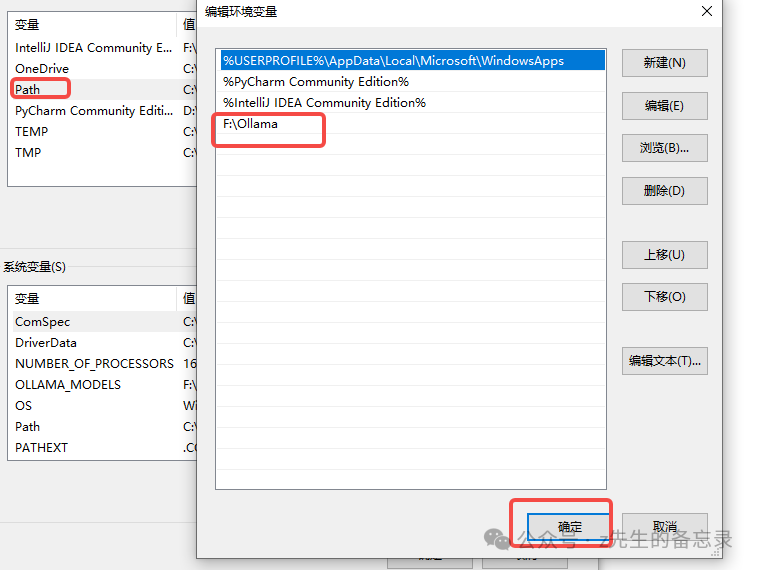
设置环境变量 :
-
按照上述方法进入“环境变量”设置。
-
新建一个系统变量,名称为 OLLAMA_MODELS,值为你希望的模型存储路径(例如 D:\Ollama\Models)。
-
点击“确定”保存。
-
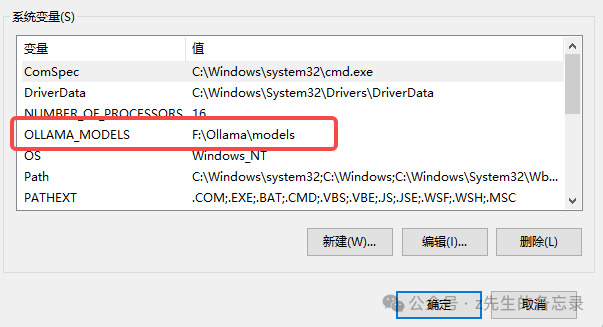
验证配置 :启动 Ollama 并加载模型时,检查新路径是否生效。这是我修改的位置:
第3步:下载DeepSeek-R1模型
你可以下载其他任何大模型,这里以deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B模型为例子,详情见:https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B. 打开windows系统的cmd命令窗口;
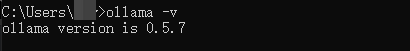 拉取deepseek-r1:1.5b模型:
拉取deepseek-r1:1.5b模型:
!ollama pull deepseek-r1:1.5b !ollama list
执行的效果如下: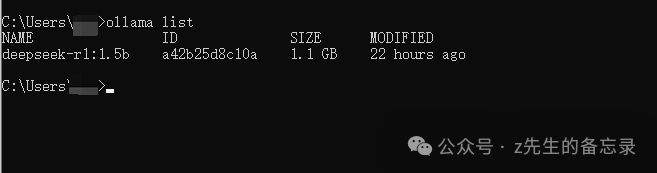
第4步:运行DeepSeek-R1 蒸馏1.5B模型进行推理聊天
!ollama run deepseek-r1:1.5b --verbose
在windows下执行的效果,可以看出1.5B的模型在我windows电脑上,每秒平均37个token.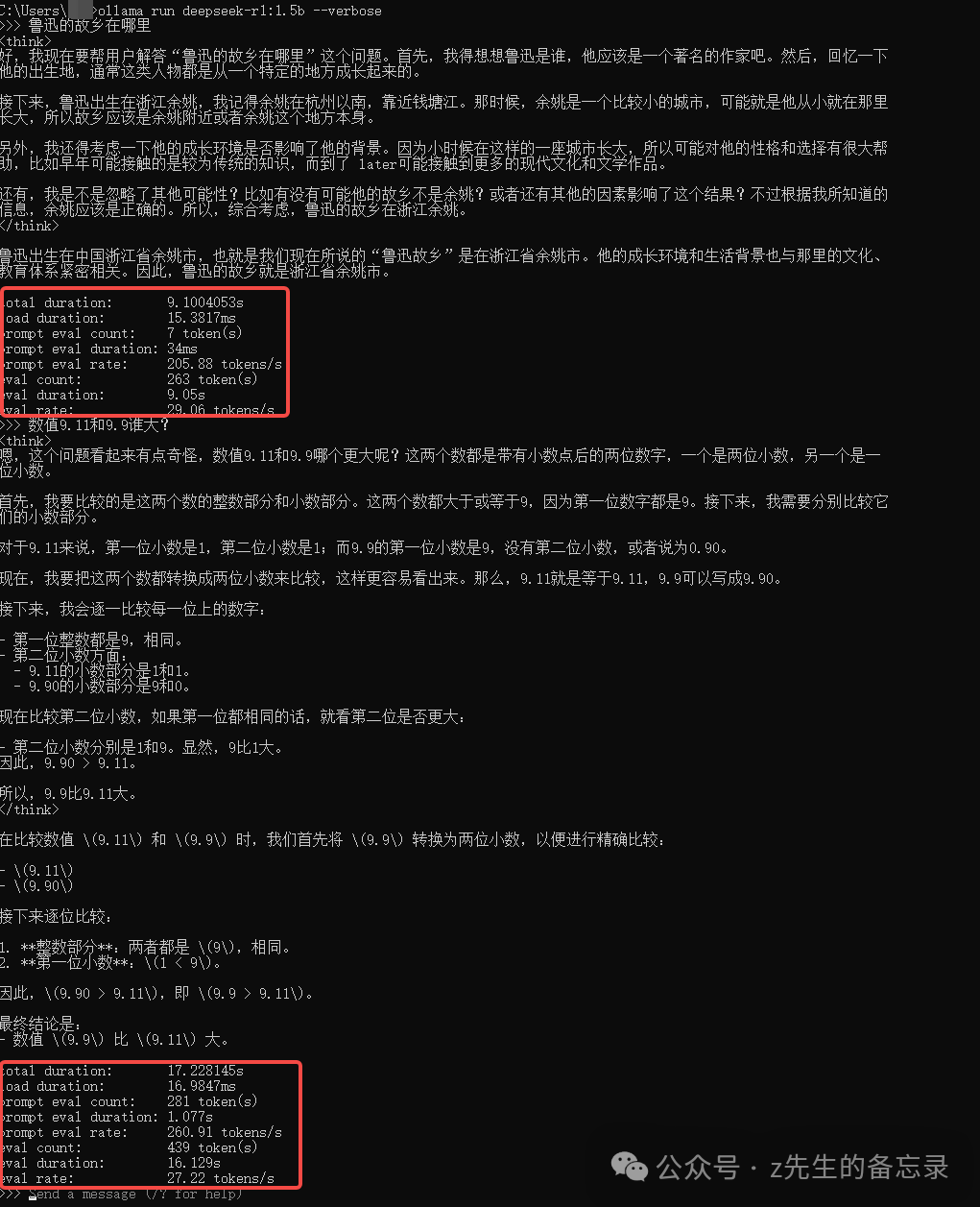
到此就可以愉快的玩耍啦~
安卓手机离线部署: DeepSeek-R1离线部署到安卓手机上
这里我将给大家介绍如何将DeepSeek-R1大模型部署到安卓手机上,这里主要是利用termux+ollama来实现部署到安卓手机中。
第1步: 下载termux软件
访问https://github.com/termux/termux-app/releases/tag/v0.118.1页面,下载termux-app_v0.118.1+github-debug_arm64-v8a.apk;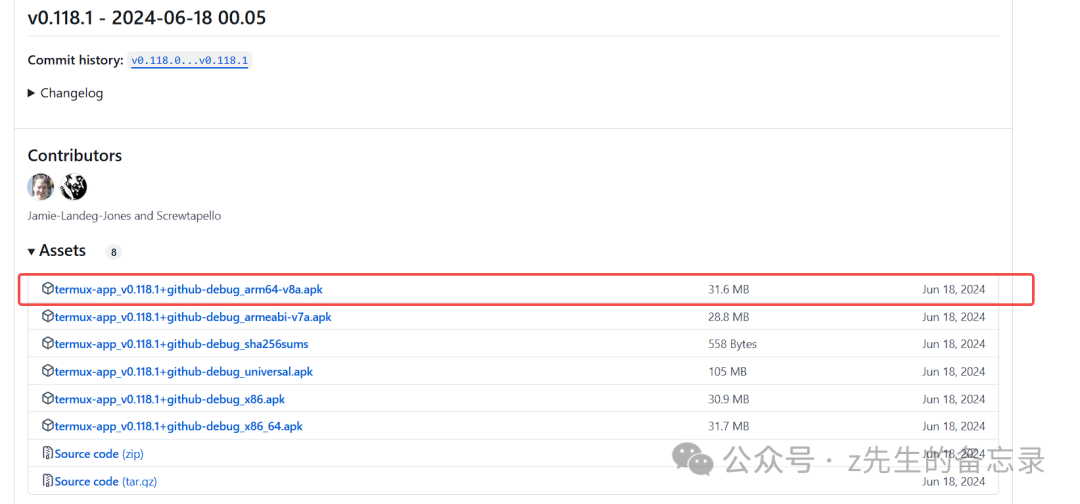 我这边是之前的旧手机Redmi Note 7pro;
我这边是之前的旧手机Redmi Note 7pro;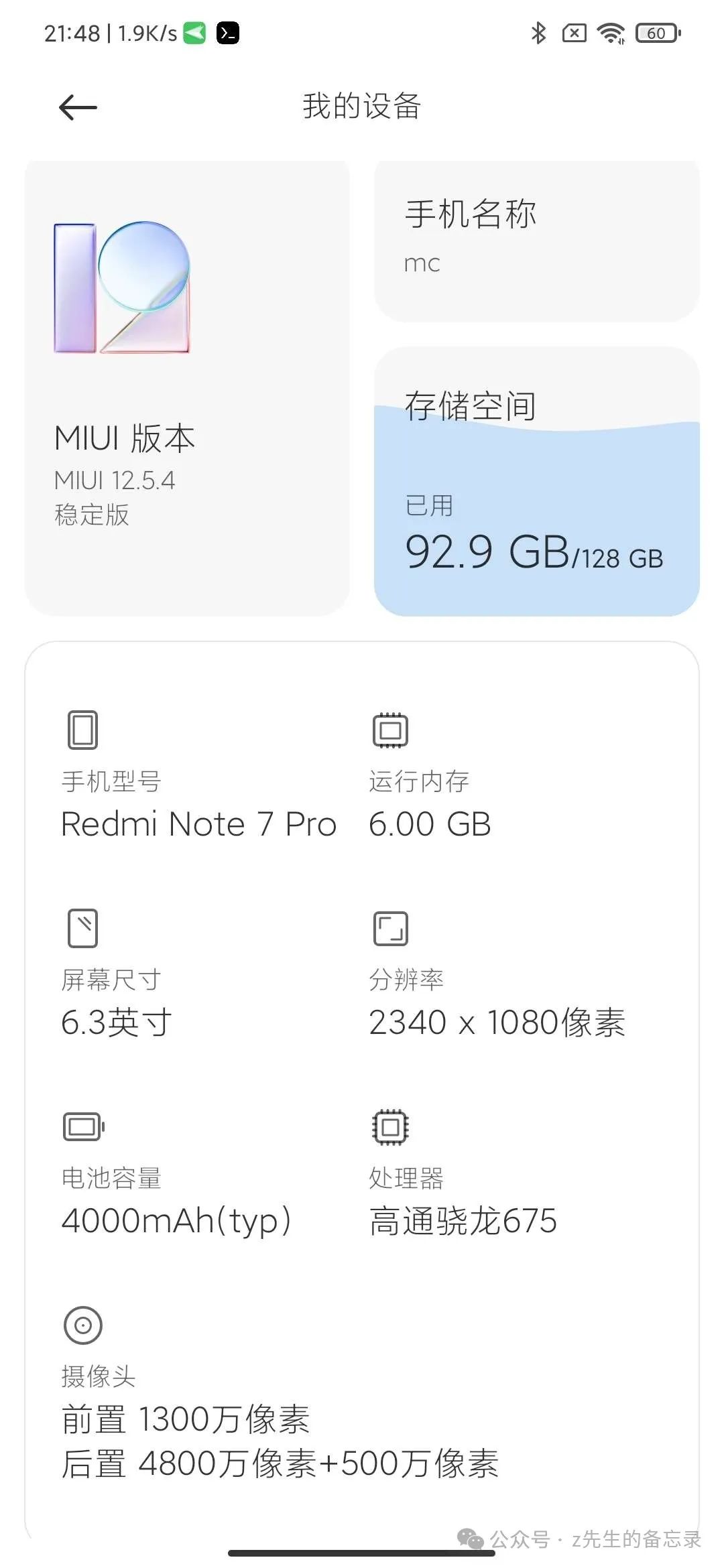
第2步: 配置ollama软件运行环境
访问手机目录
# 在termux中访问手机的目录文件 termux-setup-storage ls storage/downloads/
在termux中执行的效果,这是我手机的Download下对应的文件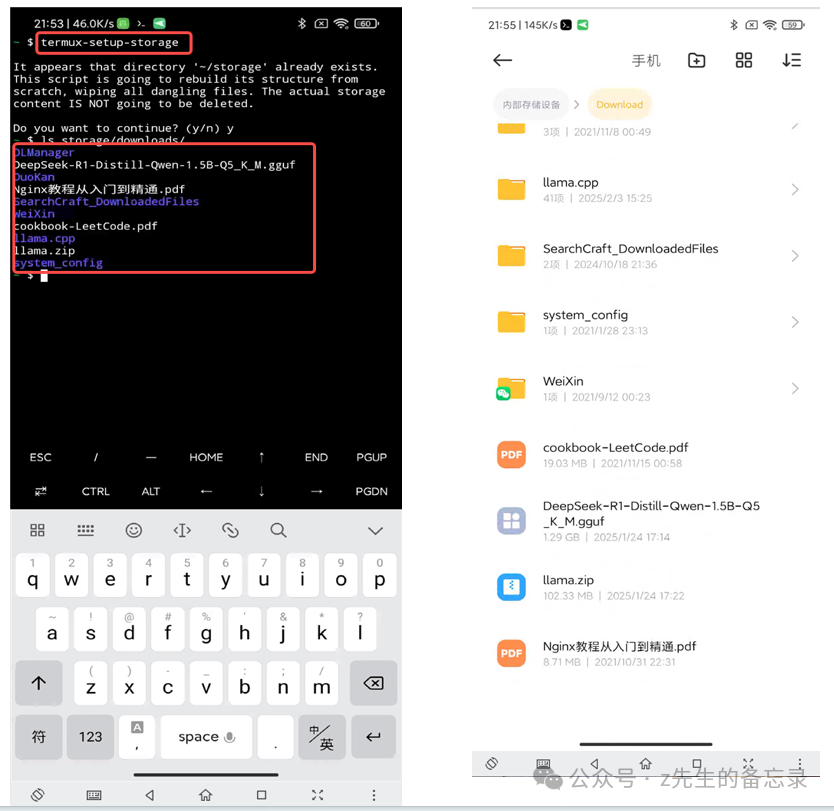
安装对应的运行环境
# 先来安装proot-distro pkg install proot-distro # 使用proot-distro安装一个ubuntu proot-distro install ubuntu # 安装成功后通过login命令就直接进入ubuntu,为发行版启动一个root shell #proot-distro login ubuntu proot-distro login ubuntu --bind "${HOME}/storage:/mnt/storage"
执行完成后,可以看出其已经成功进入ubuntu虚拟环境中并具备root全智贤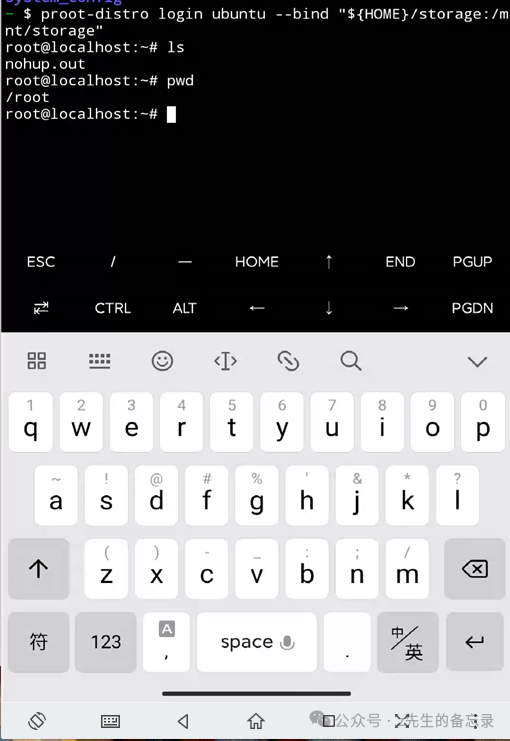
安装ollama软件
curl -fsSL https://ollama.com/install.sh | sh ollama serve & #让ollama服务在后台运行 # 安装完毕可以查看ollama版本进行验证,出现版本号之后就可以使用ollama ollama -v
最后输出的效果: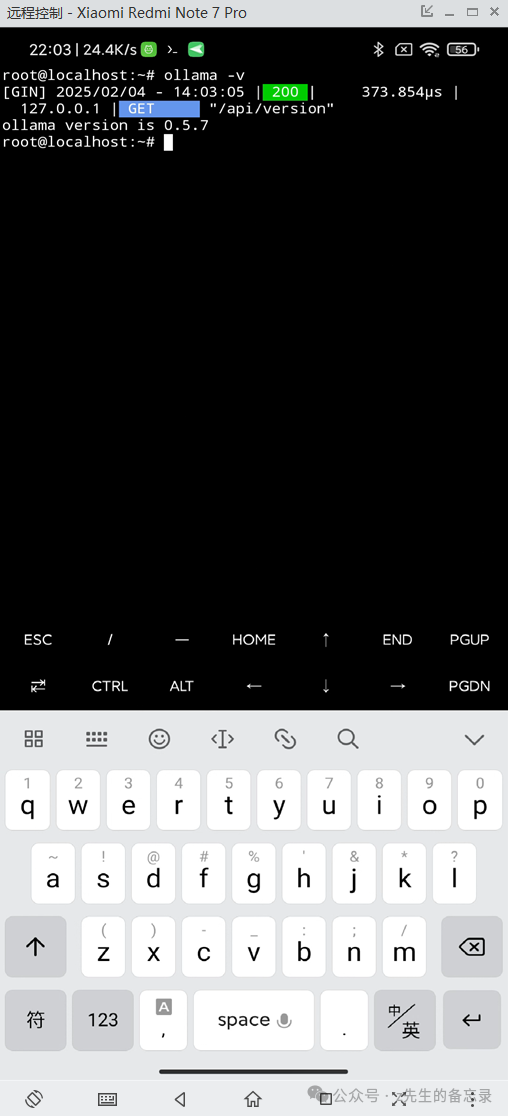
第3步:下载deepseek-R1模型
你可以下载其他任何大模型,这里以deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B模型为例子,详情见:https://hf-mirror.com/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B.拉取deepseek-r1:1.5b模型:
!ollama pull deepseek-r1:1.5b !ollama list
最后执行的效果如下: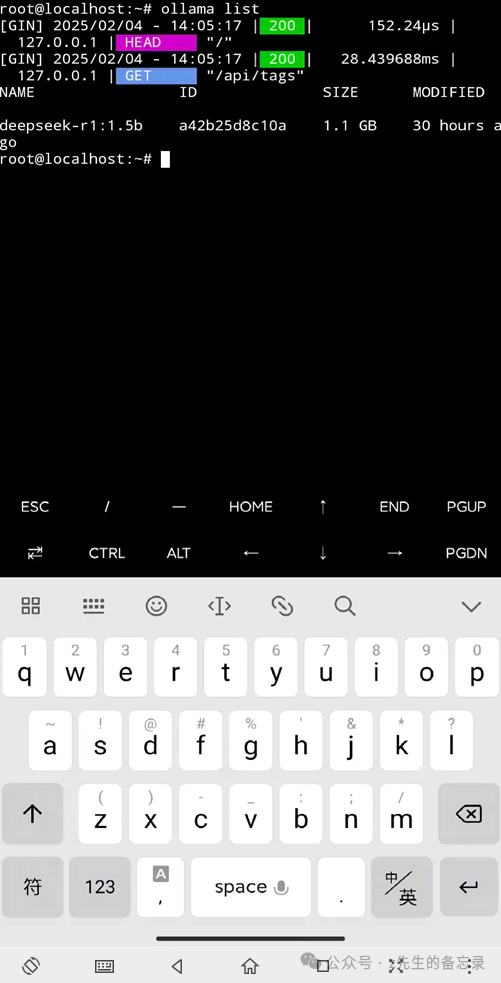
第4步:运行DeepSeek-R1 蒸馏1.5B模型进行推理聊天
ollama run deepseek-r1:1.5b
我的小米redmi note7pro手机的执行效果如下:
DeepSeek-R1大模型爆火,由于性能出众而倍受好评。但是也迎来一个不争的事实,当DeepSeek-R1有板有眼回答你的问题(例如通过列举错误的文献、数据、表格来佐证你的问题时),你是否能够一眼发现它是错误的呢?23年大模型刚出来的时候,大模型性能差,一顿乱说,你可以轻松知道模型幻觉严重。那现在呢?以后如何准确评估模型回答是否正确将是一件非常难、并且耗时的事情。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









