






在AI浪潮席卷全球的今天,Transformer模型早已成为技术圈的“顶流”,从自然语言处理的惊艳表现到图像识别的突破性应用,它无处不在,无所不能。简历上那一行“精通Transformer”,仿佛是一张通往大厂的门票,闪耀着求职者的野心与自信。可当面试官微微一笑,抛出那句轻描淡写却暗藏杀机的问题——“那你说说,Q、K、V在Transformer里到底是怎么回事?”——你的心跳是否会漏一拍?如果QKV对你来说只是三个字母的堆砌,而不是活生生的机制与逻辑,那么这场“精通”的豪言壮语恐怕要露馅了。这篇文章将带你直击Transformer的核心,直面QKV的真相。准备好迎接挑战了吗?让我们一起撕开迷雾,看看你有没有真本事让“精通Transformer”名副其实!
一、Q、K、V是什么?
在LLM的文本生成过程中,Q、K、V是注意力机制的核心概念,广泛应用于Transformer架构中。简单来说,它们就像一个高效的信息筛选和整合系统,帮助模型决定“接下来该说什么”。让我们逐一拆解:
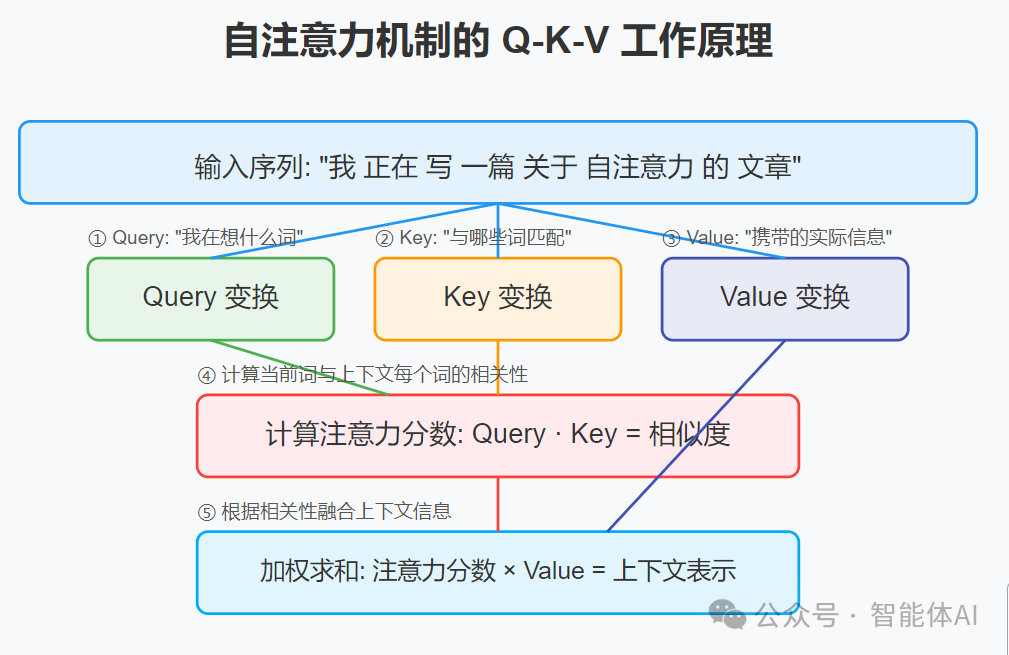
- Query(Q,查询) Query代表当前正在处理的词或词组。想象你在写文章,写到一半时停下来思考:“接下来这个词应该跟前面的哪些内容有关?”在自注意力机制中,每个词都会被当作一个Query。对于文本生成任务,Query通常是模型已经生成的词,我们的目标是通过它来“询问”上下文,找出与它最相关的部分,以便生成下一个词。
- Key(K,键) Key是一组候选词或词组,用来跟Query进行“匹配”。在自注意力机制中,每个词同时也扮演Key的角色。模型会通过计算Query和每个Key之间的相似度(通常用点积等方法),得出一个“注意力分布”。这个分布告诉你:对于当前的Query,哪些词更重要,哪些词可以稍微忽略。
- Value(V,值) Value跟Key是一对一对应的,它代表每个候选词的实际语义信息。一旦模型通过Query和Key算出了注意力分布,就用这个分布对所有的Value进行加权求和,最终得到一个“上下文表示”。这个表示就像一个信息融合的结果,包含了与当前Query最相关的内容,模型会用它来决定下一个词是什么。
简单总结一下:Query负责提问,Key负责匹配,Value负责提供答案。三者合作,让模型能够动态关注最重要的信息。
二、Q、K、V在Transformer里怎么工作?
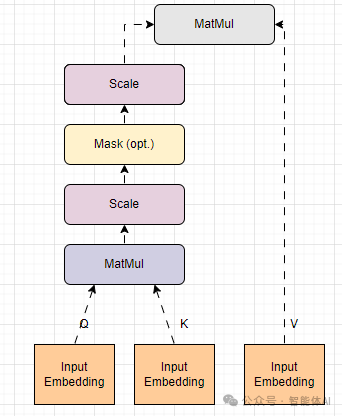
Transformer是现代LLM的支柱架构,而Q、K、V正是它的核心引擎。在Transformer的自注意力层中,输入的词序列(比如一句话)首先会被转换成三个矩阵:Q矩阵、K矩阵和V矩阵。这三个矩阵的形状通常是“序列长度 × 隐藏层大小”。
接下来,模型会执行以下步骤:

- 把Q矩阵和K矩阵的转置相乘,计算出每个Query和Key之间的相似度。
- 为了避免数值过大,通常会除以一个缩放因子(一般是隐藏层大小的平方根)。
- 通过Softmax函数,把相似度转化为注意力权重,确保所有权重加起来等于1。
- 用这些权重对V矩阵进行加权求和,得到最终的输出表示。
在文本生成任务中,Transformer的解码器会拿前面已经生成的词作为Query,去跟编码器的输出(或解码器自己的隐藏状态,作为Key和Value)互动,一步步生成后续的词。这个过程会不断循环,直到生成一个结束标志(比如“”)或者达到预设的最大长度。
三、Q、K、V如何生成连贯的文本?
为了让大家更直观地理解,我们用一个具体的例子来看看Q、K、V是怎么工作的。假设我们给模型一个提示:“欢迎关注智能体AI公众号”,希望它接着生成后续的文本,比如“,这里有最前沿的AI资讯”。现在,我们聚焦在生成“这里”这个词的瞬间。
生成过程的两个阶段:*预填充(Prefill) 和 采样(Sampling)*。
-
预填充阶段 在这个阶段,模型会根据前面的上下文(“欢迎关注智能体AI公众号”)和它学到的语言规律,预测下一个词的可能性。换句话说,它会用Q、K、V机制计算出一个概率分布,告诉你每个候选词(比如“这里”、“欢迎”、“关注”等)的可能性有多大。在我们的例子中,模型发现“这里”是个高概率的词,因为“公众号这里”可以自然地引出对公众号的介绍。
-
采样阶段 有了概率分布,模型会从中“挑”一个词出来。怎么挑呢?有几种常见方法:
-
贪婪采样:直接选概率最高的词(比如“这里”)。
-
随机采样:根据概率随机抽一个词,增加多样性。
-
束搜索:保留几个高概率的候选序列,继续往下生成。 在这个例子中,我们假设模型选了“这里”,把它加到序列里,然后重复这个过程去预测下一个词。
-
四、Q、K、V的具体计算
让我们深入看看生成“这里”时,Q、K、V是怎么协作的:
- 初始化 模型把“这里”的嵌入向量当作Query(Q),把前面的词“欢迎”、“关注”、“智能体”、“AI”、“公众号”的嵌入向量当作Key(K)。
- 计算相似度 模型会算出“这里”跟每个Key的相似度。假设结果是:
- Similarity(“这里”, “欢迎”) = 0.1
- Similarity(“这里”, “关注”) = 0.2
- Similarity(“这里”, “智能体”) = 0.3
- Similarity(“这里”, “AI”) = 0.4
- Similarity(“这里”, “公众号”) = 0.8 这里“这里”和“公众号”的相似度最高,因为“公众号这里”常用于引出对公众号的介绍。
- 转化为注意力权重 用Softmax函数处理这些得分,得到权重:
- Attention_weights = Softmax([0.1, 0.2, 0.3, 0.4, 0.8]) ≈ [0.05, 0.07, 0.10, 0.13, 0.65] 这意味着“公众号”对“这里”的影响最大(65%),其他词的影响较小。
- 加权求和 每个词还有一个Value向量,代表它的语义信息。假设是:
- Value(“欢迎”) = [0.2, 0.1, …, 0.5]
- Value(“关注”) = [0.3, 0.2, …, 0.4]
- Value(“智能体”) = [0.1, 0.3, …, 0.2]
- Value(“AI”) = [0.4, 0.2, …, 0.3]
- Value(“公众号”) = [0.5, 0.2, …, 0.9] 用注意力权重计算“这里”的上下文表示:
- Context(“这里”) = 0.05 × Value(“欢迎”) + 0.07 × Value(“关注”) + 0.10 × Value(“智能体”) + 0.13 × Value(“AI”) + 0.65 × Value(“公众号”)
- 结果 ≈ [0.42, 0.20, …, 0.75]
这个上下文表示融合了所有词的信息,但“公众号”的贡献最大。模型会用它来预测下一个词,比如“有”或“提供”。
五、Q、K、V的强大之处
通过这种机制,模型能动态关注跟当前任务最相关的上下文。比如在“欢迎关注智能体AI公众号”中,它知道“这里”应该更关注“公众号”,而不是“欢迎”。这种灵活性让模型不仅能生成连贯的文本,还能处理长距离的依赖关系(比如一句话里前后隔得很远的词之间的联系)。
在实际模型中,这个过程还会通过“多头注意力”(Multi-Head Attention)重复多次,每“头”关注不同的语义层面,再通过多个Transformer层叠加,捕捉更复杂的语言模式。
六、总结
通过这篇文章,我们一起揭开了Transformer中Q、K、V的神秘面纱,看到了它们如何协作,成为模型理解和生成文本的核心引擎。Q、K、V不仅是Transformer的基石,更是现代AI大模型能够妙笔生花、出口成章的秘密所在。理解了它们,你就抓住了Transformer的灵魂。下次面试官再抛出“Q、K、V是什么?”的问题时,你可以从容回答:“Query负责提出需求,Key负责匹配相关性,Value负责提供具体内容,三者合力让模型精准聚焦关键信息。”这不仅是一个答案,更是你实力的证明!但别止步于此,Transformer的世界深邃而精彩,等待你去探索更多。真正的强者,不仅能讲清Q、K、V,还能用它们攻克实际难题。愿你带着这份自信,在AI的征途上大放异彩,成为面试官忍不住点赞的那颗星!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









