







2024深度学习发论文&模型涨点之——曼巴+医疗图像分割
曼巴(Mamba)结合医疗图像分割是一种新兴的技术,曼巴架构以其在处理长序列和全局上下文信息方面的能力以及作为状态空间模型的计算效率的提高而闻名。它能够有效地建模医学图像中的长程依赖性,这对于精确分割是一个关键方面。
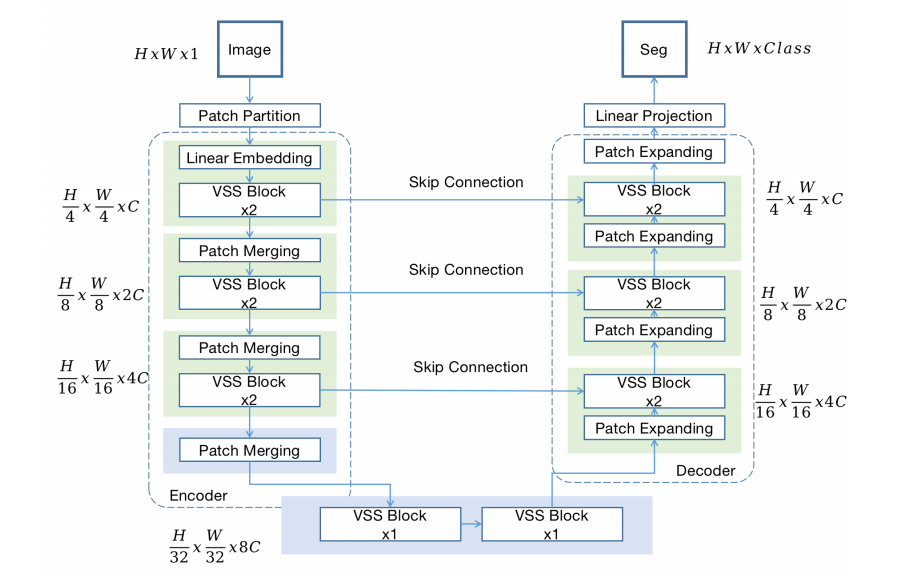
比如Mamba-UNet是一种新颖的架构,它结合了U-Net和曼巴的能力。这种架构采用了基于纯视觉曼巴(VMamba)的编码器-解码器结构,并注入跳跃连接以保留不同规模网络的空间信息。这种设计促进了全面的特征学习过程,捕获医学图像中复杂的细节和更广泛的语义上下文。
我整理了一些曼巴+医疗图像分割【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取
论文精选
论文1:
Mamba-UNet: UNet-Like Pure Visual Mamba for Medical Image Segmentation
Mamba-UNet:用于医学图像分割的UNet风格的纯视觉Mamba
方法
-
纯视觉Mamba(VMamba)基础的编码器-解码器结构:采用基于VMamba的编码器-解码器结构,通过跳跃连接保留不同尺度上的空间信息。
-
特征学习:通过综合特征学习过程,捕获医学图像中的复杂细节和更广泛的语义上下文。
-
新型集成机制:在VMamba块内引入新型集成机制,确保编码器和解码器路径之间的无缝连接和信息流动。
创新点
-
结构设计:Mamba-UNet在ACDC MRI心脏分割数据集和Synapse CT腹部分割数据集上的表现超过了多种UNet变体,具体表现为在相同超参数设置下的性能提升。
-
性能提升:在ACDC数据集上,Ma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









