






前言
在这篇文章中,围绕检索召回(Retrieval),风叔详细介绍如何优化RAG系统的召回结果,提升LLM大模型的回答准确度。

在检索召回的时候,用户的问题会被输入到嵌入模型中进行向量化处理,然后系统会在向量数据库中,搜索与该问题向量语义上相似的知识文本或历史对话记录并返回。
在Naive Rag中,系统会将所有检索到的块直接输入到 LLM生成回答,导致出现中间内容丢失、噪声占比过高、上下文长度限制等问题。
下面,我们结合源代码,详细介绍下Reranking(重排序)、Refinement(压缩)和Corrective Rag(纠正性Rag)这三种优化召回准确率的方案。
具体的源代码地址可以在文末获取。
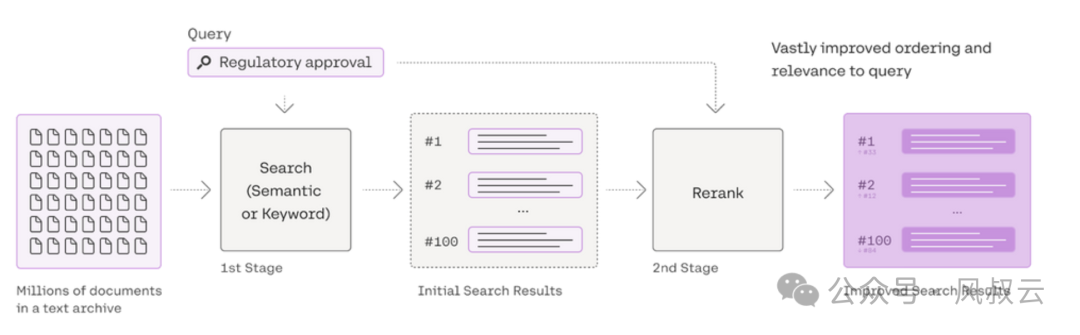
1. Rerank(重排序)
重排序,顾名思义,就是将检索召回的结果,按照一定的规则或逻辑重新排序,从而将相关性或准确度更高的结果排在前面,提升检索质量。
重排序主要有两种类型,基于统计打分的重排序和基于深度学习的重排序。
基于统计的重排序会汇总多个来源的候选结果列表,使用多路召回的加权得分或倒数排名融合(RRF)算法来为所有结果重新算分。这种方法的优势是计算简单,成本低效率高,广泛用于对延迟较敏感的传统检索系统中,比如内部知识库检索、电商智能客服检索等。
RAG Fusion 中的 reciprocal_rank_fusion 就是一种基于统计打分的重排序,我们再来回顾一下,如以下代码所示:
def reciprocal_rank_fusion(results: list[list], k=60):` `""" Reciprocal_rank_fusion that takes multiple lists of ranked documents`` and an optional parameter k used in the RRF formula """`` ` `# Initialize a dictionary to hold fused scores for each unique document` `fused_scores = {}`` ` `# Iterate through each list of ranked documents` `for docs in results:` `# Iterate through each document in the list, with its rank (position in the list)` `for rank, doc in enumerate(docs):` `# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)` `doc_str = dumps(doc)` `# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0` `if doc_str not in fused_scores:` `fused_scores[doc_str] = 0` `# Retrieve the current score of the document, if any` `previous_score = fused_scores[doc_str]` `# Update the score of the document using the RRF formula: 1 / (rank + k)` `fused_scores[doc_str] += 1 / (rank + k)`` ` `# Sort the documents based on their fused scores in descending order to get the final reranked results` `reranked_results = [` `(loads(doc), score)` `for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)` `]`` ` `# Return the reranked results as a list of tuples, each containing the document and its fused score` `return reranked_results
基于深度学习模型的重排序,通常被称为 Cross-encoder Reranker,经过特殊训练的神经网络可以更好地分析问题和文档之间的相关性。这类 重排序可以给问题和文档之间的语义相似度进行打分,打分只取决于问题和文档的文本内容,不取决于文档在召回结果中的位置。这种方法的优点是检索准确度更高,但成本更高,响应时间更慢,比较适合于对检索精度要求极高的场景,比如医疗问诊。
我们也可以使用大名鼎鼎的Cohere进行重排,一个非常优秀的开源工具,支持多种重排序策略。
其使用方法也非常简单,如以下代码所示:
from langchain_community.llms import Cohere``from langchain.retrievers import ContextualCompressionRetriever``from langchain.retrievers.document_compressors import CohereRerank``from langchain.retrievers.document_compressors import CohereRerank`` ``retriever = vectorstore.as_retriever(search_kwargs={"k": 10})`` ``# Re-rank``compressor = CohereRerank()``compression_retriever = ContextualCompressionRetriever(` `base_compressor=compressor, base_retriever=retriever``)`` ``compressed_docs = compression_retriever.get_relevant_documents(question)
2. Refinement(压缩)
压缩,即对于检索到的内容块,不要直接输入大模型,而是先删除无关内容并突出重要上下文,从而减少整体提示长度,降低冗余信息对大模型的干扰。
langchain中有一个基础的上下文压缩检索器可以使用,叫做ContextualCompressionRetriever。
from langchain.retrievers import ContextualCompressionRetriever``from langchain.retrievers.document_compressors import LLMChainExtractor``from langchain_openai import OpenAI`` ``llm = OpenAI(temperature=0)``compressor = LLMChainExtractor.from_llm(llm)``compression_retriever = ContextualCompressionRetriever(` `base_compressor=compressor, base_retriever=retriever``)`` ``compressed_docs = compression_retriever.invoke(` `"What did the president say about Ketanji Jackson Brown"``)
LLMChainFilter是一个稍微简单但更强大的压缩器,它使用 LLM 链来决定过滤掉哪些最初检索到的文档以及返回哪些文档,而无需操作文档内容
from langchain.retrievers.document_compressors import LLMChainFilter`` ``_filter = LLMChainFilter.from_llm(llm)``compression_retriever = ContextualCompressionRetriever(` `base_compressor=_filter, base_retriever=retriever``)`` ``compressed_docs = compression_retriever.invoke(` `"What did the president say about Ketanji Jackson Brown"``)``pretty_print_docs(compressed_docs)
3. Corrective Rag(纠错性Rag)
Corrective-RAG (CRAG) 是一种 RAG 策略,它结合了对检索到的文档进行自我反思/自我评分。
CRAG 增强生成的方式是使用轻量级的“检索评估器”,该评估器为每个检索到的文档返回一个置信度分数,然后该分数决定触发哪种检索操作。例如评估器可以根据置信度分数将检索到的文档标记为三个桶中的一个:正确、模糊、不正确。
如果所有检索到的文档的置信度分数均低于阈值,则假定检索“不正确”。这会触发采取新的知识来源(例如网络搜索)的行动,以实现生成的质量。
如果至少有一个检索到的文档的置信度分数高于阈值,则假定检索“正确”,这会触发对检索到的文档进行知识细化的方法。知识细化包括将文档分割成“知识条”,然后根据相关性对每个条目进行评分,最相关的条目被重新组合为生成的内部知识。

所以,Corrective Rag的关键在于”检索评估器“的设计,以下是一个实现检索评估器的示例:
from langchain_core.prompts import ChatPromptTemplate``from langchain_core.pydantic_v1 import BaseModel, Field``from langchain_openai import ChatOpenAI`` ``# Data model``class GradeDocuments(BaseModel):` `"""Binary score for relevance check on retrieved documents."""`` ` `binary_score: str = Field(` `description="Documents are relevant to the question, 'yes' or 'no'"` `)`` ``# LLM with function call``llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)``structured_llm_grader = llm.with_structured_output(GradeDocuments)`` ``# Prompt``system = """You are a grader assessing relevance of a retrieved document to a user question. \n `` If the document contains keyword(s) or semantic meaning related to the question, grade it as relevant. \n` `Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""`` ``grade_prompt = ChatPromptTemplate.from_messages(` `[` `("system", system),` `("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),` `]``)`` ``retrieval_grader = grade_prompt | structured_llm_grader``question = "agent memory"``docs = retriever.get_relevant_documents(question)``doc_txt = docs[1].page_content``print(retrieval_grader.invoke({"question": question, "document": doc_txt}))
但是,Corrective Rag的局限性是严重依赖于检索评估器的质量,并容易受到网络搜索引入的偏见的影响,因此微调检索评估器可能是不可避免的。
到这里,三种有效优化检索召回的方法就介绍完了。关注【风叔云】公众号,回复关键词“检索优化”,获取完整的源代码。
总结
在这篇文章中,风叔详细介绍了优化Retrival(检索召回)的三种方法,包括Rerank(重排序)、RefineMent(压缩)、Corrective Rag(纠错性Rag)。
检索召回的下一步是最终内容生成,即使使用了上述检索召回的优化方案,最终生成环节也可能遇到格式错误、内容不完整、政治不正确等问题。因此,在生成环节,我们也需要相应的优化方案,给整个RAG流程画上完美的句号。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤AI+零售:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥AI+交通:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
 加粗样式
加粗样式















 3284
3284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









