






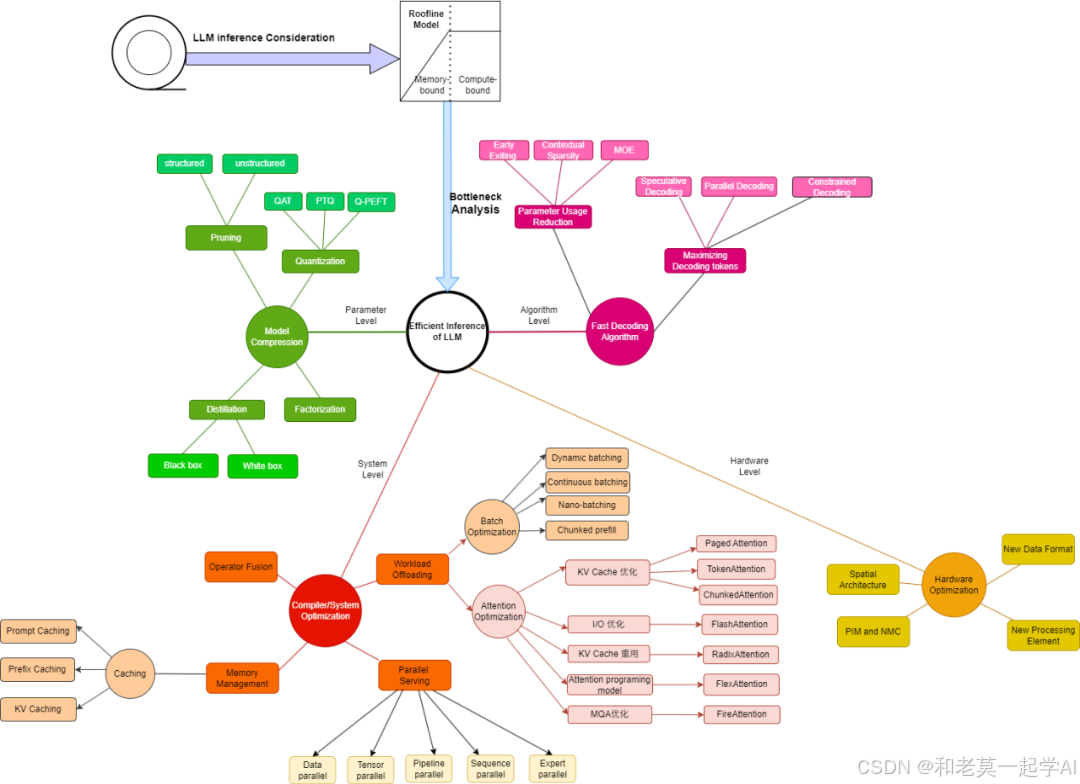
当我们在谈大模型推理优化技术的时候,可以从如图几个层面来考虑。
一、Roofline 模型
评估大语言模型部署到特定硬件上的效率需要综合考虑硬件和模型特性。 通常采用了 Roofline 模型。 Roofline 模型作为一个有效的理论框架来评估在特定硬件上部署模型的潜在性能。
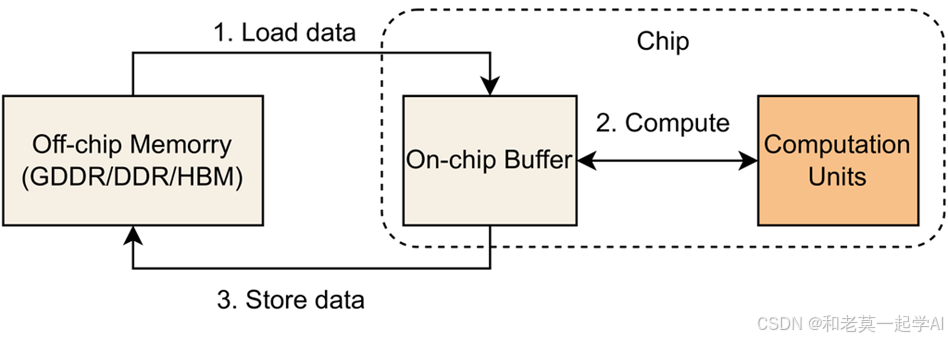
如图所示,在硬件设备上执行神经网络层需要将数据从内存(DDR 或HBM)传输到片上缓冲区,然后由片上处理单元执行计算,最终将结果输出回内存。 因此,评估性能需要同时考虑内存访问和处理单元能力。 如果某个层涉及大量计算但内存访问最少,则称为计算瓶颈。 这种情况会导致内存访问空闲。相反,当某个层需要大量内存访问而计算需求较少时,它被称为内存瓶颈。 在这种情况下,计算单元仍未得到充分利用。 我们可以根据Roofline模型清楚地区分这两种场景,并提供不同情况的性能上限。
二、Model 层面
剪枝(Pruning):就像给树枝剪去多余的枝叉一样,把模型中相对不那么重要的参数去掉,使模型变得更紧凑,减少计算量。
结构化与非结构化(structured & unstructured)剪枝:这是剪枝的两种方式。结构化剪枝是指按照某种规则或模式去除模型中的参数。这种规则通常是可以明显地改变模型的拓扑结构的,比如移除整个神经元、整个卷积核或整个通道。非结构化剪枝是指随机或基于某种启发式方法选择性地去除模型中的单个参数(如权重或偏置),而不改变模型的拓扑结构。
量化(Quantization):把模型参数用更少的比特数表示,比如从 32 位浮点数量化到 8 位甚至更少位的整数,从而降低存储空间和计算复杂度。
QAT、PTQ、Q-PEFT :它们是量化过程中的不同方法。QAT(量化感知训练)是在训练阶段就考虑量化因素;PTQ(后训练量化)是直接对训练好的模型进行量化;Q-PEFT 则是在量化的基础上应用一种叫 PEFT(参数高效微调)的技巧,以在压缩模型的同时尽量保留其性能。
模型蒸馏(Knowledge Distillation)是一种用于提高机器学习模型效率的技术,特别是在深度学习中广泛应用。它通过将一个大型复杂模型(称为“教师模型”)的知识传递给一个更小、更简单的模型(称为“学生模型”),使学生模型能够在保持较高性能的同时,减少计算资源和时间的消耗。
模型的 Factorization(分解) 是一种用于压缩和优化模型的技术。它通过将模型中的某些组件(如权重矩阵、激活等)分解为更小的子组件,从而减少模型的复杂度和计算量。从不同的角度可以理解其含义:参数矩阵分解(Parameter Matrix Factorization)、核分解(Kernel Factorization)、低秩近似(Low-Rank Approximation)、张量分解(Tensor Factorization)…
三、快速解码算法层面
减少参数使用(Parameter Usage Reduction) :想办法降低模型在推理时对参数的调用量,比如采用更高效的数据编码方式等。
早停(Early Exiting):在模型还没完全把所有计算都做完、但已经能得出一个相对可靠结果的时候就提前结束推理过程,从而节省计算时间。
上下文稀疏性(Contextual Sparsity):利用模型在处理不同输入时,有些部分的参数其实并不关键这个特点,只保留关键部分的计算,让模型变 “轻”。
MOE(Mixure of Expert):一种用于提升模型性能和效率的架构设计方法。它通过结合多个专家模型(Expert Models)的预测结果,形成一个更强大的整体模型。MoE 的核心思想是“分而治之”,即让不同的专家模型专注于处理输入数据的不同部分或特征,然后通过一个门控网络(Gating Network)动态地选择或组合这些专家模型的输出,从而提高模型的表达能力和效率。
最大化解码令牌(Maximizing Decoding tokens) :尽可能一次生成多个解码令牌,而不是一个一个慢慢生成,提高生成速度。
Parallel Decoding(并行解码):小模型(草稿模型)先生成多个 token,然后大模型(目标模型)对这些 token 进行验证并生成一个 token 。若小模型生成的 token 被大模型接受,生成多个 token 的时间就会缩短,因为小模型的推理时间低于大模型。比如 Medusa 和 Eagle2。
Speculative Decoding(投机解码):草稿模型先生成多个 token,然后目标模型一次性并行验证这些 token 的合理性,并根据验证结果接受或拒绝这些 token。如果草稿模型生成的 token 被接受,就直接作为输出;如果被拒绝,目标模型会重新采样生成新的 token 。
Constrained Decoding(约束解码):在生成 token 的过程中,对模型的下一个 token 预测进行限制,使其只预测不违反所需输出结构的 token。例如,生成符合特定 schema 的 JSON 或 XML 数据时,只从符合 schema 要求的 token 中采样。
四、系统层面
算子融合(Operator Fusion) :把模型中多个连续的算子合并成一个大操作,减少中间步骤的开销,就像把多个工序合并成一道工序来提高效率。
工作负载卸载(Workload Offloading) :把一部分计算任务分给其他更适合的设备去处理,比如把一些计算交给 GPU 或专门的硬件加速器,而不是全让 CPU 承担。
-
Baching的优化:包括了Continus baching,Dynamic batching,Nano-baching和Chunked prefill。之前的static batching 处理固定数量的请求,新请求需要等待当前批请求完成后,才能开始推理,增加了推理时延。dynamic batching, continuous batching 实时自适应批请求,可以减少推理时延、提升效率。

Continus baching允许在生成过程中动态调整批处理的大小。一旦一个序列在批处理中完成生成,就可以立即用新的序列替代它,从而提高了 GPU 的利用率。这种方法的关键在于实时地适应当前的生成状态,而不是等待整个批次的序列都完成。
Dynamic batching将多个用户的请求组合成单个批次以最大化吞吐量。新请求到达时,会与现有批进行合并或添加到正在处理的进程中。
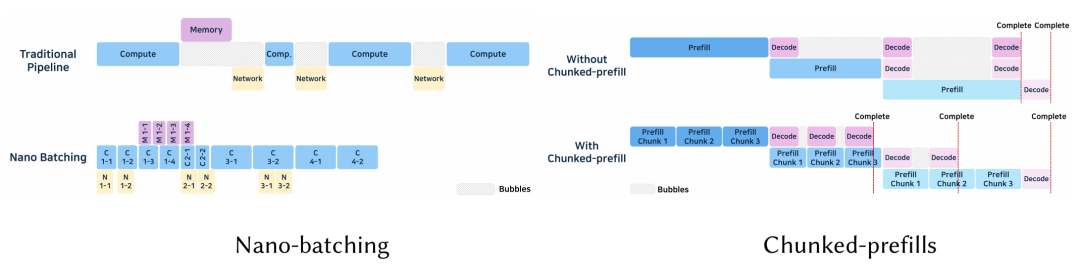
Nano-batching对算子级别切分,单卡上并行计算、访存、网络通信操作,最大化利用资源和提高吞吐率。动态调整 nano-batch 大小,优化每类资源。
Chunked prefill 将长提示词拆分成多个片段,增量式处理。第一个片段开始解码的同时,后续的片段也可以进行预填充,两个阶段可以并发计算,增强了资源利用率。
-
Attention层面的优化,包括KV Cache 的优化:PagedAttention, TokenAttention和ChunkedAttention; 以及减少I/O访问的FlashAttention;使得KV Cache可重复利用的RadixAttention和其他等Attention。
内存管理(Memory Management):合理分配和使用内存,避免出现内存不足或者内存浪费的情况,让模型能更顺畅地运行。通常会使用到缓存(Caching)技术 :包括提示缓存、前缀缓存、KV 缓存等,简单来说就是把一些经常用到的数据先存起来,下次用的时候直接拿,不用再重新计算或获取。
-
Prompt Caching 将提示(prompt)的中间计算结果缓存起来,以便在后续相同的或相似的请求中复用。当模型处理多个具有相同前缀的请求时,可以避免重复计算提示部分的 Key 和 Value 向量,直接使用缓存结果,从而提高效率。
-
Prefix Caching 通过缓存请求的共享前缀对应的键值缓存(KV Cache)块,当新请求的前缀与之前请求相同时,直接复用这些缓存块。它扩大了 KV Cache 的生命周期,使其不再局限于单个请求,而是可在多个请求间共享。
-
在 Transformer 模型的自注意力机制中,KV Caching 将已计算的 Key 和 Value 向量缓存起来,避免在自回归生成过程中重复计算。在生成新 token 时,只需计算当前 token 的 Query 向量,并与缓存的 Key 和 Value 向量进行注意力计算。
并行服务(Parallel Serving) :采用数据并行、张量并行、流水线并行、序列并行、专家并行等不同的并行方式,让多个计算单元同时为模型服务,提高推理速度。
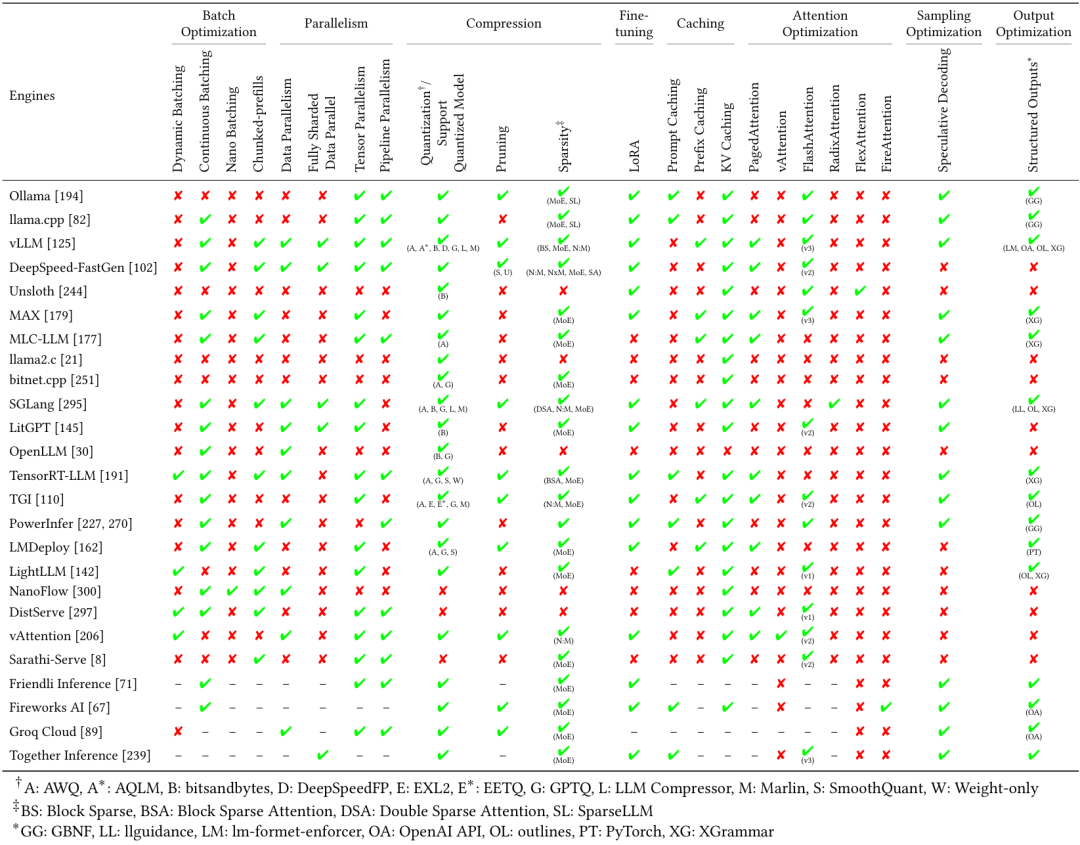
最后, 常见的大模型推理引擎使用的优化方法参考表:
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









