






一、QwQ 介绍
阿里巴巴通义千问团队今日正式发布实验性研究模型 QwQ-32B-Preview,并配以博文《QwQ: 思忖未知之界》详解其设计理念与性能表现。作为一款专注数学与编程推理的开源大模型,QwQ-32B-Preview 成为全球首个以宽松许可(Apache 2.0)提供的同类领先模型,并在多个基准测试中超越 OpenAI 的 o1-preview 模型。

阿里团队将 QwQ 比喻为“探索未知领域的学徒”,具备在复杂数学、编程推理中的优异表现,尤其在深度逻辑与科学问题的解决上表现突出。其开放性是另一大亮点,作为 Apache 2.0 许可证下的模型,QwQ 可用于商业应用,无需受到诸多开源协议限制。
模型拥有 325 亿参数,支持长达 32000 tokens 的输入提示词,这为长文档理解及复杂任务处理提供了极大便利。
QwQ-32B-Preview 在多个数学与编程领域的基准测试中,展现了其卓越能力:
-
MATH-500:该模型在包含500个数学测试样本的评测集上,取得 90.6% 的成绩,远超同类模型,展示出对代数、几何、数论等主题的全面掌握。
-
AIME:涵盖中学数学各类主题的评测中,QwQ 得分 50.0%,表现出卓越的数学问题解决能力。
-
GPQA:该基准测试模拟科学解题场景,QwQ 评分 65.2%,达到了研究生水平的科学推理能力。
-
LiveCodeBench:在评估编程实际问题解决的高难度测试中,QwQ 成绩为 50.0%,验证了其在真实编程场景下的强大生成能力。
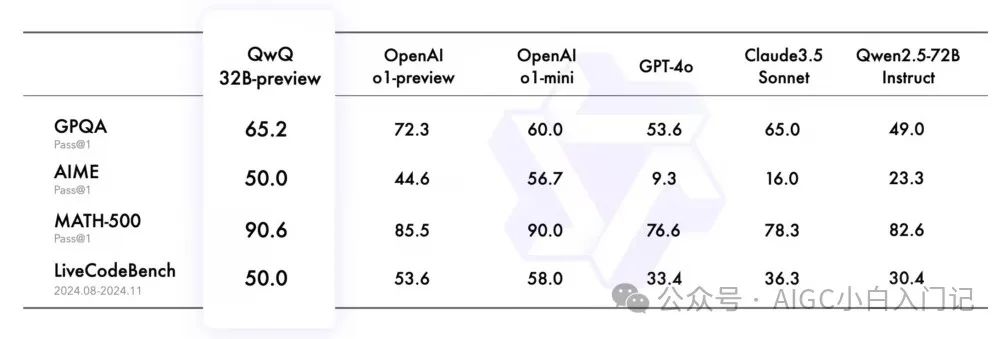
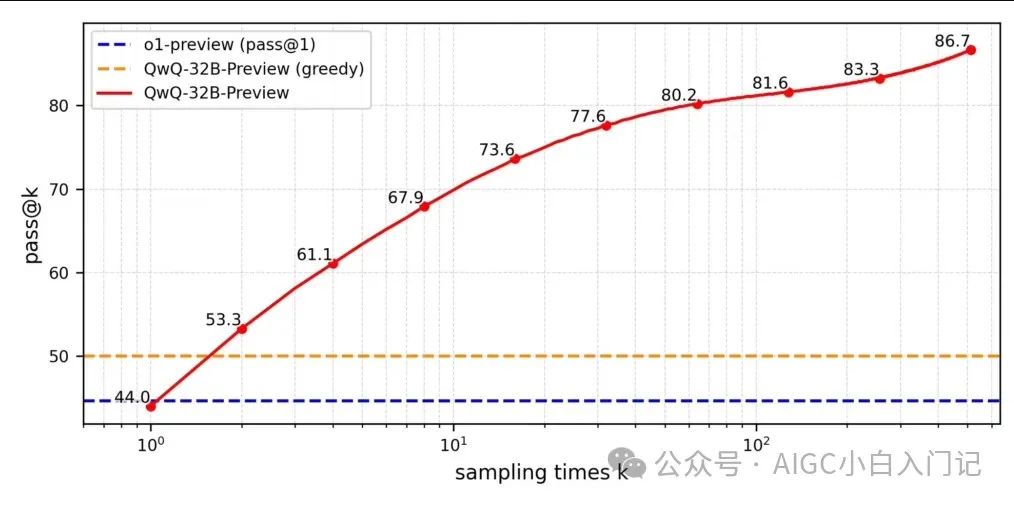
这些数据表明,QwQ 已在推理与解决复杂问题上达到业内顶尖水平,成为少数能与 OpenAI o1 模型正面对抗的开源模型。
尽管 QwQ 具备强大的推理能力,阿里团队在博文中坦承其仍存在以下局限:
-
语言切换问题:回答时可能混用多种语言,影响表达的连贯性。
-
推理循环:在处理复杂逻辑问题时,模型可能陷入递归推理模式,导致回答冗长而不够聚焦。
-
安全性不足:当前安全管控能力有限,可能生成不恰当或存在偏见的回答,生产环境中需谨慎使用并部署额外防护措施。
-
领域能力差异:在数学和编程领域表现卓越,但其他专业领域仍有待优化。
1.5 QwQ-32B-Preview的适用场景
QwQ-32B-Preview模型以其在数学、编程和科学问题解决方面的优势,适用于多个领域和场景:
-
复杂数学问题求解: QwQ-32B-Preview在解决复杂数学问题方面表现出色,尤其在GPQA、AIME、MATH-500等基准测试中展现了卓越的能力。它能够处理从基础算术到高等数学的广泛问题,为教育和研究提供了强大的支持。
-
编程挑战和算法开发: 在LiveCodeBench评测集中,QwQ-32B-Preview取得了50.0%的分数,证明了其在实际编程场景中的实用性。它可以帮助开发者解决编程难题,提供代码示例,甚至帮助优化现有代码。
-
科学研究中的逻辑推理: QwQ-32B-Preview的推理能力使其成为科研领域的重要工具。它可以帮助研究人员进行数据分析、模型构建和理论推导,尤其在需要深度思考的场景中。
-
需要深度分析的技术性任务: 模型在多个学术和技术基准测试中展现了显著的性能,使其适合于需要深度分析的技术性任务。
-
教育辅助: QwQ-32B-Preview提供数学问题的逐步解答和编程难题的解决方案,帮助学生理解复杂概念。
-
自动化编程: 辅助软件开发,基于生成代码片段或完整的代码加速开发过程。
-
智能助手: 作为个人或企业的智能助手,提供决策支持和问题解决策略。
-
金融分析: 在金融领域,QwQ-32B-Preview可以用在风险评估、市场预测和算法交易。
二、⏳ Download Models
Qwen/QwQ-32B-Preview
`from modelscope import snapshot_download` ` model_dir = snapshot_download("Qwen/QwQ-32B-Preview", cache_dir='./')`
三、Inference
from modelscope import AutoModelForCausalLM, AutoTokenizer``model_name = "Qwen/QwQ-32B-Preview"``model = AutoModelForCausalLM.from_pretrained(` `model_name,` `torch_dtype="auto",` `device_map="auto"``)``tokenizer = AutoTokenizer.from_pretrained(model_name)``prompt = "How many r in strawberry."``messages = [` `{"role": "system", "content": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step."},` `{"role": "user", "content": prompt}``]``text = tokenizer.apply_chat_template(` `messages,` `tokenize=False,` `add_generation_prompt=True``)``model_inputs = tokenizer([text], return_tensors="pt").to(model.device)``generated_ids = model.generate(` `**model_inputs,` `max_new_tokens=512``)``generated_ids = [` `output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)``]``response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]``print(response)
输出 1
User:How many r in strawberry.``QwQ-32B-Preview:``Let's see. The word is "strawberry." I need to find out how many 'r's are in it. Okay, first, I'll spell it out slowly: s-t-r-a-w-b-e-r-r-y. Hmm, I can see that there are 'r's in there. Let me count them one by one.``So, starting from the beginning:``First letter: s, no 'r'.``Second letter: t, no 'r'.``Third letter: r, that's one 'r'.``Fourth letter: a, no 'r'.``Fifth letter: w, no 'r'.``Sixth letter: b, no 'r'.``Seventh letter: e, no 'r'.``Eighth letter: r, that's another 'r'.``Ninth letter: r, yet another 'r'.``Tenth letter: y, no 'r'.``So, I've found three 'r's in "strawberry." But wait, let me double-check to make sure I didn't miss any or count incorrectly.``Spelling it again: s-t-r-a-w-b-e-r-r-y.``Looking at each letter:``3rd letter: r``8th letter: r``9th letter: r``Yes, that's three 'r's. I think that's correct.``Alternatively, sometimes people might miscount if the letters are close together, but in this case, it's straightforward.``So, the answer is three 'r's in "strawberry."``**Final Answer**``\[ \boxed{3} \]

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 686
686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









