






近期,Sakana AI 发表了一篇题为《Transformer Layers as Painters》的论文,探究了预训练 transformer 中的信息流,并针对仅解码器和仅编码器冻结 transformer 模型进行了一系列实验。请注意,该研究没有对预训练模型进行任何类型的微调。

论文地址:****https://arxiv.org/pdf/2407.09298v1
该研究认为 transformer 的内部机制(特别是中间层)可以类比画家作画流水线来理解。
_作画流水线_通常是将画布(输入)传递给一系列画家。有些画家擅长画鸟类,而另一些画家则擅长画轮子。每个画家从其下一级画家那里收到画布,然后其决定是否给画作添加一些笔画,或者只是将其传递给其上一级画家(使用剩余连接)。
这个类比并不是一个严格的理论,而是一个思考 transformer 层的工具。受这个类比的启发,该研究测试验证了一些假设:
-
各层是否都在使用相同的表征空间?
-
所有层都是必要的吗?
-
中间层都执行相同的功能吗?
-
层的顺序重要吗?
-
这些层可以并行运行吗?
-
对于某些任务来说,顺序是否比其他因素更重要?
-
循环有助于层并行吗?
-
哪些变体对模型性能影响最小?
该研究对预训练 LLM 进行了一系列实验,其中包括试验标准 transformer 执行策略的变化,并在仅解码器 (Llama) 和仅编码器 (BERT) 模型的各种基准上测量这些变化对模型性能的影响。
各层是否都在使用相同的表征空间?
为了回答不同层是否使用相同的表征空间,作者测试了 Transformer 在跳过特定层或切换相邻层的顺序时是否具有稳健性。例如,在 Llama2-7B 中,第 6 层通常期望接收第 5 层的输出。如果给第 6 层以第 4 层的输出,它是否会出现「灾难性」的行为?
在图 2 中,我们可以看到,除了第一层和最后几层之外,Llama2-7B 的各层对跳层或切换层都相当稳健。
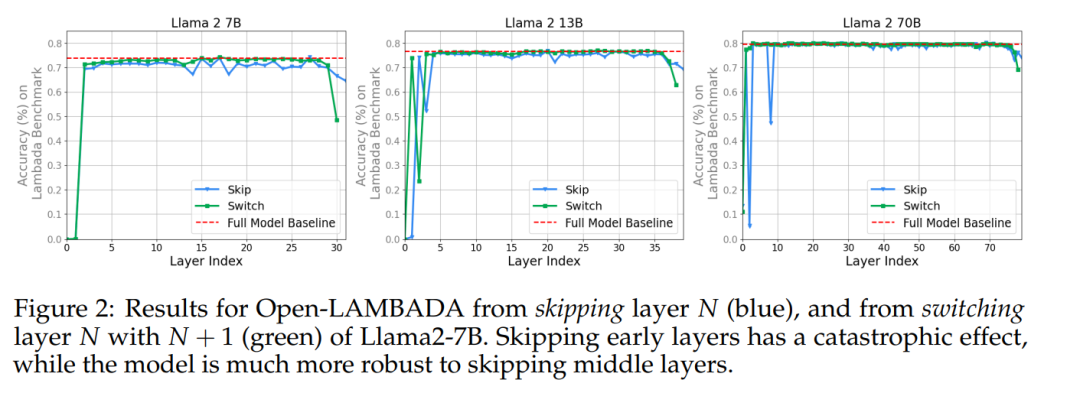
该实验表明,中间层共享一个表征空间,且与「外围层」(第一层和最后几层)拥有不同的表征空间。为了进一步验证这一假设,作者效仿之前的研究,测量了基准中模型(Llama2-7B、Llama2-13B 和 BERT-Large)不同层的隐藏状态激活之间的平均余弦相似度。图 3 显示了所有中间层之间的一致性。
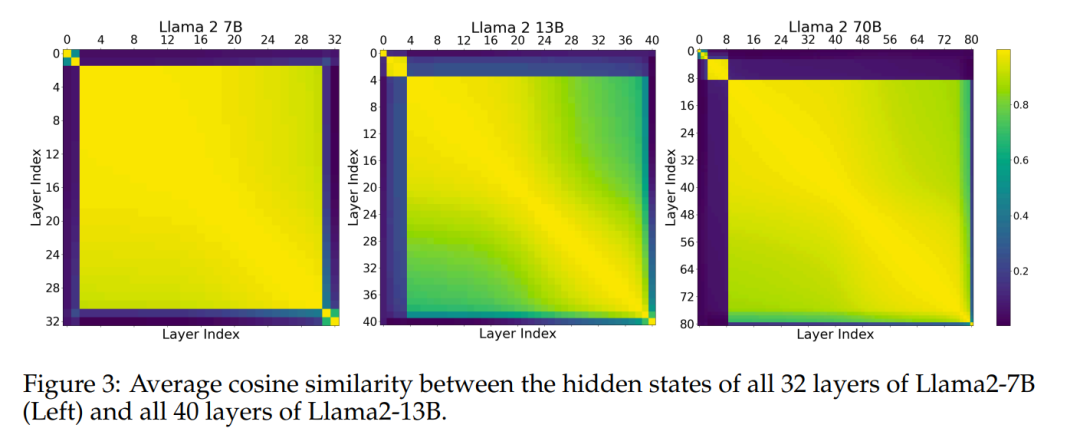
这表明该模型可能具有「开始」、「中间」和「结束」层的三个不同的表征空间。回答问题 1:是的,中间层似乎共享一个共同的表征空间。
所有层都是必要的吗?
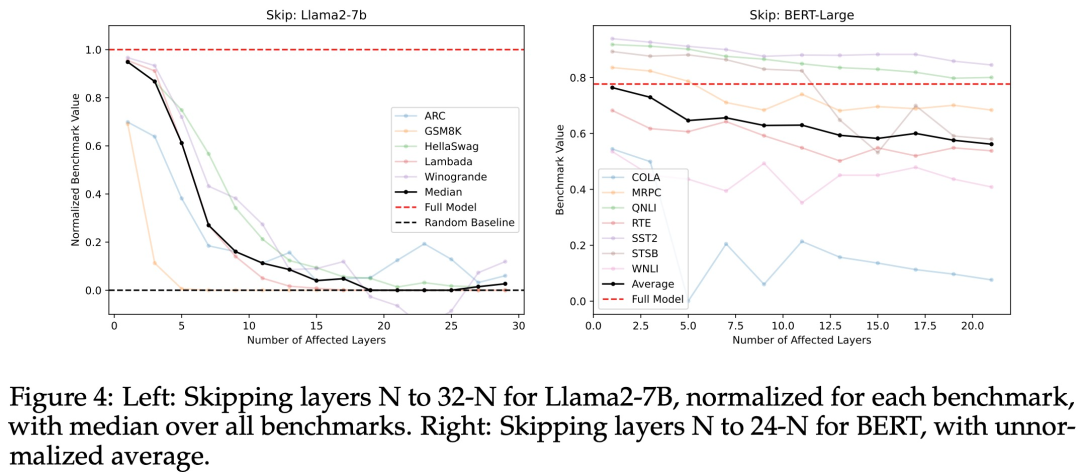
为了进一步测试中间层的重定向空间是否真正共享(除了具有接近的余弦相似度之外),该研究尝试了「跳过层」,即将第 N 层的输出直接发送到第 N + M 层(其中 M > 1)的输入中,从而「跳过」M − 1 层,如图 1a 所示。该实验是为了看看第 N + M 层是否可以理解第 N 层的激活,尽管它仅根据从第 N + M − 1 层发来的输入进行训练。图 4 显示,Llama2-7B 和 BERT-Large 在许多基准测试上性能均出现适度下降。回答问题 2,是否所有层都是必要的:
不,至少可以删除一些中间层而不会发生灾难性故障。
中间层都执行相同的功能吗?
如果中间层都共享一个共同的表征空间,这是否意味着除此之外的中间层是多余的呢?为了测试这一点,研究者们重新运行了前一子节中的「跳过」实验,他们将中间层的权重替换为中心层的权重,有效地在被替换的每一层上循环 T - 2N + 1 次,其中 T 是总层数(Llama2-7B 为 32 层,BERT-Large 为 24 层)。
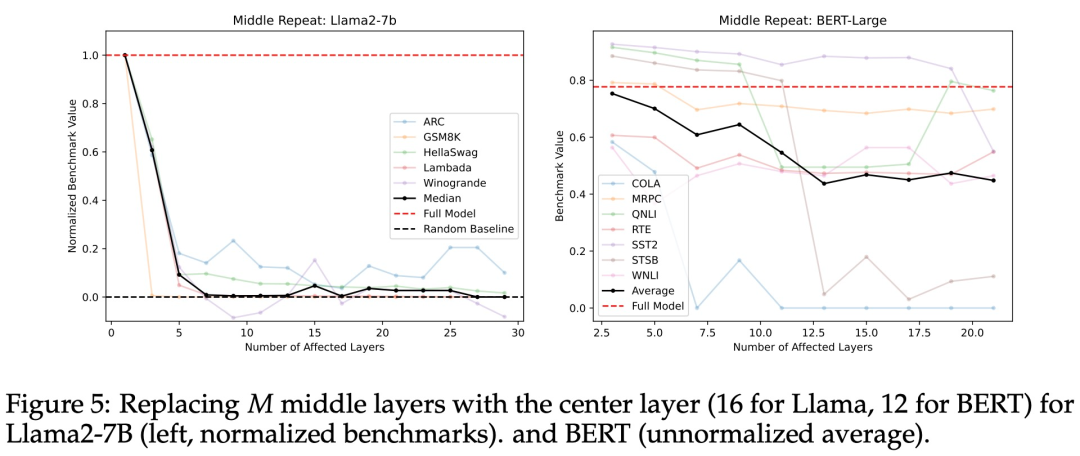
如图 5 所示,可以观察到,随着被替换层数的增加,模型在基准测试的得分迅速下降。从后文的图 11 看来,这种替换层的做法比研究者们尝试的其他方法都更糟糕。因此,研究者得出结论:中间层执行的是不同的功能,让中间层之间共享权重并不可行。

层的顺序重要吗?
之前的实验表明,中间层共享一个表示空间,但在该空间中负责不同的功能。下一个需要解决的问题是,这些功能的顺序有何意义。为了解决这个问题,研究者们设计了两组实验。首先,以与训练时相反的顺序来运行中间层。具体来说,取第 T - N 层的输出,将其输入到第 T - N - 1 层,然后将这一层的输出输入到第 T - N - 2 层,依此类推,一直到第 N 层,再将这一层的输出发送到后面的 T - N 层。在第二组实验中,研究者采用随机顺序运行中间层,并在 10 个种子值上取平均值。
图 6 和图 7 分别显示了反向和以随机顺序运行中间层的结果,模型在所有基础测试集中都显示出了逐渐下降的趋势。这也表明虽然层的顺序对模型来说有一定的重要性,但即使改变了顺序,这些层仍然能够发挥作用。
更有趣的是,随机打乱层的顺序比完全反过来效果更好。这可能是因为,随机打乱的顺序在某些方面保留了层之间的一些原有关系(即层 i 在层 j 之后,其中 i > j),而完全反过来则完全打破了这些关系。
这些层可以并行运行吗?
为了验证层本身存在比执行的顺序更重要,研究者们设计了一个实验,并行运行中间层,将它们的平均结果发送给最终的 N 层。
如图 8 所示,模型在所有基准测试中的表现均呈现了一种平缓下降趋势,然而,这种趋势并不适用于 GSM8K 中的数学应用题。
实验结果显示,大部分情况下这种方法都是有效的,只是一些复杂的数学题处理得不太好。这种并行处理方法相比直接跳过一些层,效果更好,但不如按反向顺序运行层的效果出色。基于此,研究者得出结论:并行运行层在一般情况下是可行的,但对于需要顺序逻辑理解的数学问题,这种方法可能不太适用。

对于某些任务来说,顺序是否比其他因素更重要?
对于大多数经过「改造」的模型,在面对抽象推理(ARC)或数学推理(GSM8K)基准测试时,它们往往显示出最陡峭的下降趋势。这一现象可能源于逐步推理任务对于模型层级顺序的敏感度远高于那些主要依赖语义理解的常识性任务。与那些仅通过理解语义便能完成的任务不同,推理任务要求模型同时把握结构与含义。这种观察与模型在单次处理过程中可能进行一定程度的顺序依赖性推理的假设相吻合。
研究者使用了一个比喻来说明:如果画一幅由许多不同元素组成的拼贴画,那么画的顺序可能不那么重要;但如果是要画一幅精确的建筑场景,那么每一笔的顺序就变得非常重要了。据此,研究者得出了结论:数学和推理任务对模型层的顺序具有更高的依赖性,而对于那些主要依赖语义理解的任务,顺序的影响则相对较小。
循环有助于层之间并行吗?
沿用上一节中画画的的比喻,当画家在画一幅画时,不是一开始就画所有东西,而是先画一部分,比如车身,然后再根据这部分来添加其他的东西,比如车轮。在 AI 模型中,层就是所谓的画家,处理信息就是在画画,如果先得到了正确的信息,也就先画出了所谓的车身,那么它们就能更好地完成自己的工作,为画作添加车轮。
对于 transformer 而言,当给予适当的输入时,层可能只在前向传播中做出贡献,并非通过残差连接「传递」输入。如果情况确实如此,那么迭代上一个实验中的并行层应该比单次执行并行层更能提高模型的性能。基于此,研究者通过将并行层的平均输出反馈到同一层中进行固定次数的迭代来测试这一点。
图 9 展示了将并行层循环 3 次的结果。循环并行 3 次的结果显著优于单次迭代(并行层)。起始层 N 设定为 15(针对 Llama2-7B 模型)或 11(针对 BERT 模型)时,即处于每种情况的极左端点,仅有单一的层级受到影响。在这种特定情况下,三次循环并行的效果等同于单纯地将中间层重复三次。与此同时,对于这一点上的并行层而言,其性能与完整模型无异。

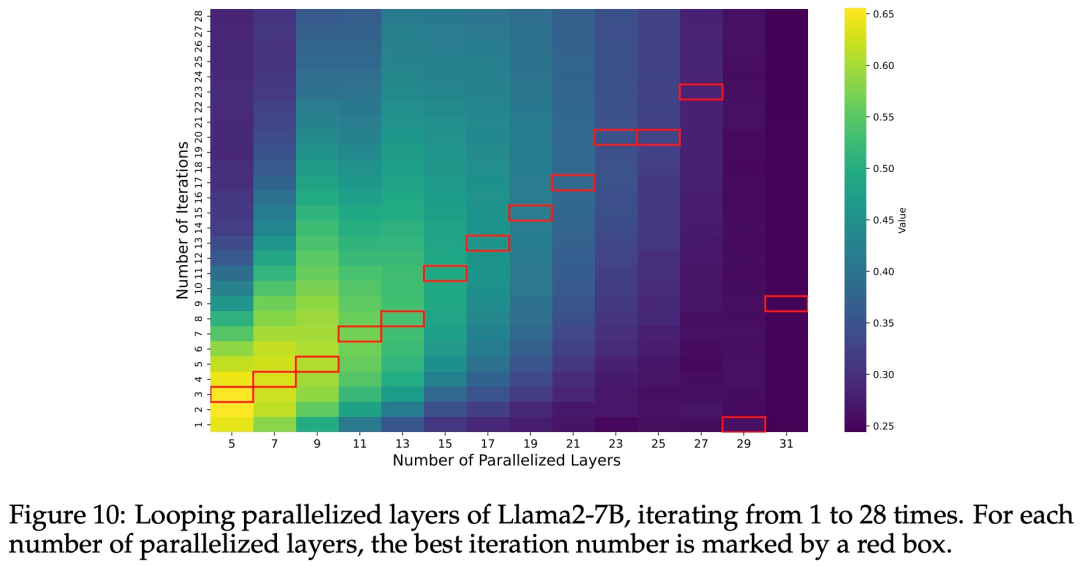
研究者们还针对不同的迭代次数重复了相同的实验。图 10 展示了 Llama2-7B 的性能随并行化层数 M 和迭代次数的变化情况。每个 M 的最高性能迭代次数用红框标出。除了 M=29 和 M=31(几乎并行化所有层)外,最佳迭代次数大致与并行化层数成线性比例。因此,研究者得出的结论是:最佳迭代次数与并行化层数成正比。
如何调整层,对模型性能的影响最小?
最后,在图 11 中,研究者们将所有实验中对 Transformer 的「改造」进行了比较,在一个图表上显示了所有基准测试的中位数或平均性 。
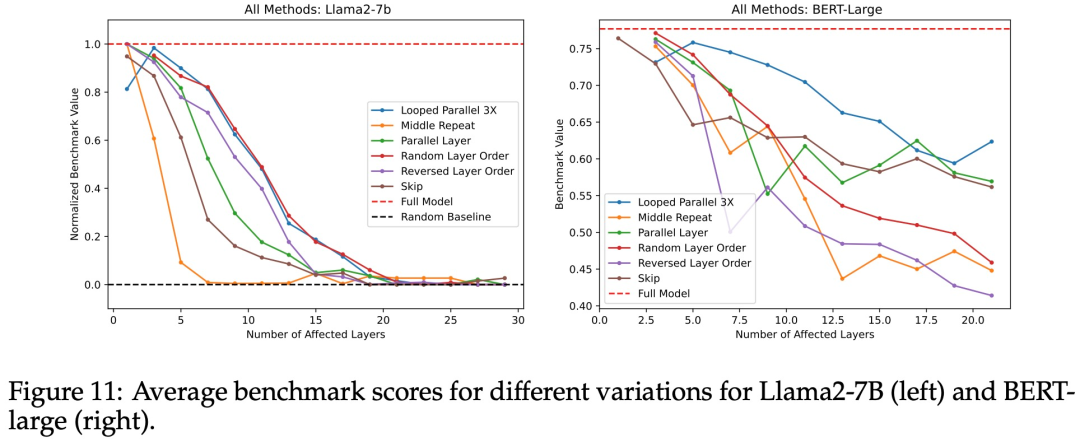
中间重复 —— 用相同数量的中间层副本替换中间层 —— 表现最差, 很快就降到了随机基线的性能。相反,循环并行和随机层顺序的影响最小。因此,研究者得出的结论是:重复单一层的影响最严重。随机化层顺序和循环并行的影响最小。
这些实验整体上显示出平缓的性能下降,但研究者仍然不清楚为什么这些层在大多数扰动下还能保持一定的稳健性,这个问题还需在未来的研究中进一步探讨。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 3753
3753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









