






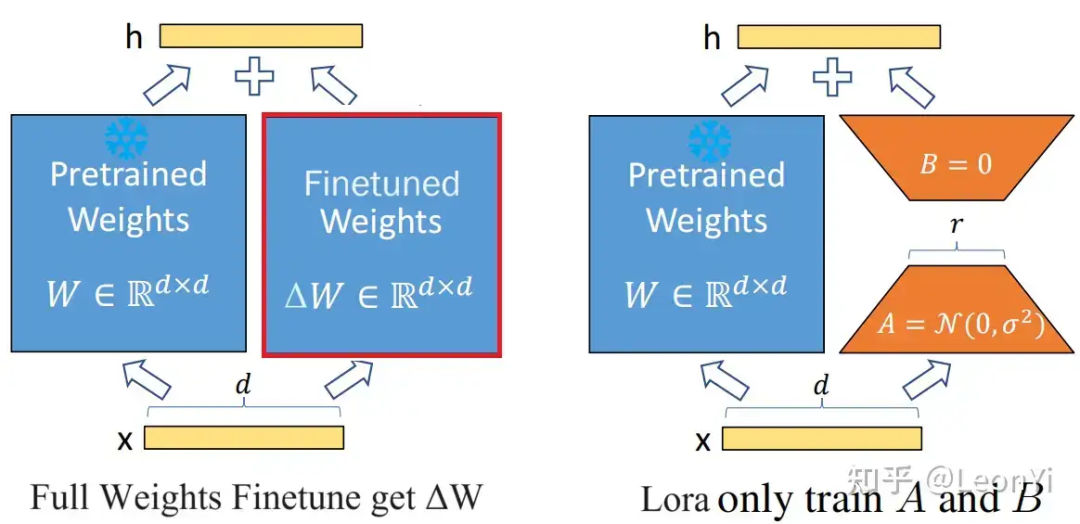
LoRA(Low-Rank Adaptation) 的思想:冻结预训练模型权重,将可训练的低秩分解矩阵注入到Transformer架构的每一层(也可单独配置某一层)中, 从而大大减少在下游任务的可训练参数量。
核心原理
对于预训练权重矩阵 ,LoRA限制了其更新方式,将全参微调的增量参数矩阵 表示为两个参数量更小的矩阵 和 的低秩近似:
其中:
-
• 和 为LoRA低秩适应的权重矩阵
-
• 秩 远小于 (即 )
此时,微调的参数量从原来 的,变成了和的。由于(满足),显著降低了训练参数量。
方法:
优势:
-
1. 高效训练:大大减少需要训练的参数数量(只训练 A 和 B,而不是 W₀),降低对GPU内存的需求,缩短训练时间。
-
2. 高效存储/切换:对每个新任务,只需要存储和加载小的 LoRA 权重(A 和 B),而不是整个模型的副本,这样就可以为一个基础模型配备多个任务的“适配器”。
-
3. 性能保持:LoRA能在降低训练成本的同时,达到接近完全微调的性能。
通过代码理解原理
下列代码拷贝合在一起,更换数据集与模型文件路径后,可直接运行,PEFT版本为0.14.0。重点关注第四步配置LoRA和第八步模型推理, 其余代码在往期文章中已有详细介绍。
-
• 数据集:alpaca_data_zh
-
• 预训练模型:bloom-389m-zh
第一步: 导入相关包
import torch
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
from peft import PromptTuningConfig, get_peft_model, TaskType, PromptTuningInit, PeftModel第二步: 加载数据集
# 包含 'instruction' (指令), 'input' (可选的额外输入), 'output' (期望的回答)
ds = Dataset.load_from_disk("../data/alpaca_data_zh/") 第三步: 数据集预处理
将每个样本处理成包含 input_ids, attention_mask, 和 labels 的字典。
tokenizer = AutoTokenizer.from_pretrained("D:\\git\\model-download\\bloom-389m-zh")
defprocess_func(example):
MAX_LENGTH = 256
# 构建输入文本:将指令和输入(可选)组合到一起,并添加明确的 "Human:" 和 "Assistant:" 标识符。"\n\nAssistant: " 是提示模型开始生成回答的关键分隔符。
prompt = "\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: "
# 对输入+提示进行分词,这里暂时不添加特殊token (<s>, </s>),后面要拼接
instruction_tokenized = tokenizer(prompt, add_special_tokens=False)
# 对期望的输出(回答)进行分词,在回答的末尾加上 `tokenizer.eos_token` (end-of-sentence)。告诉模型生成到这里就可以结束。
response_tokenized = tokenizer(example["output"] + tokenizer.eos_token, add_special_tokens=False)
# 将输入提示和回答的 token IDs 拼接起来,形成完整的输入序列 input_ids
input_ids = instruction_tokenized["input_ids"] + response_tokenized["input_ids"]
# attention_mask 用于告诉模型哪些 token 是真实的、需要关注的,哪些是填充的(padding)。
attention_mask = instruction_tokenized["attention_mask"] + response_tokenized["attention_mask"]
# 创建标签 (labels):这是模型需要学习预测的目标,因为只希望模型学习预测 "Assistant:" 后面的回答部分,所以将输入提示部分的标签设置为 -100,损失函数自动忽略标签为 -100 的 token,不计算它们的损失。
labels = [-100] * len(instruction_tokenized["input_ids"]) + response_tokenized["input_ids"]
# 截断
iflen(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
# 返回处理好的数据
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
# .map() 方法将处理函数应用到整个数据集的所有样本上。
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names) # `remove_columns` 会移除原始的列,只保留 process_func 返回的新列。
print("\n检查第2条数据处理结果:")
print("输入序列 (input_ids解码):", tokenizer.decode(tokenized_ds[1]["input_ids"]))
target_labels = list(filter(lambda x: x != -100, tokenized_ds[1]["labels"])) # 过滤掉 -100,看看模型真正需要预测的标签是什么
print("标签序列 (labels解码,过滤-100后):", tokenizer.decode(target_labels))第四步: 加载预训练模型和配置LoRA
1. 配置LoRA(关键步骤):
-
• 选择在哪些层上应用LoRA,
target_modules=".*\\.1.*query_key_value": 用来指定要在哪些模块(层)上应用LoRA适配器,.*\\.1.*query_key_value匹配的是模型中名字包含 ".1." (通常指第一层Transformer块)并且是 "query_key_value" (在某些模型结构中,QKV是合并在一起的)的线性层。如果指定的是["query_key_value"],则表示适配所有层的QKV映射,从而调整模型注意力机制中的参数。 -
•
r:低秩分解的秩,默认值通常是8或16。r越小,引入的参数越少,但会牺牲一些性能;r越大,参数越多,可能性能更好,但效率增益降低。
2. 使用PEFT将LoRA应用到模型:
-
•
get_peft_model接收原始模型和LoRA配置:
a. 冻结原始模型所有参数。
b. 根据target_modules在指定层旁边添加LoRA适配器层(可训练的小矩阵A和B)。
c. 如果指定了modules_to_save,则会解冻这些模块的参数,使其也可训练。 -
• 返回的
model是一个PeftModel对象,封装了原始模型和LoRA适配器。
model = AutoModelForCausalLM.from_pretrained("D:\\git\\transformers-code-master\\model-download\\bloom-389m-zh")
# LoRA 配置
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=".*\\.1.*query_key_value", # 适配第1层的QKV合并层(根据模型结构调整),或者更通用的写法,target_modules=["query_key_value"],适配所有层的QKV
r=8, # 显式设置LoRA的秩 (rank),可以调整,比如 8, 16, 32
lora_alpha=32, # LoRA缩放因子,通常设为 r 的2倍或4倍
lora_dropout=0.1, # LoRA层的dropout率
modules_to_save=["word_embeddings"] # 除了LoRA参数外,有时需要训练(并保存)词嵌入层(`word_embeddings`)。有时调整词嵌入对适应新词汇或领域有帮助。如果不需要,可以去掉这个参数。
)
print("\nLoRA配置详情:", config)
# 使用 PEFT 应用 LoRA 到模型
model = get_peft_model(model, config)
print("\n应用LoRA后的模型可训练参数:")
# 打印模型中哪些参数是可训练的(主要是LoRA的A、B矩阵和word_embeddings)
for name, parameter in model.named_parameters():
if parameter.requires_grad:
print(name)
print("\n可训练参数统计:")
model.print_trainable_parameters() # 关键:观察可训练参数占比!3. 检查可训练参数:
-
• 可训练参数统计:原训练规模为3.9亿参数,LORA后,训练参数规模为0.43亿,训练参数规模大大降低。
trainable params: 43,815,936 || all params: 389,584,896 || trainable%: 11.2468,第五步: 配置训练参数
args = TrainingArguments(
output_dir="./chatbot_lora_tuned", # 输出目录
per_device_train_batch_size=1, # 每个GPU的批大小
gradient_accumulation_steps=8, # 梯度累积步数,实际批大小 = 1 * 8 = 8
logging_steps=10, # 每10步记录一次日志
num_train_epochs=1, # 训练轮数
save_strategy="epoch", # 每个epoch保存一次模型
learning_rate=1e-4, # 学习率
warmup_steps=100, # 预热步数
# 可以添加更多参数,如 weight_decay, evaluation_strategy 等
)第六步: 创建训练器
trainer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
train_dataset=tokenized_ds,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True), # 使用Seq2Seq的整理器,将批次内的数据动态填充(padding)到相同长度,确保张量形状一致。
)第七步: 模型训练
只有在LoRA配置中指定的可训练参数
(LoRA的A、B矩阵,以及 modules_to_save 中的层)会被优化器更新,原始模型权重保持冻结。
trainer.train()第八步: 模型推理 (使用微调后的模型)
推理时,PeftModel 会自动将 LoRA 适配器(B*A)的效果加到原始权重上,无需手动操作。
from peft import PeftModel
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("D:\\git\\transformers-code-master\\model-download\\bloom-389m-zh")
tokenizer = AutoTokenizer.from_pretrained("D:\\git\\transformers-code-master\\model-download\\bloom-389m-zh")
print("基础模型加载完成:", type(model))
# 加载Lora模型
p_model = PeftModel.from_pretrained(model, model_id="./chatbot/checkpoint-3357/")
print("Lora模型加载结果:", p_model)
# 生成对话
ipt = tokenizer("Human: {}\\n{}".format("考试有哪些技巧?", "").strip() + "\\n\\nAssistant: ", return_tensors="pt")
generated = p_model.generate(**ipt, do_sample=False)
response = tokenizer.decode(generated[0], skip_special_tokens=True)
print("生成的回答:", response)
# 模型合并
merge_model = p_model.merge_and_unload()
print("合并后的模型结构:", merge_model)
# 验证合并模型效果
ipt_merged = tokenizer("Human: {}\\n{}".format("考试有哪些技巧?", "").strip() + "\\n\\nAssistant: ", return_tensors="pt")
merged_response = tokenizer.decode(
merge_model.generate(
**ipt_merged,
max_length=1024, # 保持总长度限制
max_new_tokens=500, # 新增关键参数:控制新生成token数量
do_sample=True, #启用采样,让生成结果更多样化(否则可能总是生成最可能的词)。
temperature=0.8, # 提高随机性 (0.7-1.0)
top_p=0.9, # 核采样增加多样性
repetition_penalty=1.2,# 抑制重复同时允许合理扩展
early_stopping=False # 防止过早停止
)[0],
skip_special_tokens=True
)
print("合并模型生成的回答:", merged_response)
# 保存完整模型
merge_model.save_pretrained("./chatbot/merge_model")
print("模型已保存至:", "./chatbot/merge_model")总结
-
1. LoRA的核心思想:
冻结原始模型参数,只在特定层旁边添加两个小的矩阵(A和B)并进行训练,用 B*A 近似模拟所需的模型调整。 -
2. 代码体现
-
•
LoraConfig:定义哪些层要加适配器 (target_modules),适配器的秩r是多少等。 -
•
get_peft_model把 LoRA 配置应用到原始模型上,返回PeftModel。 -
•
model.print_trainable_parameters():可训练参数大大减少。 -
• 训练时 (
trainer.train()) 只更新这些少量参数。 -
• 推理时 (
model.generate()):自动结合原始权重和LoRA适配器的效果。
-
-
3. 优势: 训练快、省显存、模型存储小、任务切换方便,效果有保障。

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









