







1 论文情况


这篇论文发布在 2024 ECCV 上(AdaCLIP),GitHub网址已给出(代码仓库),目前已开源,但暂时只支持batch_size为1,该篇论文主要由华科和浙大的团队完成,他们之前也有一些很好的异常检测工作,大家可以去他们的GitHub主页关注关注。
从论文标题可以看出,本片文章主要聚焦于混合提示学习(多支路 + 多模态),但看完论文后会发现,作者还针对图像级的检测模块(HSF语义特征丰富模块)进行了创新。
2 Introduction & Related Works
以往的异常检测主要基于无监督学习和半监督学习,如图所示。
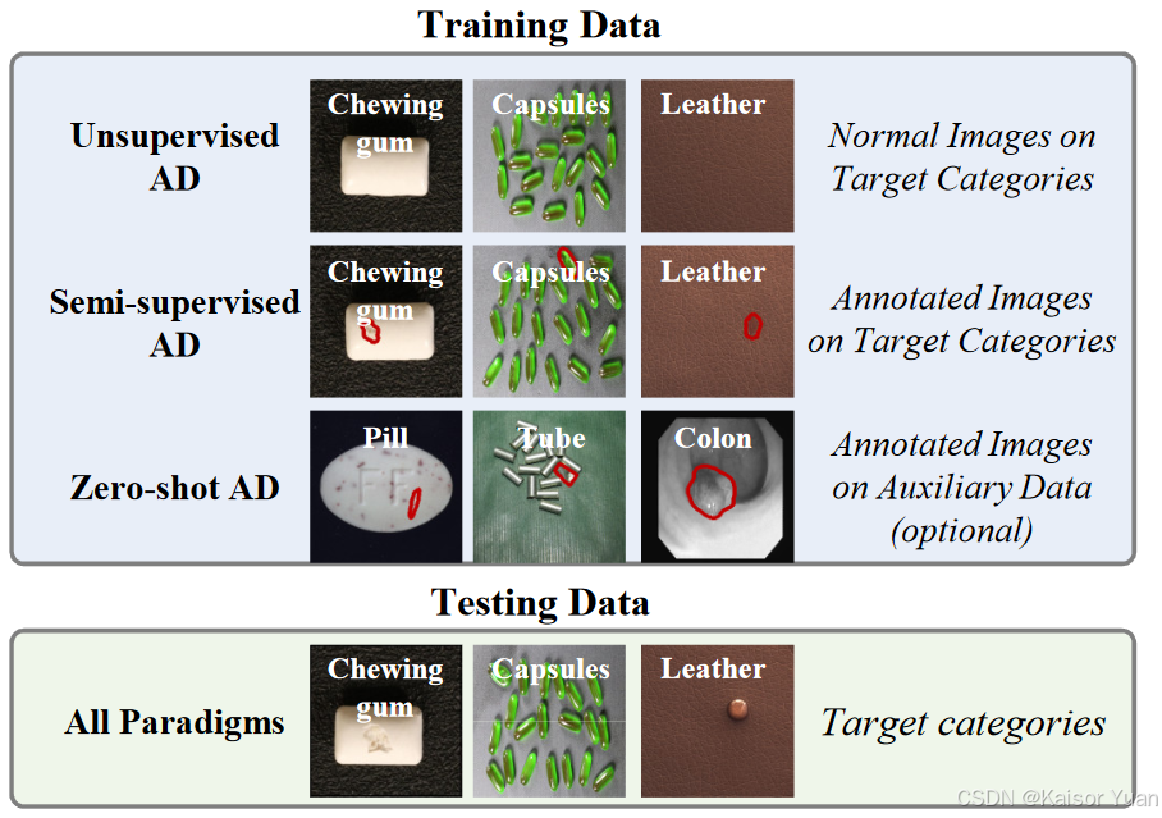
2.1 无监督异常检测
无监督异常检测主要依赖于收集的工业正常图像,对正常图像进行建模,获取工业领域的正常分布,在测试时对比测试特征和正常特征以此来检测和定位异常,著名方法有PatchCore和SPADE等,可参考博主的其他论文分享博客。
2.2 半监督异常检测
而对于半监督异常检测,则是引入了部分异常样本用于训练。这些方法在公开数据集上都实现了不错的性能。但是由于工业领域有的物体种类收集足够多的正常样本也存在一定的困难,异常样本数量更是无法满足需求,因此基于大模型的零样本异常检测任务越来越引起人们的重视。
2.3 零样本异常检测
现有的零样本异常检测方法中,WinCLIP引入了手工设计的文本提示通过视觉语言大模型来识别异常,主要是通过计算文本提示和特征空间的相似度来实现的。但是由于CLIP是在自然图像上训练的,和工业领域存在一定的域偏移。所以有相关方法使用工业辅助数据来调整CLIP以适应于工业图像零样本缺陷检测,如APRIL-GAN和AnomalyCLIP,均实现了较好的性能。这种辅助微调能奏效的原因就是不同的测试图片在正/异常特征上可能展现出统一的模式,例如pill和gum上面的划痕。
2.4 提示学习
在视觉语言大模型的应用中,提示学习发挥了重要作用,其旨在通过在文本或者图像tokens中插入可学习的提示tokens,将多模态大模型应用到各种下游领域。
以往有相关方法在文本支路插入了可学习的tokens,然而这种所有图像共享的静态提示对于多种多样的特征分布可能不够用。所以有其他方法提出了针对每张图片的动态提示来改善模型性能,但是这些提示学习往往聚焦于文本编码器部分。因此本文针对文本和视觉编码器均设计了静态+动态的混合提示学习,达到了较好的效果。
3 AdaCLIP
3.1 Overview
首先输入一张图片,模型会生成对应的正/异常文本提示,如“A photo of normal/damaged [cls]”。检测异常的方式是通过计算图像和文本描述之间的相似度,这是目前主流方法的做法,本文基于此做出了三点创新,模型总览如图所示:
① 多模态(image + text)的混合提示学习(静态 + 动态):静态提示所有图像共享,动态提示基于特定测试图片生成。提示tokens直接拼接于transformer之后。
② CLIP Image Encoder 之后加入Linear Layer,用于对齐视觉特征和文本特征的维度,方便计算相似度,并起到一定的特征微调的作用。
③ 语义特征丰富模块(HSF),用于集中异常分数较高的区域特征,提取语义信息更加丰富的特征embedding,以此提高图像级异常检测水平。
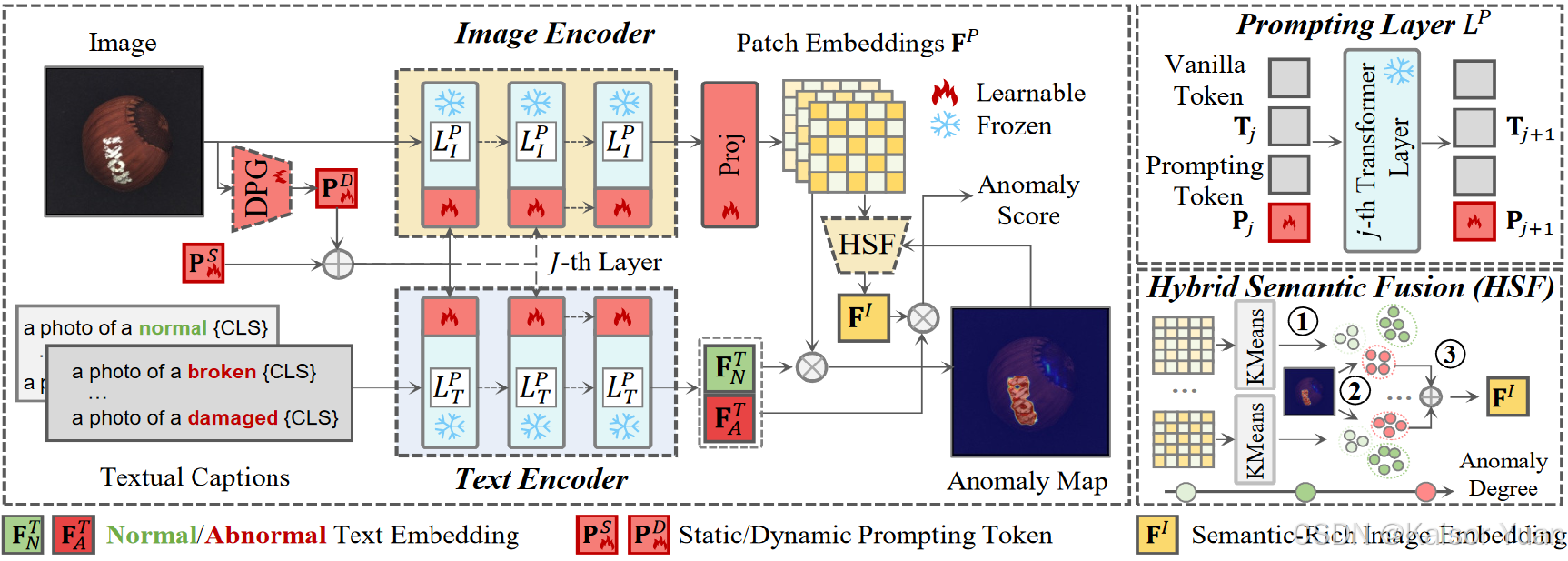
3.2 Prompting Layers
AdaCLIP引入了提示层和
代替原始的图像和文本编码器中的transformer layer。其中保留了原始的transformer权重但拼接了可学习的提示tokens,在保持原始的泛化性能同时引入了域相关的提示。
在原始的特征tokens之后拼接了提示tokens
,其中
代表特征维度,
分别表示原始特征和提示tokens的长度,其中
,由于transformer中的自注意力操作,提示tokens将对所有的特征产生影响。另外为了防止过拟合,设置了一个提示深度
,在前面
层后面拼接可学习的提示,后面层直接用transformer的前向输出。如下公式所示。
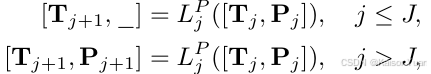
3.3 Hybrid Learnable Prompts
为了有效地利用辅助训练数据,本文引入了静态+动态的混合学习提示。
3.3.1 Static Prompts 
静态提示作为所有图像共享的基础学习tokens,通过辅助训练数据准确学习得到(含有先验知识),然而由以前的相关方法可知,他们的调整效果有限,因此后续引入了动态提示。
3.3.1 Dynamic Prompts 
为了使模型对于图像种类的泛化性更强,本文引入了动态提示产生器(DPG),与静态提示不同的是,它是基于测试图片实时产生的。
![]()
这个提示生成器由冻结的CLIP图像编码器和一个可学习的线性映射层构成,生成的动态提示在图像和文本支路共享。
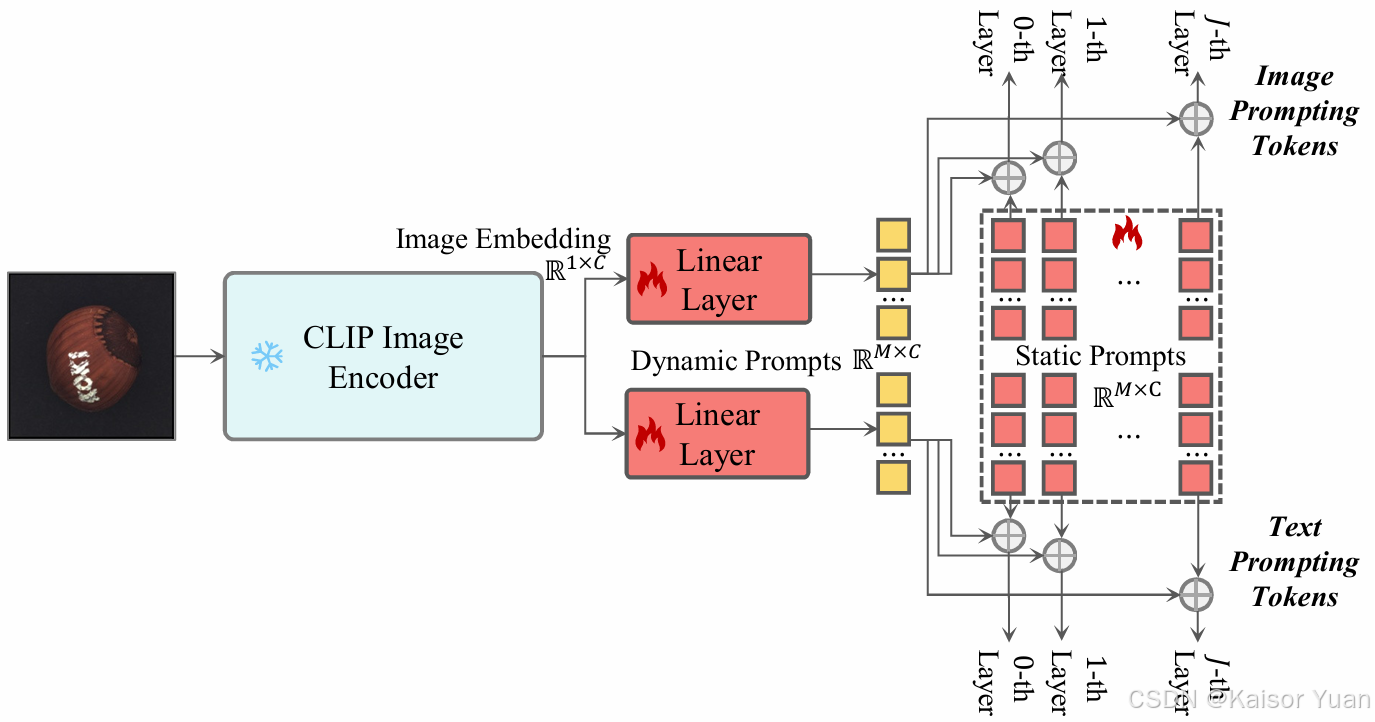
在前层,动态和静态的提示加在一起共同拼接到图像和文本编码器的输出后输入到下一层。 后续所有层,均由前向传播的结果代替。
3.4 Projection Layer & Pixel-Level Anomaly Localization
以为例,图像编码器输出特征维度为1024,但是文本编码器的特征维度为768,两者的维度并不相同,因此为了后续方便计算文本特征和图像特征之间的余弦相似度,本文在图像编码器之后引入了一个可学习的带偏置的线性映射层,将图像的特征维度和文本的特征维度对应上,如模型总览图所示。另外,由于该层存在一些可学习的参数,也对CLIP图像编码器输出的特征有一定的微调作用。
特征维度对齐之后,将通过余弦相似度的计算得到异常图,再进行插值操作得到最终的像素级分割结果,如下公式所示,在训练时,使用focal个dice loss来进行损失计算,其中表示层序号,最终的结果是综合每一层的结果得到的。
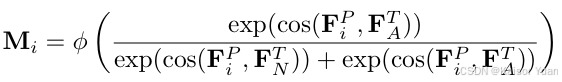
3.5 Hybrid Semantic Fusion Module
传统的异常检测方法中,对于图像级的分类,往往是选取异常图中的最大值作为图像级异常分数,但是这种方法对于噪声预测很敏感,容易降低指标。因此本文引入了HSF模块来聚合更可能表征异常的块特征,因此获得更为丰富的语义信息,最终输出的特征为。该模块主要由③步组成:
① 使用K-Means聚类将patch embedding聚成K个类;
② 通过异常图对应位置异常分数的平均来得到每个聚类的平均异常分数;
③ 选取平均异常分数最高的类的patch embedding,计算它们的质心作为聚合后的语义更为丰富的特征。
3.6 Image-Level Anomaly Detection
在得到聚合后的图表征之后,与3.4中的计算方式一样,外加一个softmax层得到图像级异常分数,最终使用focal loss进行训练。
4 Experiments
4.1 实验细节及结果展示
本用了工业和医学数据集进行实验验证。对于工业和医学数据集,分别使用MVTech AD 和 ClinicDB 作为训练集,在其他数据集上进行测试。对于那两个数据集的测,则使用VisA和ColonDB进行训练,相关实验细节如图表所示。

在14个数据集上的详细定量实验结果如下表所示。
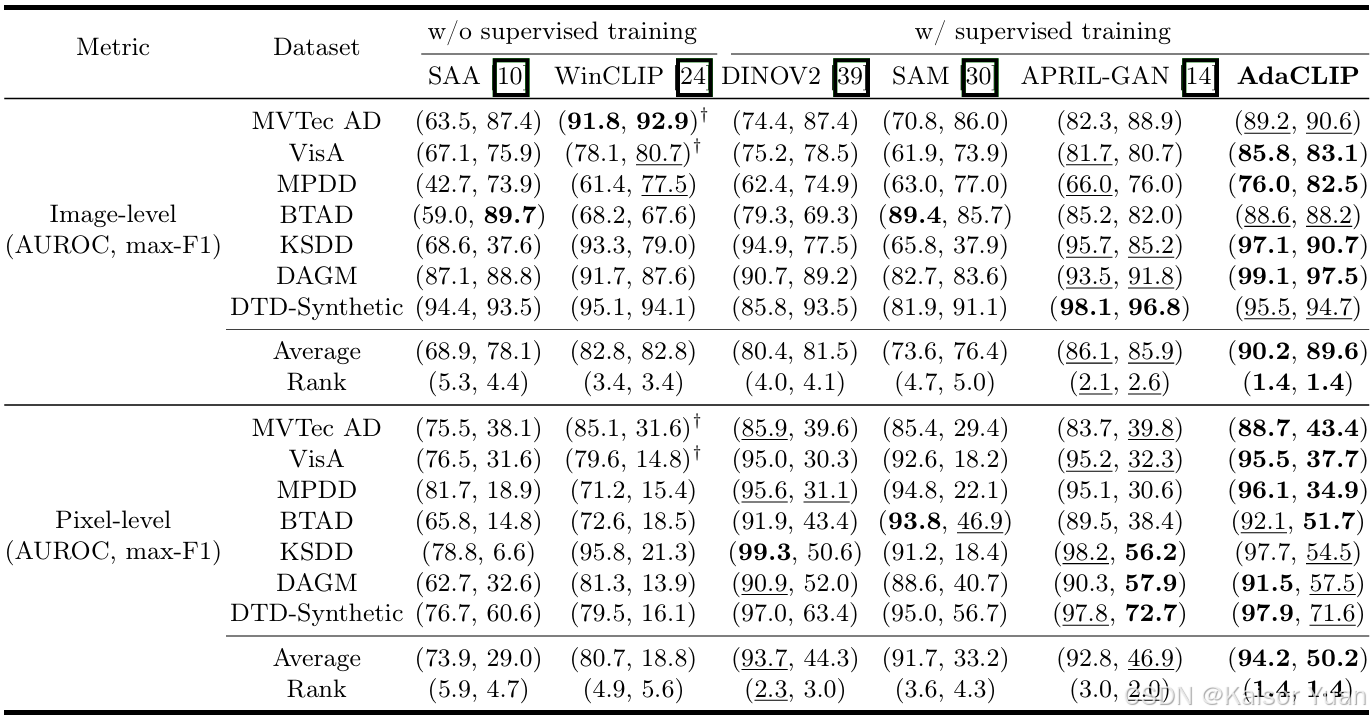
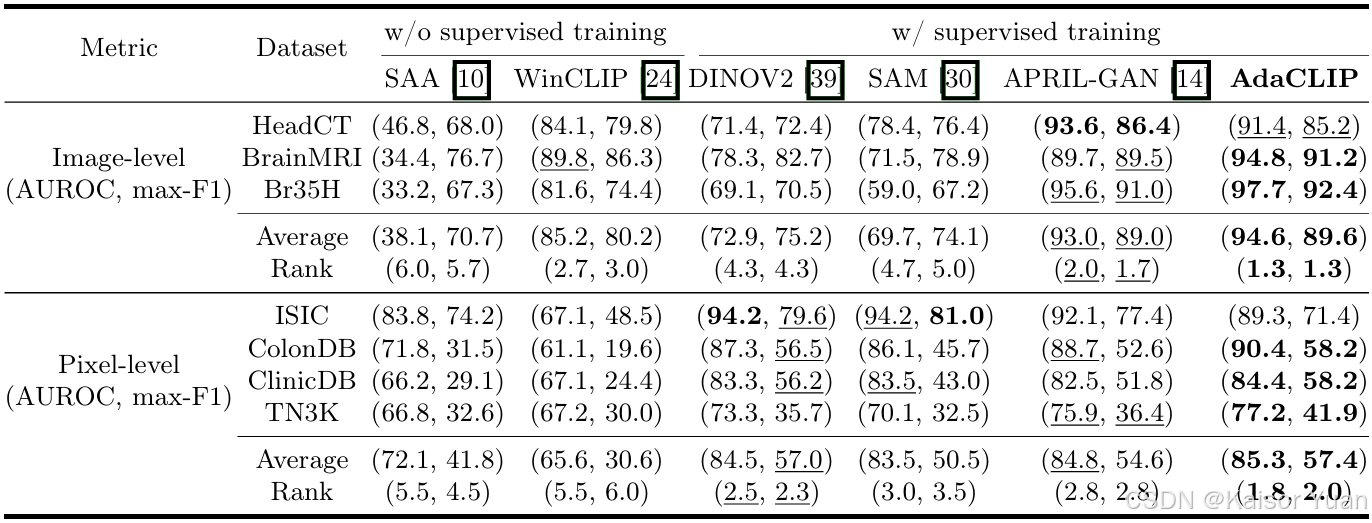
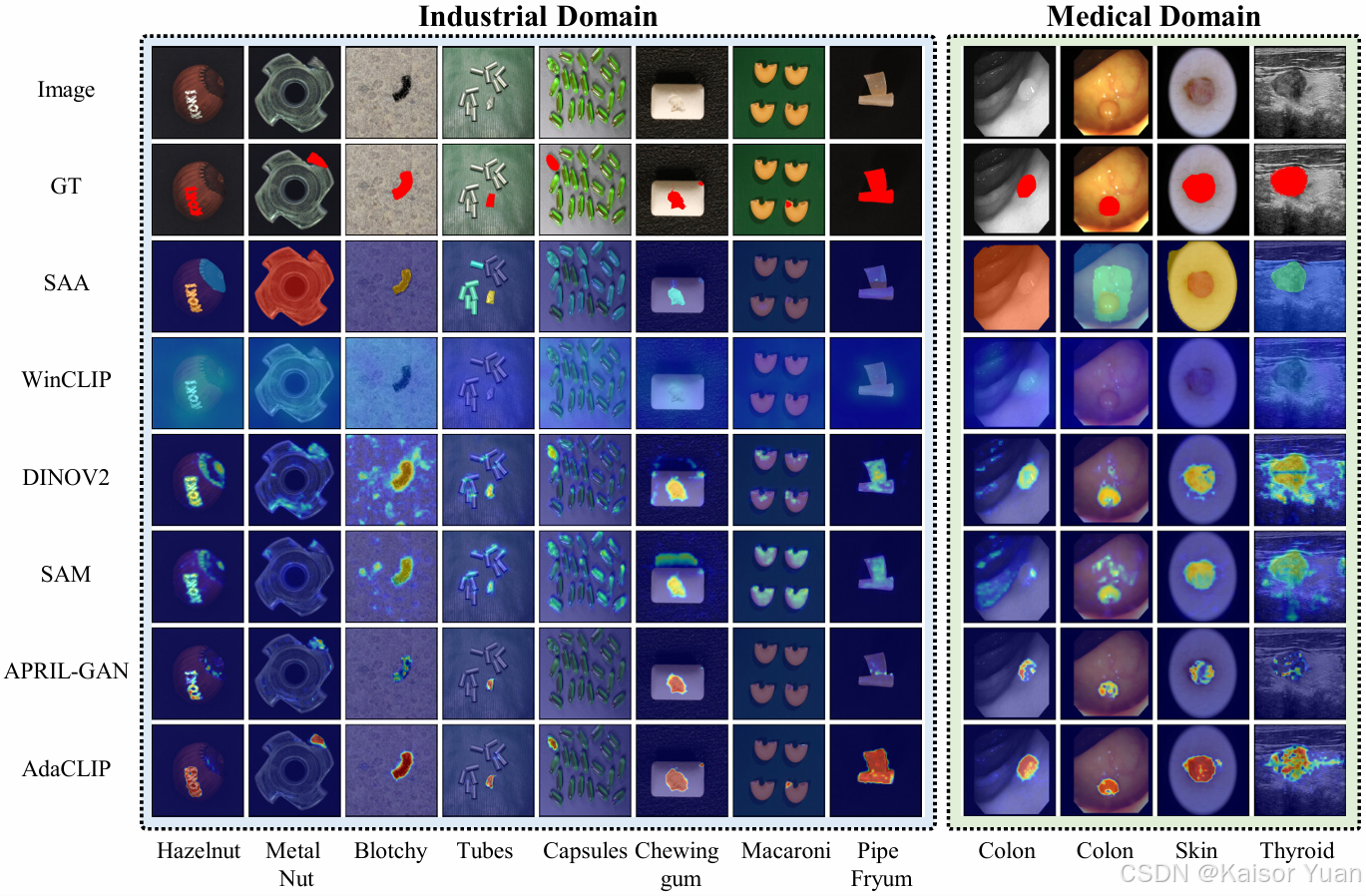
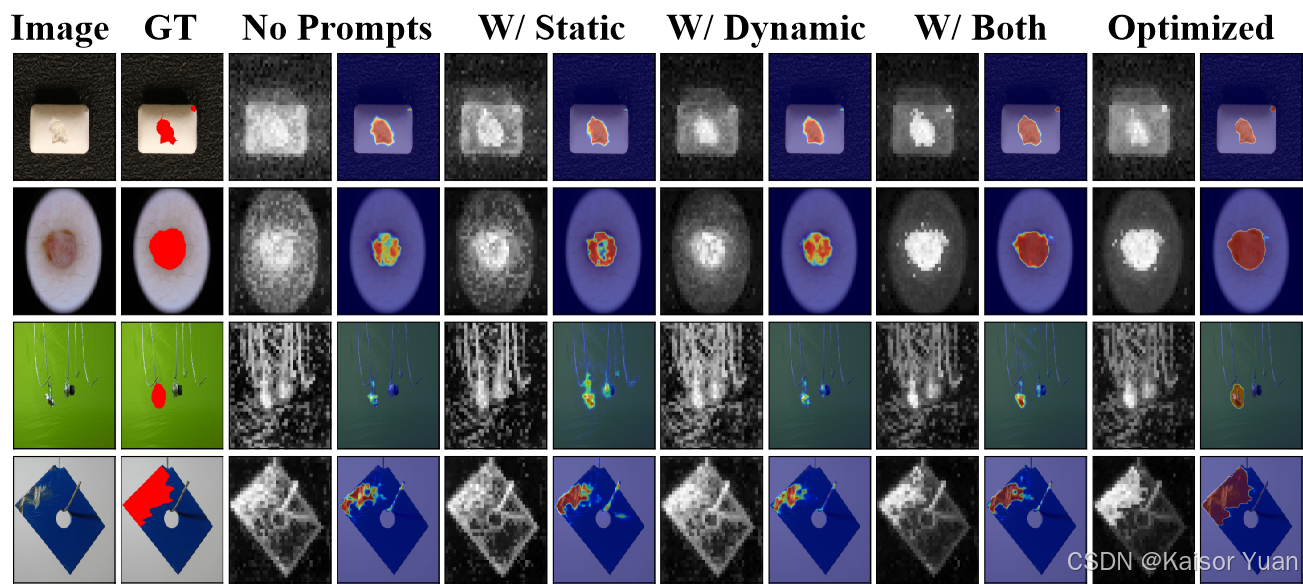
可视化结果如下:
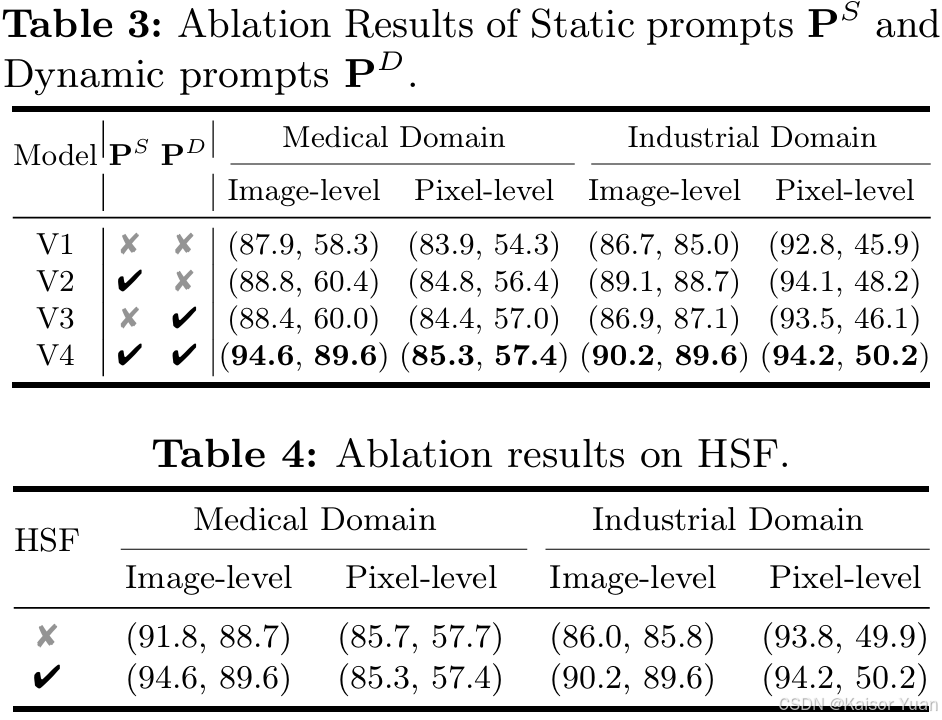
4.2 消融实验
本文分别探究并证实了混合提示学习和语义特征混合模块的作用,并通过对于特征图的可视化直观地证明了混合提示学习的有效性。
5 Analysis & Conclusion
本文针对辅助训练数据的有效性进行了可视化研究,由于工业领域的实验验证都是在使用MVTech AD 作为训练集来进行的,为什么在其上训练的模型能很好地适用于其他工业数据集呢?作者针对这一问题开展了相关研究,可视化结果如下,可以发现不同的数据集的正异常模式大致是相同的对于MVTech AD 和VisA 数据集,正异常特征的边界可以很大程度地共用,因此这是该类方法奏效的原因。
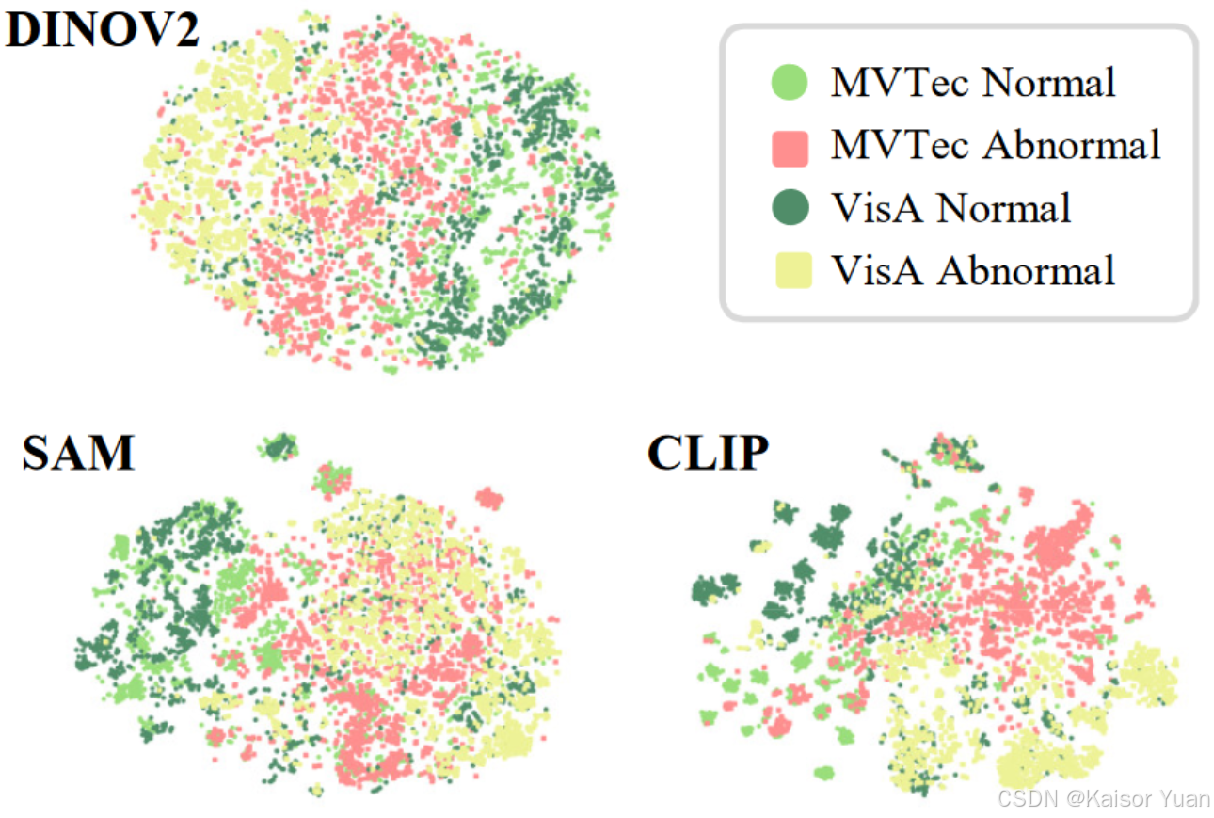
最后,作者分析了本文的局限性,就是当测试数据的分布远离辅助训练数据时,模型的效果会变得很差,在附录中有相关解释,感兴趣的小伙伴可以去原论文中查看。

















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









