






导语:ICML 国际机器学习大会(International Conference on Machine Learning,简称 ICML)是机器学习领域最重要和最有影响力的学术会议之一。《Ditto: Quantization-aware Secure Inference of Transformers upon MPC(量化感知的 Transformer 模型密态推理)》,在本次投稿中的 9,473 篇有效论文且接收率为27.5%中脱颖而出,顺利中选。本文将详细解读该论文提出的具体技术原理与实现。
Ditto 是针对大模型密态推理场景展开的一个研究工作:
“Ditto can transform to different quantization settings.”
该论文基于 Secretflow-SPU 框架实现了量化感知的 Transformer 模型密态推理,基于安全多方计算技术对大模型推理中的模型参数以及用户输入提供可证安全保护。本文在先前隐语和蚂蚁技术研究院合作的工作 PUMA 基础之上,受到明文场景中常用的量化技术的启发,Ditto 尝试将不同精度的量化运算应用在密态计算领域。然而,由于 cost model 的不同,简单地套用明文量化并不能带来显著的性能提升,甚至是负收益。
针对此问题,Ditto 采用了 layer-wise 静态对偶量化方案,设计并实现了量化感知的编译器,能够自动地根据前端数据类型,执行不同精度的后端密态运算。此外,为了支持密态计算下的数据类型切换,Ditto 提出了新的安全多方计算协议实现相关算子,能够以更高的效率实现密态数据类型的切换,进而带来更优的密态推理性能。
一、背景
近年来,预训练的 Transformer 模型技术在视觉识别和自然语言处理等领域的飞速发展,促使它们在机器学习(ML)推理服务中的广泛应用。随着其研究热度不断上升,涉及到的数据安全问题更是一个主要关注点。以 ChatGPT 为例,在基于大模型的在线服务中,模型所有者提供的 API 接收用户提示(Prompt)作为输入并生成相应的回答,作为输出返回给用户。在这一过程需要将用户输入以明文形式发送到服务器,就存在泄露用户敏感信息的风险。一种可行的解决方法是采用密码学的安全多方计算(MPC)对输入进行加密,提供可证安全。
然而,MPC 技术会引入巨大的计算和通信开销,阻碍了基于 MPC 的 Transformer 安全推理的应用。这其中主要有如下几个瓶颈:
-
非线性函数(如 GeLU)被频繁调用,但它们在 MPC 中计算代价高昂。
-
通常,Transformer 模型包含数百万到数十亿个参数,由于 Transformer 模型的规模巨大,这些开销在 Transformer 中被放大。
针对前一个问题,可以参考相关工作[1][2][3][4],这些研究用对 MPC 更友好的近似函数替代了这些非线性函数。针对后一个问题,已有的一些在明文推理中的实践[5][6]通过量化模型为低位数并采用低位整数运算,从而加速了推理。
然而,明文量化无法简单地结合到 MPC 安全推理中。举例来说,对于 Transformers 中的一个线性层 ,其中,,,是批量大小,和是特征维度。
MPC 上的标准浮点矩阵乘法通常在统一的64位定点数上操作,表示为,而量化矩阵乘法表示为,其中的乘加运算是在32位整数上进行的,是一个量化参数,表示clip操作。如下图所示,在 MPC 中,虽然量化确实减少了位宽,从而降低了点积的通信量,但额外的步骤,如缩放和 clip 操作,会带来较大的额外开销,甚至超过了量化带来的性能提升。
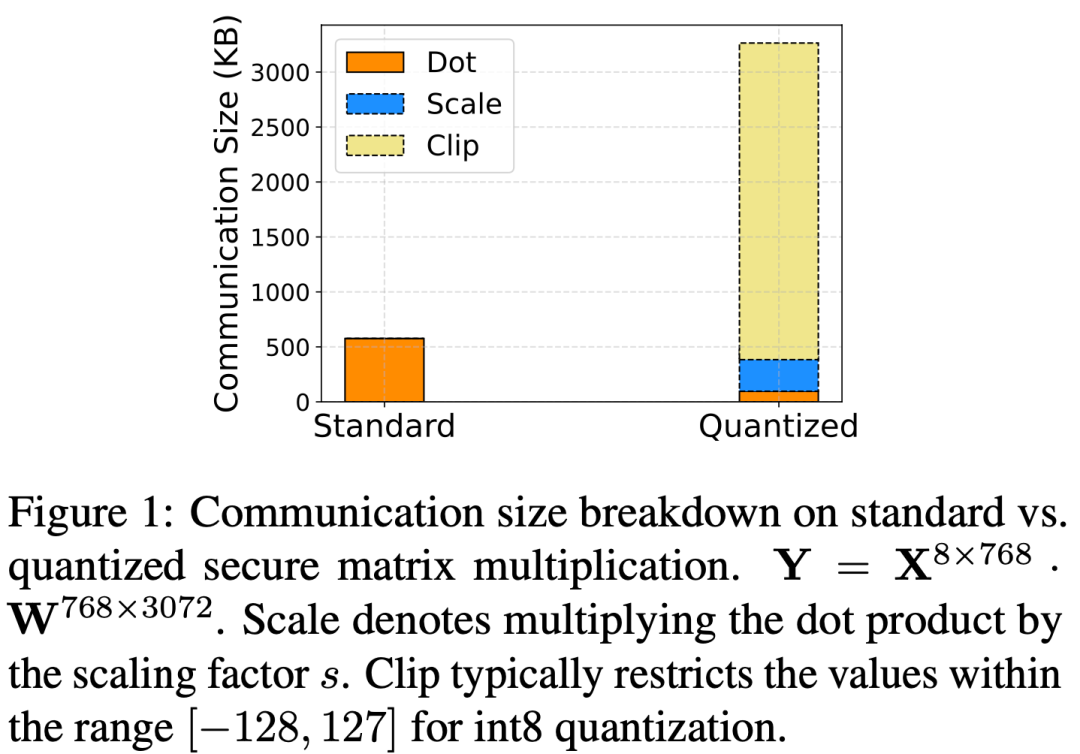
因此,机器学习(ML)和安全多方计算(MPC)两个领域之间存在 cross-domain gaps:
-
机器学习专家主要专注于设计精细的量化方法以提高效率,但这些方法可能并不适用于 MPC。在明文量化中,涉及缩放和 clip 操作的数据类型转换(比如和之间的转换)在 MPC 中并不是可以本地直接执行的简单操作。此外,直接应用量化可能会导致显著的模型精度下降。
-
MPC 专家主要专注于构建高效的底层密码学算法原语,可能并未注意到结合 ML 的视角,使用混合精度量化来提升端到端的安全推理效率。
那么,是否能在不影响模型表现的情况下进行量化感知的高效安全推理呢?
为解决上述问题,我们提出了 Ditto,主要提出以下几个技术方案:
-
MPC 友好的量化机制:提出引入 layer-wise static dyadic quantization(即 layer-wise 定点表示),以避免 CPU 上便宜但在 MPC 中代价高昂的动态量化操作,如 clip 操作。通过按层设置不同量化精度,所需的整体位宽减少,从而降低安全推理的总体开销。
-
量化感知的模型蒸馏:利用知识蒸馏对训练好的模型进行量化感知的蒸馏,以对齐安全推理中的行为,保证模型的精度。
-
量化感知的安全推理框架:据我们所知,Ditto 是第一个支持量化的安全推理框架。具体来说,逐层量化计算会自动映射到不同数据类型(在 MPC 中则是不同大小的环)上的安全计算。为此,我们提出了优化的 MPC 原语,支持高效的类型转换。
-
性能评估:我们在经典 Transformer 模型(Bert 和 GPT2)上评估了 Ditto 执行安全推理的表现。性能从两个指标进行评估:模型精度和效率。实验结果表明,在不显著降低模型精度的情况下可以实现效率提升。与先前的工作相比, Ditto 的速度比 MPCFormer[2] 快3.14 ∼ 4.40倍,比 PUMA[7] 快1.44 ∼ 2.35倍。
接下来,我们详细给出 Ditto 的核心设计与实现。
二、核心设计与实现
1.场景设置 & 安全模型
在此工作中,我们考虑大模型推理场景,其中模型所有者提供训练好的模型,客户端提供推理任务的输入数据。推理计算可以表述为,其中表示模型的参数。
安全目标在于参数和输入数据对除了持有方以外的参与方以及潜在攻击者MPCFormer[2], PUMA[7])类似,我们考虑三方安全外包计算场景。也就是说,我们将模型推理外包给由三个计算方组成的 MPC 系统(模型提供方、客户端也可以充当计算方的角色)。客户端使用 Replicated Secret Sharing(RSS[8])加密并将这些份额发送给相应的计算方。同样,模型所有者加密模型参数并发送给。计算方随后执行安全推理,并获得结果,接着把的所有份额发送给客户端,客户端可以解密得到的明文。
在上述场景中,我们考虑半诚实和诚实多数敌手模型。其中不超过一半的计算方可能勾结,并且各个计算方严格遵循协议执行计算,但可能试图通过分析他们接收的消息来窃取敏感信息。
2.整体流程
考虑上述场景以及安全模型,Ditto 的架构如下图所示,核心是机器学习量化和高效的 MPC 计算两者协同设计的两步方案:
-
第一步(图中左上部分):将模型量化并蒸馏为更 MPC 友好的版本。这一步由模型所有者在本地使用明文计算执行,包括对模型非线性部分的高效近似以及线性部分的 layer-wise 定点数量化。
-
第二步(图中底部部分):对从第一步中获得的 MPC 友好的模型进行量化感知的安全推理。我们设计了优化的 MPC 原语,以支持量化中的高效基本类型转换。此外,我们对 Secure Processing Unit(SPU)框架进行了改进,能够自动地根据前端定义的数据类型映射到对应的后端 MPC 环表示,并自动添加密态数据类型转换算子,支持不同参数量化计算的转换。
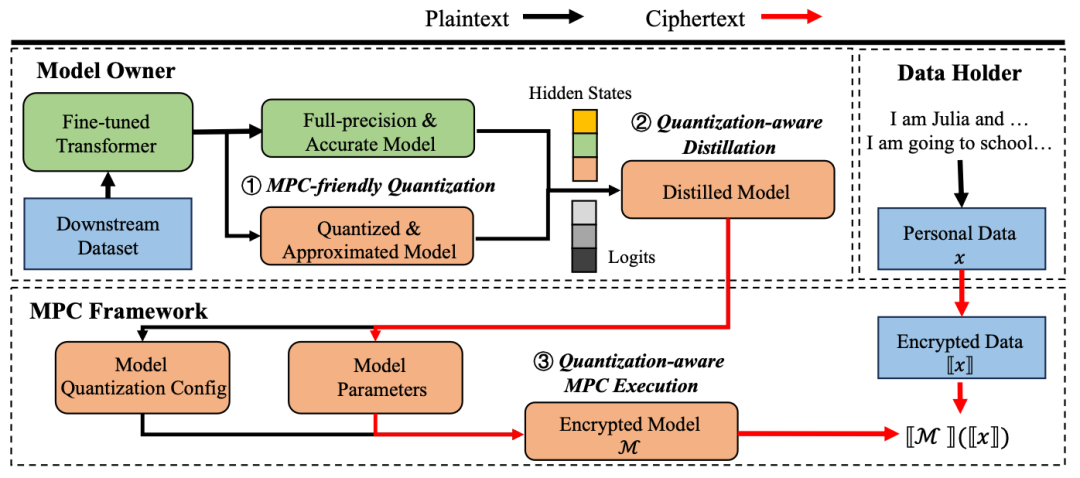
Ditto 整体框架
3.MPC 友好的模型
针对非线性比较运算在 MPC 下是主要的性能瓶颈这一观察,此部分的模型调整主要从三个角度进行:
-
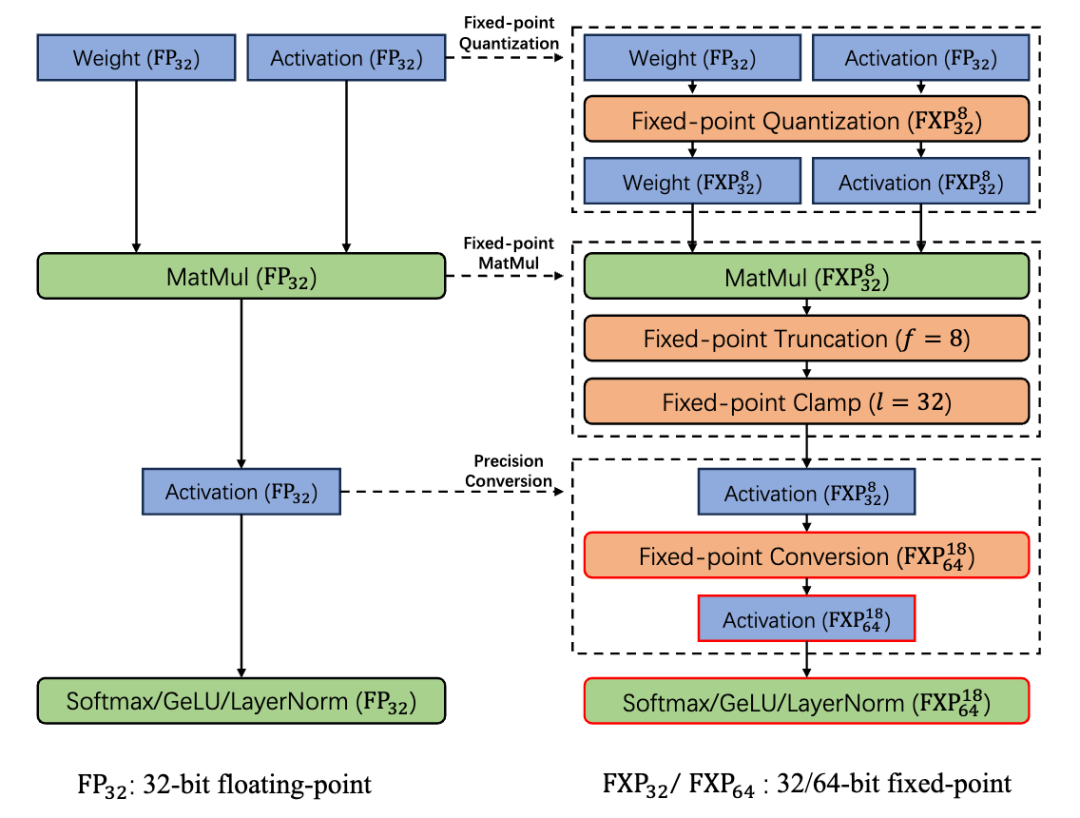
避免使用明文中的动态量化:不同于明文中将浮点数量化到 int8,甚至是 int2,int1。在 MPC 中,采用 32 位或 64 位的定点数来进行计算,对于可以量化到低精度的网络层(比如部分线性层),我们使用 32 位的定点数进行计算。不同于 int8,int32 可以提供较大的整数空间,因此可以极大程度上减少出现溢出的情况,进而可以避免执行 clip 操作。
-
尽量减少频繁的量化类型转换:明文的量化矩阵乘通常使用 int8 作为输入,中间计算结果 promote 到 int32 进行累加,这在 MPC 下存在一定开销,因此我们避免使用极致的量化表示来避免这部分输入输出的 type conversion。举例来说,对于模型的中间线性层,我们使用统一的 32 位定点数计算,避免频繁的层内类型转换。
-
非线性激活函数采用混合精度量化:考虑到部分非线性函数如 Softmax 函数是复合操作,可以拆解为多个子运算,对于 Softmax 的第一步 normalize 输入的子运算,其涉及到比较计算,相对大小关系不会受到精度太大影响,因此可以针对其使用较小位宽的定点数执行,减少整体的开销。
在执行了上述几步的模型改动之后,为了对齐模型表现,我们引入知识蒸馏。如下图所示,模型的前向传播从左边的浮点运算,改造为右边定点数运算逻辑,实现 layer-wise 的量化,同时针对权重 weight 和激活值 activation。采用了经典的蒸馏方法,对齐左右两个模型的 layer-wise 输出以及最后一层输出,确保量化模型的精度。
4. 基于 SPU 的量化感知 MPC 推理
在得到上述量化模型之后,MPC 侧还需要有两个卡点问题解决:
-
高效的量化类型转换协议
-
编译器自动翻译动态量化类型
针对第一点,我们在论文中给出了详细的 MPC 协议,以及正确性和安全性的推导,感兴趣的同学推荐看下原文,这里就不展开赘述了。
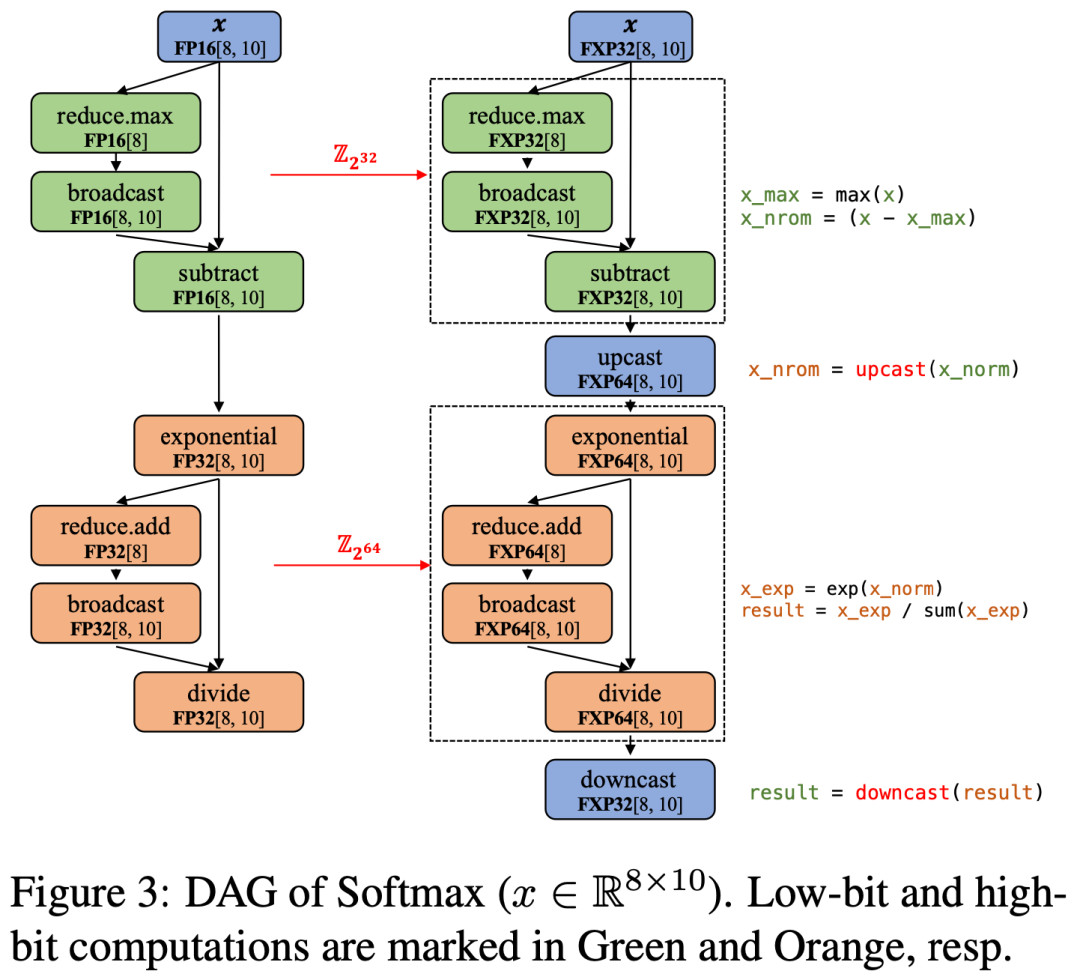
针对第二点,得益于底层的 Secretflow-SPU 框架[9] ,Ditto 能够轻松地从 Huggingface 导入训练好的模型,无缝地由明文推理切换到安全推理。此外,能够将前端的数据类型透传到后端 MPC 协议测。基于此,我们定义了一个前端数据类型和后端 MPC 定点数的映射,如 16 位浮点数对应 32 位定点数,32 位浮点数对应 64 位定点数。SPU 会自动地根据前端类型翻译程序,并采用不同大小的环来执行后端 MPC 计算。此外,在涉及到不同大小的环转换时,会自动调用第一步中的优化的 MPC 类型转换协议,从而打通整体链路,实现量化感知的 MPC 推理。
如下图所示,以 Softmax 函数计算为例,左侧为前端定义的浮点数计算图,Ditto 将其翻译成右侧的定点数计算图,根据前端数据类型,使用不同的定点数表示,比如使用 32 位定点数计算 ,接着使用 64 位定点数计算后续和除法运算,这中间 Ditto 自动调用密态类型转换算子(此例子中为从 FXP32 到 FXP64 的 up cast)进行桥接。
三、实验结果
论文中的实验在一台配备有一个 AMD Ryzen CPU(32核,3.60GHz)和 256GB RAM 的 CentOS 8 机器上进行。我们考虑了两种网络环境:
1)局域网设置,带宽为 5Gbps,RTT 为 0.4ms;
2)广域网设置,带宽为 400Mbps,RTT 为 40ms。
我们使用 Linux 的 tc 工具来模拟上述网络环境。主要的实验指标为:模型精度、模型推理效率和一些扩展性实验。我们选取了 Bert-{base, large} 和 GPT2-{base, medium} 作为实验模型,针对 Bert 测试了在 RTE,CoLA,QQP 和 QNLI 数据集上的表现,针对 GPT2 上测试了在 Wikitext-103 数据集上的 perplexity。
下图分别为模型精度以及模型推理效率的实验结果,看到 Ditto 可以在不显著降低模型可用性的情况下实现密态推理效率的提升,效率相较最新工作提升约 2~4 倍。
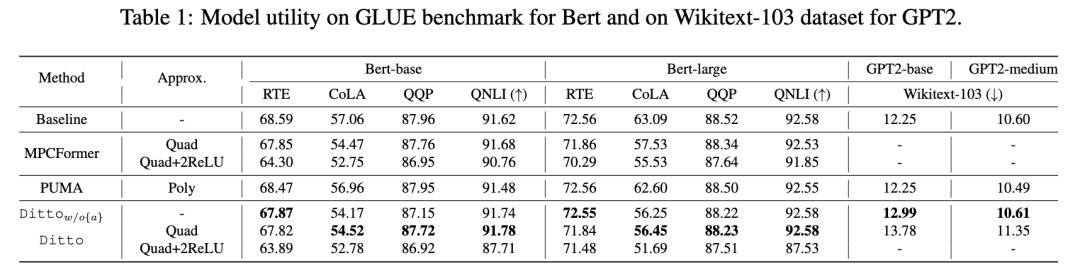
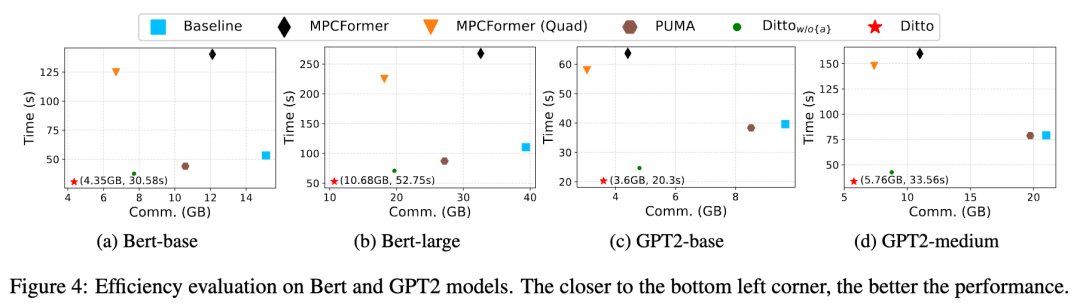
更多详细数据可以查看论文原文,以了解更多细节。
四、结论
在本论文中,我们提出了 Ditto,通过结合 MPC 友好的机器学习量化机制和量化感知的 MPC 编译器执行,针对大模型的安全推理,Ditto 减少了整体的通信开销,提高了推理的效率,同时能够保证模型的精度不受太大影响。目前本文的相关代码正在整理中,预计在 SPU 的 GitHub 仓库中开源一个 PoC 分支,相关能力后续将持续集成到 SPU 框架中,敬请期待。
学习文档:欢迎参考《SPU二次开发指北》进行尝试:
https://github.com/secretflow/spu/blob/main/docs/SPU_gudience.pdf
SPU GitHub 指路:
https://github.com/secretflow/spu
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 115
115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









