






前言
2025年春节期间AI圈deepseek 这家公司在国外大模型火的不要不要的。deepseek官方网站受到国外DDos攻击,目前网络访问不是很通畅。2月1日国内硅基流动 x 华为云联合推出基于昇腾云的 DeepSeek R1 & V3 推理服务!我这2天使用起来效果还不错,支持一波国产化大模型,今天就带大家体验一下基于 DeepSeek R1 & V3 模型的AI资讯每日新闻+语音播报工作流的工作流。
下面我们首先介绍一下整体功能。
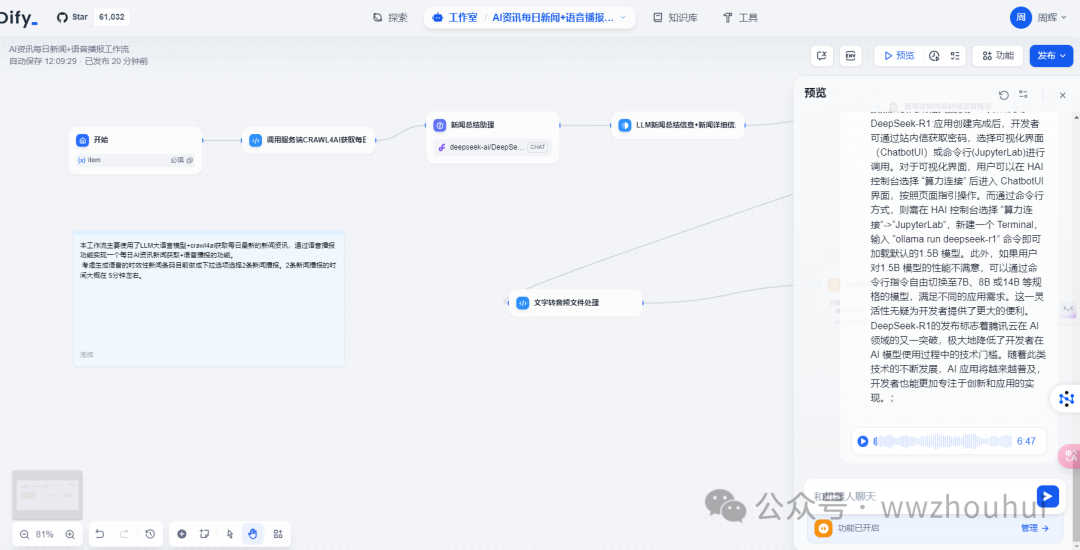
实现的效果如下:
上面的工作流主要由几块组成,其中难点是使用到了crawl4ai 爬取AI新闻资讯网站获取每日最新的新闻资讯,这块内容我们通过python代码编写来实现的,然后对dify提供http请求接口,然后就是通过大语言模型DeepSeek R1 & V3 模型对其获取的新闻内容进行总结,然后在调用我们之前讲过的自定义第三方语音TTS来实现的。其中TTS语音的模型也是硅基流动提供的FunAudioLLM/CosyVoice2-0.5B模型来实现。总体的流程大致就上面所述,下面介绍一下这个工作流节点详细内容。
工作流实现
1.开始
这个开始节点我们这里设置了一个新闻获取条数,主要通过下拉选项来实现的。
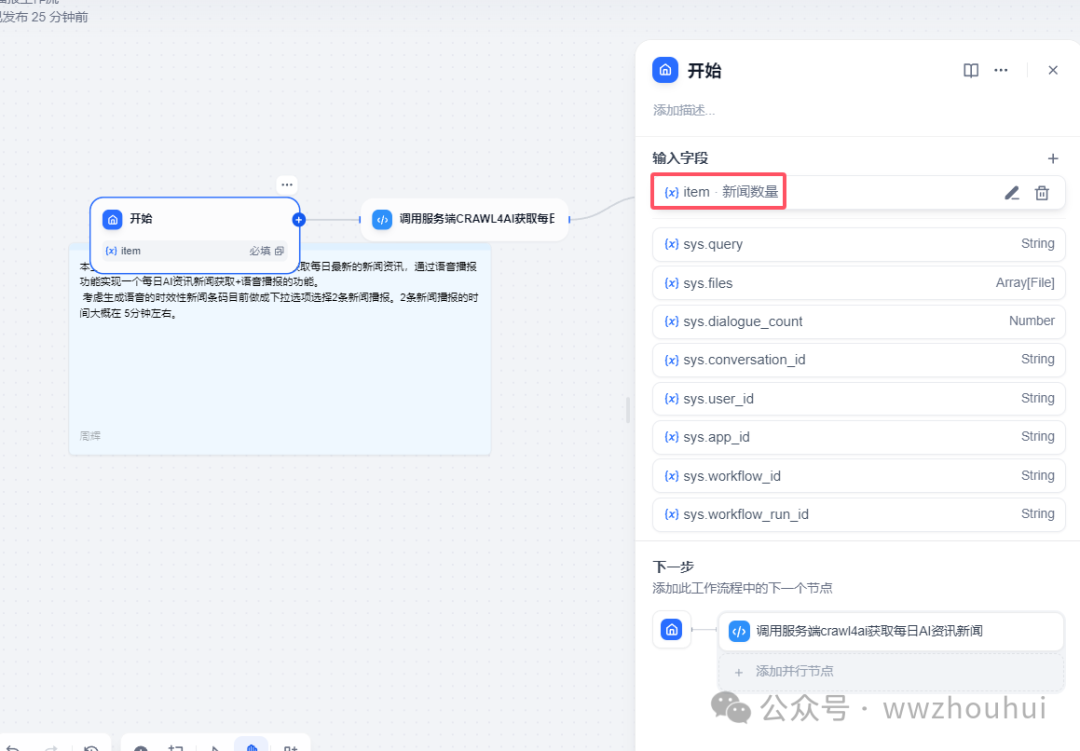
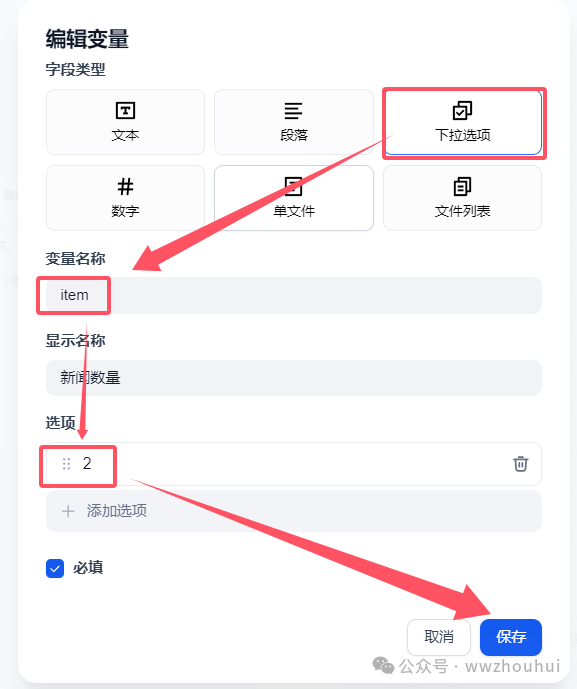
这里考虑模型对文本总结的时间以及生成 语音TTS时间我们设置2条新闻。(设置的新闻条目越多,工作处理的时间也会越长)
2.代码处理
这个地方主要是我们用到了crawl4ai 这个爬虫框架,通过这个爬虫程序来实现AI新闻的获取。我们这里使用fastapi做成一个http请求接口提供dify 调用
服务端代码如下:
import json
import requests
from bs4 import BeautifulSoup
from fastapi import FastAPI, Query
from crawl4ai import AsyncWebCrawler
from crawl4ai.extraction_strategy import JsonCssExtractionStrategy
app = FastAPI()
# 获取新闻列表页面的所有新闻URL
def get_news_urls():
url = "https://www.aibase.com/zh/news"
response = requests.get(url)
news_urls = []
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有新闻链接
news_items = soup.find_all('a', href=True)
for item in news_items:
link = item['href']
# 过滤出符合新闻详情页的链接
if '/zh/news/' in link and len(link.split('/')) > 3:
full_url = f"https://www.aibase.com{link}"
news_urls.append(full_url)
else:
print(f"请求失败,状态码: {response.status_code}")
return news_urls
# 提取单个新闻文章的数据
async def extract_ai_news_article(url):
print(f"\n--- 提取新闻文章数据: {url} ---")
# 定义提取 schema
schema = {
"name": "AIbase News Article",
"baseSelector": "div.pb-32", # 主容器的 CSS 选择器
"fields": [
{
"name": "title",
"selector": "h1",
"type": "text",
},
{
"name": "publication_date",
"selector": "div.flex.flex-col > div.flex.flex-wrap > span:nth-child(6)",
"type": "text",
},
{
"name": "content",
"selector": "div.post-content",
"type": "text",
},
],
}
# 创建提取策略
extraction_strategy = JsonCssExtractionStrategy(schema, verbose=True)
# 使用 AsyncWebCrawler 进行爬取
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(
url=url,
extraction_strategy=extraction_strategy,
bypass_cache=True, # 忽略缓存,确保获取最新内容
)
if not result.success:
print(f"页面爬取失败: {url}")
return None
# 解析提取的内容
extracted_data = json.loads(result.extracted_content)
print(f"成功提取新闻: {extracted_data[0]['title']}")
return extracted_data[0]
# 主函数:获取所有新闻URL并逐一提取详细数据
async def fetch_news(limit: int = 5):
# 获取所有新闻URL
news_urls = get_news_urls()
print(f"共找到 {len(news_urls)} 条新闻链接")
# 限制新闻数量
news_urls = news_urls[:limit]
news_data_list = []
newsdetail = ""
# 循环处理每个新闻URL
for index, url in enumerate(news_urls, start=1):
news_data = await extract_ai_news_article(url)
if news_data:
# 添加到新闻数据列表
news_data_list.append(news_data)
# 拼接新闻详情字符串
content = news_data.get("content", "无法提取内容")
newsdetail += f"今天新闻第{index}条内容:{content};\n"
return news_data_list, newsdetail
# FastAPI 接口
@app.get("/news/")
async def get_news(limit: int = Query(5, description="返回的新闻数量")):
news_data, newsdetail = await fetch_news(limit)
return {"news": news_data, "newsdetail": newsdetail}
# 运行 FastAPI 应用
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8086)
这服务端代码主要的目的就是爬取https://www.aibase.com 最新的新闻资讯。将以上代码部署到服务器中,如果没有服务器可以在本地电脑上部署一个python服务,这里我们就不详细展开,不懂的小伙伴可以私信我。
接下来我们需要dify工作流中使用代码执行来调用这个服务端代码。
客户端调用代码如下:
import requests
import json
def main(arg1: str) -> dict:
try:
# 构造请求URL和参数
url = 'http://127.0.0.1:8086/news/'
limit = arg1
# 发送GET请求
response = requests.get(url, params={'limit': limit})
# 检查响应状态码
if response.status_code == 200:
# 请求成功,处理结果
result = response.json()
# 提取新闻数据和新闻详情字符串
news_list = result.get('news', [])
newsdetail = result.get('newsdetail', "")
# 确保 news_list 是一个列表
if not isinstance(news_list, list):
return {"error": "服务端返回的新闻数据格式不正确,'news' 字段应为列表。"}
# 格式化新闻数据(如果需要)
formatted_news = []
for news_item in news_list:
if isinstance(news_item, dict): # 如果是字典,直接添加
formatted_news.append(news_item)
elif isinstance(news_item, str): # 如果是字符串,尝试解析为字典
try:
news_dict = json.loads(news_item) # 使用 json.loads 解析字符串
formatted_news.append(news_dict)
except Exception as e:
print(f"解析新闻数据时出错: {e}")
else:
print("无效的新闻数据格式")
# 返回格式化的新闻数据和新闻详情字符串
return {"news": formatted_news, "newsdetail": newsdetail}
else:
# 请求失败,返回错误信息
return {"error": f"请求失败,状态码: {response.status_code}"}
except requests.exceptions.RequestException as e:
# 捕获请求异常
return {"error": f"请求出错: {str(e)}"}
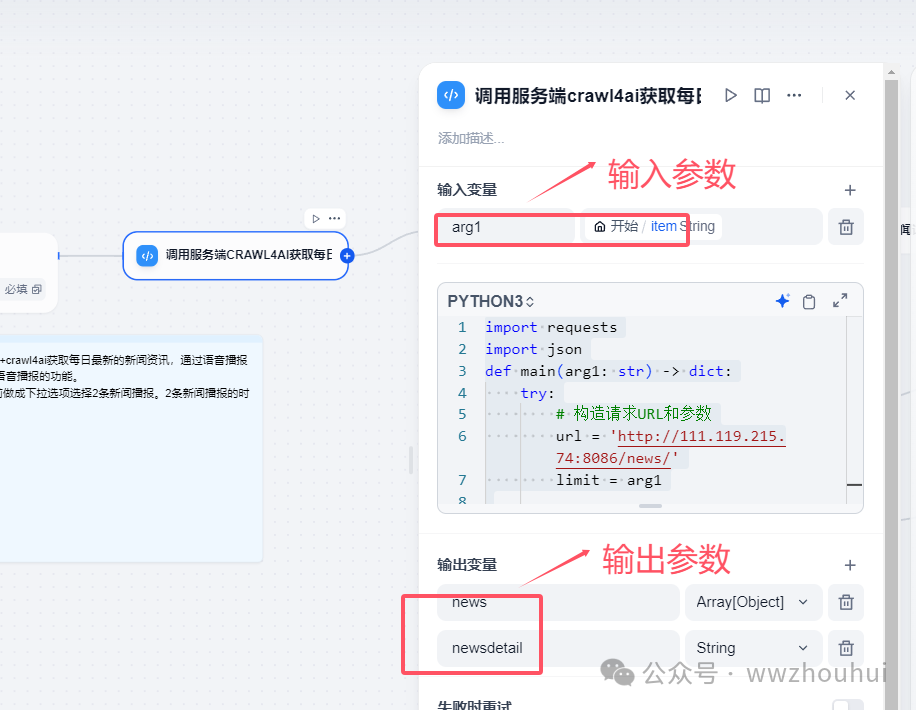
这个我们简单解释一下,输入参数就是开始节点中item值;输出变量有2个 一个是news 数据类型是个数组,第二个参数是newsdetail 是新闻详细内容。
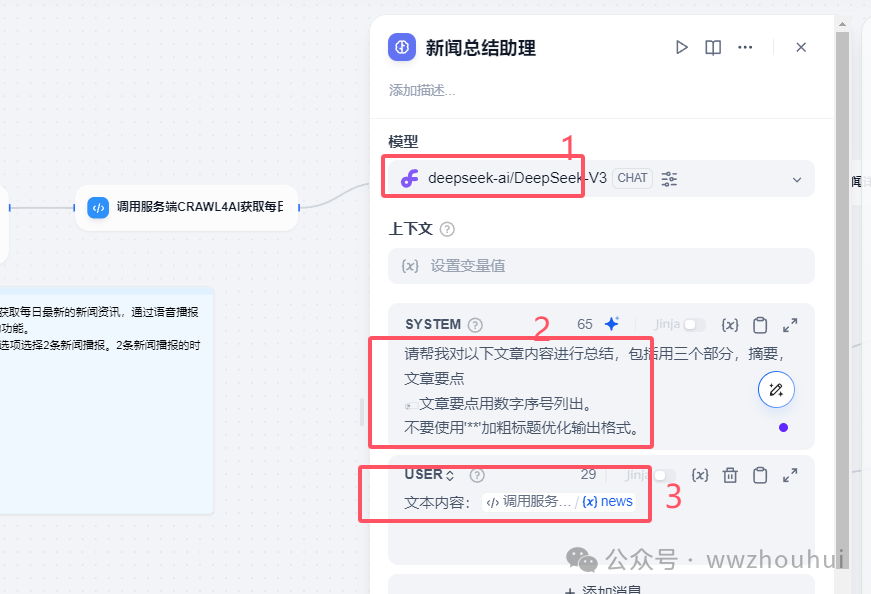
3.llm大语言模型
接下来这块就是我们非常熟悉的llm大语言模型的部分了,我们这里用到了硅基流动提供的 DeepSeek V3 模型。
关于硅基的模型可以在官方网站获取详细信息。
系统提示词
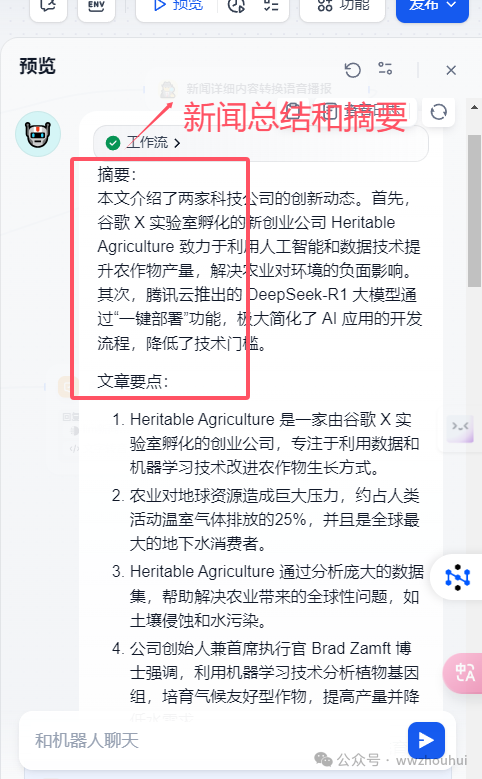
请帮我对以下文章内容进行总结,包括用三个部分,摘要,文章要点 🏷文章要点用数字序号列出。 不要使用'**'加粗标题优化输出格式。
系统提示词比较简单,主要就是让模型给我把详细AI新闻总结 摘要,文章要点等信息。
用户提示词
这个用户提示词就是上个节点中出来的news信息
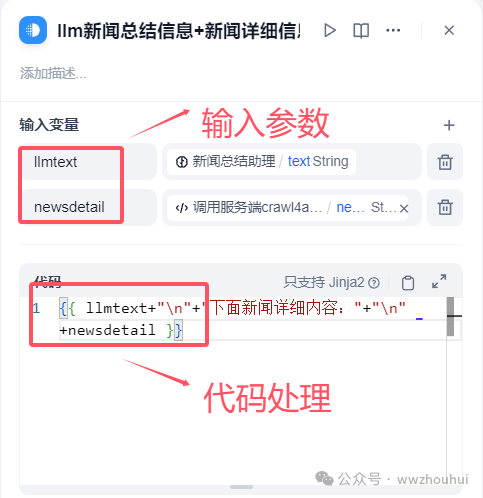
4.模版转换
这个工作流节点主要用到了模版转换功能,主要目的是将llm大语言模型总结的信息和新闻详细信息通过字符串拼接起来。
输入变量有2个,1个是llmtext ,1个是newsdetail。主要的功能就是字符串的拼接。
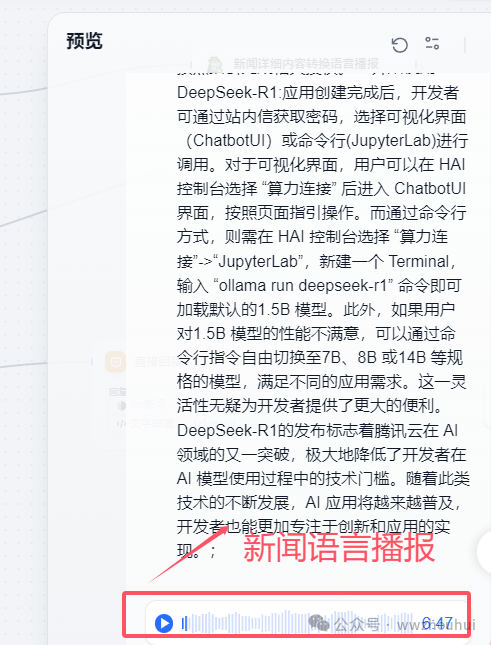
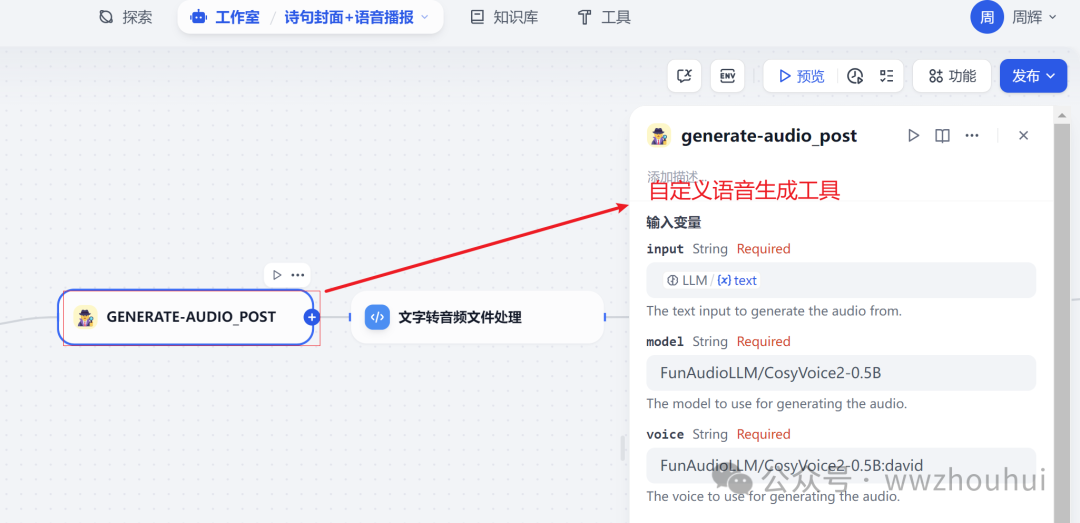
5.语音播报
这个地方就是调用了第三方自定义的语音播报插件功能。
这里我们拖拽一个自定义工具实现文本转语音。
在工作流 画布中 点击“添加节点”- 选择工具- 自定义工具-选择自定义工具
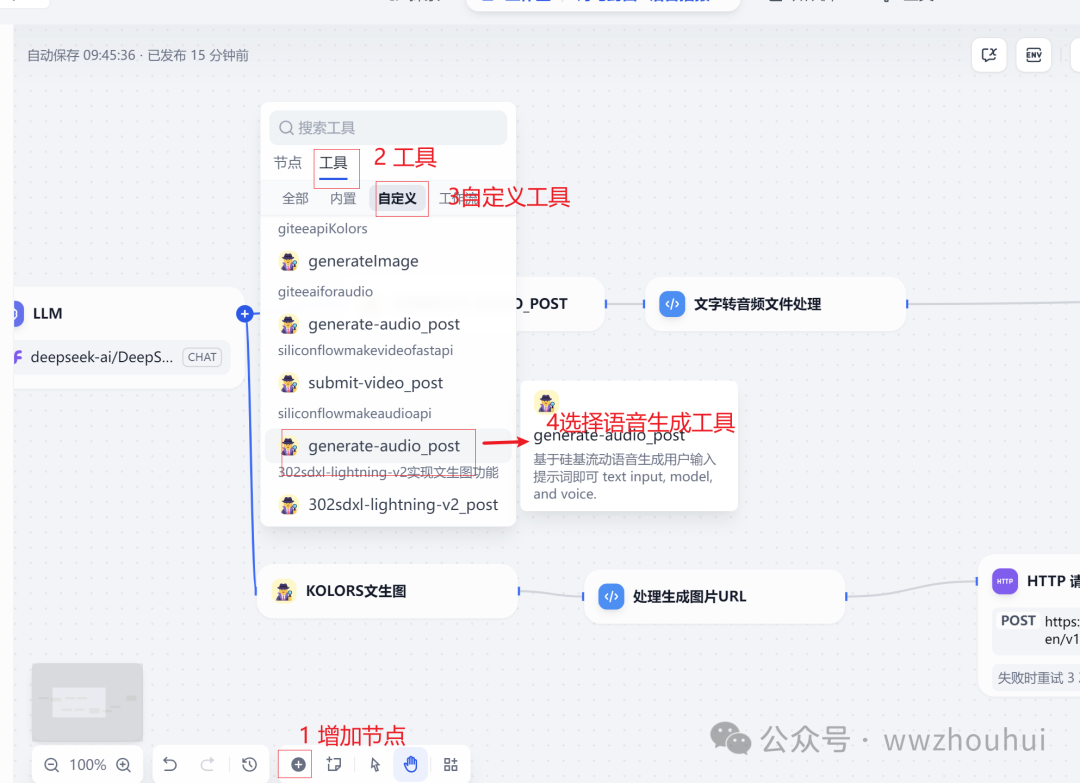
关于自定义工具,这里有3个参数。
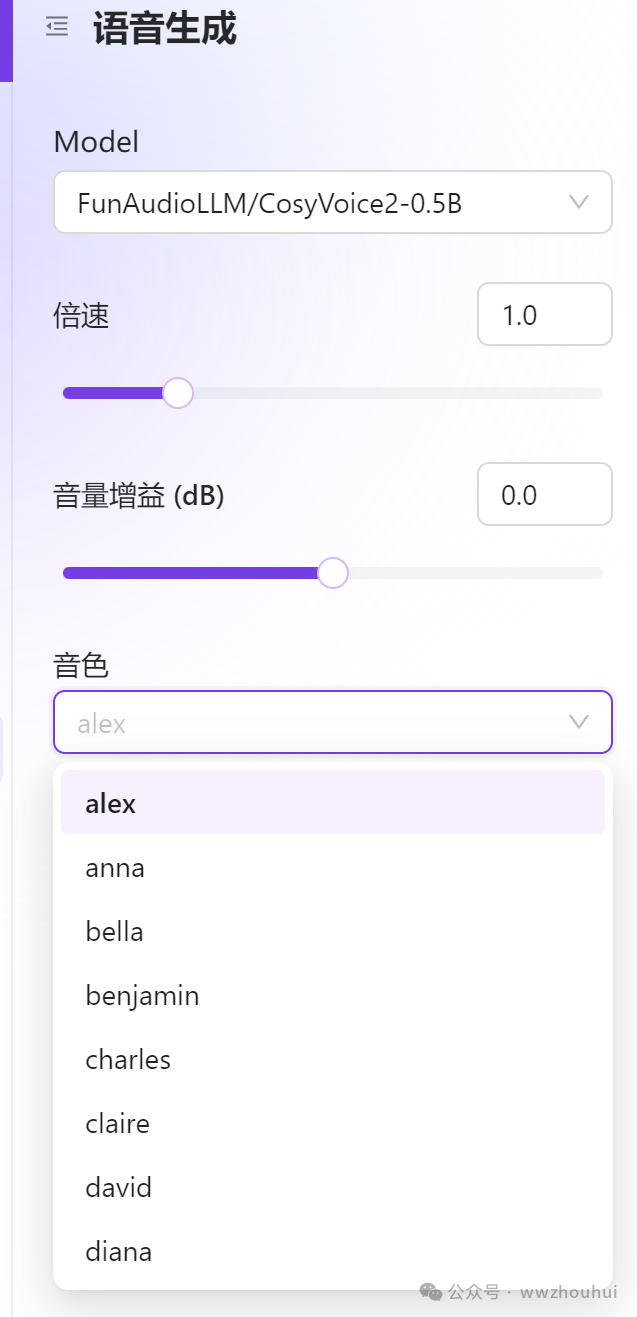
1.input 用户输入的提示词。这里我们直接接入上面流程中文本翻译的结果即可。
2.model 这个主要是填写语音翻译的模型,我这里填写的是FunAudioLLM/CosyVoice2-0.5B
3.voice 这里主要是填写模型对应的音色, 我这里填写的是FunAudioLLM/CosyVoice2-0.5B:david
我这里用到了硅基的模型,这里是需要根据他们的API 来填写。
关于这块代码,我已经上传github,大家自行获取。地址(https://github.com/wwwzhouhui/dify-for-dsl/tree/main/dsl/difyforsiliconflow)
流程节点截图如下
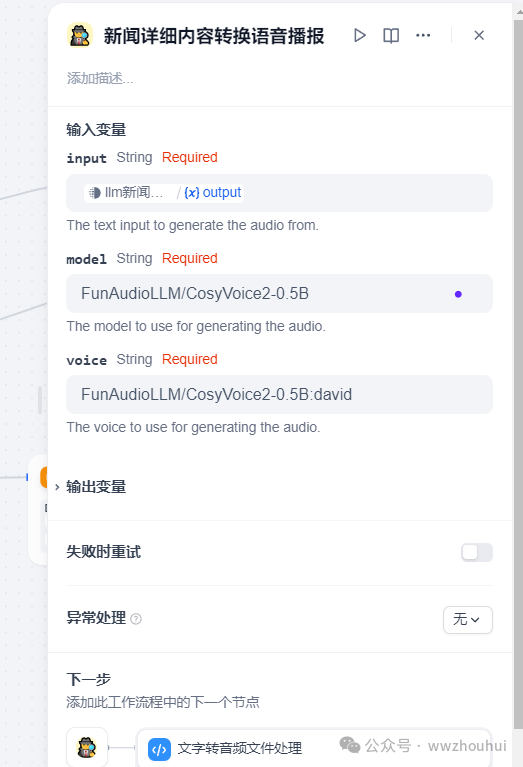
文字转音频文件处理
接下来我们需要有个代码转换对上个节点中自定义工具返回数据进行处理。
输入的参数就是arg1 它的值就是自定义工具返回数据字符串
代码如下
def main(arg1: str) -> str:
# 首先解析外层的 JSON 字符串
data = json.loads(arg1)
filename=data['filename']
url=data['etag']
markdown_result = f"<audio controls><source src='{url}' type='audio/mpeg'>{filename}</audio>"
return {"result": markdown_result}
这个代码主要目的处理返回结果后生产TTS语言播报markdown_result

7 直接回复
这个节点就比较简单的主要是目的是输出LLM大语言模型总结的AI新闻内容,在把语音播报的TTS语音部分输出出来。
有2个输出参数,一个是模版转换的文本内容,一个是文字转音频文件处理结果
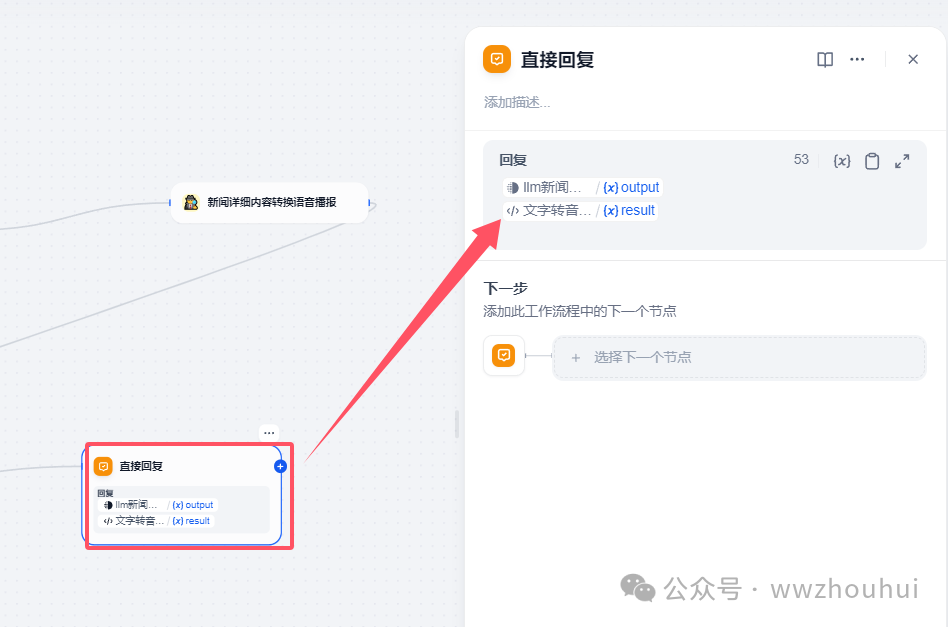
以上我们就完成了工作流的配置。
工作流体验
大家可以点击这个体验地址(http://101.126.84.227:88/chat/sGsc8dVLyFHODT0V)来感受一下,效果如下:

如果大家没有硅基流动的账号,可以点击https://cloud.siliconflow.cn/i/e0f6GCrN地址来注册,目前硅基的政策是新户注册送14块钱,14块钱够玩一阵子了。
10 .总结
今天我们给大家带来使用硅基流动的模型DeepSeek R1 & V3 加语音播报实现一个AI每日新闻资讯的+语音播报的工作流。感兴趣的小伙伴可以参考我上面的文档操作一遍,体验一下DeepSeek R1 & V3 模型的强大,今天的分享就到这里我们下个文章见。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 2603
2603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









