







论文信息
题目:Low-Light Image Enhancement via Generative Perceptual Priors
基于生成感知先验的低光照图像增强
作者:Han Zhou, Wei Dong, Xiaohong Liu, Yulun Zhang, Guangtao Zhai, Jun Chen
源码:https://github.com/LowLevelAI/GPP-LLIE
论文创新点
-
生成感知先验提取管道:作者提出了一种创新的管道,通过预训练的视觉语言模型(VLMs)提取低光照图像的全局和局部生成感知先验。该管道通过设计文本提示,引导VLMs评估图像的多个视觉属性(如对比度、可见性和清晰度),并通过基于sigmoid的量化策略将这些评估结果量化为全局评分和局部质量图。
-
基于Transformer的扩散框架:作者开发了一种高效的基于Transformer的扩散框架(GPP-LLIE),用于低光照图像增强。
-
全局感知先验调制的层归一化(GPP-LN):作者提出了一种新的层归一化方法,通过全局感知先验调制层归一化过程。该方法利用全局评分S来调整层归一化的缩放和偏移参数,从而更好地反映全局感知先验提供的感知洞察。
-
局部感知先验引导的注意力机制(LPP-Attn):作者设计了一种局部感知先验引导的注意力机制,通过局部质量图M引导注意力计算。
摘要
尽管在增强低光照(LL)图像的可见性、恢复纹理细节和抑制噪声方面取得了显著进展,但由于现实场景中复杂的光照条件,现有的低光照图像增强(LLIE)方法在实际应用中仍面临挑战。此外,生成视觉上逼真且吸引人的增强效果仍然是一个未被充分探索的领域。针对这些挑战,作者提出了一种新颖的LLIE框架,该框架通过视觉语言模型(VLMs)生成的生成感知先验(GPP-LLIE)进行指导。具体来说,作者首先提出了一种管道,引导VLMs评估LL图像的多个视觉属性,并将评估结果量化为全局和局部感知先验。随后,为了将这些生成感知先验融入LLIE中,作者在扩散过程中引入了一个基于Transformer的主干网络,并开发了一种新的层归一化(_GPP-LN_)和一种由全局和局部感知先验引导的注意力机制(_LPP-Attn_)。大量实验表明,该模型在成对的LL数据集上优于当前的最先进方法,并在现实世界数据上表现出优异的泛化能力。
关键字
低光照图像增强,生成感知先验,视觉语言模型,扩散模型,Transformer
III. 方法
本工作的主要重点是提取能够很好地表示LL图像视觉属性的生成感知先验,并开发由这些先验引导的LLIE模型,以生成逼真且视觉上吸引人的增强结果。整体框架如图3所示。

在本节中,作者首先讨论了利用视觉语言模型(VLMs)指导进行LLIE任务的动机(第3.1节)。然后,作者提出了一种创新的管道,引导VLMs全局和局部评估LL图像的视觉属性,并通过引入基于sigmoid的量化策略提取感知先验(第3.2节)。此外,作者开发了一种基于Transformer的扩散框架,并将这些先验融入其中以指导反向扩散过程(第3.3节)。
利用VLMs指导的动机
尽管最近的低光照图像增强(LLIE)方法表现出改进的性能,但在应用于现实世界图像时,它们通常会产生不平衡的结果,出现过曝伪影,这些图像的光照条件通常与训练数据集不同。这些结果突显了当前LLIE方法在多样化光照条件下自适应增强图像的普遍能力不足。因此,使模型能够自主感知并适应各种视觉失真至关重要。受最近新兴视觉语言模型(VLMs)在低层次视觉感知和理解方面展示的能力的启发,作者旨在探索利用这些VLMs的感知能力来促进LLIE任务的潜力。
从VLMs中提取生成感知先验
VLMs通常通过数百万个文本-图像对进行训练,并在生成文本和图像之间的对齐理解方面展示了显著的零样本能力。因此,利用VLMs中固有的先验信息来帮助LLIE模型在恢复过程中做出更合适的决策是非常有前景的。然而,最近图像恢复工作中使用的VLMs主要集中在理解图像的语义内容,但它们缺乏对视觉细节的精确表示。此外,准确描述复杂LL图像的内容具有挑战性。相比之下,作者在本工作中使用的VLMs是LLaVA,它进一步通过200K个与低层次视觉方面相关的指令-响应对进行了微调。在本文中,作者引入了一种新的管道,将LLaVA应用于LLIE:作者设计了文本提示,引导LLaVA评估LL图像的多个视觉属性。此外,与之前方法中的文本/图像嵌入不同,作者引入了量化策略,输出量化的全局评估和局部质量图作为LLIE的感知先验。作者提出的感知先验提取管道如图2所示。
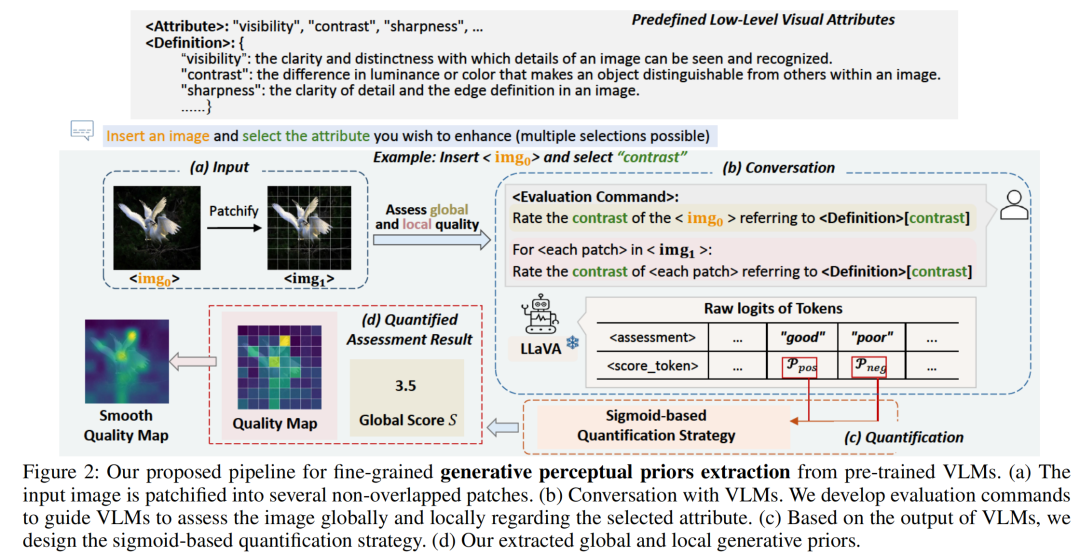
生成感知先验引导的扩散Transformer
为了在未见现实世界图像上实现增强的泛化能力,作者基于扩散Transformer(DiT)网络构建了LLIE模型,该网络与视觉Transformer(ViT)共享相似的架构,并具有良好的可扩展性。然而,DiT最初设计用于特定分辨率(如256*256或512*512)的图像合成,且ViT的计算复杂度随输入尺寸呈二次方增长。显然,原始的DiT不适用于LLIE任务,因为LLIE模型通常处理具有可变尺寸且有时较大分辨率的LL图像。为此,作者在扩散过程中引入了一种基于Transformer的主干网络,该网络适用于LLIE,并包含用于融入外部生成感知先验的特殊设计。


IV. 实验
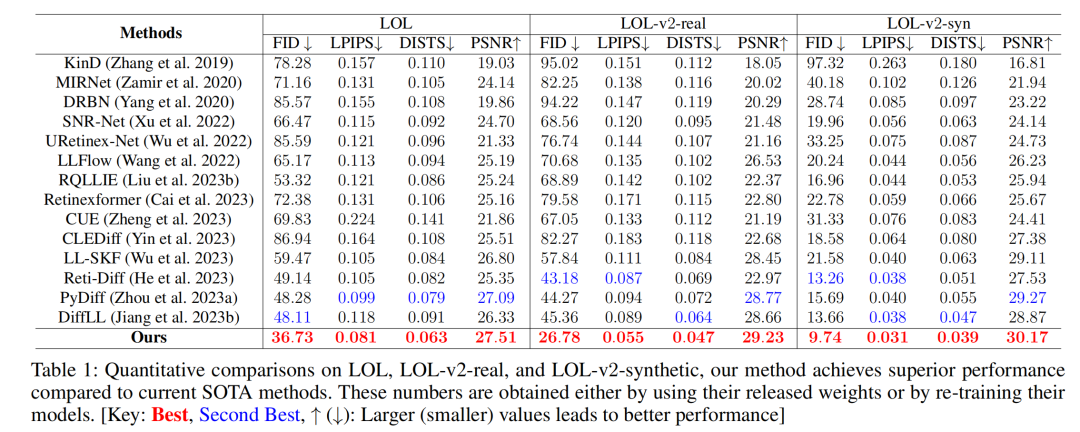

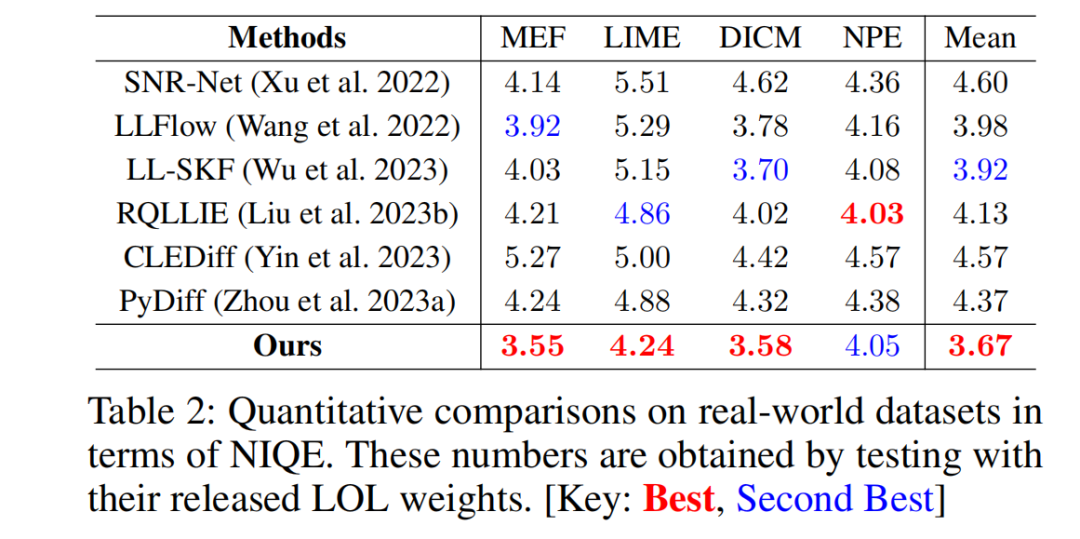



















 55
55

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









