







引言
知识问答系统(KQA)是自然语言处理领域的核心技术之一,它能够帮助用户从大量数据中快速准确地检索到所需信息。知识问答系统成为了帮助个人和企业快速获取、筛选和处理信息的重要工具。它们在很多领域都发挥着重要作用,例如在线客服、智能助手、数据分析和决策支持等。
Langchain不仅提供了构建基本问答系统的必要模块,还支持更为复杂和高级的问答场景。例如,它可以处理结构化数据和代码,使得我们能够针对数据库或代码库进行问答。这极大地扩展了知识问答系统的应用范围,使其能够适应更多复杂的实际需求。本篇文章将通过一个简单的实战例子,介绍如何使用Langchain构建基本的知识问答系统。
①人工智能/大模型学习路线
②AI产品经理入门指南
③大模型方向必读书籍PDF版
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧AGI大模型技术公开课名额
实战
下面,我们将通过实战例子手把手介绍如何使用Langchain搭建知识问答系统。
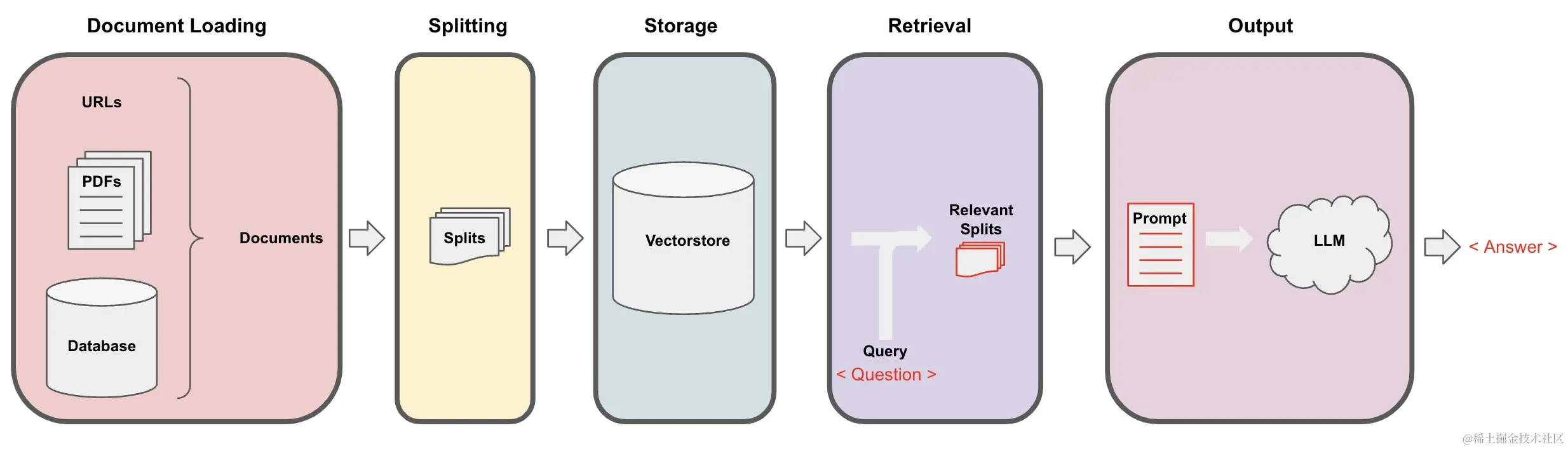
1. 文档加载和预处理
构建知识问答系统的第一步是加载和预处理文档。Langchain提供了WebBaseLoader模块,可以帮助我们轻松加载文档:
from langchain.document_loaders import WebBaseLoader
# 加载文档
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
documents = loader.load()
加载文档后,我们需要对文档进行预处理,以便后续处理。RecursiveCharacterTextSplitter模块可以帮助我们将文档切割成小块,便于处理:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 文档切割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
2. 文本嵌入
文本嵌入是将文本转换为向量的过程,它是自然语言处理的基础。Langchain提供了OpenAIEmbeddings模块,可以帮助我们快速实现文本嵌入:
from langchain.embeddings import OpenAIEmbeddings
# 创建嵌入
embeddings = OpenAIEmbeddings()
3. 构建向量存储库
向量存储库是存储文档嵌入的地方。通过Chroma模块,我们可以方便地创建和管理向量存储库:
from langchain.vectorstores import Chroma
# 构建向量存储库
docsearch = Chroma.from_documents(texts, embeddings)
4. 构建检索QA链
检索QA链是知识问答系统的核心,它负责处理用户的查询,并从向量存储库中检索相关文档:
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 构建检索QA链
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
5. 查询执行和结果获取
最后,我们可以执行用户的查询,并从系统中获取答案:
# 执行查询
query = "What is Task Decomposition?"
answer = qa.run(query)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}