






大语言模型中的提示隐私保护
一、简介:
大语言模型(LLM) 拥有庞大的规模、预先训练的知识和卓越的性能,被广泛应用于各种任务。提示学习(prompt learning)和指令微调(instruction tuning) 是两种重要的使得大模型能理解具体任务的技术手段。然而,这些prompt或instruction常常会包含隐私信息,使得难以直接共享。本文讲解了两篇大语言模型中的prompt和instruction的隐私保护论文,它们都致力于如何在保护隐私的前提下利用大模型生成高质量的prompt和instruction。
二、Prompt的隐私保护:
❝
论文:Flocks of Stochastic Parrots: Differentially Private Prompt Learning for Large Language Models
会议:NeurIPS 2023
Motivation
现有研究表明,LLM会记住用于训练或微调LLM的数据信息,从而造成数据隐私泄露 [1,2]。除了这些在训练/微调LLM时用到的数据隐私,当利用训练好的LLM执行下游任务时,所用到的prompt同样也会泄露用户隐私。比如,prompt可能会涉及知识产权,甚至有些prompt可能包含用户个人隐私信息。为了验证这个猜想,本文首先基于文本分类任务的prompt进行了成员推理攻击(MIA),目的是判断某个私有数据是否用在了prompt中。这里MIA的核心思想是,如果一个私有数据用在了prompt中(member),那么prompted LLM输出此数据正确类别的概率会比non-member要高(这里我感觉只适用于soft prompt,离散prompt不存在训练过程)。实验结果如图1所示: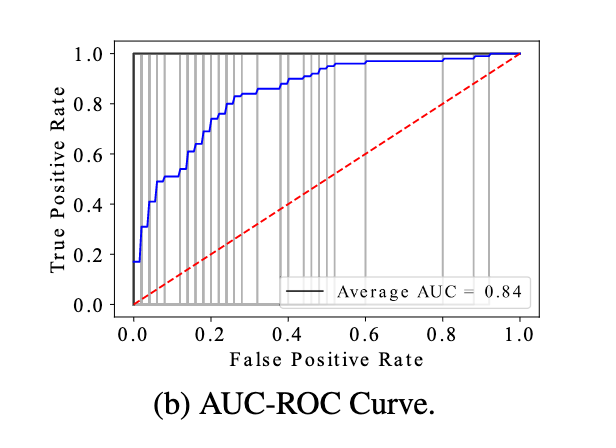
可以发现,MIA成功率比random guess(红线)要好很多。因此作者得出结论prompt本身也会泄露用户隐私(感觉只能说soft prompt会泄露用户隐私)。
Method
首先本文设定LLM是黑盒访问,即不能改变LLM的参数,并且本文的任务限定为文本分类任务。为了防止隐私泄露,作者针对soft prompt和discrete prompt分别提出了方案。首先对于soft prompt,因为要发布的是prompted之后的模型,本质目的是为了让prompt向量不记住原始数据的隐私,所以可以直接用现有的DPSGD算法[3]来进行prompt向量的更新,称为PromptDPSGD。模型图如下:

对于discrete prompt,由于无法使用DPSGD,作者考虑利用原始的private prompts去生成新的满足差分隐私的prompt来发布(但本文限定在文本分类任务,所以合成操作只是合成了最后一个token,即文本的class,并没有考虑任意文本形式的prompt生成)。它借鉴了PATE(Private Aggregation of Teacher Ensembles)[4]模型的思想。PATE模型的提出是为了让机器学习\深度学习模型满足差分隐私性质。它首先将隐私数据划分成多个部分,然后在每个部分数据集上训练一个teacher模型,假设存在一些和隐私数据分布一致的public unlabeled data,PATE利用每个teacher模型给这些unlabeled data打标签,然后将所有teacher模型的结果做一个投票,并将投票的结果加入拉普拉斯噪音作为label。这样就把隐私数据的知识传递给了public data,并且可以证明满足差分隐私的性质。为了减少隐私预算,PATE利用labeled public data再训练一个student model,这样根据后处理规则,只有训练student model的数据会消耗隐私预算,之后的查询将不再消耗隐私预算。将PATE利用到discrete prompt,作者提出promptPATE,首先划分隐私数据并在每部分数据中设计private prompts作为teacher,然后将这些teacher prompts拼接unlabeled public data输入到LLM进行打标签,同样加入拉普拉斯噪音。最终从labeled public data中选取代表性的prompt作为student prompt进行发布。PromptPATE流程图如下所示:
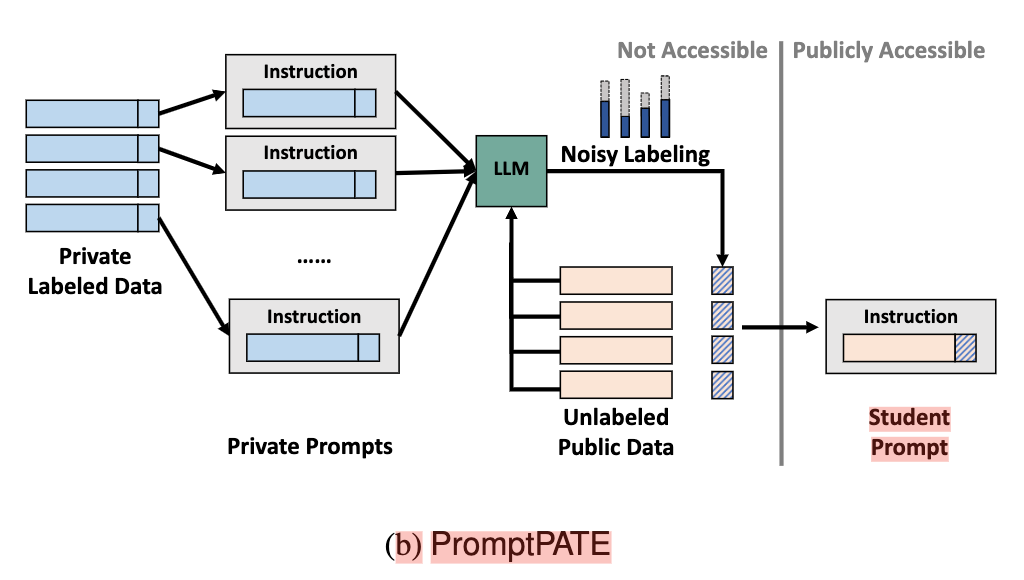
Experiments
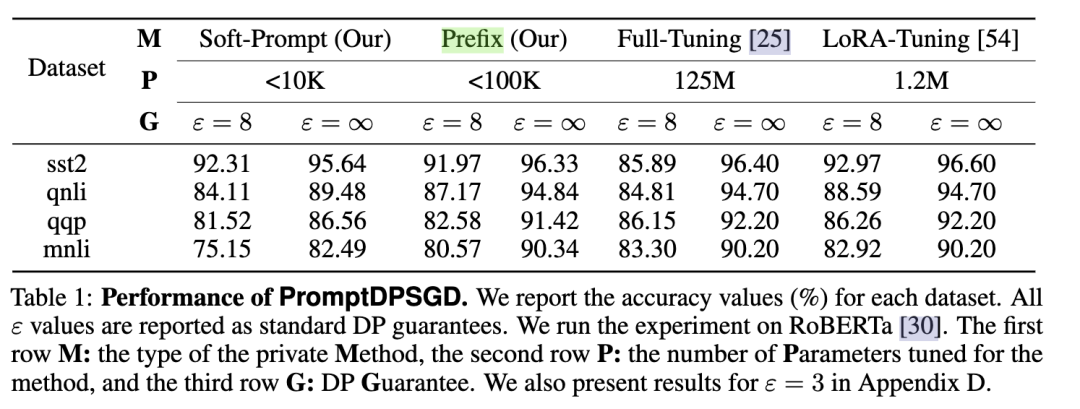
作者在四个文本分类数据集中验证了PromptDPSGD和PromptPATE的效果。可以看出,对比Prefix,full-tuning,LoRA三种调整大模型的方式,PromptDPSGD需要微调的参数更少,并且能达到相当的效果,同时还以合理的隐私预算满足了差分隐私性质。
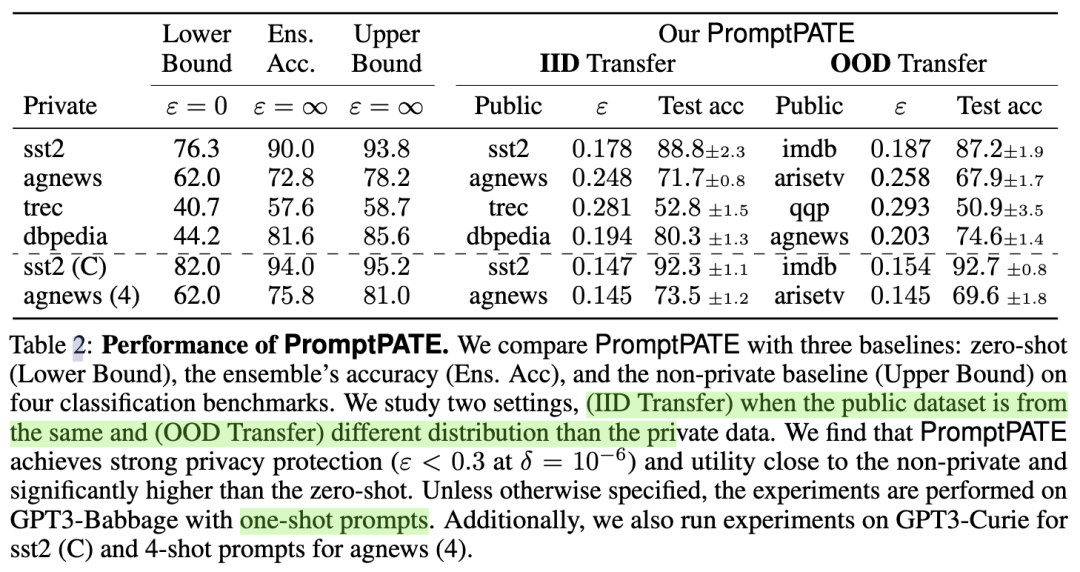
而对于离散的prompt,作者比较了不同数据集的效果,以及IID和OOD下的迁移能力,可以看出PromptPATE在很少的隐私预算下达到了和不加隐私保护相当的效果,同时也发现当prompt样本数增多时(n-shot)和利用更强大的语言模型时(如GPT3-Curie),模型的效果会更好。
Conclusion
之前的工作对于LLM的隐私保护致力于防止大模型记住训练数据的隐私,即在训练或微调大模型的时候来保护这些训练数据的隐私。而这篇论文是第一篇保护prompt本身的论文,或者说,是在训练好大模型之后的阶段,利用大模型来做下游任务时对于下游数据的隐私保护。模型主要贡献点在于对离散prompt的保护,提出利用PATE合成满足差分隐私的promp,并在合理的隐私预算下取得了比较满意的结果,但是本文在motivation层面比较模糊(prompt是否含有隐私以及保护prompt隐私的挑战点),而且提出的模型只针对于few-shot文本分类任务(只是合成label),没有做到任意形式的prompt合成。
三、Instruction的隐私保护:
❝
论文:Privacy-Preserving Instructions for Aligning Large Language Models
会议:ICML 2024
Motivation
上一篇论文致力于prompt本身的保护,假设对LLM是黑盒访问,不涉及LLM参数的微调。这篇论文更进一步,提出对instruction的保护。作者首先给出了instruction-tuning的一般步骤: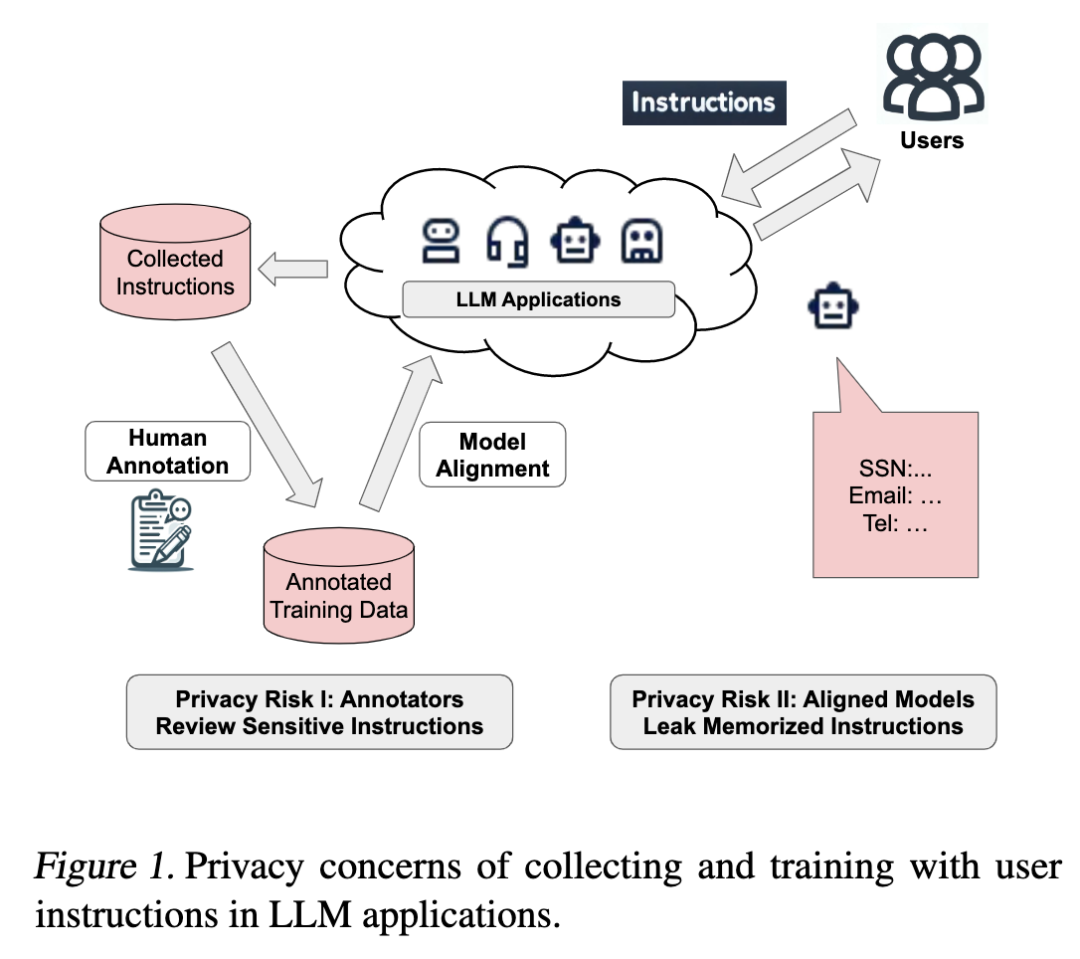
相较于对prompt的保护,instruction涉及微调大模型,因此整个过程包含了两方面的隐私泄露:(1)制作instruction的时候,需要手动给instruction打标签,这个时候收集的原始instruction中的隐私信息会泄露给打标签的人,(2)在微调LLM的时候,LLM本身会记住instruction中的隐私信息。简单来说就是保护instruction本身和防止LLM参数记忆。
Method
和promptPATE类似,这篇论文也提出合成满足差分隐私性质的instruction来替代原始instruction进行发布。整个流程如下图所示: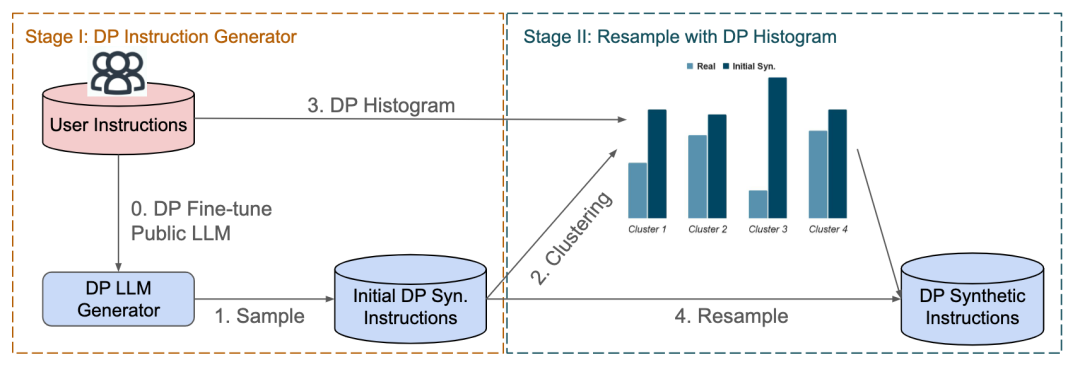
它共涉及两个阶段,第一个阶段是满足差分隐私的instruction-tuning。这里它同样采用了DP-Adam来对大模型进行隐私保护微调,此过程满足差分隐私(防止LLM记忆user instruction),所以微调后的LLM也可以进行发布。在得到微调后的LLM之后,就可以从LLM中采样生成合成的instructions,这也是和promptPATE不同的地方,promptPATE是少量(few-shot)文本分类prompt的合成,这里是大量任意文本形式的instructin合成(但这里应该需要大量的user instructions才能生成可用的合成instruction)。由于LLM的微调是基于DP-Adam,根据差分隐私后处理特性,后续对LLM的采样不消耗隐私预算。可以看出,相较于原始的instruction-tuning,这里第一阶段利用LLM来生成满足差分隐私的instructions,避免了标注人员的介入,并且得到的instructions不包含用户隐私,所以可以直接进行下游任务的instruction-tuning。但是,此时得到的instruction效用比较低,并不能直接代替原始instruction,所以作者又提出了第二阶段的instruction校正。核心思想是让合成instruction的分布和原始user instruction一致。首先将合成instruction和user instruction都经过编码器得到向量表示,然后对合成instruction进行k-means聚类分成k个簇。同时将user instruction的向量表示划分到每个簇中(按照到各个簇中心的距离)。这样就得到real user instruction的分布和合成 instruction的分布,之后对合成 instruction进行重新采样来逼近real instruction分布就可以了。注意此过程中real instruction的分布会泄露数据隐私,所以在得到向量后需要加上高斯噪音再进行发布以满足差分隐私。这里簇的大小K是隐私和效用的折中,教大的K会使分布刻画更准确但可能会更易受噪音影响(每个簇中的real instruction会变少),实验也发现,效用会随着K的增大先增加后平缓甚至减小。
Experiments
作者首先衡量了real instructions和合成instruction的分布差异,分别利用unigram和sentence-T5两个方法来衡量分布,利用MAUVE score来衡量分布差异。FLAN是一个public的OOD instruction datasets,可以看出虽然有很多public instructions,in-domain sensitive instructions仍旧是很重要的,public instructions的分布和in-domain的分布差异很大。同时可以看出,filtering(第二阶段的校正)有效缓解了分布差异。
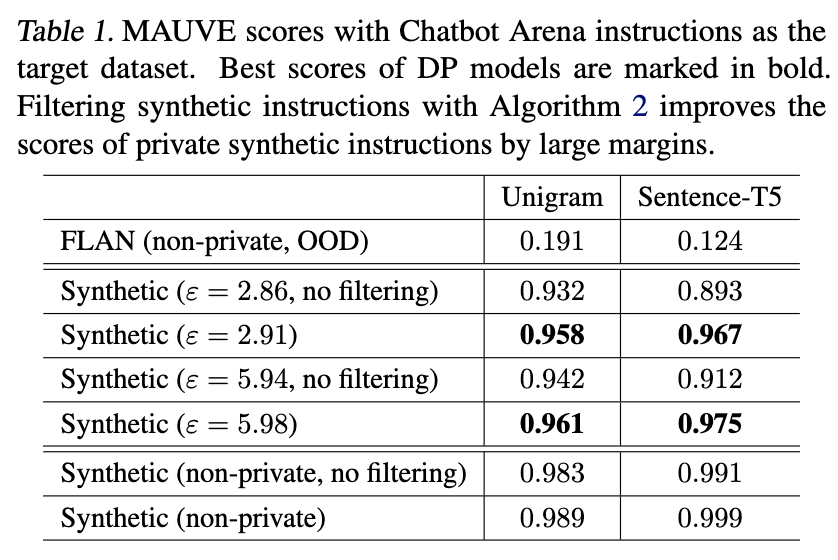
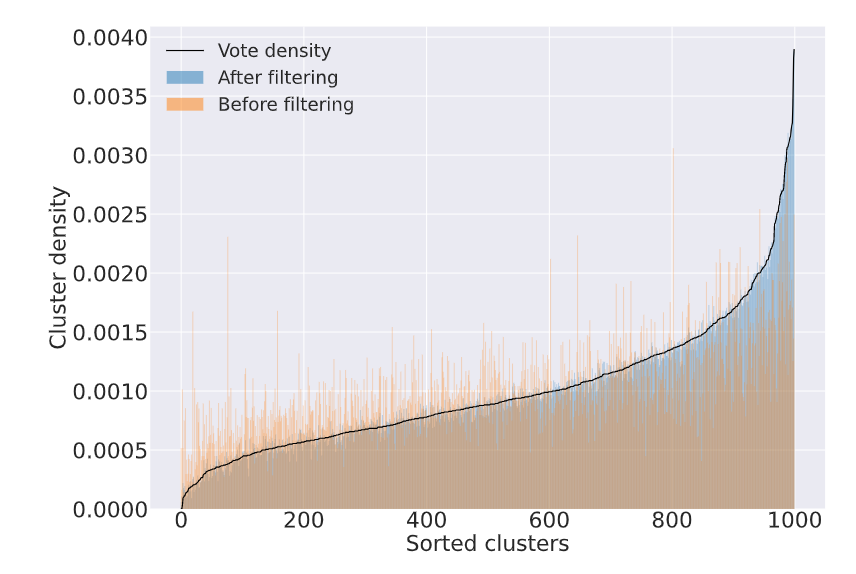
下图同样展示了校正后的分布更贴近real instruction分布。
对于合成instruction的效用,作者比较了OOD instruction(FLAN),没有fine-tuning的public 模型Vicuna-v1.3,private instructions(Chatbot Arena)和本文合成的数据集(Synthetic)的效果。可以看出合成数据集达到了和real instructions相当的效果,并且优于FLAN和Vicuna-v1.3。这也说明了in-domain private instructions和对LLM进行fine-tune的重要性。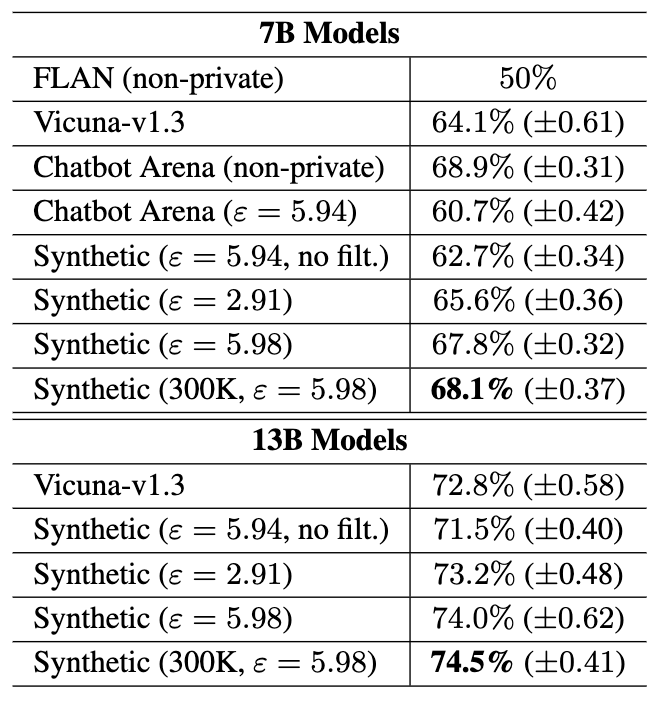
Conclusion
本文利用user的隐私instruction微调LLM合成满足差分隐私的instruction,然后再进行校正提高效用,最终就可以将合成的instruction进行发布。但本文需要用户端部署并微调LLM,这对资源受限设备提出了挑战。
四、总结
现有研究大多集中于研究如何防止LLM在训练过程中记忆训练数据中的隐私信息[4,5],这两篇论文致力于保护prompt/instruction本身的隐私,属于LLM应用中对不同对象的隐私保护。但对prompt/instruction的保护在隐私定义方面还比较模糊,在用户的instruction中可能只有部分信息具有隐私,或者用户会共享部分的信息,这种情况下需要设计更加个性化的prompt/instruction的隐私保护手段。同时还需要考虑在资源受限设备中的隐私保护手段(因为很难将LLM部署到资源受限设备上,所以现有基于LLM的prompt/instruction发布不可行)。后续可能研究方向还包括对多种模态数据的prompt/instruction隐私保护。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









