






作者:Reku
原文:https://zhuanlan.zhihu.com/p/21525151726
DualPipe是DeepSeek V3里面infra部分的重头戏,既能减少bubble还能做到通信掩盖,整个编排方式看起来神乎其技。而且对于一些国产芯片复现DeepSeek V3(FP8很难用起来、也没法用SM去控制网卡),DualPipe几乎是论文里面infra部分唯一能参考的优化点。我用我半吊子的大模型并行知识,猜想一下这个东西是怎么构造出来的,以及落地上可能遇到的难度。
动机猜想
对于DeepSeek V3,性能的最大瓶颈就是正反向里面巨大的AllToAll通信,根据论文里面的说法,计算和通信大概是1:1的水平。而且整体拓扑关系是attention->alltoall->mlp->alltoall这样的顺序,前后有严格的依赖,根本没什么掩盖空间。
对于这种类型的通信,比较常见的做法是bs或者seq维度切一切,把1层拆成两个没有数据依赖的小层,互相做掩盖,类似下图:
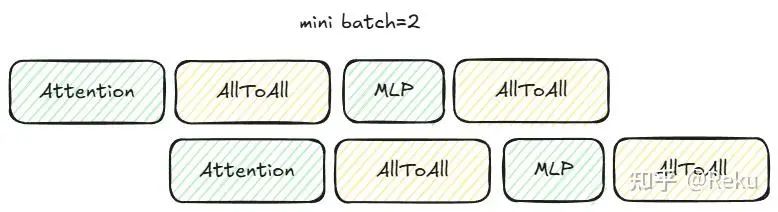
但是每个micro的bs为了省activation的显存,基本都是1;切seq的话,MLP会被切小,可能导致算子本身性能下降,都不算是最好的做法。
这是两个正向或者两个反向互相做掩盖的场景,如果这个不好搞的话,就可能会想到,一个正向和一个反向能不能做掩盖,因为对于1f1b的调度来说,一定有正反向交替的阶段:
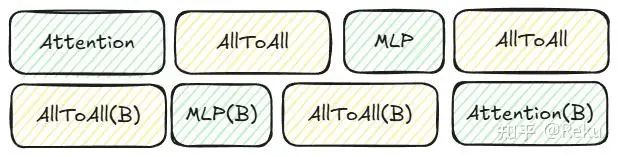

画一画,会发现不怎么对劲,如果强行掩盖相邻部分的正反向通信,会导致bubble变的巨大:

那现在的问题就是,需要一个合适的pipeline排布,既可以正反向做掩盖,bubble也不会增大。估计DeepSeek的大神们很快想到了Chimera,因为这个是双向的pp,上面rank灌进来的micro和下面rank灌进来的micro,相互之间的依赖关系没有这么重,如果相邻的正反向是不同方向的micro,是可以掩盖起来的,而且不会增大bubble:
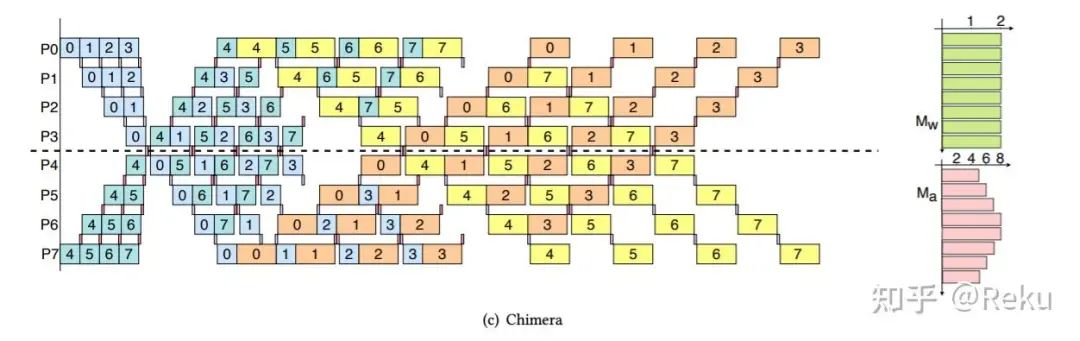
想象一下上面的图micro再多一点
结合上zero bubble的优化点,把dw拆出来,最后就形成了DualPipe:

一些问题
DualPipe的编排相比最常用的pp或者vpp甚至zero bubble,都复杂许多,想在工程落地会有很多问题:
-
• 实现逻辑的就很复杂。我不确定他们这个20micro的排布是基于策略写出来的还是基于一套算法搜出来的,想泛化感觉很不容易。
-
• 因为pp的编排复杂,会导致在超大集群下类似精度对比(需要沿着stage往上找输入)、快慢卡识别(会沿着pp传递)、首报错节点识别(要分析通信关系)都变的复杂很多。可能DeepSeek V3用的是2048卡,还不够大,这些问题还没那么重要,上了万卡规模,这些东西定位起来都很痛苦。
-
• 因为是双向的pp,需要每个rank放两个stage,导致param要翻个两倍。这个对于国产芯片可能很致命,显存没有那么多不说,暂时还不能用fp8训练,雪上加霜。
抛砖引玉
虽然普通的pp不行,但是对于vpp来说,很多地方都是可以做掩盖的:
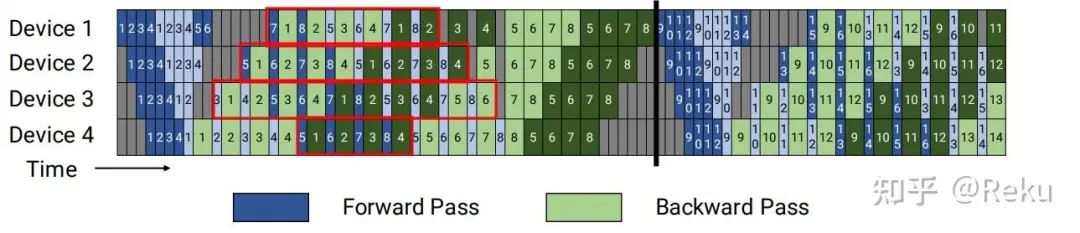
红框标注的地方都可以掩盖,而且这个方式相比普通的vpp显存没有任何增加,实现逻辑也比DualPipe简单多了,感觉是个比较靠谱的落地方向。
或者更本质的,能不能用类似FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion[1]的思路搞一个AllToAll MLP AllToAll的融合算子,这样对上层业务来说是最轻松的。但这个领域不太熟,不确定能不能做到。
引用链接
[1] FLUX: Fast Software-based Communication Overlap On GPUs Through Kernel Fusion: https://arxiv.org/abs/2406.06858

















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









