 MCP传输机制详解及大模型AI学习指南
MCP传输机制详解及大模型AI学习指南




介绍 MCP 传输机制
MCP 传输机制(Transport)是 MCP 客户端与 MCP 服务器通信的一个桥梁,定义了客户端与服务器通信的细节,帮助客户端和服务器交换消息。
MCP 协议使用 JSON-RPC 来编码消息。JSON-RPC 消息必须使用 UTF-8 编码。
MCP 协议目前定义了三种传输机制用于客户端-服务器通信:
-
stdio:通过标准输入和标准输出进行通信
-
SSE:通过 HTTP 进行通信,支持流式传输。(协议版本 2024-11-05 开始支持,即将废弃)
-
Streamble HTTP:通过 HTTP 进行通信,支持流式传输。(协议版本 2025-03-26 开始支持,用于替代 SSE)
MCP 协议要求客户端应尽可能支持 stdio。
MCP 协议的传输机制是可插拔的,也就是说,客户端和服务器不局限于 MCP 协议标准定义的这几种传输机制,也可以通过自定义的传输机制来实现通信。
stdio 传输
stdio 即 standard input & output(标准输入 / 输出)。
是 MCP 协议推荐使用的一种传输机制,主要用于本地进程通信。
在 stdio 传输中:
-
客户端以子进程的形式启动 MCP 服务器。
-
服务器从其标准输入(stdin)读取 JSON-RPC 消息,并将消息发送到其标准输出(stdout)。
-
消息可能是单个 JSON-RPC 请求、通知、响应,或者包含多个请求、通知、响应的 JSON-RPC 批处理。
-
消息由换行符分隔,且不得包含嵌套的换行符。
-
服务器可以将其 UTF-8 字符串写入标准错误(stderr)以进行日志记录。客户端可以捕获、转发或忽略此日志。
-
服务器不得向 stdout 写入无效的 MCP 消息内容。
-
客户端不得向服务器的 stdin 写入无效的 MCP 消息内容。
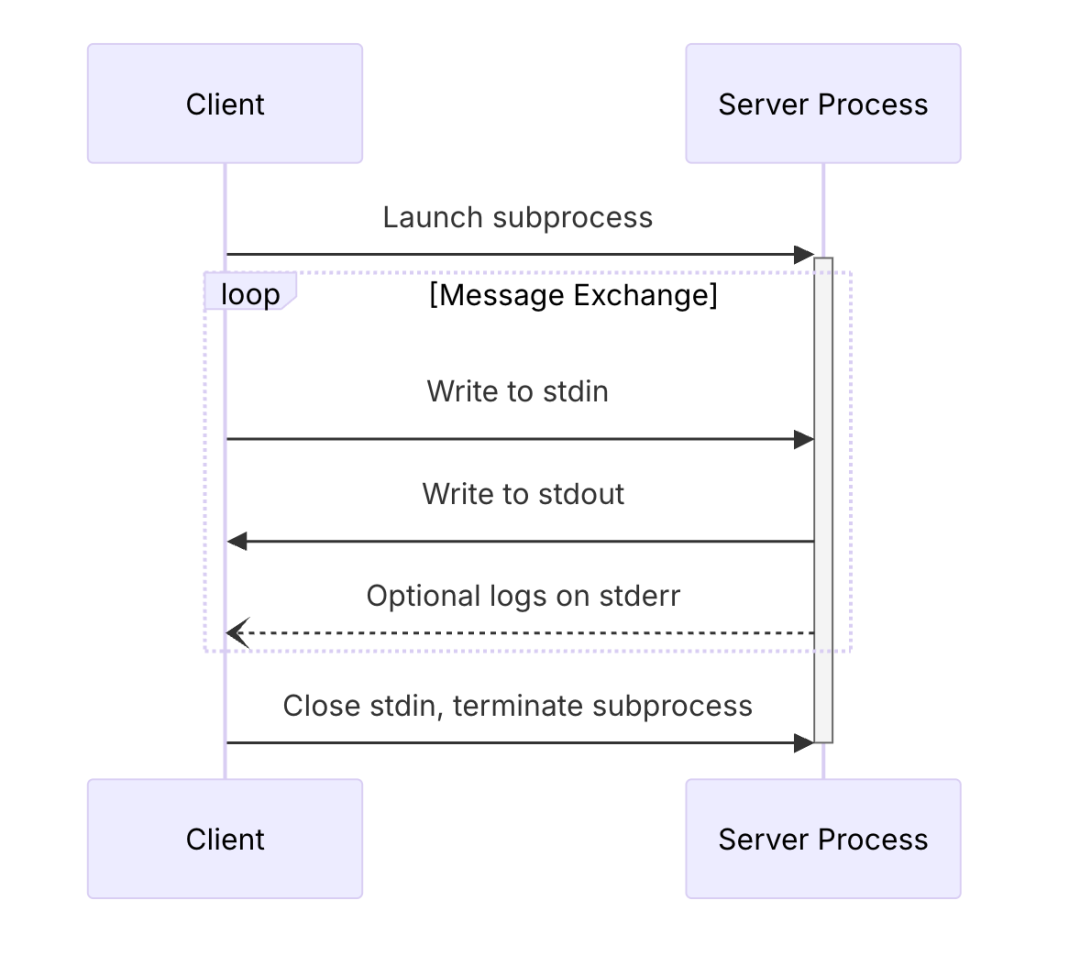
stdio 通信流程
-
客户端以子进程的方式启动服务器
-
客户端往服务器的 stdin 写入消息
-
服务器从自身的 stdin 读取消息
-
服务端往自身的 stdout 写入消息
-
客户端从服务器的 stdout 读取消息
-
客户端终止子进程,关闭服务器的 stdin
-
服务器关闭自身的 stdout
stdio 传输实现
参考 MCP 官方的 typescript-sdk 来看 stdio 传输机制是如何实现的:
-
启动 MCP 服务器
以命令行的方式,在本地启动 MCP 服务器:
npx -y mcp-server-time
-
创建 stdio 通信管道
MCP 服务器启动时,会创建 stdio 通信管道(pipeline),用于跟 MCP 客户端进行消息通信。在 MCP 客户端发送关闭信号,或者 MCP 服务器异常退出之前,这个通信管道会一直保持,常驻进程。
export class StdioServerTransport implements Transport {
private _readBuffer: ReadBuffer = new ReadBuffer();
private _started = false;
constructor(
private _stdin: Readable = process.stdin,
private _stdout: Writable = process.stdout
) {}
onclose?: () =>void;
onerror?: (error: Error) =>void;
onmessage?: (message: JSONRPCMessage) =>void;
}
-
从 stdin 读取请求消息
MCP 客户端把消息发到通信管道。MCP 服务器通过标准输入 stdin 读取客户端发送的消息,以换行符:\n 作为读取完成标识。
MCP 服务器读取到的有效消息,是 JSON-RPC 编码的结构体。
readMessage(): JSONRPCMessage | null {
if (!this._buffer) {
returnnull;
}
const index = this._buffer.indexOf("\n");
if (index === -1) {
returnnull;
}
const line = this._buffer.toString("utf8", 0, index).replace(/\r$/, '');
this._buffer = this._buffer.subarray(index + 1);
return deserializeMessage(line);
}
-
往 stdout 写入响应消息
MCP 服务器运行完内部逻辑,需要给 MCP 客户端响应消息。
MCP 服务器先用 JSON-RPC 编码消息,再把消息写入标准输出 stdout。
send(message: JSONRPCMessage): Promise<void> {
return new Promise((resolve) => {
const json = serializeMessage(message);
if (this._stdout.write(json)) {
resolve();
} else {
this._stdout.once("drain", resolve);
}
});
}
}
MCP 客户端从 MCP 服务器的标准输出 stdout 读取消息,获得 MCP 服务器的响应内容。
-
关闭 stdio 通信管道
MCP 客户端退出,给 MCP 服务器发送关闭信号。
MCP 服务器通过 stdio 通信管道读到客户端发送的终止信号,或者内部运行错误,主动关闭 stdio 通信管道。
stdio 通信管道关闭之后,MCP 客户端与 MCP 服务器之间不能再相互发送消息,直到再次建立 stdio 通信管道。
async close(): Promise<void> {
// Remove our event listeners first
this._stdin.off("data", this._ondata);
this._stdin.off("error", this._onerror);
// Check if we were the only data listener
const remainingDataListeners = this._stdin.listenerCount('data');
if (remainingDataListeners === 0) {
// Only pause stdin if we were the only listener
// This prevents interfering with other parts of the application that might be using stdin
this._stdin.pause();
}
// Clear the buffer and notify closure
this._readBuffer.clear();
this.onclose?.();
}

stdio 传输的利弊
stdio 传输机制主要依靠本地进程通信实现。
主要的优势是:
-
无外部依赖,实现简单
-
无网络传输,通信速度快
-
本地通信,安全性高
也有一些局限性:
-
单进程通信,无法并行处理多个客户端请求
-
进程通信的资源开销大,很难在本地运行非常多的服务
stdio 传输的适用场景
stdio 传输适用于要操作的数据资源位于本地计算机,且不希望暴露外部访问的场景。
比如,你希望通过一个聊天客户端,来总结你的微信消息,微信消息文件存储在你的本地电脑,外部访问不了,也不应该访问。
这种情况,你可以实现一个 MCP 服务器来读取你电脑上的微信消息文件,通过 stdio 传输接收 MCP 客户端的访问请求。
如果你要访问的是一个远程服务器上的文件,也可以使用 stdio 传输,流程会复杂一些:
-
先写一个 API 服务,部署在远程服务器,操作远程服务器上的资源,暴露公网访问
-
写一个 MCP 服务器,对接远程 API,再通过 stdio 传输与客户端本地通信
既然 stdio 传输访问远程资源这么麻烦,是不是应该有一种更适合远程资源访问的传输机制?
当然有。可以使用 SSE 传输。
SSE 传输
MCP 协议使用 SSE(Server-Sent Events) 传输来解决远程资源访问的问题。底层是基于 HTTP 通信,通过类似 API 的方式,让 MCP 客户端直接访问远程资源,而不用通过 stdio 传输做中转。
在 SSE 传输中,服务器作为一个独立进程运行,可以处理多个客户端连接。
服务器必须提供两个端点:
-
一个 SSE 端点,供客户端建立连接并从服务器接收消息
-
一个常规 HTTP POST 端点,供客户端向服务器发送消息
当客户端连接时,服务器必须发送一个包含客户端用于发送消息的 URL 的端点事件。所有后续客户端消息必须作为 HTTP POST 请求发送到该端点。
服务器消息作为 SSE 消息事件发送,消息内容以 JSON 格式编码在事件数据中。
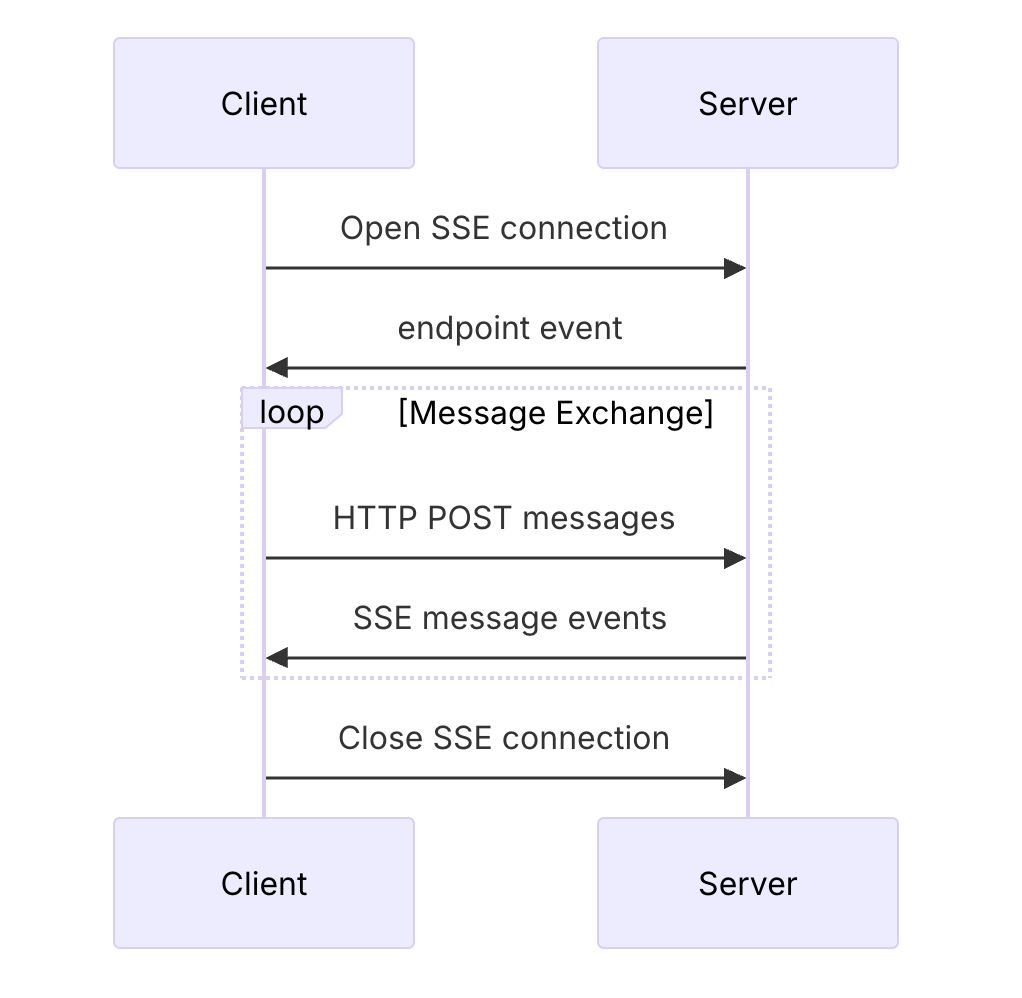
SSE 通信流程
-
客户端向服务器的 /sse 端点发送请求(一般是 GET 请求),建立 SSE 连接
-
服务器给客户端返回一个包含消息端点地址的事件消息
-
客户端给消息端点发送消息
-
服务器给客户端响应消息已接收状态码
-
服务器给双方建立的 SSE 连接推送事件消息
-
客户端从 SSE 连接读取服务器发送的事件消息
-
客户端关闭 SSE 连接
SSE 传输实现
参考 MCP 官方的 typescript-sdk 来看 SSE 传输机制是如何实现的:
-
启动 MCP 服务器
系统管理员在远程服务器(也可以是本地电脑)输入命令,启动 MCP 服务器,监听服务器端口,对外暴露 HTTP 接口。
const server = new McpServer({
name: "example-server",
version: "1.0.0",
});
const app = express();
app.get("/sse", async (_: Request, res: Response) => {
const transport = new SSEServerTransport("/messages", res);
await server.connect(transport);
});
app.post("/messages", async (req: Request, res: Response) => {
await transport.handlePostMessage(req, res);
});
app.listen(3001);
在这个示例中,使用了 express 框架,启动了一个 HTTP 服务,监听在 3001 端口,对外暴露了两个端点:
-
/sse:GET 请求,用于建立 SSE 连接
-
/messages:POST 请求,用于接收客户端发送的消息
解析一个 MCP 客户端可访问的域名到 MCP 服务器。比如:abc.mcp.so
-
建立 SSE 连接
MCP 客户端请求 MCP 服务器的 URL 地址:https://abc.mcp.so:3001/sse 与 MCP 服务器建立连接,MCP 服务器需要给 MCP 客户端返回一个用于消息通信的地址:
res.writeHead(200, {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
});
const messagesUrl = "https://abc.mcp.so:3001/messages?sessionId=xxx";
res.write(`event: endpoint\ndata: ${messagesUrl}\n\n`);
MCP 客户端从 MCP 服务器返回的 endpoint 事件中得到了消息通信的地址,与 MCP 服务器建立 SSE 连接成功。
MCP 客户端通过 POST 请求把消息发到这个消息通信地址,与 MCP 服务器进行消息交互。
-
消息交互
MCP 客户端在与 MCP 服务器建立 SSE 连接之后,开始给 MCP 服务器返回的通信地址发送消息。
MCP 协议中的 SSE 传输是双通道响应机制。也就是说,MCP 服务器在接收到 MCP 客户端的消息之后,既要给当前的请求回复一个响应,也要给之前建立的 SSE 连接发送一条响应消息。(通知类型的消息,不需要给 SSE 连接发消息)
举个例子,MCP 客户端与 MCP 服务器建立 SSE 连接之后,给 MCP 服务器发送的第一条消息,用于初始化阶段做能力协商。
MCP 客户端请求示例:
curl -X POST https://abc.mcp.so/messages?sessionId=xxx \
-H "Content-Type: application/json" \
-d '{
"jsonrpc": "2.0",
"id": "1",
"method": "initialize",
"params": {
"protocolVersion": "1.0",
"capabilities": {},
"clientInfo": {
"name": "mcp-client",
"version": "1.0.0"
}
}
}'
MCP 服务器从 HTTP 请求体里面读取 MCP 客户端发送的消息:
async handlePostMessage(
req: IncomingMessage,
res: ServerResponse,
parsedBody?: unknown,
): Promise<void> {
if (!this._sseResponse) {
const message = "SSE connection not established";
res.writeHead(500).end(message);
thrownewError(message);
}
let body: string | unknown;
try {
const ct = contentType.parse(req.headers["content-type"] ?? "");
if (ct.type !== "application/json") {
thrownewError(`Unsupported content-type: ${ct}`);
}
body = parsedBody ?? await getRawBody(req, {
limit: MAXIMUM_MESSAGE_SIZE,
encoding: ct.parameters.charset ?? "utf-8",
});
} catch (error) {
res.writeHead(400).end(String(error));
this.onerror?.(error asError);
return;
}
try {
awaitthis.handleMessage(typeof body === 'string' ? JSON.parse(body) : body);
} catch {
res.writeHead(400).end(`Invalid message: ${body}`);
return;
}
res.writeHead(202).end("Accepted");
}
先给当前请求,响应一个 HTTP 202 状态码,告知 MCP 客户端,请求已收到。
然后 MCP 服务器运行内部逻辑,完成业务功能。
再给之前与 MCP 客户端建立的 SSE 连接发送一个事件消息,data 里面放 JSON-RPC 编码的消息内容:
async send(message: JSONRPCMessage): Promise<void> {
if (!this._sseResponse) {
throw new Error("Not connected");
}
this._sseResponse.write(
`event: message\ndata: ${JSON.stringify(message)}\n\n`,
);
}
MCP 客户端根据 MCP 服务器同步响应的 2** 状态码,判断 MCP 服务器已经接到请求,并开始读取 MCP 服务器发到 SSE 连接的消息内容。
MCP 客户端从与 MCP 服务器建立的 SSE 连接中读取 event: message 事件消息,获得 MCP 服务器发送的业务数据 data。
MCP 客户端与 MCP 服务器建立的 SSE 连接,应该是 1:1 的。为了防止串数据的问题,在建立 SSE 连接阶段,MCP 服务器返回的通信地址,应该为当前连接分配一个唯一标识,叫做 sessionId,给 MCP 客户端返回的通信地址带上这个标识,比如 /messages?sessionId=xxx。
在消息交互阶段,MCP 服务器根据 MCP 客户端请求地址参数里面的 sessionId,找到之前建立的 SSE 连接,并只给这个 SSE 连接发送消息。
-
断开 SSE 连接
MCP 服务器与 MCP 客户端双方都可能会主动断开 SSE 连接。
还保持连接的一方,应该加上必要的连接检测和超时关闭机制。
比如通过 SSE 连接,给对方定时发送一条心跳检测消息,如果多次无响应,可以认作对方已断开连接,此时可以主动关闭 SSE 连接,避免资源泄露。
一个用 go 实现的心跳检测和超时关闭示例:
// Setup heartbeat ticker
heartbeatInterval := 30 * time.Second
heartbeatTicker := time.NewTicker(heartbeatInterval)
defer heartbeatTicker.Stop()
// Setup idle timeout
idleTimeout := 5 * time.Minute
idleTimer := time.NewTimer(idleTimeout)
defer idleTimer.Stop()
gofunc() {
for {
select {
case <-session.Done():
return
case <-heartbeatTicker.C:
// Send heartbeat
if err := writer.SendHeartbeat(); err != nil {
session.Close()
return
}
case <-idleTimer.C:
// Close connection due to inactivity
session.Close()
return
}
}
}()
SSE 安全防护
当使用 SSE 传输时,服务器一方需要实现一些必要的安全防护措施:
-
服务器必须验证所有传入连接的 Origin 头,以防止 DNS 重绑定攻击
-
在本地运行时,服务器应仅绑定到 localhost(127.0.0.1),而不是所有网络接口(0.0.0.0)
-
服务器应对所有连接实施适当的身份验证
如果没有这些保护措施,攻击者可能会使用 DNS 重绑定从远程网站与本地 MCP 服务器交互。
SSE 传输的适用场景
SSE 传输适用于 MCP 客户端与 MCP 服务器不在同一个网络下的通信场景。
比如,你希望在本地电脑,通过对话的方式,查询你云服务器上的数据库。你就可以在你的云服务器上部署一个 MCP 服务器,去读取数据库,再跟你本地电脑上的 MCP 客户端建立连接通信。
当然,所有用 SSE 传输实现的 MCP 服务器,理论上都可以通过 stdio 传输 + API 的方式实现。
区别在于:
-
用 SSE 传输,MCP 客户端直接与 MCP 服务器通信,而不用通过本地的 stdio 传输调用 API 进行中转。
-
用 SSE 传输,在 MCP 客户端只需要一个 URL 即可接入,对本地环境无要求,也无需在本地运行 MCP 服务器,用户侧的使用门槛更低。
SSE 传输的利弊
SSE 传输主要解决远程资源访问的问题,依靠 HTTP 协议实现底层通信。
SSE 传输的主要优势:
-
支持远程资源访问,让 MCP 客户端可以直接访问远程服务,解决了 stdio 传输仅适用于本地资源的局限
-
基于标准 HTTP 协议实现,兼容性好,便于与现有 Web 基础设施集成
-
服务器可作为独立进程运行,支持处理多个客户端连接
-
相比 WebSocket 实现简单,是普通 HTTP 的扩展,不需要协议升级
SSE 传输的主要劣势与问题:
-
连接不稳定:在无服务器(serverless)环境中,SSE 连接会随机、频繁断开,影响 AI 代理需要的可靠持久连接
-
扩展性挑战:SSE 不是为云原生架构设计的,在扩展平台时会遇到瓶颈
-
浏览器连接限制:每个浏览器和域名的最大打开连接数很低(6 个),当用户打开多个标签页时会出现问题
-
代理和防火墙问题:某些代理和防火墙会因为缺少 Content-Length 头而阻止 SSE 连接,在企业环境部署时造成挑战
-
复杂的双通道响应机制:MCP 中的 SSE 实现要求服务器在接收客户端消息后,既要给当前请求响应,也要给之前建立的 SSE 连接发送响应消息
-
无法支持长期的无服务器部署:无服务器架构通常自动扩缩容,不适合长时间连接,而 SSE 需要维持持久连接
-
需要大量会话管理:需要为每个 SSE 连接分配唯一标识(sessionId)来防止数据混淆,增加了实现复杂度
-
需要额外的连接检测和超时关闭机制:需要实现心跳检测和超时机制来避免资源泄露
正因为这些问题,MCP 协议已经引入了新的 Streamable HTTP 传输机制(2025-03-26 版本)来替代 SSE,并计划废弃 SSE 传输。新的传输机制保留了 HTTP 的基础,但支持更灵活的连接方式,更适合现代云架构和无服务器环境。
Streamable HTTP 传输
Streamable HTTP 传输是 MCP 协议在 2025-03-26 版本中引入的新传输机制,用于替代之前的 SSE 传输。
在 Streamable HTTP 传输中,服务器作为一个独立进程运行,可以处理多个客户端连接。此传输使用 HTTP POST 和 GET 请求,服务器可以选择使用服务器发送事件(SSE)来流式传输多个服务器消息。
服务器必须提供一个同时支持 POST 和 GET 方法的单个 HTTP 端点。例如:https://xyz.mcp.so/mcp。
Streamable HTTP 通信流程
-
客户端给服务器的通信端点发消息
-
服务器给客户端响应消息
-
客户端根据服务器的响应类型,继续给服务器发消息
-
服务器继续响应客户端消息
跟 SSE 传输不同的点在于,Streamable HTTP 传输中,客户端与服务器的消息交互,基本上是“一来一回”的(单通道响应)。而这个“一来一回”的消息交互,可能会有很多种组合类型。
-
客户端发送 GET 请求给服务器,服务器返回 SSE 连接
-
客户端 POST JSON-RPC 编码的消息给服务器,服务器返回 JSON-RPC 编码的消息响应
-
客户端 POST JSON-RPC 编码的消息给服务器,服务器返回一个 SSE 连接
-
客户端给 SSE 连接发消息,服务器收到后给 SSE 连接响应消息
-
服务器响应的消息,可能包含状态标识:Mcp-Session-Id
-
客户端发消息时候需要带上状态标识:Mcp-Session-Id
Streamable HTTP 传输实现
参考 MCP 官方的 typescript-sdk 来看 Streamable HTTP 传输机制是如何实现的:
-
启动服务器
跟 SSE 传输机制一样,Streamable HTTP 传输本质上也是基于 HTTP 协议通信,需要先启动一个 HTTP 服务:
const server = new McpServer({
name: "example-server",
version: "1.0.0",
});
const app = express();
app.all("/mcp", async (req: Request, res: Response) => {
const transport = new StreamableHTTPServerTransport();
await server.connect(transport);
await transport.handleMessage(req, res);
});
app.listen(3002);
跟 SSE 传输不一样的点在于,Streamable HTTP 传输只需要暴露一个端点(endpoint),来接收各种类型的客户端请求(GET / POST / DELETE)。
比如在这个例子,使用 express 框架,启动了一个 HTTP 服务,监听在 3002 端口,对外暴露了一个端点:
-
/mcp:接收客户端建立连接、交换消息的请求
解析一个 MCP 客户端可访问的域名到 MCP 服务器。比如:xyz.mcp.so
-
消息交互
在 MCP 服务器启动成功之后,MCP 客户端可以直接给 MCP 服务器暴露的地址发送消息。
跟 SSE 传输不同,Streamable HTTP 传输机制中,MCP 客户端给服务器发送消息,无需先跟一个端点建立 SSE 连接,再给另一个端点发消息。而是单通道模式,即客户端给服务器发消息,直接获得服务器的响应内容。
MCP 客户端可以使用 GET 或者 POST 请求给服务器发消息,每个请求必须设置请求头 Accept,传递以下两个值:
-
application/json 接收服务器响应的 JSON-RPC 编码消息
-
text/event-stream 由服务器开启流式传输通道,客户端从这个流里面读取事件消息
MCP 客户端请求示例:
curl -X POST https://xyz.mcp.so/mcp \
-H "Content-Type: application/json" \
-H "Accept: application/json, text/event-stream" \
-d '{
"jsonrpc": "2.0",
"id": "1",
"method": "initialize",
"params": {
"protocolVersion": "1.0",
"capabilities": {},
"clientInfo": {
"name": "mcp-client",
"version": "1.0.0"
}
}
}'
Streamable HTTP 传输机制下,MCP 客户端与服务器通信的几个要点:
-
客户端可以给服务器发送不包含请求体的 GET 请求,用于建立 SSE 连接,让服务器可以主动给客户端先发消息
-
客户端给服务器发送 JSON-RPC 消息的情况,必须使用 POST 请求
-
服务器接到客户端的 GET 请求时,要么返回
Contet-Type: text/event-stream开启 SSE 连接,要么返回 HTTP 405 状态码,表示不支持 SSE 连接。 -
服务器接到客户端的 POST 请求时,从请求体里面读取 JSON-RPC 消息,如果是通知消息,就响应 HTTP 202 状态码,表示消息已收到。如果是非通知消息,服务器可以选择返回
Content-Type: text/event-stream开启 SSE 传输,或者返回Content-Type: application/json同步响应一条 JSON-RPC 消息。
-
会话保持
Streamable HTTP 传输既支持无状态的请求:每一次请求都是独立的,无需记录状态。
也支持有状态的请求:一次新的请求,可能需要同步之前的请求 / 响应信息作为参考。这种情况叫做:会话保持。
如果需要保持会话,MCP 服务器与 MCP 客户端之间的交互应该遵守以下原则:
-
使用 Streamable HTTP 传输的服务器可以在初始化时分配一个会话 ID,方法是在包含
InitializeResult的 HTTP 响应中包含它,放在Mcp-Session-Id头中。 -
如果服务器在初始化期间返回了
Mcp-Session-Id,使用 Streamable HTTP 传输的客户端必须在所有后续的 HTTP 请求中在Mcp-Session-Id头中包含它。 -
服务器可以随时终止会话,之后它必须使用 HTTP 404 Not Found 响应包含该会话 ID 的请求。
-
当客户端收到对包含
Mcp-Session-Id的请求的 HTTP 404 响应时,它必须通过发送一个不带会话 ID 的新InitializeRequest来启动一个新会话。 -
不再需要特定会话的客户端应该发送一个带有
Mcp-Session-Id头的 HTTP DELETE 到 MCP 端点,以显式终止会话。
MCP 服务器验证会话的一个示例:
/**
* Validates session ID for non-initialization requests
* Returns true if the session is valid, false otherwise
*/
private validateSession(req: IncomingMessage, res: ServerResponse): boolean {
if (!this._initialized) {
// If the server has not been initialized yet, reject all requests
res.writeHead(400).end(JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Bad Request: Server not initialized"
},
id: null
}));
returnfalse;
}
if (this.sessionId === undefined) {
// If the session ID is not set, the session management is disabled
// and we don't need to validate the session ID
returntrue;
}
const sessionId = req.headers["mcp-session-id"];
if (!sessionId) {
// Non-initialization requests without a session ID should return 400 Bad Request
res.writeHead(400).end(JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Bad Request: Mcp-Session-Id header is required"
},
id: null
}));
returnfalse;
} elseif (Array.isArray(sessionId)) {
res.writeHead(400).end(JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Bad Request: Mcp-Session-Id header must be a single value"
},
id: null
}));
returnfalse;
}
elseif (sessionId !== this.sessionId) {
// Reject requests with invalid session ID with 404 Not Found
res.writeHead(404).end(JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32001,
message: "Session not found"
},
id: null
}));
returnfalse;
}
returntrue;
}
-
连接断开与重连
Streamable HTTP 传输,如果客户端与服务器使用 SSE 连接通信,断开连接的方式跟 SSE 传输断开连接的方式一致。
可以由连接的任意一方主动断开连接。还保持着连接的一方,需要实现心跳检测和超时机制,以便能及时关闭连接,避免资源泄露。
Streamable HTTP 传输比起 SSE 传输,做了一些改进,支持恢复已中断的连接,重新发送可能丢失的消息:
-
服务器可以在其 SSE 事件中附加一个 ID 字段。如果存在,ID 必须在所有会话所有流中全局唯一。
-
如果客户端希望在断开连接后恢复,它应该向服务器发出 HTTP GET 请求,并包含 Last-Event-ID 头,告知服务器它接收到的最后一个事件 ID。服务器可以重放在最后一个事件 ID 之后将发送的消息,并从该点恢复流。
支持断点重连的 Streamable HTTP 传输,在消息传输方面会比 SSE 传输更加可靠。
Streamable HTTP 传输的利弊
Streamable HTTP 传输机制结合了 SSE 传输的远程访问能力和无状态 HTTP 的灵活性,同时解决了 SSE 传输中的许多问题。
主要优势:
-
兼容无服务器环境,可以在短连接模式下工作
-
灵活的连接模式,支持简单的请求-响应和流式传输
-
会话管理更加标准化和清晰
-
支持断开连接恢复和消息重传
-
保留了 SSE 的流式传输能力,同时解决了其稳定性问题
-
向后兼容,可以支持旧版客户端和服务器
主要劣势:
-
相比单纯的 stdio 传输实现复杂度更高
-
仍需处理网络连接断开和恢复的逻辑
-
会话管理需要服务器引入额外的组件(比如用 Redis 来存储 Session)
Streamable HTTP 传输的适用场景
Streamable HTTP 传输适用于:
-
需要远程访问服务的场景,特别是云环境和无服务器架构
-
需要支持流式输出的 AI 服务
-
需要服务器主动推送消息给客户端的场景
-
大规模部署需要高可靠性和可扩展性的服务
-
需要在不稳定网络环境中保持可靠通信的场景
与 SSE 传输相比,Streamable HTTP 传输是一个更全面、更灵活的解决方案,特别适合现代云原生应用和无服务器环境。
自定义传输
MCP 客户端和 MCP 服务器可以实现额外的自定义传输机制以满足其特定需求。MCP 协议与传输无关,可以在支持双向消息交换的任何通信通道上实现。
选择支持自定义传输的实现者必须确保他们保留由 MCP 定义的 JSON-RPC 消息格式和生命周期要求。自定义传输应记录其特定的连接建立和消息交换模式,以实现互操作性。
用一个实际的例子来说明,如何实现一个自定义传输,来满足特定的需求。
需求分析
目前市面上大部分的 MCP 服务器是使用 stdio 和 SSE 传输机制实现的,用户要使用这些 MCP 服务器,需要拉代码到本地运行,使用门槛有点高。
我们希望实现一个 MCP 代理服务,在云上部署,让用户仅需要配置一个 URL 即可接入。由这个云端部署的 MCP 代理去对接第三方的 MCP 服务器。
大致的流程是:
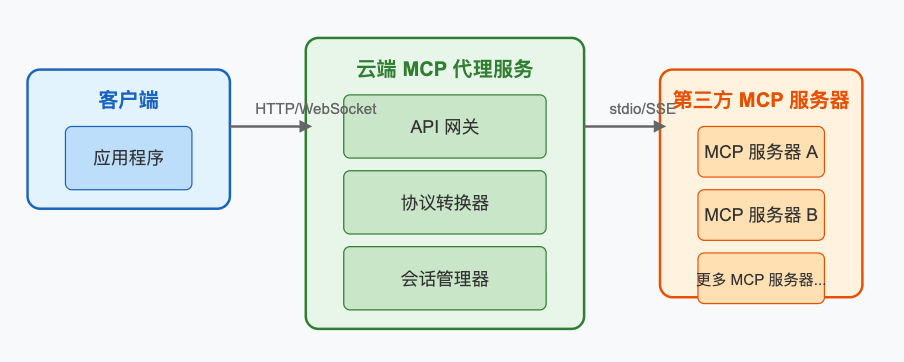
这个 MCP 代理服务以 HTTP 的形式提供接入,需要支持并发调用。这个 MCP 代理服务作为 stdio 传输或者 SSE 传输的客户端,发送消息给后台的 MCP 服务器。
按照这个方案,MCP 代理服务跟后台部署的第三方服务器之间的交互存在着一些问题:
-
如果后台对接的 MCP 服务器是基于 stdio 传输实现的,MCP 代理每接到一个用户请求,都需要调用 MCP 服务器创建一个独立的 stdio 通信进程。服务器开销特别大(进程创建和销毁、上下文切换,内存隔离等操作,都很消耗服务器资源)。
-
如果后台对接的 MCP 服务器是基于 SSE 传输实现的,从前面对 SSE 传输的分析我们知道,MCP 代理需要跟后台部署的 MCP 服务器之间保持一个 SSE 连接。如果每个用户请求都需要维持一个 SSE 的长连接,对服务器也是不小的压力。
为了解决这些问题,对于 MCP 代理和其背后连接的 MCP 服务器,可以想到的一些优化方案:
-
用 k8s 集群分布式部署,代替单机部署,保持 MCP 代理的弹性扩容能力,支持更高的并发请求
-
修改第三方服务器的传输机制,如果是 stdio 进程通信,可以改成轻量级的协程通信,或者使用 HTTP 通信,支持多路复用
-
如果第三方服务器的传输机制是 SSE,需要把双通道响应改成单通道响应,并且不应该使用长连接
-
分布式网络下,会话保持需要引入一些额外的组件(比如 redis)或者额外的策略(比如用负载均衡的 IP Hash 策略把请求路由到固定的机器),如果 MCP 服务器不是必须要用到会话保持,那就最好改成无状态的传输
基于以上几点分析,我们可以设计一套自定义的传输机制,来改造在分布式集群部署的第三方 MCP 服务器。
这套自定义的传输机制应该具备的几个特性:
-
基于 HTTP 通信
-
非流式传输
-
无状态,无会话保持
-
短连接
虽然 Streamable HTTP 传输通过配置参数也能实现这些功能,但是我们还是希望能自定义一套更简单,更直接,零配置的传输机制。
我们把这个新的传输机制取名为:Restful HTTP Transport,简称 Rest Transport
因为要改造的主要是 MCP 服务器,接下来主要讲解如何实现一个服务器使用的 Rest Server Transport.
实现 Rest Server Transport
参考 MCP 官方实现的 Streamable HTTP Transport,我们来实现这个自定义的 Rest Server Transport。
-
定义新的传输类,实现 MCP 协议的 Transport 接口
/**
* Server transport for Synchronous HTTP: a stateless implementation for direct HTTP responses.
* It supports concurrent requests with no streaming, no SSE, and no persistent connections.
*/
export class RestServerTransport implements Transport {
// ...
}
-
定义启动服务方法,用来启动一个 HTTP 服务器,处理客户端的请求
/**
* Start the HTTP server
*/
async startServer(): Promise<void> {
if (this._server) {
thrownewError("Server is already running");
}
this._server = express();
this._server.post(this._endpoint, (req, res) => {
this.handleRequest(req, res, req.body);
});
returnnewPromise((resolve, reject) => {
try {
this._httpServer = this._server!.listen(this._port, () => {
console.log(
`Server is running on http://localhost:${this._port}${this._endpoint}`
);
resolve();
});
this._httpServer.on("error", (error) => {
console.error("Server error:", error);
this.onerror?.(error);
});
} catch (error) {
reject(error);
}
});
}
跟 Streamable HTTP 传输一样,自定义的传输在启动 HTTP 服务器之后,我们也只暴露一个端点来接收客户端请求,这个端点和 HTTP 服务器监听的端口,都可以在启动服务器的时候自定义。
export interface RestServerTransportOptions {
endpoint?: string;
port?: string | number;
}
-
接收客户端请求
跟 Streamable HTTP 传输最主要的区别,我们自定义的这个传输,仅支持客户端发起 POST 请求,客户端也只会收到 application/json 响应,不会收到 text/event-stream 响应。
客户端与服务器使用短连接通信,不会有 Connection: "keep-alive"。服务器响应完,与客户端的连接就会断开。
客户端与服务器之间的消息交互是无状态的,所以客户端无需传递 Mcp-Session-Id,服务器也不会判断客户端的会话有效性,不会维护任何 session 相关的数据。
Rest Server Transport 处理用户请求的主要实现逻辑:
/**
* Handles an incoming HTTP request
*/
async handleRequest(
req: IncomingMessage,
res: ServerResponse,
parsedBody?: unknown
): Promise<void> {
if (req.method === "POST") {
awaitthis.handlePostRequest(req, res, parsedBody);
} else {
res.writeHead(405).end(
JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Method not allowed",
},
id: null,
})
);
}
}
/**
* Handles POST requests containing JSON-RPC messages
*/
privateasync handlePostRequest(
req: IncomingMessage,
res: ServerResponse,
parsedBody?: unknown
): Promise<void> {
try {
// validate the Accept header
const acceptHeader = req.headers.accept;
if (
acceptHeader &&
acceptHeader !== "*/*" &&
!acceptHeader.includes("application/json")
) {
res.writeHead(406).end(
JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message: "Not Acceptable: Client must accept application/json",
},
id: null,
})
);
return;
}
const ct = req.headers["content-type"];
if (!ct || !ct.includes("application/json")) {
res.writeHead(415).end(
JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32000,
message:
"Unsupported Media Type: Content-Type must be application/json",
},
id: null,
})
);
return;
}
let rawMessage;
if (parsedBody !== undefined) {
rawMessage = parsedBody;
} else {
const parsedCt = contentType.parse(ct);
const body = await getRawBody(req, {
limit: MAXIMUM_MESSAGE_SIZE,
encoding: parsedCt.parameters.charset ?? "utf-8",
});
rawMessage = JSON.parse(body.toString());
}
let messages: JSONRPCMessage[];
// handle batch and single messages
if (Array.isArray(rawMessage)) {
messages = rawMessage.map((msg) => JSONRPCMessageSchema.parse(msg));
} else {
messages = [JSONRPCMessageSchema.parse(rawMessage)];
}
// check if it contains requests
const hasRequests = messages.some(
(msg) =>"method"in msg && "id"in msg
);
const hasOnlyNotifications = messages.every(
(msg) =>"method"in msg && !("id"in msg)
);
if (hasOnlyNotifications) {
// if it only contains notifications, return 202
res.writeHead(202).end();
// handle each message
for (const message of messages) {
this.onmessage?.(message);
}
} elseif (hasRequests) {
// Create a unique identifier for this request batch
const requestBatchId = randomUUID();
// Extract the request IDs that we need to collect responses for
const requestIds = messages
.filter((msg) =>"method"in msg && "id"in msg)
.map((msg) =>String(msg.id));
// Set up a promise that will be resolved with all the responses
const responsePromise = newPromise<JSONRPCMessage[]>((resolve) => {
this._pendingRequests.set(requestBatchId, {
resolve,
responseMessages: [],
requestIds,
});
});
// Processallmessages
for (const message of messages) {
this.onmessage?.(message);
}
// Waitforresponsesandsendthem
constresponses = awaitPromise.race([
responsePromise,
// 30 second timeout
new Promise<JSONRPCMessage[]>((resolve) =>
setTimeout(() => resolve([]), 30000)
),
]);
// Cleanupthependingrequest
this._pendingRequests.delete(requestBatchId);
// Setresponseheaders
constheaders: Record<string, string> = {
"Content-Type": "application/json",
};
res.writeHead(200, headers);
// FormattheresponseaccordingtoJSON-RPCspec
constresponseBody = responses.length === 1 ? responses[0] : responses;
res.end(JSON.stringify(responseBody));
}
} catch (error) {
// returnJSON-RPCformattederror
res.writeHead(400).end(
JSON.stringify({
jsonrpc: "2.0",
error: {
code: -32700,
message: "Parse error",
data: String(error),
},
id: null,
})
);
this.onerror?.(error as Error);
}
}
-
服务器发送消息
MCP 服务器接到客户端请求后,把请求数据发到内部实现的各个功能函数内,得到响应内容后,用 JSON-RPC 编码,响应给 MCP 客户端。
Rest Server Transport 发送消息的主要实现逻辑:
async send(message: JSONRPCMessage): Promise<void> {
// Only process response messages
if (!("id"in message) || !("result"in message || "error"in message)) {
return;
}
const messageId = String(message.id);
// Find the pending request that is waiting for this response
for (const [batchId, pendingRequest] of this._pendingRequests.entries()) {
if (pendingRequest.requestIds.includes(messageId)) {
// Add this response to the collection
pendingRequest.responseMessages.push(message);
// If we've collected all responses for this batch, resolve the promise
if (
pendingRequest.responseMessages.length ===
pendingRequest.requestIds.length
) {
pendingRequest.resolve(pendingRequest.responseMessages);
}
break;
}
}
}
-
关闭服务
Streamable HTTP / SSE 以及我们自定义的 Rest Transport,关闭服务的逻辑都是一致的。
因为服务启动时是启动了一个 HTTP 服务器,所以服务关闭时,只需要关闭这个 HTTP 服务器即可。
Rest Server Transport 实现的关闭服务的主要逻辑:
async stopServer(): Promise<void> {
if (this._httpServer) {
returnnewPromise((resolve, reject) => {
this._httpServer!.close((err) => {
if (err) {
reject(err);
return;
}
this._server = null;
this._httpServer = null;
resolve();
});
});
}
}
在实现完这个自定义的传输后,我们就可以把代码打包,发布到 npm 公共仓库。这样第三方 MCP 服务器都可以使用这个 Transport 来改造自己的实现。
比如,我用 typescript 实现的 Rest Server Transport 封装在 @chatmcp/sdk 这个 npm 包里面,第三方服务器可以这样引入:
import { RestServerTransport } from "@chatmcp/sdk/server/index.js";
改造 MCP 服务器
为了把第三方 MCP 服务器部署到云端,支持多租户并发调用,我们需要对第三方 MCP 服务器做一定的改造。
以 Perplexity Ask Server 这个 MCP 服务器为例,来演示具体的改造流程:
-
安装包含 Rest Server Transport 的 SDK
npm install @chatmcp/sdk
-
获取服务启动参数
通过 @chatmcp/sdk 提供的 getParamValue 方法,可以获得 MCP 服务器启动时候的参数,从命令行读取,或者从环境变量读取:
import { getParamValue } from "@chatmcp/sdk/utils/index.js";
const perplexityApiKey = getParamValue("perplexity_api_key") || "";
const mode = getParamValue("mode") || "stdio";
const port = getParamValue("port") || 9593;
const endpoint = getParamValue("endpoint") || "/rest";
-
获取请求参数
MCP 服务器的设计初衷,是让用户运行在本地,跟私有数据打交道。
所以目前绝大部分的 MCP 服务器,都是不支持多租户的(也就是不能让多个用户共同使用)
主要的限制在于,在 MCP 服务器内部的实现逻辑里面,用到鉴权参数的地方,是在服务器启动时获取的,不是在请求时动态获取的。
如果要在云端部署 MCP 服务器,支持多租户使用,我们需要修改 MCP 服务器内部的参数获取逻辑,改成从请求参数里面动态获取。
MCP 协议允许在每个请求的 Request 对象通过 _meta 字段传递自定义的数据。
那么就可以改造 MCP 服务器,从 request.params._meta 里面获取客户端传递的 auth 参数。
在 @chatmcp/sdk 中,实现了一个 getAuthValue 方法,可以让 MCP 服务器获取 MCP 客户端传递的鉴权参数。
const auth: any = request.params?._meta?.auth;
以这个 Perplexity Ask Server 为例,我们把读取启动时参数,改成读取请求时参数:
// before: get params from env and set as global params
// after: get params from env or command line, set as global params
import { getParamValue, getAuthValue } from"@chatmcp/sdk/utils/index.js";
const perplexityApiKey = getParamValue("perplexity_api_key") || "";
const mode = getParamValue("mode") || "stdio";
const port = getParamValue("port") || 9593;
const endpoint = getParamValue("endpoint") || "/rest";
server.setRequestHandler(CallToolRequestSchema, async (request) => {
try {
// before: use global params
// after: get auth params from request, use global params if request params not set
const apiKey =
getAuthValue(request, "PERPLEXITY_API_KEY") || perplexityApiKey;
if (!apiKey) {
thrownewError("PERPLEXITY_API_KEY not set");
}
const { name, arguments: args } = request.params;
if (!args) {
thrownewError("No arguments provided");
}
switch (name) {
case"perplexity_ask": {
if (!Array.isArray(args.messages)) {
thrownewError(
"Invalid arguments for perplexity_ask: 'messages' must be an array"
);
}
const messages = args.messages;
// before: use global params in every function
// const result = await performChatCompletion(
// messages,
// "sonar-pro"
// );
// after: pass params to every function
const result = await performChatCompletion(
apiKey,
messages,
"sonar-pro"
);
return {
content: [{ type: "text", text: result }],
isError: false,
};
}
// ...
}
} catch (error) {
// Return error details in the response
return {
content: [
{
type: "text",
text: `Error: ${
error instanceof Error ? error.message : String(error)
}`,
},
],
isError: true,
};
}
});
改造完之后,云端的 MCP 代理,就可以把用户设置的鉴权参数:perplexity_api_key,通过这种方式传给 MCP 服务器了:
request.params._meta.auth = {
perplexity_api_key: "xxx",
};
-
新增 Rest 传输
修改这个 MCP 服务器,在原来仅支持 stdio 传输的基础上,新增一个 rest http 传输:
import { RestServerTransport } from"@chatmcp/sdk/server/rest.js";
import { getParamValue } from"@chatmcp/sdk/utils/index.js";
const mode = getParamValue("mode") || "stdio";
const port = getParamValue("port") || 9593;
const endpoint = getParamValue("endpoint") || "/rest";
asyncfunction runServer() {
try {
// after: MCP Server run with rest transport and stdio transport
if (mode === "rest") {
const transport = new RestServerTransport({
port,
endpoint,
});
await server.connect(transport);
await transport.startServer();
return;
}
// before: MCP Server only run with stdio transport
const transport = new StdioServerTransport();
await server.connect(transport);
console.error(
"Perplexity MCP Server running on stdio with Ask, Research, and Reason tools"
);
} catch (error) {
console.error("Fatal error running server:", error);
process.exit(1);
}
}
改造之后,这个 MCP 服务器就支持两种传输机制了。在不同的场景下,使用不同的传输机制运行:
使用 MCP 服务器
-
本地使用
-
通过源代码运行:
export PERPLEXITY_API_KEY=xxx && node build/index.js
-
或者使用二进制运行:
PERPLEXITY_API_KEY=xxx npx -y server-perplexity-ask
-
或者使用 docker 运行:
docker run -i --rm -e PERPLEXITY_API_KEY=xxx mcp/perplexity-ask
这三种方式,都会在本地启动 stdio 通信,在服务器启动的时候传递 PERPLEXITY_API_KEY 参数。
-
云端调用
改造完的 MCP 服务器在云端部署的启动命令:
node build/index.js --mode=rest --port=8081 --endpoint=/rest
使用了自定义的 Rest 传输,启动 HTTP 服务器,监听在本地的 8081 端口。通过 K8S Service 创建一个内网访问域名:perplexity-svc
MCP 代理把客户端的请求转发到 http://perplexity-svc:8081/rest,就可以处理多个用户的并发请求了。
MCP 客户端仅需要配置一个 MCP 代理的 URL,就可以使用 MCP 服务器了:
总结
在本节中,我们详细讲解了 MCP 协议支持的三种标准传输机制以及自定义传输的实现方式:
-
stdio 传输:
-
通过标准输入/输出进行本地进程间通信
-
优势在于实现简单、通信速度快、安全性高
-
主要适用于本地数据访问场景
-
局限于单进程通信,资源开销较大
-
-
SSE 传输(即将废弃):
-
基于 HTTP 协议,支持远程资源访问
-
使用双通道响应机制(SSE 连接 + POST 端点)
-
存在连接不稳定、扩展性差、浏览器限制等问题
-
不适合无服务器(serverless)环境和云原生架构
-
-
Streamable HTTP 传输:
-
替代 SSE 的新传输机制,兼容现代云架构
-
更灵活的连接模式,支持简单请求-响应和流式传输
-
标准化的会话管理和断点恢复功能
-
适合远程访问、无服务器环境和大规模部署
-
-
自定义传输机制:
-
MCP 协议支持实现自定义传输以满足特定需求
-
可以针对特定部署环境和使用场景进行优化
-
示例中实现了一个 Rest Transport,适合无状态、短连接场景
-
传输机制的选择应基于具体应用场景:
-
本地数据访问优先选择 stdio 传输
-
远程资源访问优先选择 Streamable HTTP 传输
-
特殊需求场景可考虑实现自定义传输
MCP 协议的可插拔传输架构使其能够灵活适应不同的部署环境和通信需求,从简单的本地工具到复杂的云服务均可支持。随着技术发展,传输机制也在不断优化,以提供更好的性能、可靠性和可扩展性。
一、大模型风口已至:月薪30K+的AI岗正在批量诞生
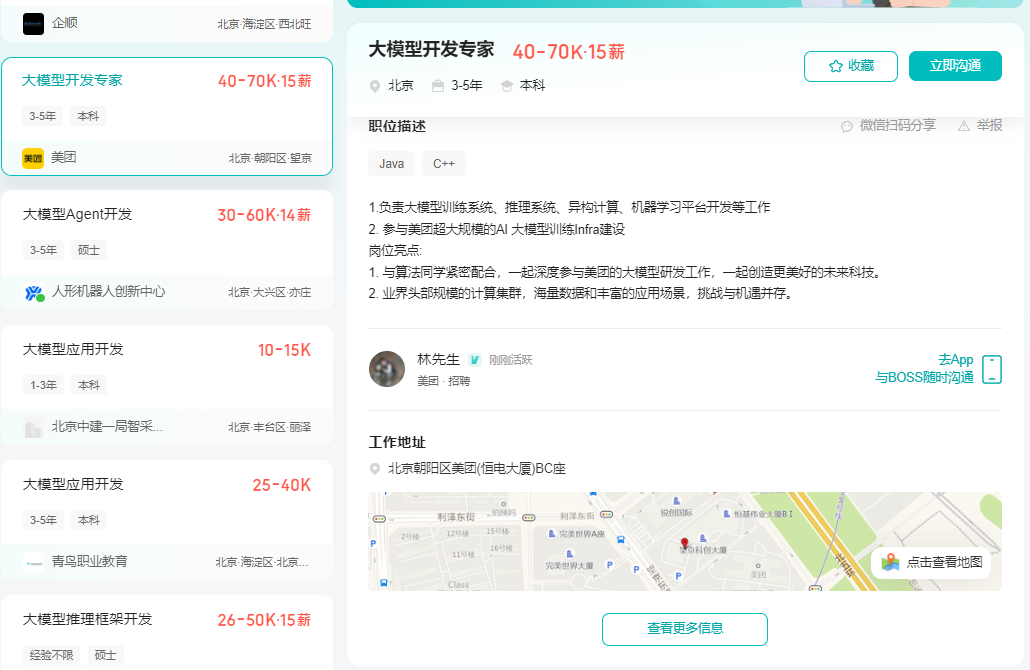
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!

二、如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









