







文章目录
链接
论文:https://arxiv.org/abs/2407.15795
代码:https://github.com/caoyunkang/AdaCLIP
模型
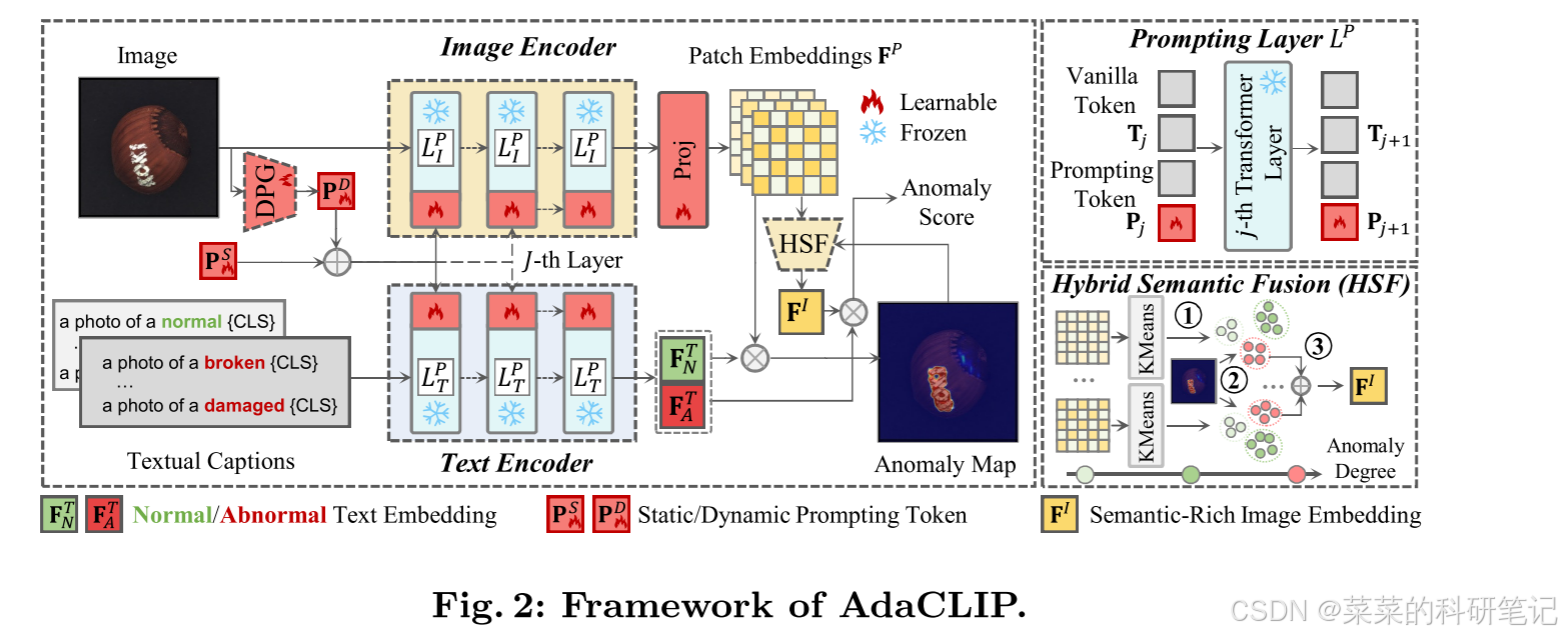
- 文中提出将可学习的提示合并到CLIP中,通过辅助的异常检测数据的训练来优化
- 提出两种类型的可学习提示,分别是动态可学习提示和静态可学习提示,静态和动态提示组合称为混合提示
- 开发了混合语义融合模块来提取有关异常区域的区域级上下文,增强图像级异常检测性能
提示层 prompting layers
AdaCLIP在图像和文本编码器的提示层合并可学习参数,取代原始的图像和文本编码器中的transformer层,增强了预训练的CLIP。
提示层保留原始transformer的权重,然后将可学习的提示token连接到输入图像或输入文本产生的普通token,只连接到前J个层中,而其余层通过前馈过程生成
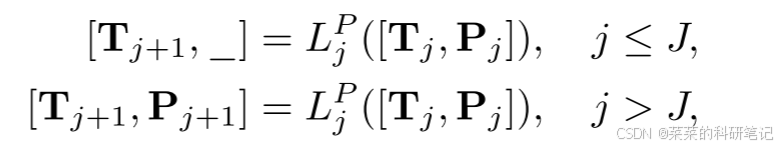
代码位于promptLayer类
混合可学习提示 hybrid Learnable prompts
静态可学习提示和动态科学系提示组合称为混合可学习提示,静态提示在所有图像之间共享,用于初步适应零样本异常检测;动态提示则根据每张测试图像生成动态提示。
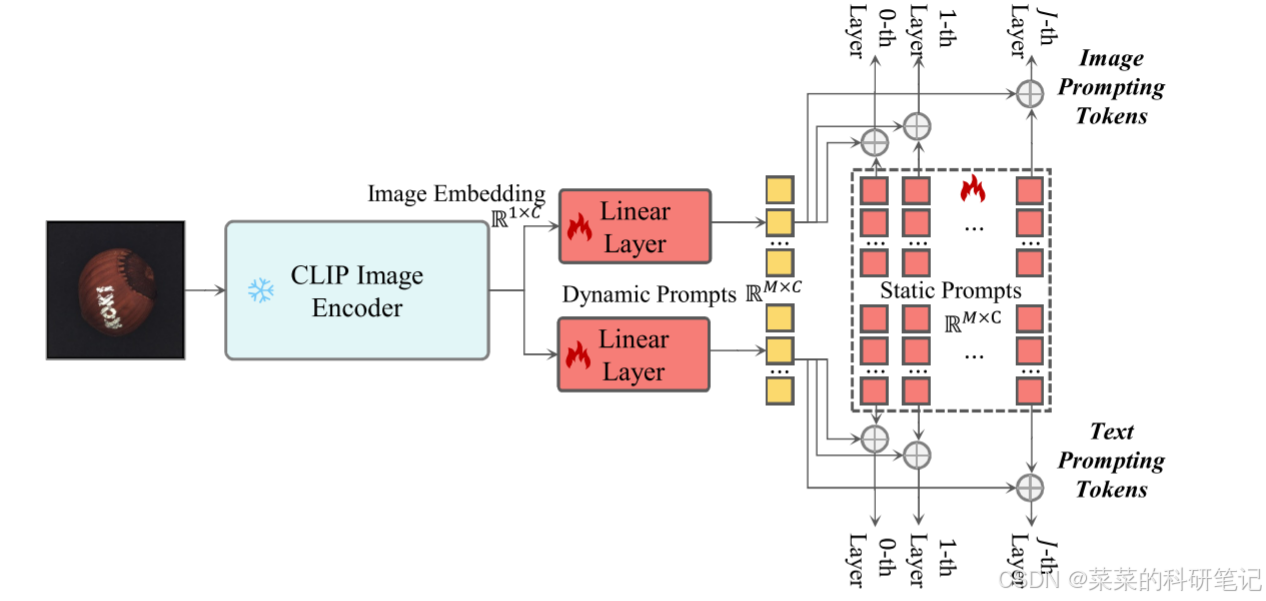
动态提示:首先将测试图像通过CLIP图像解码器,然后分别通过线性层生成文本和图像编码器的动态提示
动态提示和静态提示结合起来得到混合可学习提示
代码位于AdaCLIP类和promptLayer类
投影层projection layer
将投影层附加到图像编码器,使得patch embedding和text embedding的尺寸对齐
通过引入带有偏差的线性层来对齐,并且还添加了一些用于CLIP自适应的可学习参数
代码实现位于ProjectLayer类
混合语义融合模块hybrid semantic fusion modele
引入HSF模块来增强图像级异常检测的性能,避免传统选择最大值作为异常分数导致的噪声预测很敏感
HSF聚合更有可能表示异常的patch嵌入,称为语义丰富的嵌入
HSF的实现分为三步:
- 使用KMeans将簇patch 嵌入分为K组
- 对异常图M中相应位置的分数进行平均,计算各个簇的异常分数
- 选择异常分数最高的簇,计算质心,聚合成最终的语义丰富的图像嵌入
代码位于HybridSemanticFusion类
像素级异常检测实现
测量patch embedding和正常文本嵌入、异常文本嵌入的余弦相似度得出异常分数。与Win CLIP相同,定义第i层的异常图
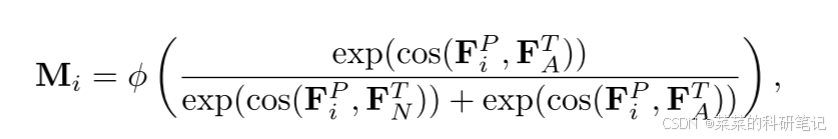
图像级异常检测实现
使用语义丰富的图像嵌入和文本嵌入计算余弦相似度,然后进行softmax归一化,使用焦点损失优化图像级异常分数
实验
在辅助数据集上进行训练
使用mvtec作为训练集时,使用visa作为验证集,从验证集中选出最佳模型。
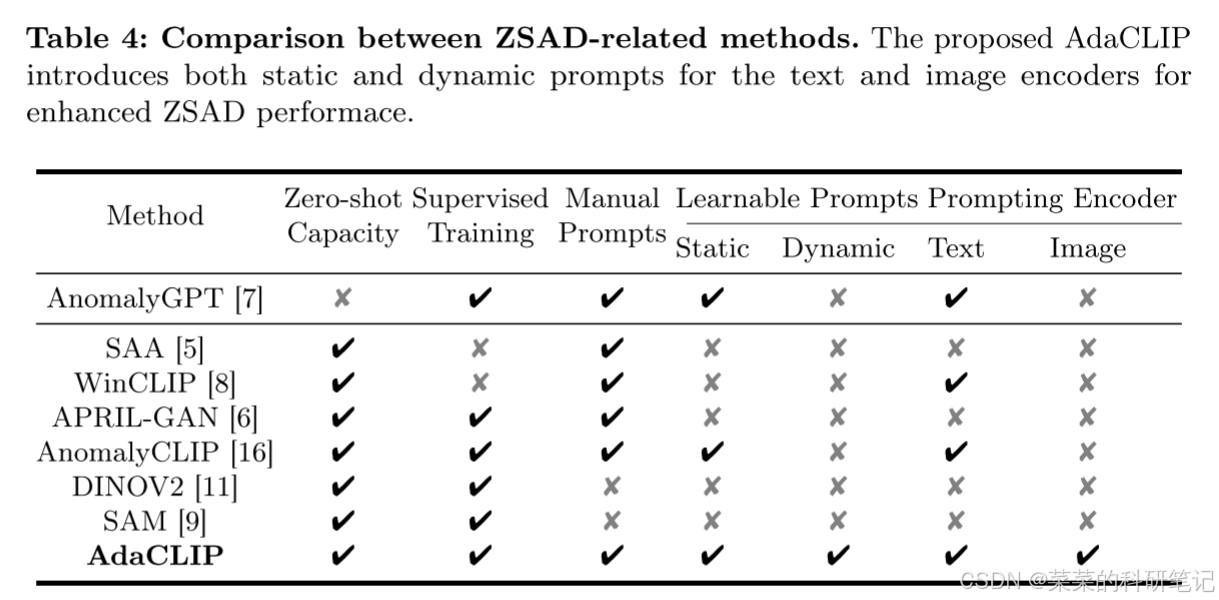
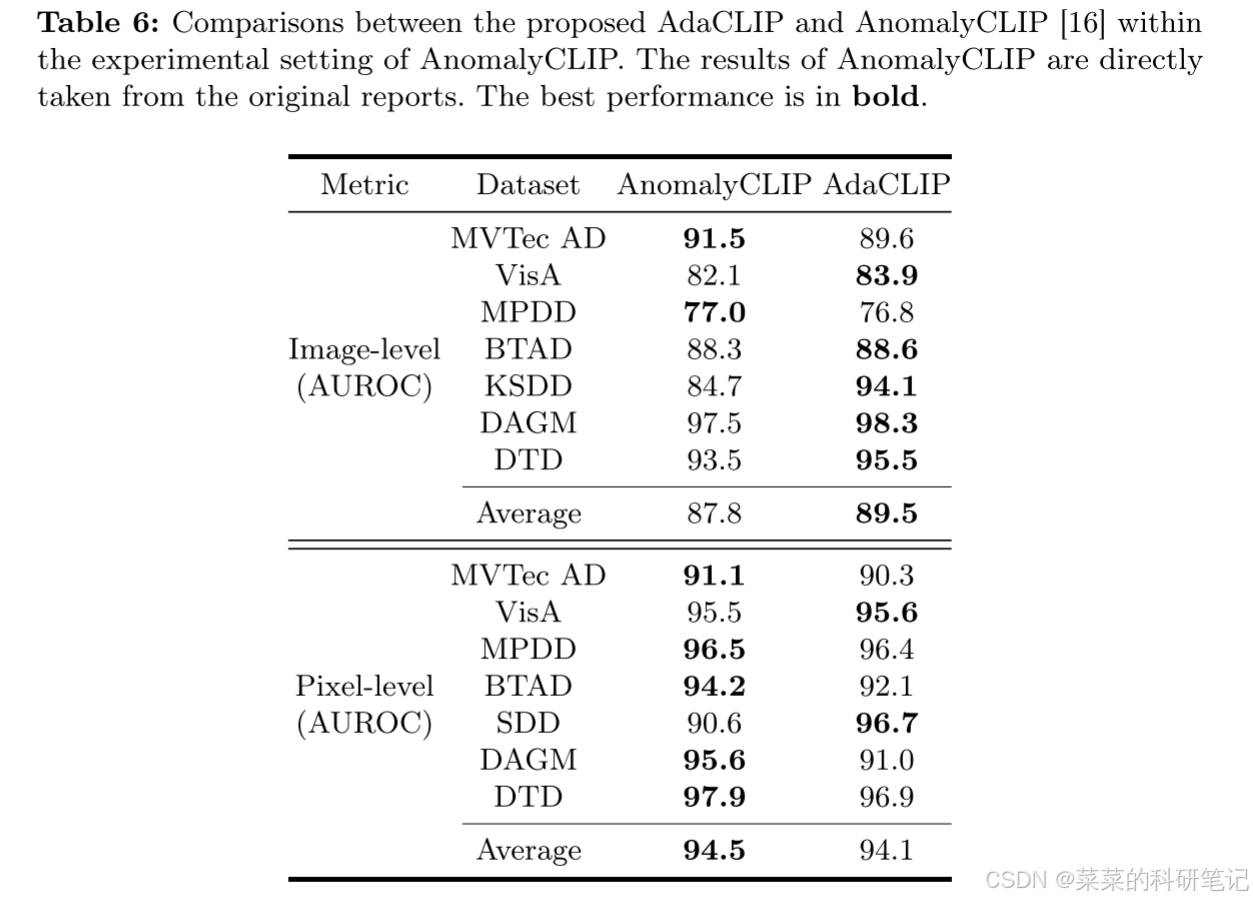
主要性能指标
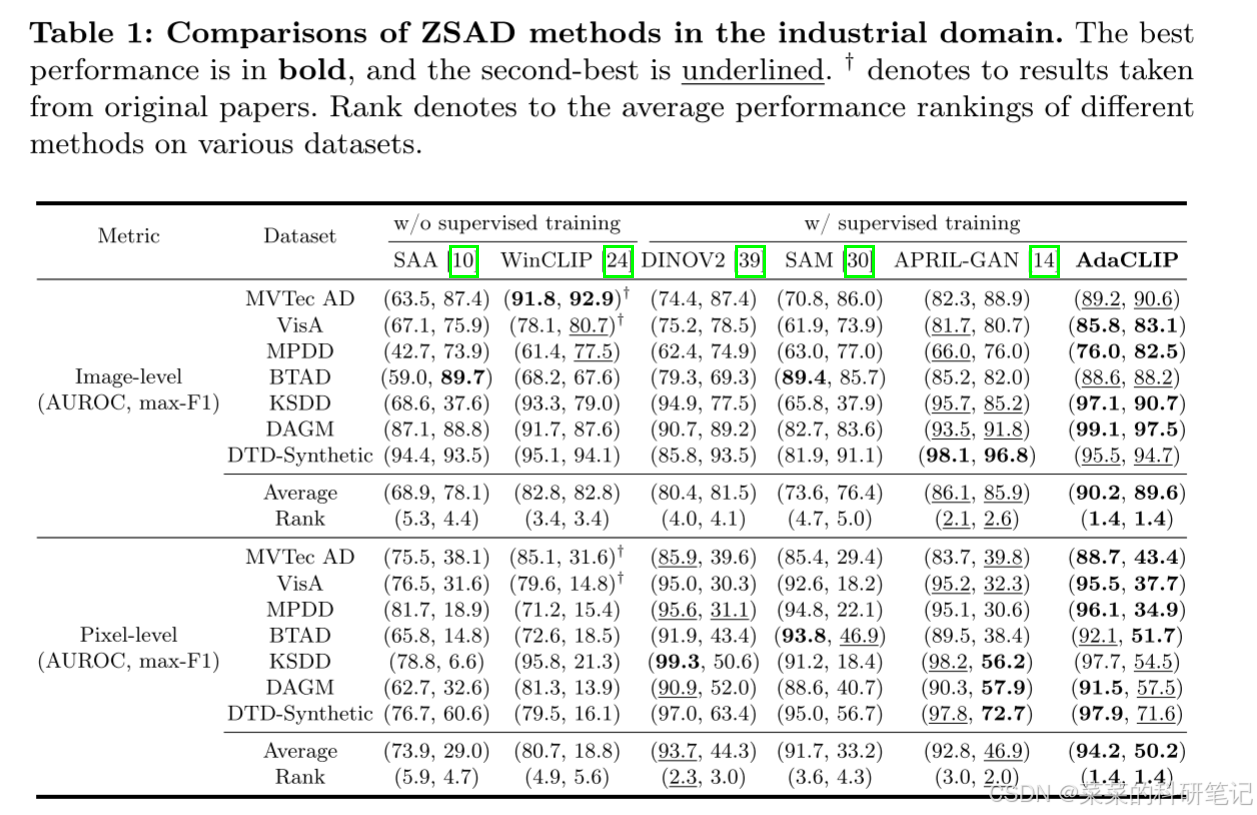
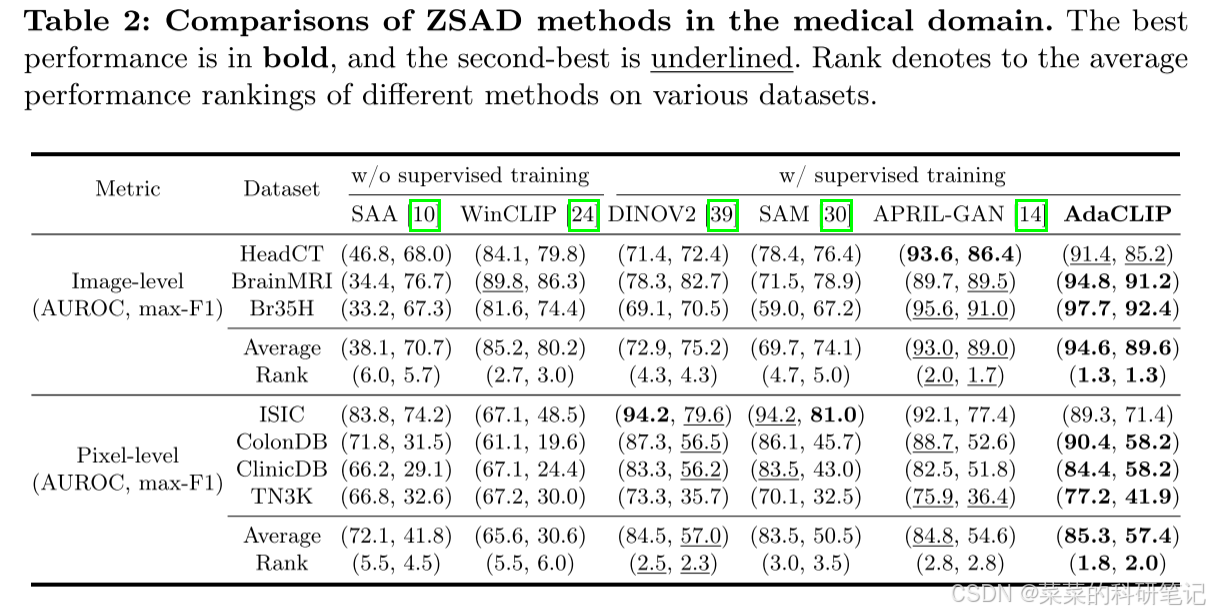
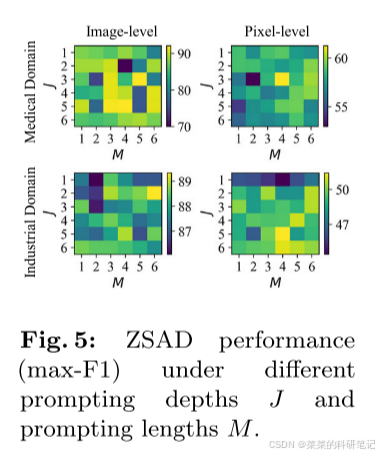
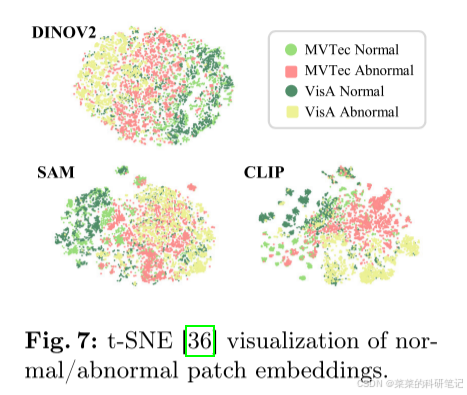
主要消融实验
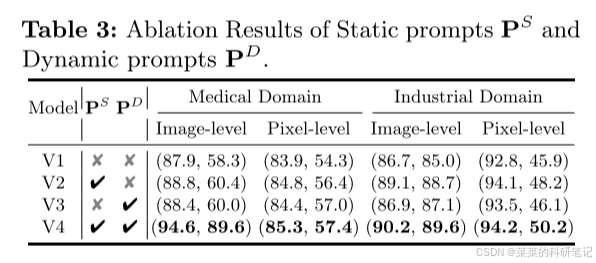
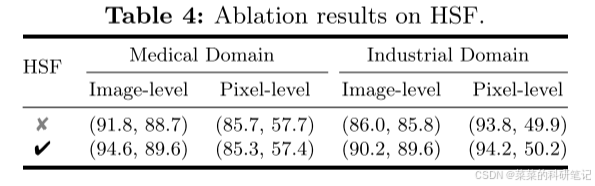
总结
文中提到的限制
AdaCLIP利用辅助数据集实现ZSAD,利用多样化的辅助数据集会提高AdaCLIP的泛化能力,但当测试集与辅助数据集有显著偏离的情况下可能会失败

可能无法检测缺乏结构偏差的异常,这些异常源于偏离了正常上下文规范。
引用
[1] Cao Y, Zhang J, Frittoli L, et al. AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection[C]//European Conference on Computer Vision. Springer, Cham, 2025: 55-72.

















 5267
5267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









