






昨天,阿里开源最新的编程模型:Qwen3-Coder,其性能在开源模型中达到了新的最先进水平。随模型一同开源的,还有一款面向智能体式编程的命令行工具:Qwen Code。Qwen Code 是基于 Gemini CLI 分支开发,其功能定位与 Gemini CLI 相同。Qwen Code 的发布,使得国内开发者可以便捷地使用先进的 AI 编程工具,进一步推动 AI 编程工具的平民化。
本文主要内容:
- Qwen3-Coder 模型介绍
- AI 编程工具 Qwen Code 安装与应用实测(与 Gemini 2.5 Pro 相比,Qwen3-Coder 的编程能力还是有一定的差距)
Qwen3-Coder 模型介绍
Qwen3-Coder:“Agentic Coding in the World”(在世界中自主编程)
官方文档:
- https://qwenlm.github.io/blog/qwen3-coder/
- https://github.com/QwenLM/Qwen3-Coder
- https://github.com/QwenLM/qwen-code
今天,我们正式发布 Qwen3-Coder,这是我们迄今为止最先进的智能体式代码模型。Qwen3-Coder 提供多种规模版本,但我们首先推出其中最强大的变体:Qwen3-Coder-480B-A35B-Instruct —— 一个拥有 4800 亿参数的混合专家(Mixture-of-Experts)模型,激活参数为 350 亿,能够在代码生成和智能体任务方面提供卓越的性能。Qwen3-Coder-480B-A35B-Instruct 在开源模型中于智能体编程、智能体浏览器使用和智能体工具使用等任务上树立了新的最先进水平,性能可与 Claude Sonnet 相媲美。

随模型一同开源的,还有一款面向智能体式编程的命令行工具:Qwen Code。该工具基于 Gemini Code 分支开发,通过定制化提示词与函数调用协议,充分释放 Qwen3-Coder 在智能体编程任务中的潜力。Qwen3-Coder 可与社区顶尖开发者工具无缝协作。作为基础模型,我们期待它能在数字世界的任何场景中被使用——在世界中实现智能体式编程!
- 模型定位 :目前最先进的智能体式编程(Agentic Coding)模型,支持代码生成、浏览器交互、工具调用等复杂任务。
- 核心参数:
- Qwen3-Coder-480B-A35B-Instruct :4800亿参数的混合专家(MoE)模型,激活参数350亿。
- 📚上下文长度:原生支持256K token,通过YaRN技术扩展至100万token,适用于超大规模代码仓库和动态数据(如Pull Requests)。
- 💻性能表现:
- 在开源模型中,智能体编程、浏览器使用、工具调用等任务上达到SOTA(与Claude Sonnet 4相当)。
预训练策略
- 扩展数据量 :预训练数据达7.5万亿token,其中70%为代码数据,兼顾代码能力与通用数学能力。
- 长上下文优化 :针对仓库级代码和动态数据优化,赋能智能体式编程。
- 合成数据质量提升 :利用Qwen2.5-Coder清理和重写噪声数据,显著提升数据质量。
后训练与强化学习
- 代码强化学习(Code RL) :
- 长周期强化学习(Long-Horizon RL):通过多轮交互(规划、调用工具、反馈、决策)解决真实软件工程任务(如SWE-Bench)。
- 大规模环境支持:基于阿里云基础设施构建可并行运行20,000个独立环境的系统,支持大规模强化学习训练。
- 成果:在SWE-Bench Verified任务上达到开源模型SOTA,且无需测试时扩展。
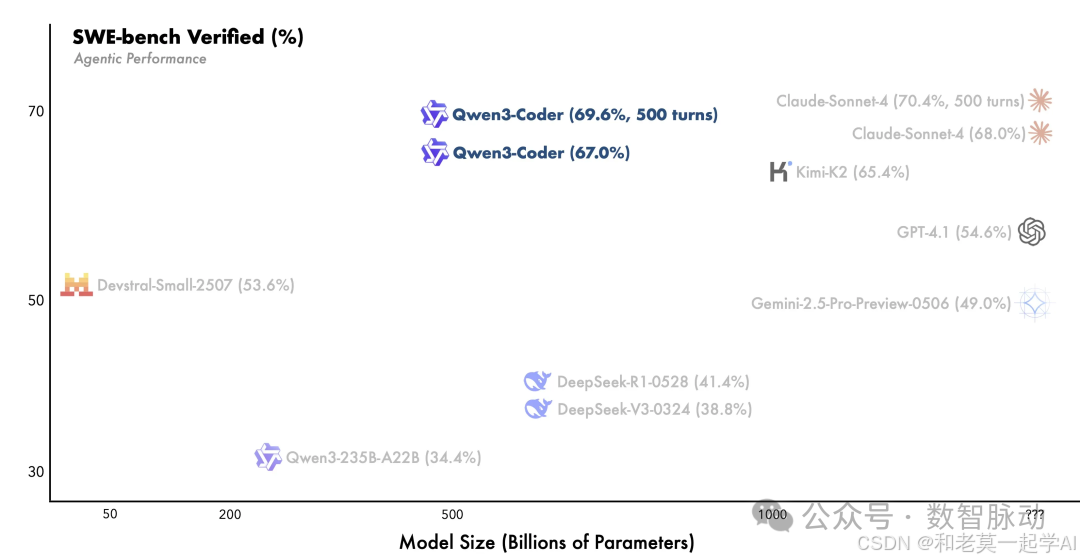
模型使用方式
- Qwen Code:基于Gemini CLI改造的命令行工具,增强对Qwen3-Coder模型的解析和工具支持。
- Claude Code:通过配置代理 API 或自定义路由的方式,在 Claude Code 里调用Qwen3-Coder
- Cline:选择“OpenAI Compatible”接口,填写DashScope提供的API Key和自定义URL,指定模型名称(如qwen3-coder-plus)。
- 官网页面:登录 https://chat.qwen.ai/,选择 Qwen3-Coder 模型。
Qwen Code 安装与应用实测
Qwen Code 是一款基于 Gemini CLI 改造的命令行 AI 工作流工具,专为 Qwen3-Coder 模型优化,提供增强的解析器支持与工具功能
主要功能
- 代码理解与编辑 - 突破传统上下文窗口限制,可查询和编辑超大规模代码库
- 工作流自动化 - 自动化处理拉取请求(Pull Requests)、复杂变基(Rebases)等操作任务
- 增强解析器 - 专为 Qwen-Coder 模型适配的解析器,实现深度优化 安装
1、安装 Node.js version 20
下载连接:https://nodejs.org/en/download,选择与操作系统匹配的版本下载,点击安装:
在终端分别输入: node -v 、npm -v ,验证是否已成功安装。

2、安装 Qwen Code
运行命令 npm install -g @qwen-code/qwen-code,安装 Qwen Code。
运行命令 qwen --version,查看是否成功安装
3、配置
官方文档介绍的配置方式:项目目录中创建 .qwen/.env 或 .env 文件(建议使用 .qwen/.env 文件,以隔离其他环境变量与其他工具的配置),设置以下信息(api key、url、model):
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="your_api_base_url_here"
export OPENAI_MODEL="your_api_model_here"
由于笔者使用 windows 系统,通过上述方式配置,使用 Qwen Code时环境变量并没有生效(希望后续版本可完善这个问题)。笔者在 cmd 窗口,在使用 Qwen Code 前,先输入以下命令,设置环境变量:
set OPENAI_API_KEY=your_api_key_here
set OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
set OPENAI_MODEL=qwen3-coder-plus
输入 qwen,启动 Qwen Code:
应用实测
1、网络搜索
- 今天上证指数行情是?
由于 Qwen Code 内置的网络搜索工具还是 google search,由于某些原因,网络不可用。
╭──────────────────────────╮
│ > 今天上证指数行情是? │
╰──────────────────────────╯
╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ ✔ GoogleSearch Searching the web for: "2025年7月23日 上证指数行情" │
│ │
│ Error performing web search. │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
✦ 抱歉,我无法获取到今天的上证指数行情。你可以尝试通过财经网站或应用查看最新的行情信息。
2、本地文件操作
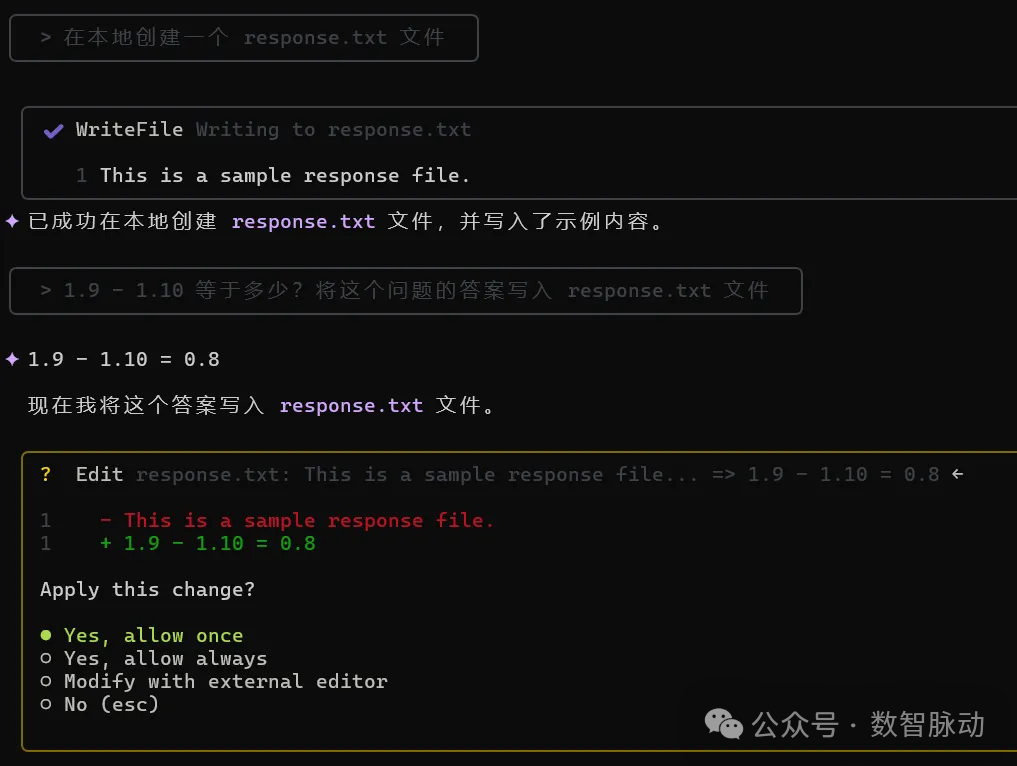
- 在本地创建一个 response.txt 文件
- 1.9 - 1.10 等于多少?将这个问题的答案写入 response.txt 文件
╭──────────────────────────────────────╮
│ > 在本地创建一个 response.txt 文件 │
╰──────────────────────────────────────╯
╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ ✔ WriteFile Writing to response.txt │
│ │
│ 1 This is a sample response file. │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
✦ 已成功在本地创建 response.txt 文件,并写入了示例内容。
╭─────────────────────────────────────────────────────────────────╮
│ > 1.9 - 1.10 等于多少?将这个问题的答案写入 response.txt 文件 │
╰─────────────────────────────────────────────────────────────────╯
✦ 1.9 - 1.10 = 0.8
现在我将这个答案写入 response.txt 文件。
╭─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ ✔ Edit response.txt: This is a sample response file... => 1.9 - 1.10 = 0.8 │
│ │
│ 1 - This is a sample response file. │
│ 1 + 1.9 - 1.10 = 0.8 │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
✦ 已成功将答案 "1.9 - 1.10 = 0.8" 写入 response.txt 文件。
╭────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ > Type your message or @path/to/file │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
3、代码生成
让 qwen3-coder 编写代码,演示三体运动:
用 Canvas 模拟三体运动:
1. 加载三个不同颜色的星球图片(100px×100px)
2. 初始位置可拖动,点击"Start"后按万有引力定律运动
3. 实时绘制每个星球的加速度和速度向量
4. 提供"Reset"按钮复位星球,滑动条调节模拟速度
5. 星球质量差异显著(如 1:3:9)
以下是 qwen3-coder 生成的页面效果。经过几次测试和问题反馈,三个星球还是不会动(效果不达预期):

测试了几个例子后,已使用了 9 w 多 tokens。虽然阿里云提供了 100w tokens 的免费额度,但这免费额度显然是不够用的。因此,使用时需注意模型调用费用。
同样的提示词,使用 gemini-cli(gemini-2.5 pro),一次即可生成以下三体运动效果(点击 start,三个星球可运动):
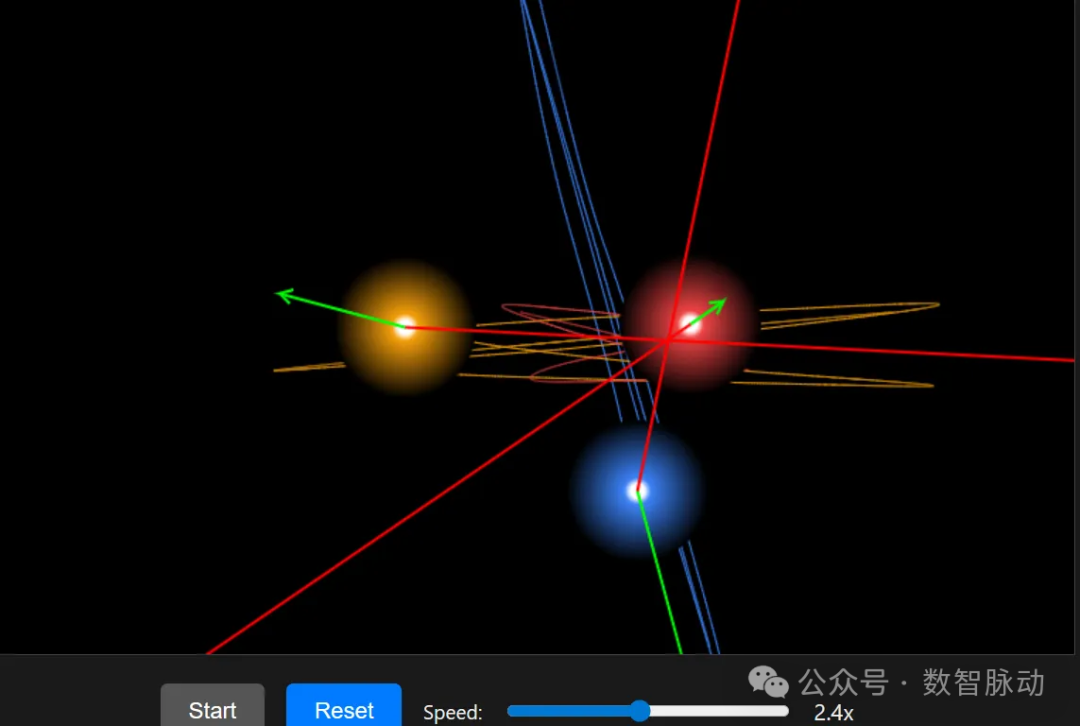
从上面的例子可见,在编程能力上,与 Gemini 2.5 Pro 相比,Qwen3-Coder 的编程能力还是有一定的差距。
尽管与闭源的 Gemini 2.5 Pro 在部分编程能力上存在差距,Qwen3-Coder 作为开源模型,使得开源模型的编程能力达到更高的水平,推动了 AI 编程技术的平民化。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









