







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯使用计算机视觉技术分析学生课堂行为的实时监测系统
项目背景
在教育领域,学生的课堂行为对学习效果有着重要影响。研究表明,学生在课堂上的注意力、参与度和行为表现与学习成果密切相关。传统的课堂观察方法通常依赖教师的主观判断,难以实现客观、全面的行为分析。随着计算机视觉和深度学习技术的发展,建立一个自动化的课堂行为监测系统显得尤为重要。该系统可以实时捕捉和分析学生的行为状态,例如抬头、低头及四周观察等,帮助教师及时了解学生的注意力和参与情况,从而改进教学策略,提升教学效果。这不仅有助于推动教育技术的发展,也为教育管理提供了数据支持和决策依据。
数据集
在制作学生课堂行为数据集的过程中,首先需要进行图像采集。可以选择自主拍摄和互联网采集两种方式。在实际课堂视频中截取图片,确保捕捉到真实的课堂场景和学生的自然行为。访问公开的教育视频或图片库,获取多样化的课堂行为图像,以丰富数据集的内容和样本量。

为了准确识别和分类学生的课堂行为,使用标注工具进行数据标注。通过labeling,为每一张图像添加标签,标明具体的行为类别,比如“举手发言”、“注意听讲”或“睡觉”等。标注的准确性直接影响到后续模型训练的效果。

数据集的划分与扩展是确保模型训练有效性的关键环节。通常将数据集划分为训练集、验证集和测试集,常见的比例为70%、20%和10%。为了进一步增强数据集的多样性,可以使用数据扩展技术,如旋转、翻转、缩放和颜色调整等方法,增加样本的数量和多样性,从而提高模型的鲁棒性和准确性。
设计思路
卷积神经网络是一种专门用于处理具有网格结构数据的深度学习模型,常用于分析视觉图像。卷积神经网络分为五层:数据输入层、卷积计算层、ReLU激励层、池化层和全连接层。
输入层对原始图像数据进行预处理,包括去均值、归一化和PCA等操作。卷积计算层是深度学习的重要组件,主要对输入数据进行卷积操作,提取和学习特征信息。每个卷积操作都需要随机生成的卷积核,通过滑动窗口的方式扫描数据,移动方式由定义的步长决定。卷积层的参数包括滤波器的大小、步长和填充方式,共同决定输出特征图的大小。滤波器的大小影响特征提取的复杂度,填充方式通常为边缘填充,以避免输出特征图尺寸过小而丢失重要信息。
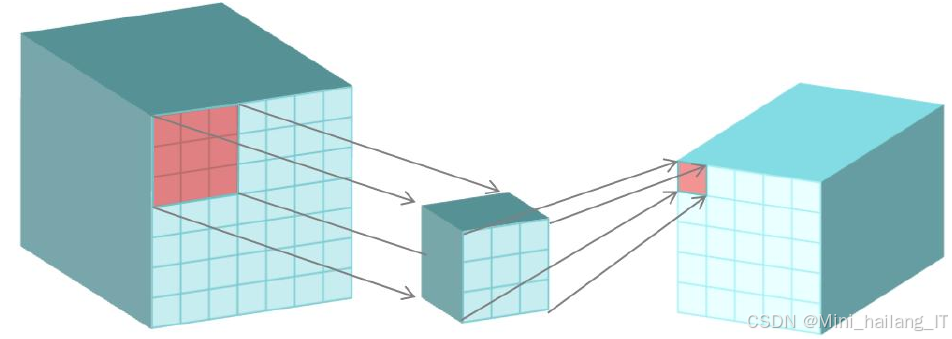
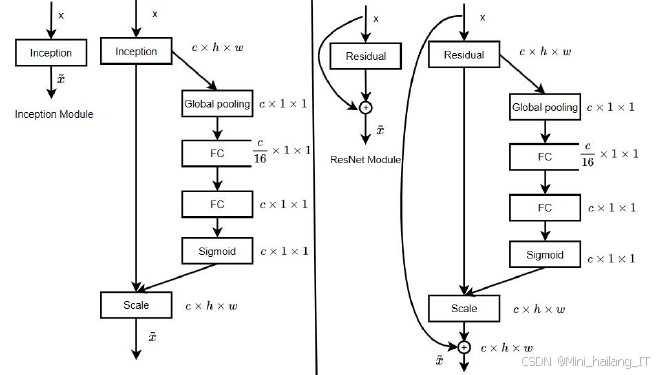
SENet是一种引入注意力机制的深度学习模型,主要用于提高卷积神经网络(CNN)在视觉任务中的性能。SENet的核心思想是通过自适应地重标定通道特征响应,从而强调重要特征并抑制不重要特征。具体来说,SENet通过两个主要步骤实现这一目标:压缩(Squeeze)和激励(Excitation)。在压缩阶段,网络对每个通道的特征图进行全局平均池化,生成一个通道描述符,汇聚了通道的信息。这个描述符反映了该通道在整个特征图中的重要性,为后续的激励阶段提供依据。
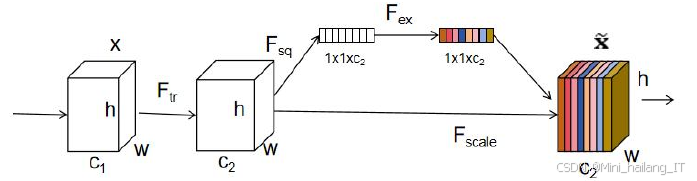
在激励阶段,SENet利用全连接层和激活函数(如Sigmoid)生成每个通道的权重。通过将这些权重与原始特征图的通道相乘,SENet能够动态调整每个通道的响应,强调更加重要的特征,抑制那些不太重要的特征。这样的机制使得网络能够自适应地关注于关键特征,从而提高模型的表现。SENet在多个视觉任务上,如图像分类、目标检测和图像分割等,均展现出了显著的性能提升,且可以与现有的网络架构无缝结合,增强其表达能力和特征学习效果。
学生课堂行为的数据。数据可以通过视频监控、摄像头采集或通过已有的公开数据集获取。收集到的视频数据需要经过预处理,包括去噪、剪辑和帧提取等,以便提取出每一帧的图像用于后续分析。为每一帧图像标注学生的行为,比如“举手”、“注意听讲”或“走动”。可以使用工具(如LabelImg或VGG Image Annotator)进行手动标注,也可以考虑半自动标注的方法,以提高效率。完成数据标注后,需要将数据集划分为训练集、验证集和测试集。这一步骤能够帮助模型评估其在未见数据上的泛化能力。通常的比例是70%用于训练,15%用于验证,15%用于测试。
import cv2
import os
def extract_frames(video_path, output_dir, frame_rate=1):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cap = cv2.VideoCapture(video_path)
count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if count % frame_rate == 0:
cv2.imwrite(os.path.join(output_dir, f"frame_{count}.jpg"), frame)
count += 1
cap.release()
extract_frames('classroom_video.mp4', 'output_frames', frame_rate=30)选择合适的深度学习模型(CNN)进行训练。定义模型结构后,使用训练集进行训练,并使用验证集进行实时监测,以调整超参数和防止过拟合。训练完成后,使用测试集对模型进行评估。根据评估结果,分析模型的性能,并进行必要的调优,例如调整学习率、增加正则化或尝试不同的网络架构。
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {test_accuracy:.4f}')将训练好的模型应用于实时监测系统中,通过摄像头实时捕捉课堂行为,并进行行为识别。这可以通过将图像输入到模型中,并输出相应的行为类别来实现。
def predict_class(frame):
processed_frame = preprocess(frame) # 预处理函数
predictions = model.predict(np.expand_dims(processed_frame, axis=0))
return np.argmax(predictions)
# 在实时视频流中使用预测函数
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
behavior = predict_class(frame)
# 处理和展示识别结果
# ...
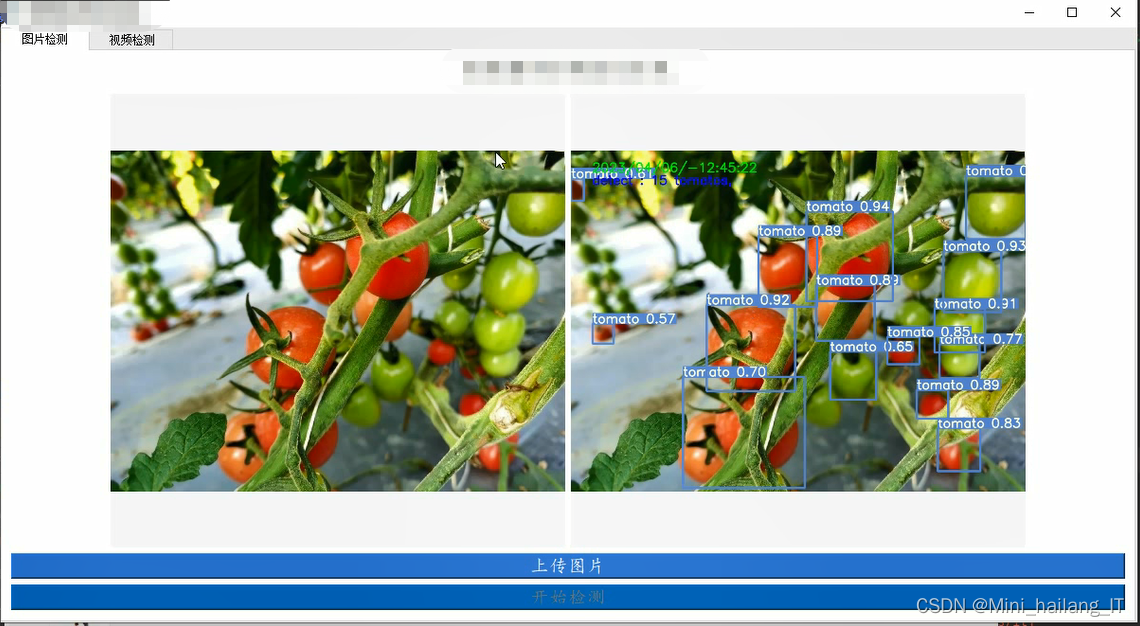
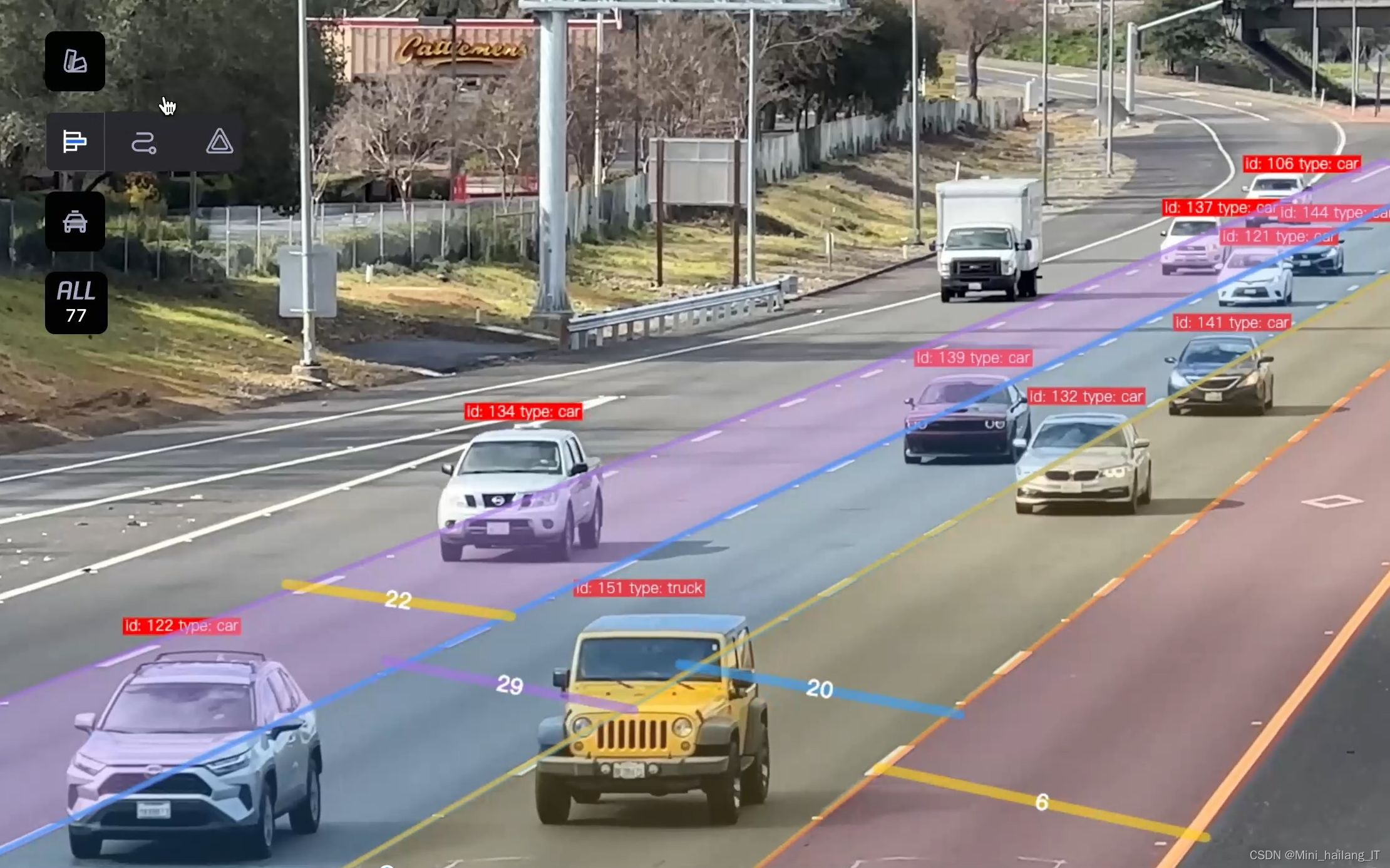
cap.release()海浪学长项目示例:




















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









