






前言
有如下几点更新(省流版):
-
上下文长度更长:支持的上下文长度由64k->128k,上下文理解能力增强,并支持更长的上下文长度;
-
参数量更大:参数量由原来的671b,增加到685b;
-
编程、数学能力显著提升;
-
生成速度更快:从20 TPS提升至60 TPS(不过这个肯定还是吃算力,以及服务器压力过大的话也会变慢);
-
多位博主实测,其生成网页,svg等页面的审美大幅提升,直逼Claude3.7。
我是第一时间接入dify进行了实测:
用dify的多模型调试功能,对比了新版DeepSeek V3和旧版DeepSeek V3的知识库问答效果,发现使用新版效果提升非常明显!
所以我第一时间就让客户把V3模型更新到新版使用了
接下来我带大家在dify接入新版deepseek v3,并看下实测效果。
获取新版DeepSeek V3 API
老规矩,要想接入大模型就要获取老三样:
模型名称、API地址、apikey
而openrouter真滴卷,deepseek昨天才开源的新版deepseek v3,它立马就上线了(关键api还是免费使用)。
甚至连deepseek官网都没有通知,我都不知道deepseek官方api到底有没有更新到新版v3,而且就算更新了,估计调用的人也很多,到时候可能又会卡
openrouter地址:
https://openrouter.ai/
访问openrouter,首页就能看到新版V3,点击进入
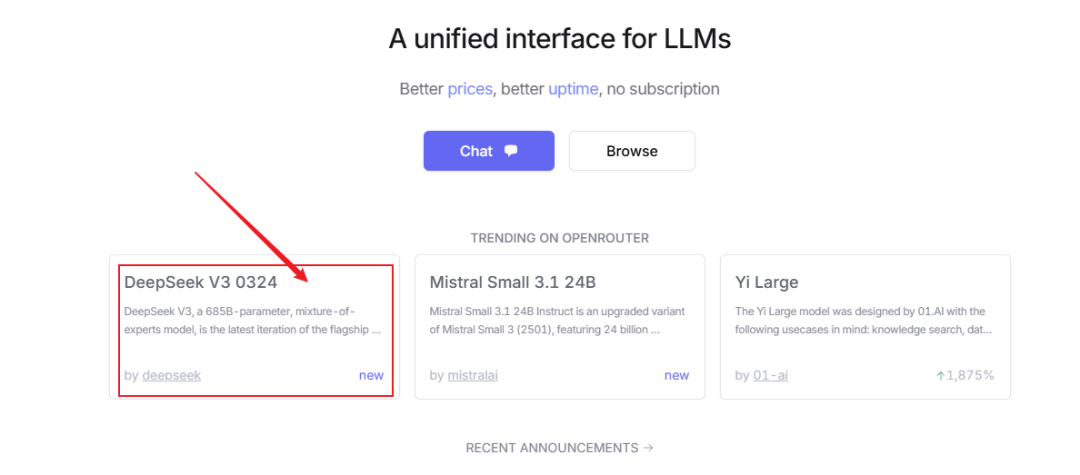
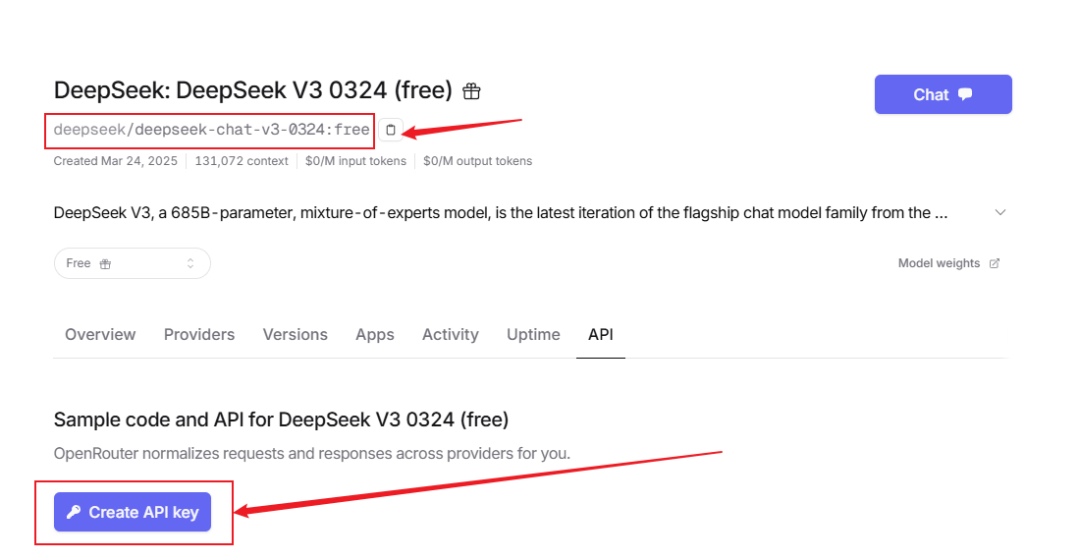
模型名称: deepseek/deepseek-chat-v3-0324:free
如果没有apikey可以先创建
顺便说一下API地址是:
https://openrouter.ai/api/v1
接入dify并测试知识库效果
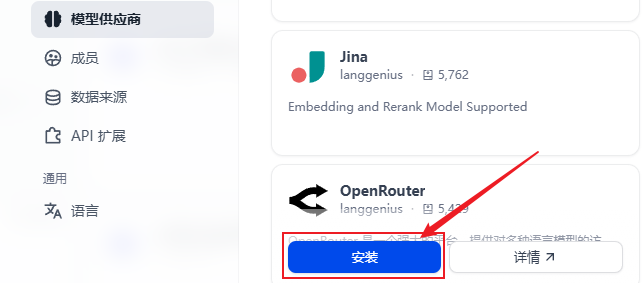
进入dify->右上角头像->设置->模型供应商
找到openrouter,点击安装
因为是调用github,可能会有点慢,或者失败,多试几次即可
在安装好的供应商列表找到openrouter,点击设置
把openrouter的apikey粘贴到下图位置,保存
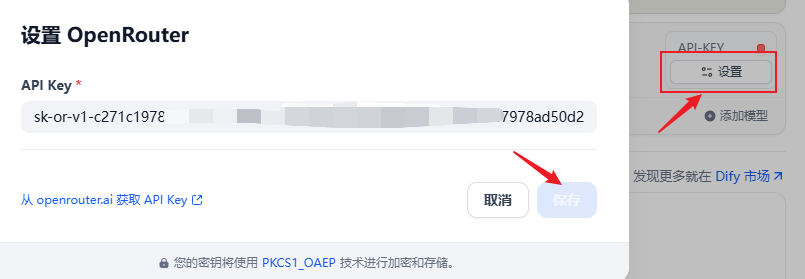
这里会自动读取相关模型,但是自动读取到的模型里面并没有新版deepseek v3,所以我们需要额外添加
点击添加模型,填写模型名称和apikey,保存
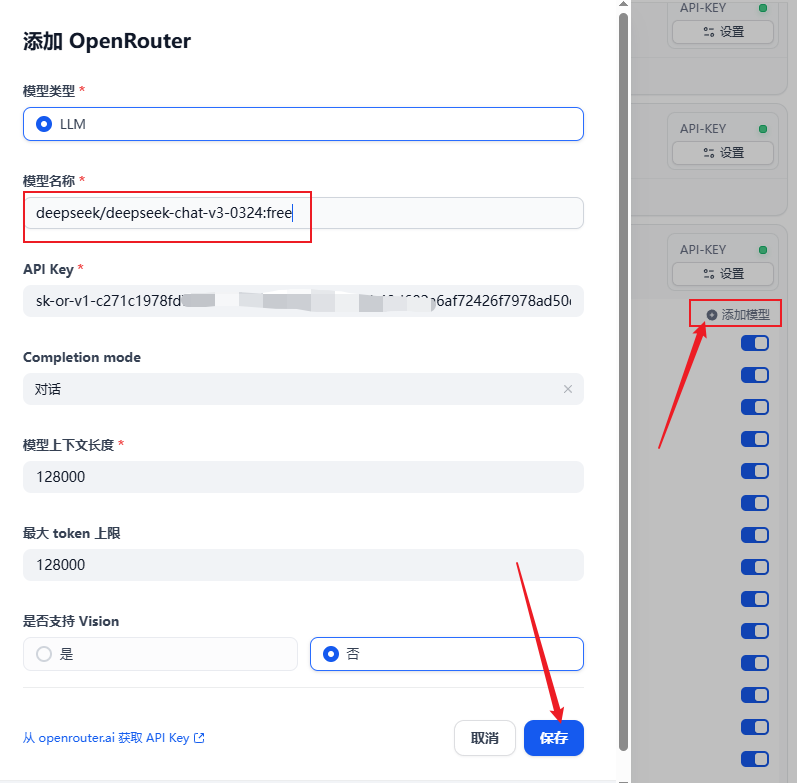
接下来,我直接用上次测试minimax-01的知识库来对新版deepseek v3进行测试。
感兴趣的朋友可以看下之前这篇:使用了不同的方式构建知识库,并且当你的知识库内容非常庞大的时候,更适合用minimax-01
在bot的编辑页面,点击模型参数配置->多个模型进行调试
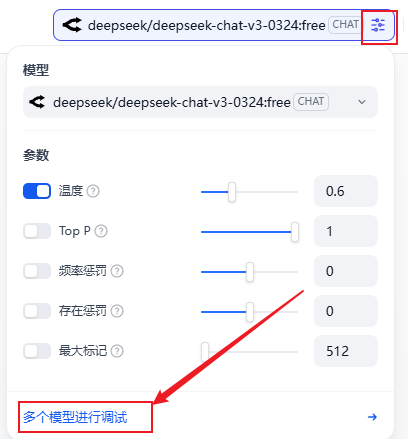
这里我开了两个模型,一个是刚刚配置的openrouter的新版v3,一个是硅基流动的旧版v3
这时,我在输入框发送一个问题,两边就会同时执行,用来测试不同模型的效果非常方便、直观。
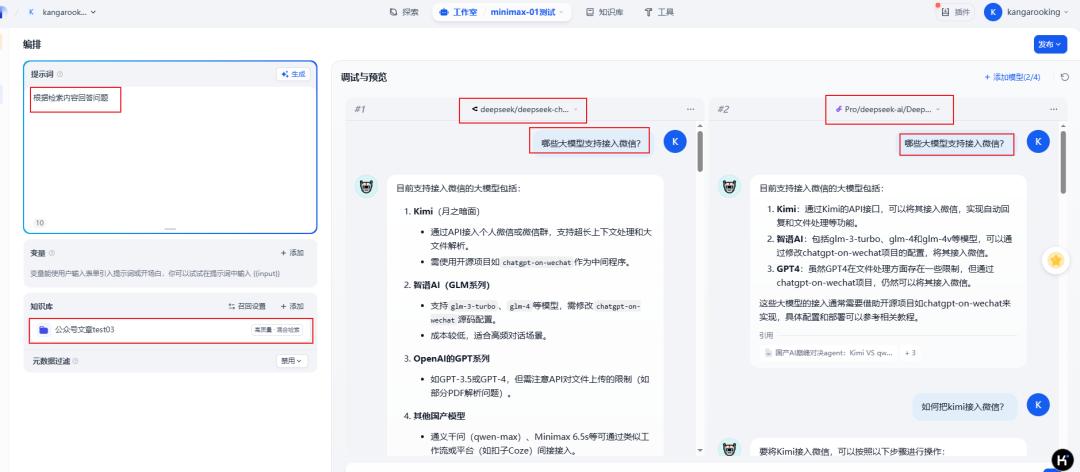
从上面第一个问题可以看出,虽然两边都回答正确,但是新版v3更详细。
我们在看看第二个问题(下图)
回答的内容都正确,但还是新版V3更详细(左边新版V3,右边旧版V3)
看看第三个问题: 有哪些浏览器插件?(下图)
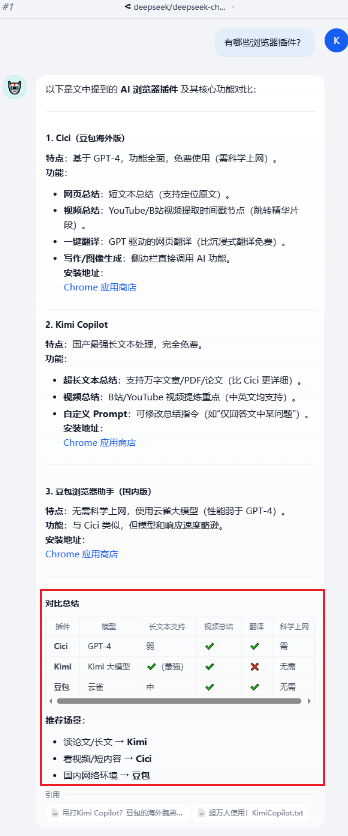
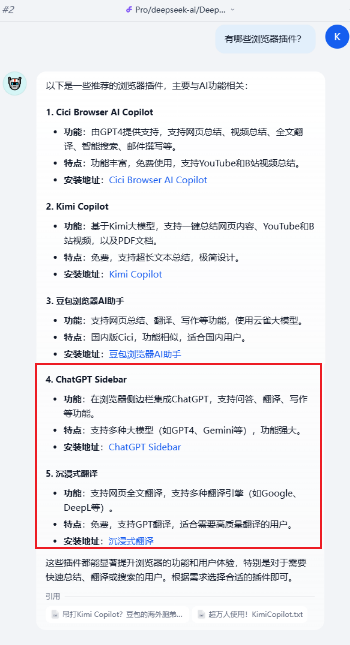
我知识库里面提到的插件就只有豆包(海外cici、和国内版),以及kimi Copilot。旧版V3还是容易出现幻觉,回答内容里面凭空出现了沉浸式翻译、和ChatGPT sidebar,,,
而新版V3这边回答正确,还给出了一个表格进行对比,以及贴心的推荐了使用场景,这就是上下文长度和理解能力增强的表现。
第四个问题: 如何降低论文AI率?
知识库中提到了两种,一种是海外Humanizer Pro,一种是智谱的Humanizer Pro,新版V3两种都提到了,而旧版V3缺少了智谱的Humanizer Pro。


当然,测试不止上面给出的4个,我进行了很多轮测试
实测下来,真的新版DeepSeek V3,提升不止亿点点:
上下文理解能力显著增强,回复更加详细,不容易出现幻觉,prompt理解能力增强,更加遵守prompt。经过多次测试,发现回复的内容,习惯性的会增加表格,进行对比(这点太贴心了)
所以,现在新版DeepSeek V3应该是目前最具性价比的大模型了。
各方面能力都直逼Claude3.7,但API甚至还能免费用。
不过openrouter的新版deepseek v3接口有点不太稳,偶尔会卡**住几秒到几十秒才继续回复,生产环境建议等火山、硅基流动等接入之后在切换
总结一下,如果您的知识库数量非常庞大,推荐使用minimax-01(因为它有最长上下文-400万tokens,而且比deepseek API还便宜)
如果您的知识库数据量一般,推荐直接上新版DeepSeek V3。
这个数据量多大 算庞大呢?不好说,可以两个都使用,对比一下效果就知道选谁了。
好了,以上就是本期所有了
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









