






目录
要做什么
手腕部骨龄是预测青少年儿童生长发育的重要指标,在传统的医学诊断中主要依赖人工判断,这一过程过程主观性强、耗时费力。
如果能够使用机器学习的方案,将X光片和性别信息输入,自动获取骨龄信息,那么无疑将极大地缓解医生压力。
目前已有许多研究利用机器学习,尤其是深度学习方法,对儿童骨龄X光片进行自动骨龄检测和评估。主要的研究工作和方法包括:
-
RSNA骨龄挑战赛推动的深度学习方法
2017年RSNA举办的“RSNA Pediatric Bone Age Challenge”提供了一个大规模公开数据集,极大促进了自动骨龄评估模型的开发。许多团队利用卷积神经网络(CNN)进行端到端的骨龄预测,并以均方误差(MAE)等指标进行评价。 -
基于深度卷积神经网络的骨龄预测模型
同时,Lee等(2017)开发了一个完全自动化的深度学习系统,该系统在处理海量手部X光图像时能快速给出骨龄预测结果。
例如,Ren等(2018)提出了基于回归卷积神经网络的自动骨龄评估方法,该方法直接从手部X光图像中提取特征,并实现了较低的预测误差。 -
结合图像分割技术的骨龄评估
有研究采用了Mask R-CNN等图像分割方法来精确分离出手部的骨骼区域,进一步减少背景干扰,再利用Xception等网络进行骨龄回归,从而提升预测精度。 -
中国学者的相关探索
针对我国儿童的骨龄特点,部分研究基于“中华05标准”等本土骨龄评估方法,结合卷积神经网络、迁移学习等技术,设计了数字化骨龄X光片自动识别算法,实现了误差仅在0.5岁左右的高准确度。 -
其他机器学习方法
除了深度学习模型外,还有部分研究尝试使用支持向量机(SVM)、贝叶斯网络和传统回归等方法,对骨龄进行评估;近期也有一些工作引入了对抗性回归学习和岭回归神经网络,以进一步提高模型的泛化能力和准确性。
为了代码练手,增大项目经验,接下来笔者将分享自己使用基于 ResNet50 模型微调的骨龄预测模型
思路
使用已经在更大的数据集上预训练好的 ResNet50 模型,将最后的 fc 替换为符合任务需要的层。
在训练的时候先锁定预训练的层,只训练替换的层,充分训练之后再训练全部的层。
最后计算 MAE 损失,使得直观的得到模型的性能。
数据集下载
代码实现
导入相关需要的库
import os
import pandas as pd
from PIL import Image
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
import torchvision.models as models
from sklearn.model_selection import train_test_split
自定义数据集
由于本项目任务是实现多模态预测模型,需要 X-ray 图像信息 和 male 二元文字信息 综合之后得到预测结果,所以这里自定义骨龄数据集,用于保存、迭代对应的信息。
class BoneAgeDataset(Dataset):
"""
自定义数据集
"""
def __init__(self, csv_file, root_dir, transform=None):
"""
:param csv_file: CSV 文件路径,文件中包含 "fileName", "boneage" 和 "male" 三列
:param root_dir: 图像文件存放的根目录
:param transform: 图像预处理转换
"""
self.data_info = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.data_info)
def __getitem__(self, idx):
# 获取图像文件名及完整路径
filename = self.data_info.iloc[idx]['fileName']
img_path = os.path.join(self.root_dir, filename)
image = Image.open(img_path).convert("RGB")
# 获取骨龄标签
bone_age = self.data_info.iloc[idx]['boneage']
# 获取性别信息,并转换为数值(“male”列中 TRUE 表示男性)
gender_str = str(self.data_info.iloc[idx]['male']).strip().upper()
gender_val = 1.0 if gender_str == "TRUE" else 0.0
if self.transform:
image = self.transform(image)
return image, torch.tensor(bone_age, dtype=torch.float32), torch.tensor(gender_val, dtype=torch.float32)
实现基于 ResNet50 微调的骨龄预测模型
这里使用已经在较大的数据集上预训练好的 ResNet50 模型,进行迁移学习。
为了实现迁移学习的目的,首先通过 self.num_features = backbone.fc.in_features 来保存原 ResNet50 模型最后全连接层的输入特征数。然后通过 backbone.fc = nn.Identity() 去掉 ResNet50 模型最后的全连接层,将在后续工作换上目标任务的全连接层。
为了实现多模态的任务目的,将使用 self.gender_branch 将原有的1维布尔型性别分类信息转化为32维的高维可学习向量。
接着构建 self.fc 来实现模型的数据流动过程。
在前向传播中,为了使得图像信息和性别信息能够多模态融合,将性别信息构造成和图像信息适配的形状,然后和图像信息 cat 起来,一起进入self.fc 进行处理。
class EnhancedBoneAgeModel(nn.Module):
"""
模型构建
"""
def __init__(self):
super().__init__()
# 使用预训练的 ResNet50 作为特征提取器
weights = models.ResNet50_Weights.IMAGENET1K_V1
backbone = models.resnet50(weights=weights)
self.num_features = backbone.fc.in_features
backbone.fc = nn.Identity() # 去掉最后的全连接层
self.backbone = backbone
# 构建性别信息处理分支,将1维信息映射到32维
self.gender_branch = nn.Sequential(
nn.Linear(1, 32),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.Dropout(0.2)
)
# 融合后的全连接网络
self.fc = nn.Sequential(
nn.Linear(self.num_features + 32, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 1)
)
def forward(self, image, gender):
features = self.backbone(image) # [batch_size, num_features]
# 保证 gender 形状为 [batch_size, 1]
if gender.dim() == 1:
gender = gender.unsqueeze(1)
gender_features = self.gender_branch(gender) # [batch_size, 32]
x = torch.cat([features, gender_features], dim=1)
out = self.fc(x)
return out
构建训练和验证函数
为了让代码增强可读性和模块性,将构建训练和验证函数,分别返回对应的损失值。
# 训练与验证函数
def train_epoch(model, loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for images, bone_ages, genders in loader:
images = images.to(device)
bone_ages = bone_ages.to(device).unsqueeze(1) # [batch_size, 1]
genders = genders.to(device)
optimizer.zero_grad()
outputs = model(images, genders)
loss = criterion(outputs, bone_ages)
loss.backward()
optimizer.step()
running_loss += loss.item() * images.size(0)
return running_loss / len(loader.dataset)
def eval_epoch(model, loader, criterion, device):
model.eval()
running_loss = 0.0
with torch.no_grad():
for images, bone_ages, genders in loader:
images = images.to(device)
bone_ages = bone_ages.to(device).unsqueeze(1)
genders = genders.to(device)
outputs = model(images, genders)
loss = criterion(outputs, bone_ages)
running_loss += loss.item() * images.size(0)
return running_loss / len(loader.dataset)
构建计算MAE损失函数
为了很直观的衡量模型的性能,直接得到模型预测和真实值误差多少时间,使用MAE损失函数来进行最后的评价。
这里构建一个计算函数来实现。
def compute_mae(model, loader, device):
model.eval()
total_mae = 0.0
with torch.no_grad():
for images, bone_ages, genders in loader:
images = images.to(device)
bone_ages = bone_ages.to(device).unsqueeze(1)
genders = genders.to(device)
outputs = model(images, genders)
mae = torch.abs(outputs - bone_ages).sum().item()
total_mae += mae
return total_mae / len(loader.dataset)
进入主函数
这里的训练策略为:
- 首先固定原 ResNet50 的参数,对于新增加的头(fc、gender_branch)进行训练。
- 在充分训练之后,此时对于新增加的头的参数,已经是相对优良的状态。
- 然后解锁之前固定的参数,对全部的网络进行训练。
- 在充分训练之后,对于模型的全部参数,达到较为不错的状态
数据的预处理以及数据加载
为了增强数据的质量,在数据的预处理阶段,将训练的数据图像进行放缩到指定大小、随机水平翻转、随机旋转、归一化等操作,对于评测的数据图像仅进行归一化的操作。
增强后的数据有利于模型更好地学习。
然后按照8:2的比例将数据进行划分为 训练集和测试集,保存它们的信息为 “train_split.csv” 和 “val_split.csv”
接下来加载数据,进行下一步训练。
# 图像预处理配置
IMG_SIZE = 224
train_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=[0.1827, 0.1827, 0.1827],
std=[0.1643, 0.1643, 0.1643])
])
val_transform = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.1827, 0.1827, 0.1827],
std=[0.1643, 0.1643, 0.1643])
])
csv_path = 'data.csv'
df = pd.read_csv(csv_path)
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42)
train_csv = 'train_split.csv'
val_csv = 'val_split.csv'
train_df.to_csv(train_csv, index=False)
val_df.to_csv(val_csv, index=False)
image_root = 'dataset\images'
# 构造数据集
train_dataset = BoneAgeDataset(csv_file=train_csv, root_dir=image_root, transform=train_transform)
val_dataset = BoneAgeDataset(csv_file=val_csv, root_dir=image_root, transform=val_transform)
BATCH_SIZE = 32
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4)
训练设备和模型的加载
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = EnhancedBoneAgeModel().to(device)
进入模型的第一阶段的训练——训练最后新增加的层
通过 param.requires_grad = False 来控制模型无需训练的层
# 阶段1:冻结预训练部分,仅训练新增层(包括 fc 和 gender_branch)
for param in model.backbone.parameters():
param.requires_grad = False
criterion = nn.MSELoss()
optimizer = optim.Adam(list(model.fc.parameters()) + list(model.gender_branch.parameters()),
lr=1e-3, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
epochs_top = 30
print("=== 阶段1:训练新增层和性别分支 ===")
for epoch in range(epochs_top):
train_loss = train_epoch(model, train_loader, criterion, optimizer, device)
val_loss = eval_epoch(model, val_loader, criterion, device)
scheduler.step()
print(f"Epoch [{epoch + 1}/{epochs_top}], 训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}")
进入模型的第二阶段的训练——训练全部网络
通过 param.requires_grad = True 来打开模型需要训练的层
# 阶段2:Fine-tuning 全部网络
for param in model.parameters():
param.requires_grad = True
optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-4)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
epochs_finetune = 30
print("=== 阶段2:Fine-tuning 全部层 ===")
for epoch in range(epochs_finetune):
train_loss = train_epoch(model, train_loader, criterion, optimizer, device)
val_loss = eval_epoch(model, val_loader, criterion, device)
scheduler.step()
print(f"Epoch [{epoch + 1}/{epochs_finetune}], 训练损失: {train_loss:.4f}, 验证损失: {val_loss:.4f}")
保存模型参数以及返回模型性能评价
torch.save(model.state_dict(), "enhanced_bone_age_predictor.pth")
print("模型已保存!")
mae_val = compute_mae(model, val_loader, device)
print(f"验证集 MAE: {mae_val:.4f}")
总结反思
下面将展示模型的运行结果:
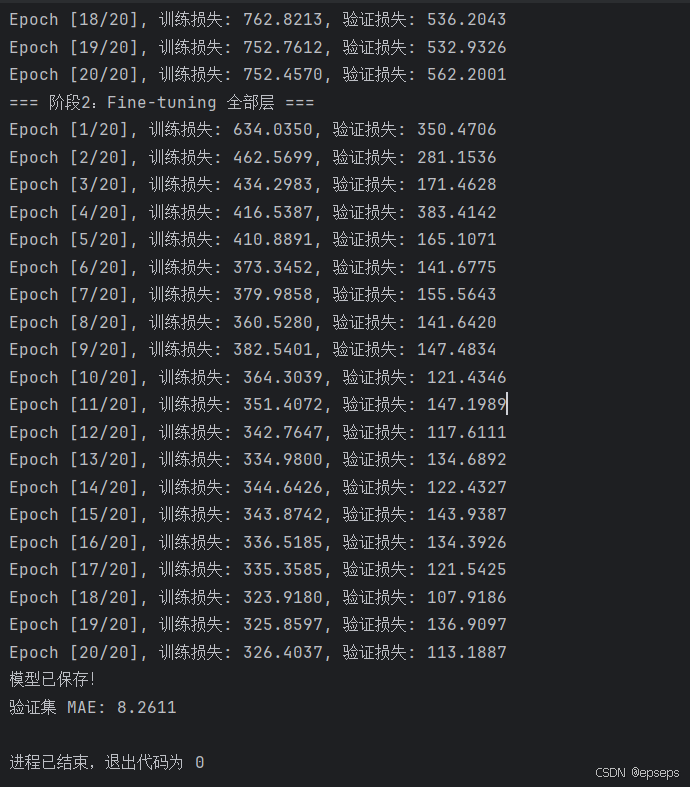
可以看到,模型的平均预测误差为 8.26 个月,和目前被认为是最领先的4~5个月虽然仍有一定的差距,但是对于新手练习基于预训练模型微调以及多模态模型的构建仍然有积极意义。


















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









