







【机器学习|学习笔记】核逻辑回归(Kernel extreme learning machine ,KELM )详解,附代码。
【机器学习|学习笔记】核逻辑回归(Kernel extreme learning machine ,KELM )详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147567533
前言
- 核逻辑回归是在经典逻辑回归中引入核技巧,使模型能够在高维特征空间中进行非线性分类而无需显式计算映射;
- 它结合了核方法的强大非线性表示能力与逻辑回归的概率输出特性,自2001年左右提出以来,已衍生出多种高效求解与近似算法,并在离散选择建模、环境工程、灾害预测、生物信息学等领域广泛应用。
起源
逻辑回归的统计学渊源
- 逻辑回归最早可追溯至19世纪末对逻辑函数的研究,并于20世纪初在生物测定(bio‑assay)中得到应用;
- Joseph Berkson于1944年正式将“logit”模型引入统计学,奠定了现代逻辑回归的基础 。
核方法与代表性定理
- 20世纪90年代,支持向量机(SVM)等核方法兴起,利用再生核希尔伯特空间(RKHS)的代表性定理,将非线性映射隐式地嵌入模型中 。
- 根据代表性定理,任何在RKHS中带惩罚项的经验风险最小化问题,其最优解都可表示为训练样本的核加权和,这为核逻辑回归的提出提供了理论依据 。
核逻辑回归的首次提出
- 2001年,Zhu 和 Hastie在NIPS会议上发表论文,首次将逻辑回归的对数似然损失与核技巧结合,提出了Kernel Logistic Regression,并在此基础上发展出Import Vector Machine(IVM)模型 。
- IVM通过选择关键“导入点”减少模型稀疏性,并保留概率输出,从而兼具SVM的高精度与逻辑回归的概率解释性。
发展
稳定性与可扩展性改进
- Nyström 近似:针对KLR在大规模数据上需存储和反演 N × N N×N N×N 核矩阵的瓶颈,提出Nyström方法对核矩阵做低秩近似,显著降低时间和空间复杂度 。
- 并行与分布式求解:Schölkopf等人将KLR与分布式优化结合,实现千万级样本的并行训练 。
- 算法变体:灰狼优化(GWO)等元启发式算法被用于自动调优核参数与正则化系数,形成KLR‑GWO等混合模型,在工程预测中表现优异 。
- 专用软件包:PyKernelLogit封装了带惩罚最大似然估计的KLR,支持多种离散选择模型,简化了工程应用 。
原理
对偶表示与优化目标
-
给定训练集 ( x i , y i ) i = 1 N {(x_i,y_i)}_{i=1}^N (xi,yi)i=1N,其中 y i ∈ − 1 , 1 y_i ∈{−1,1} yi∈−1,1,KLR基于代表性定理将决策函数表示为
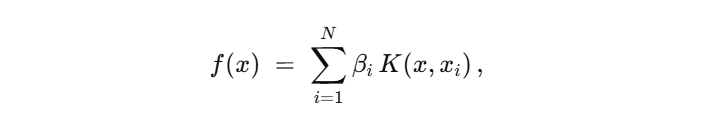
其中 K K K 为正定核函数(如RBF、Polynomial等) -
其正则化对数似然最小化目标为
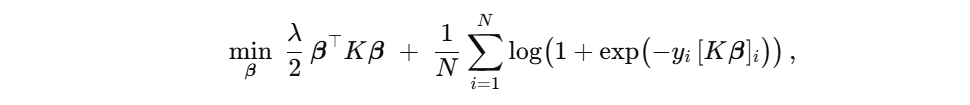
其中 K i j = K ( x i , x j ) K_{ij} = K(x_i,x_j) Kij=K(xi,xj), λ λ λ 为正则化系数
求解方法
- 迭代重权最小二乘(IRLS):将对数似然二阶泰勒展开,迭代求解加权最小二乘子问题,直至收敛
- 梯度与牛顿法:直接对对偶目标计算梯度 ∇ β = λ K β + K ( − y ⊙ σ ( − y ⊙ f ) ) ∇_β=λKβ+K(−y⊙σ(−y⊙f)) ∇β=λKβ+K(−y⊙σ(−y⊙f))并采用L‑BFGS或牛顿法优化。
应用
- 离散选择建模:用于交通出行模式、产品选择等行为建模,提供概率预测
- 洪涝易发性映射:与RBF、朴素贝叶斯等方法比较,KLR在小样本高维下稳定性更优
- 环境工程:预测重金属吸附效率时,KLR结合克里金法提高了回归精度
- 关联记忆与Hopfield网络容量:在Hopfield关联记忆网络中,KLR显著提升存储容量与噪声鲁棒性
- 医学与信用风险评估:针对不平衡数据提供概率输出,便于风险分层与决策支持
Python 代码实现
下面给出两种常用实现方式:
- 核近似 + 线性逻辑回归(适合大规模场景);
- 对偶形式直接优化(适合中小规模数据,体现KLR本质)。
1. 核近似 + 线性逻辑回归
- 利用 RBFSampler 对RBF核做随机傅里叶特征近似,再调用scikit‑learn的LogisticRegression即可
from sklearn.kernel_approximation import RBFSampler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 加载数据
X, y = load_iris(return_X_y=True)
y = (y == 2).astype(int) # 二分类示例
# 划分训练/测试
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 构造管道:RBF近似 → 逻辑回归
model = make_pipeline(
RBFSampler(gamma=0.5, n_components=200, random_state=42),
LogisticRegression(max_iter=1000)
)
model.fit(X_train, y_train)
print("Test accuracy:", model.score(X_test, y_test))
2. 对偶形式直接优化
- 下面展示对偶KLR的简易实现,采用L‑BFGS优化器。
import numpy as np
from scipy.optimize import minimize
from scipy.special import expit # sigmoid
def rbf_kernel(X1, X2, gamma):
sqd = np.sum(X1**2,1)[:,None] + np.sum(X2**2,1)[None,:] - 2*X1.dot(X2.T)
return np.exp(-gamma * sqd)
class DualKLR:
def __init__(self, C=1.0, gamma=1.0):
self.C = C
self.gamma = gamma
def fit(self, X, y):
N = X.shape[0]
K = rbf_kernel(X, X, self.gamma)
y_signed = np.where(y==1, 1, -1)
# 目标函数和梯度
def obj(beta):
f = K.dot(beta)
loss = np.logaddexp(0, -y_signed * f).mean()
reg = 0.5 * (beta @ K @ beta) / self.C
return reg + loss
def grad(beta):
f = K.dot(beta)
sigma = expit(-y_signed * f)
grad_loss = (-1/N) * K.dot(y_signed * sigma)
grad_reg = (K.dot(beta)) / self.C
return grad_reg + grad_loss
# 初始化β
beta0 = np.zeros(N)
res = minimize(obj, beta0, jac=grad, method='L-BFGS-B')
self.beta = res.x
self.X_train = X
self.K = K
def predict_proba(self, X):
K_test = rbf_kernel(X, self.X_train, self.gamma)
f = K_test.dot(self.beta)
p = expit(f)
return np.vstack([1-p, p]).T
def predict(self, X):
return (self.predict_proba(X)[:,1] > 0.5).astype(int)
# 测试
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = DualKLR(C=10.0, gamma=0.01)
model.fit(X_train, y_train)
print("Dual KLR accuracy:", np.mean(model.predict(X_test)==y_test))
- 以上两种实现方式分别兼顾了大规模效率与KLR的理论本质,可根据数据规模与精度需求灵活选择。


















 2263
2263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











