









DeepSeek-VL: Towards Real-World Vision-Language Understanding 实现真实世界的视觉语言理解
2024.3.8


Abstract
We present DeepSeek-VL, an open-source Vision-Language (VL) Model designed for real-world vision and language understanding applications. Our approach is structured around three key dimensions: We strive to ensure our data is diverse, scalable, and extensively covers real-world scenarios including web screenshots, PDFs, OCR, charts, and knowledge-based content, aiming for a comprehensive representation of practical contexts. Further, we create a use case taxonomy from real user scenarios and construct an instruction tuning dataset accordingly. The fine-tuning with this dataset substantially improves the model’s user experience in practical applications. Considering efficiency and the demands of most real-world scenarios, DeepSeek-VL incorporates a hybrid vision encoder that efficiently processes high-resolution images (1024 x 1024), while maintaining a relatively low computational overhead. This design choice ensures the model’s ability to capture critical semantic and detailed information across various visual tasks. We posit that a proficient Vision-Language Model should, foremost, possess strong language abilities. To ensure the preservation of LLM capabilities during pretraining, we investigate an effective VL pretraining strategy by integrating LLM training from the beginning and carefully managing the competitive dynamics observed between vision and language modalities. The DeepSeek-VL family (both 1.3B and 7B models) showcases superior user experiences as a vision-language chatbot in real-world applications, achieving state-of-the-art or competitive performance across a wide range of visual-language benchmarks at the same model size while maintaining robust performance on language-centric benchmarks. We have made both 1.3B and 7B models publicly accessible to foster innovations based on this foundation model.
我们推出的 DeepSeek-VL 是一个开源的视觉语言(VL)模型,专为真实世界的视觉和语言理解应用而设计。
我们的方法围绕三个关键维度展开:
-
我们努力确保 数据的多样性和 可扩展性,并广泛涵盖现实世界的 各种场景,包括网页截图、PDF、OCR、图表和基于知识的内容,旨在全面呈现实际语境。
-
此外,我们还根据真实用户场景创建了 用例分类法,并据此构建了指令调整数据集。利用该数据集进行的微调大大改善了模型在实际应用中的用户体验。
-
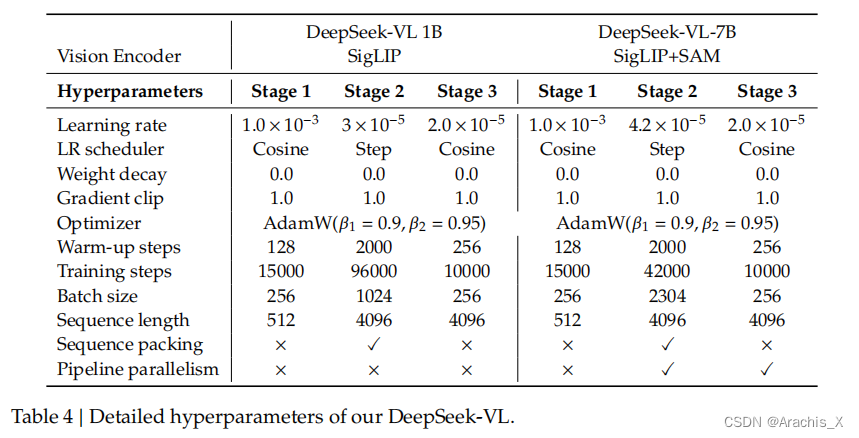
考虑到大多数实际应用场景的效率和需求,DeepSeek-VL采用了混合视觉编码器,可高效处理高分辨率图像(1024 x 1024),同时保持相对较低的计算开销。
这一设计选择确保了该模型在各种视觉任务中捕捉关键语义和细节信息的能力。
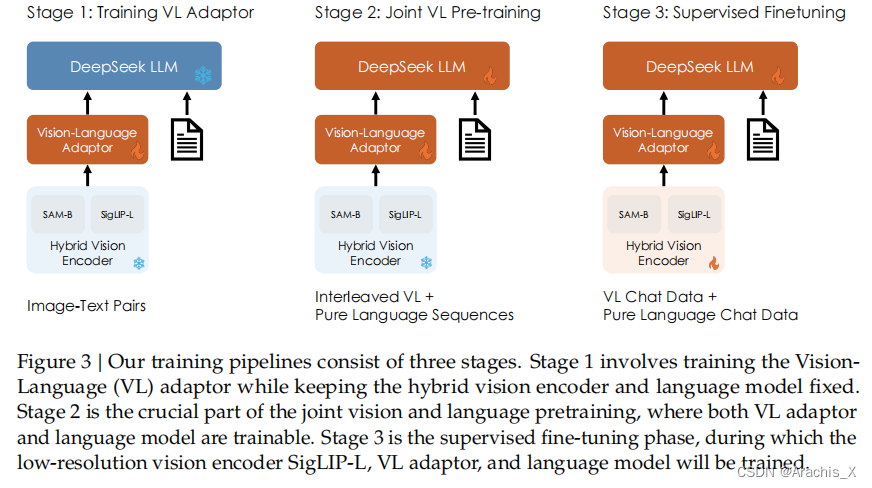
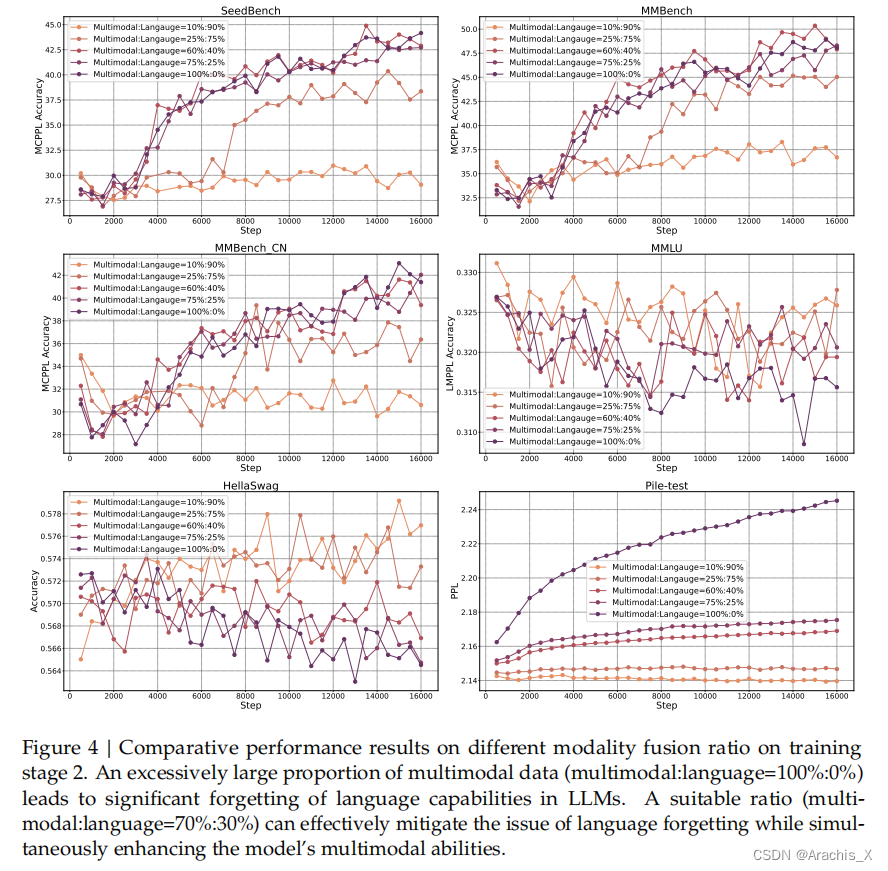
我们认为,一个熟练的视觉语言模型首先应具备强大的语言能力。为了确保在预训练过程中保留 LLM 的能力,我们研究了一种有效的VL 预训练策略,即从一开始就整合 LLM 训练,并仔细管理视觉和语言模式之间的竞争动态。
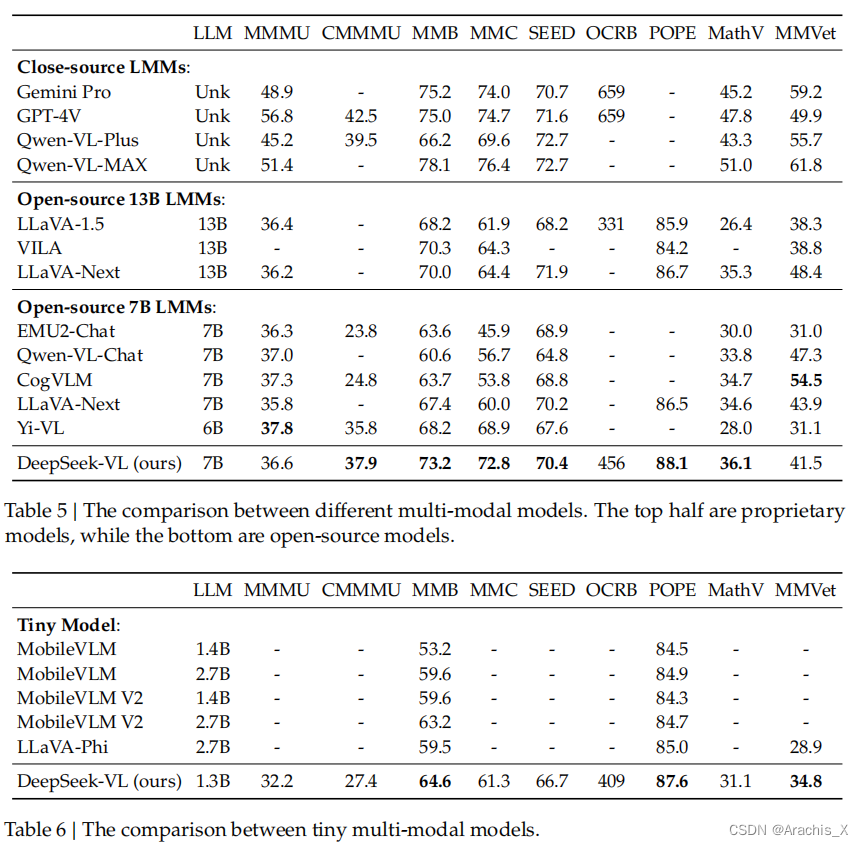
DeepSeek-VL 系列(包括 1.3B 和 7B 模型)作为视觉语言聊天机器人,在现实世界的应用中展示了卓越的用户体验,在相同模型大小的各种视觉语言基准测试中取得了最先进或具有竞争力的性能,同时在以语言为中心的基准测试中保持了强劲的性能。我们公开了 1.3B 和 7B 模型,以促进基于该基础模型的创新。
Model Downloads
Huggingface
| Model | Sequence Length | Download |
|---|---|---|
| DeepSeek-VL-1.3B-base | 4096 | 🤗 Hugging Face |
| DeepSeek-VL-1.3B-chat | 4096 | 🤗 Hugging Face |
| DeepSeek-VL-7B-base | 4096 | 🤗 Hugging Face |
| DeepSeek-VL-7B-chat | 4096 | 🤗 Hugging Face |
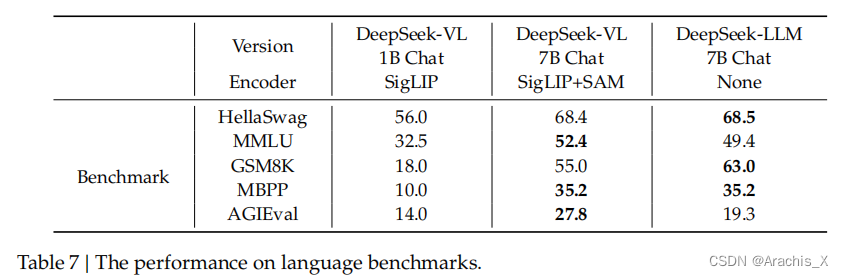
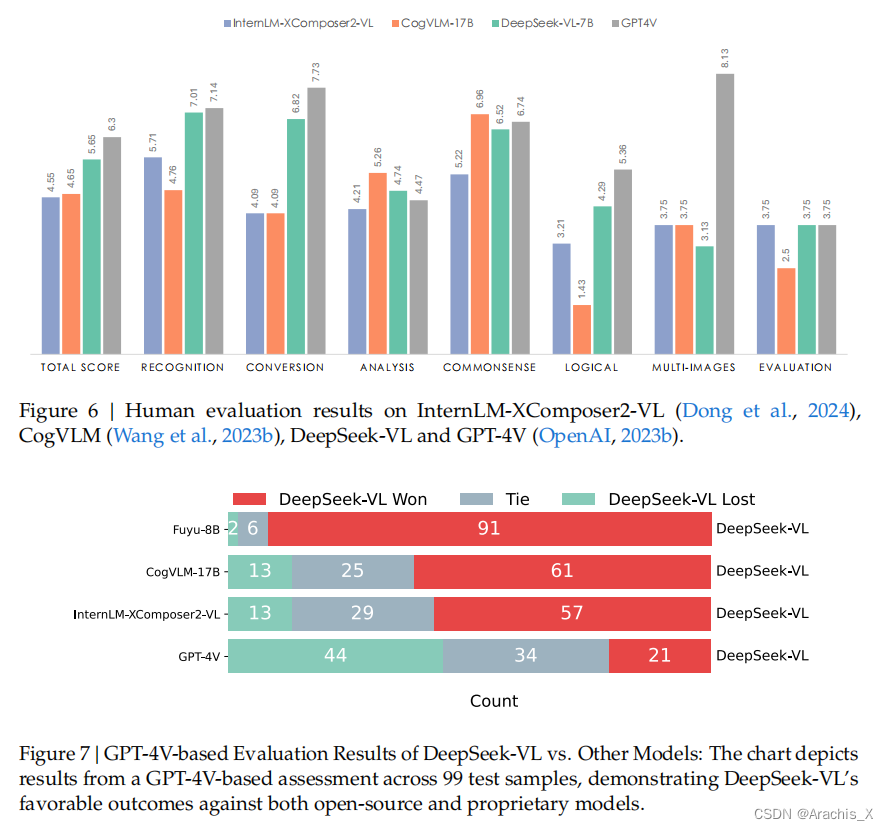
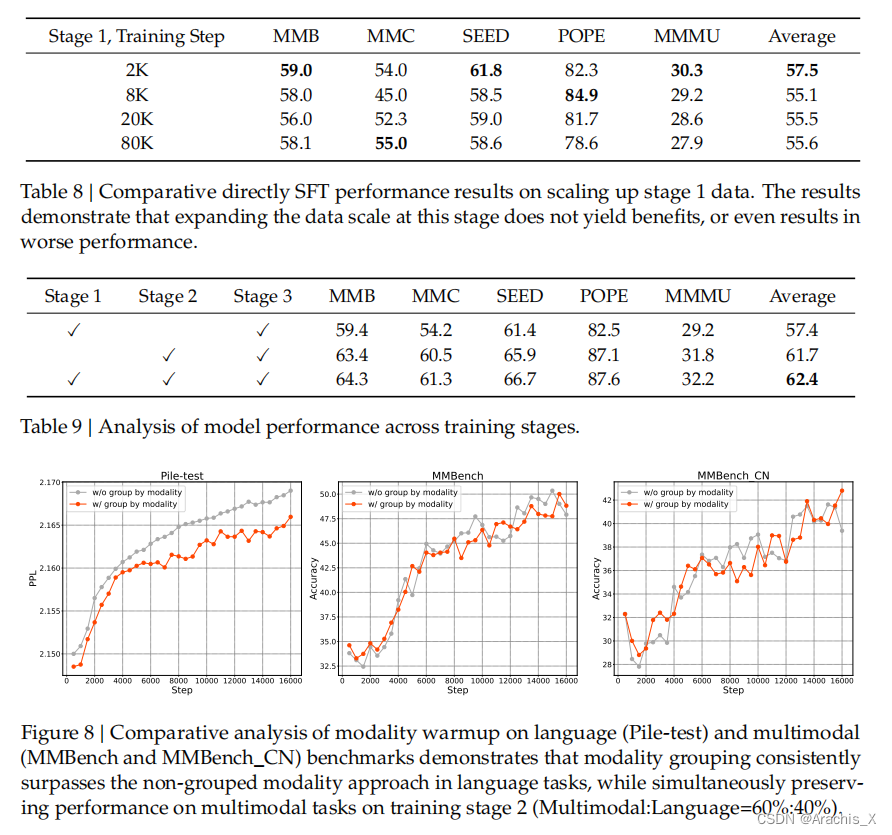
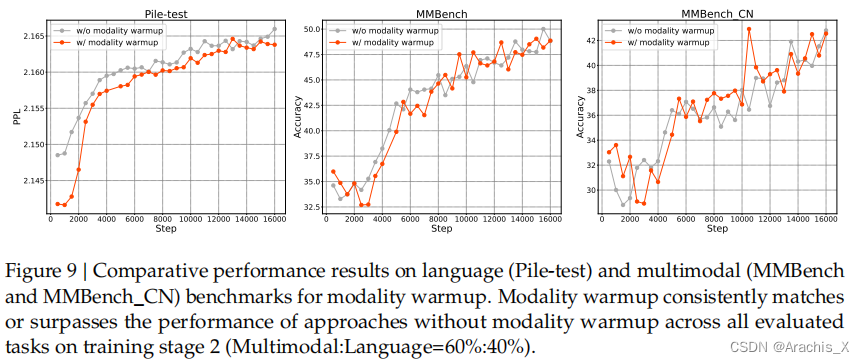
Results


Evaluation

















 3004
3004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









