






作者 | 王汝嘉 编辑 | 汽车人
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【语义分割】技术交流群
后台回复【分割综述】获取语义分割、实例分割、全景分割、弱监督分割等超全学习资料!
“论文:https://arxiv.org/pdf/2301.04275.pdf
代码:https://github.com/fengluodb/LENet
”

摘要
激光雷达的语义分割可以为车辆提供丰富的场景理解,是机器人和自动驾驶中感知系统的关键。本文提出了一种轻量级、高效的基于投影(projection-based)的LIDAR语义分割网络LENet,该网络具有encoder-decoder结构。该编码器由一组MSCA模块组成,该模块是一个简单的卷积注意力模块,用于捕捉多尺度特征图。该解码器由IAC模块组成,该模块利用双线性插值对多分辨率特征图进行上采样,并利用单个卷积层集成前一维和当前维特征。IAC非常轻量(very lightweight),大大降低了复杂度和存储成本。此外,本文引入了多个辅助分割头,进一步细化网络精度。本文进行了详细的定量实验,显示了每个组件对最终性能的贡献。本文在众所周知的公共基准(SemanticKITTI)上对本文的方法进行了评估,结果表明本文提出的LENet比目前最先进的语义分割方法更加轻量和有效(lightweight and effective)。
1.介绍
环境感知可以帮助车辆理解周围场景,这对自动驾驶至关重要。激光雷达和RGB摄像头是自动驾驶感知系统中常见的传感器。与摄像机相比,激光雷达传感器不受光照和天气条件的影响,因此更加鲁棒。同时,与二维图像相比,激光雷达点云能够准确地描述目标的结构,为车辆提供了对周围环境的几何精确描述。因此,三维点云分析越来越受到人们的重视。特别是,点云语义分割的目的是为每个点指定标签,帮助车辆获得对场景的丰富理解。因此,点云语义分割成为学术界和工业界的一个研究热点。
由于三维点云的无序性和不规则性,本文不能直接对其进行标准卷积神经网络。为了解决这一问题,在过去的一年里,人们对点云语义分割进行了广泛的研究。基于点的方法[2]-[5]直接从原始点云中提取特征,可以减少预处理过程中计算复杂度和噪声误差的影响。然而,它们通常具有较高的计算复杂度和有限的处理速度。基于体素的方法将不规则的点云转化为规则的网格表示,从而可以使用三维卷积网络。尽管基于体素的方法可以达到最先进的精度,但它们主要存在计算量大的问题,尤其是对于自动驾驶室外场景中的大规模激光雷达点云。基于投影的方法通过球面投影策略将原始点云转化为二维距离图像。与基于点的方法和基于体素的方法相比,基于投影的方法具有更快的推理速度和更好的精度性能。同时,由于全卷积网络在图像语义分割方面取得了巨大的成功,它们近年来受到了越来越多的关注。
在这项工作中,本文提出了一个轻量级和高效的基于投影的激光雷达语义分割网络。在著名的公共基准(SemanticKITTI)上的实验结果表明,本文的网络具有更高的精度性能,并能以,比先前的工作更少的参数实时运行。综上所述,本文的主要贡献如下:leftmargin=*
“提出了一种简单的多尺度卷积注意力模块(MSCA),该模块能够在激光雷达360度全扫描范围内捕捉不同尺寸物体的信息。
一种新的IAC模块,它使用双线性插值对多分辨率特征图进行上采样,并使用单个卷积层集成前一维和当前维特征。IAC重量很轻,大大降低了复杂度和存储成本。
通过引入多个辅助分割头,本文在不引入额外推理参数的情况下进一步细化了网络精度。
本文在公开可用的数据集SemanticKITTI[1]上进行了广泛的实验。结果表明,本文的方法达到了最先进的性能。
”
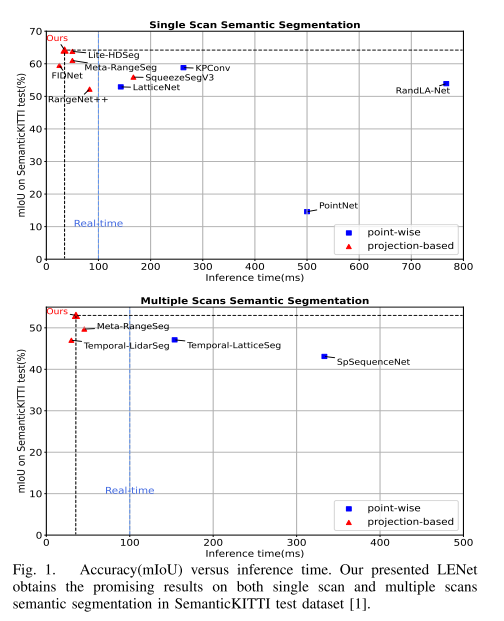
图 1. 精确度(mIoU)与推断时间的关系。在SemanticKITTI测试数据集[1]中,本文提出的LENet在单扫描和多扫描语义分割方面都取得了很好的结果。
2.相关工作
随着自动驾驶场景点云分割任务大规模数据集[1]、[6]、[7]的普及和深度学习的快速发展,近年来提出了多种基于深度学习的3D LiDAR点云语义分割方法。通常,根据输入数据的表示形式,它们可以大致分为点、体素和距离图三大类(point, voxel and range map)。
**Point-based methods **直接对原始的三维点云进行处理,不需要进行任何额外的变换或预处理,能够较好地保留三维空间的结构信息。这个小组的开创性方法是PointNet[2]和PointNet++[3],它们使用共享MLPs来学习每个点的特性(properties)。在随后的一系列工作中,KPConv[8]发展了可变形卷积,它可以使用任意数目的核点(kernel points)来学习局部几何。然而,这些方法都存在计算复杂度高、内存消耗大的缺点,阻碍了它们在大规模点云计算中的应用。RandLA-Net[5]采用随机抽样策略,并利用局部特征聚集来减少随机操作带来的信息损失,大大提高了点云处理的效率,减少了内存消耗。
Voxel-based Methods 将点云转化为体素进行处理,可以有效地解决不规则性问题。早期的基于体素的方法首先将点云转化为三维体素表示,然后利用标准的三维CNN预测语义标记。然而,常规的三维卷积需要巨大的内存和繁重的计算能力。Minkowski[9]CNN选择使用稀疏卷积代替标准的3D卷积等标准神经网络来降低计算代价。Cylinder3D[10]采用三维空间划分,并设计了非对称残差块以减少计算量。AF2S3Net[11]实现了体素方法的SOTA,提出了两个新的注意力块,即注意力特征聚焦模块(AF2M)和自适应特征聚焦模块(ASFM)来有效地学习局部特征和全局上下文。
Projection-based Methods 将三维点云投影到二维图像空间,可以利用大量用于进行图像特征提取的高级层(advanced layers)。SqueezeSeg[12]提出了球面投影法,将散射的三维激光点映射成二维Range-Image,然后利用轻量级模型SqueezeNet和CRF进行分割。随后,SqueezeSegV2[13]提出了上下文聚合模块(CAM)来聚合来自更大感知场的上下文信息。RangeNet++[14]将DarkNet集成到SqueezeSeg中,提出了一种高效的KNN后处理方法来预测点的标签。SqueezeSegV3[15]提出了根据输入图像的位置采用不同滤波器的空间自适应卷积(SAC)。SalsaNext[16]继承了SalsaNet[17]的编码器-解码器体系结构,并提出了一种用于点特征学习的不确定性感知机制。Lite-HDSeg[18]通过引入三个不同的模块,即Inception-like上下文模块、多类空间传播网络和边界损失,实现了最先进的性能。
3.方法
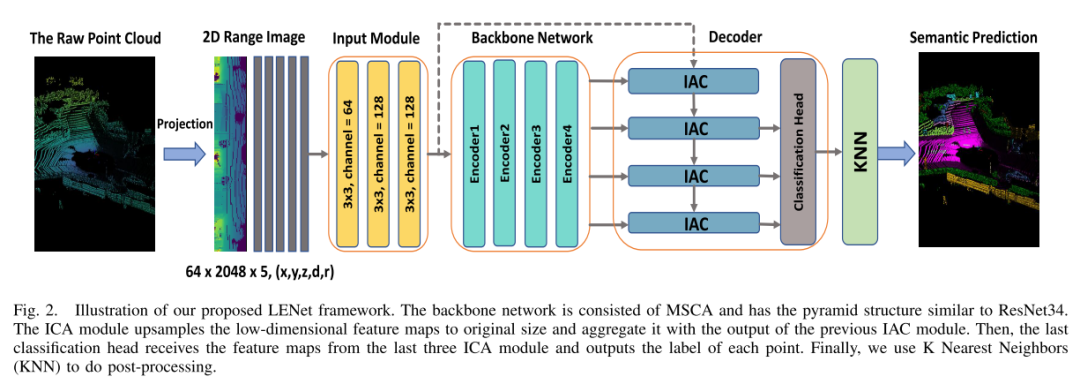
图 2. 本文的提出的LENet框架的插图。骨干网由MSCA组成,采用类似RESNET34的金字塔结构。IAC模块将低维特征图向上采样到原始大小,并将其与先前IAC模块的输出聚合。然后,最后一个分类头接收来自最后三个IAC模块的特征图,并输出每个点的标签。最后,本文使用K近邻(KNN)进行后处理。
A.距离图像表示. Range Image Representation.
利用球面投影方法,本文可以将非结构化的点云转化为有序的距离图像表示。距离表示的优点在于它可以利用有效的二维卷积运算进行快速的训练和推理,并且它可以促进(facilitate)已经在基于图像的任务中被充分研究的成熟深度学习技术。
在距离图像(range image)表示中,每个激光雷达点p=(x,y,z)具有笛卡尔坐标,球面映射用于将其转换到图像坐标,如下所示:
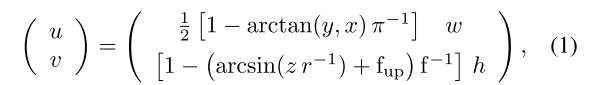
其中(u,v)是图像坐标,(h,w)是所需距离(range)图像表示的高度和宽度,是传感器的垂直视场,是每个点的距离(range)。
###B.卷积注意力编码器 Convolution Attention Encoder
多尺度特征在语义分割中起着重要的作用,因为语义分割任务通常需要处理单个图像中不同大小的对象。提取多尺度特征的一种常见方法是使用具有不同感受野的一组卷积的组合,然后融合这些感受野,如[16]。受SegNext[19]的启发,本文提出了一种新的多尺度卷积注意力模块(MSCA)。
如图3(b)所示,MSCA包括三个部分:聚合局部信息的深度(depth-wise)卷积,捕获多尺度上下文的多分支depth-wise strip卷积,以及建模不同通道之间关系的1×1卷积。最后,将1×1卷积的输出直接作为注意力权重,对MSCA的输入进行重新加权。此外,本文的编码器采用金字塔结构,编码器中的构造块(building block)由3×3卷积层和MSCA组成,如图3(a)所示。
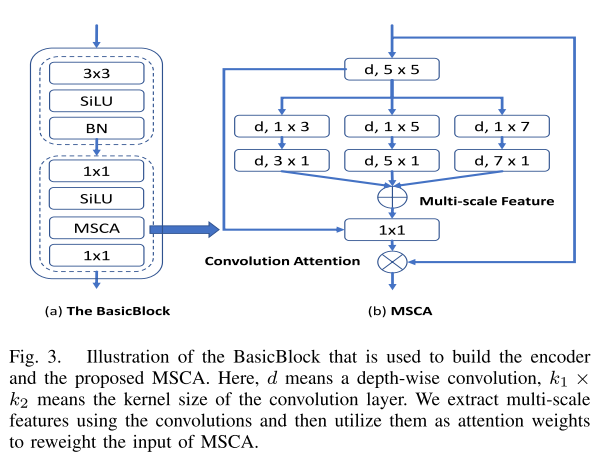
图 3. 用于构建编码器和提出的MSCA的BasicBlock的说明。这里,d表示深度方向的卷积,k1×k2表示卷积层的核大小。利用卷积提取多尺度特征,并将其作为注意力权重对MSCA的输入进行重新加权。
C. IAC Decoder
为了设计一个简单有效的解码器,本文研究了几种不同的解码器结构。在[14]-[16]中,他们使用标准的转置卷积(standard transpose convolutions)或pixel-shuffle来产生上采样的特征图,然后使用一组卷积来解码特征图,这是有效的,但计算量很大。在FIDNet中,它的解码器使用FID(fully interpolation decoding)对不同层次的语义进行解码,然后使用分类头对这些语义进行融合。虽然FID是完全无参数的,但它不具备从特征中学习的能力,这使得模型的性能过分依赖于分类头。另外,FIDNet的分类方法融合了太多的底层(low-level)信息,影响了性能。
在这项工作中,本文提出了一个轻量级解码器,如图2所描述的。IAC模块包括两个部分:对来自编码器的特征图进行双线性插值,对来自编码器的信息进行3×3卷积,将来自编码器的信息与前一个IAC信息融合。最后,本文使用逐点卷积来融合最后三个IAC模块的特征。在三种不同的解码器中,本文的解码器参数最少,性能最好。
D. 损失函数 Loss Function
在这项工作中,本文用三种不同的损失函数训练提出的神经网络,即加权交叉熵损失、Lovasz损失和边界损失。最后,本文的总损失如下:
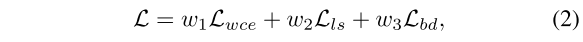
三个损失函数解释(account)了三个不同的问题。针对类不平衡的问题,采用加权交叉熵损失[32]来最大限度地提高点标签(point labels)的预测精度,使不同类之间的分布趋于平衡。它被定义为
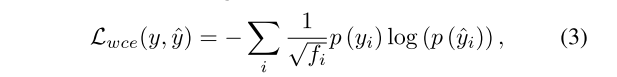
为了解决intersection-over-union(IOU)的优化问题,本文利用lovasz loss [33]来最大化语义分割性能验证中常用的intersection-over-union(IOU)得分。它被定义为:
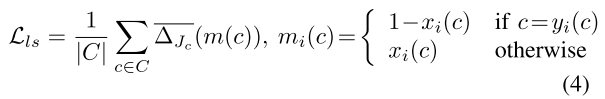
为了解决文献[18]、[28]、[35]中提出的分割边界模糊问题,将边界损失函数[34]用于激光雷达语义分割,其定义如下:
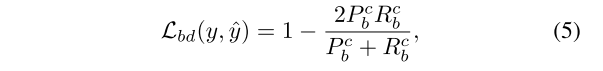
其中和为 class c 定义了预测边界图像对真实边界图像的精度和召回率(precision recall)。边界图像计算如下:
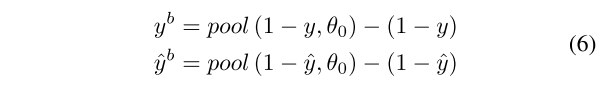
在本文的提出的网络中,分类头融合后三个不同维度的特征映射来进行输出,这使得分类头的性能在很大程度上依赖于后三个IAC模块。因此,本文使用辅助分割头进一步细化本文提出的网络精度。这些辅助分段头计算加权损失和主损失。同时,由于不同维度的特征图具有不同的表现力,每个损失都有相应的权重,这与[15]、[35]不同。最终损失函数可以定义为
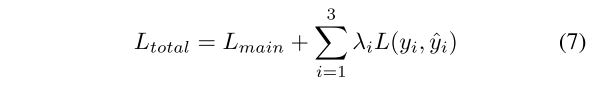
E. Implementation details.
本文使用Pytorch[36]来实现本文的方法,并在一台有4个NVIDIA RTX 3090 GPU的PC上进行所有实验。本文对网络进行50个epoch的训练,初始学习速率为,由cosine annealing scheduler动态调整[37]。批量大小设置为8,距离(range)图像的高度和宽度分别设置为H=64和W=2048。优化器是Pytorch中默认配置的AdamW[38]。在训练过程中,采用random rotation, random point dropout, and flipping the 3D point cloud 来进行数据增强。
4.实验
A.实验设置
数据集。 本文在面向自动驾驶场景点云分割任务的大规模数据集SemanticKITTI DataSet上训练和评估本文的网络。它为KITTI Odometry[39]基准中的22个序列(43,551次扫描)提供了稠密逐点标注。序列00至10(19,130次扫描)用于训练,11至21(20,351次扫描)用于测试。本文遵循[1]中的设置,并使用序列08(4,071次扫描)进行验证。为了评估本文提出的方法的有效性,本文将输出提交到在线验证网站上,以获得测试集上的结果。
验证指标。 为了使比较更加公平,本文根据(mIoU)来评估不同方法的性能,其定义如下:

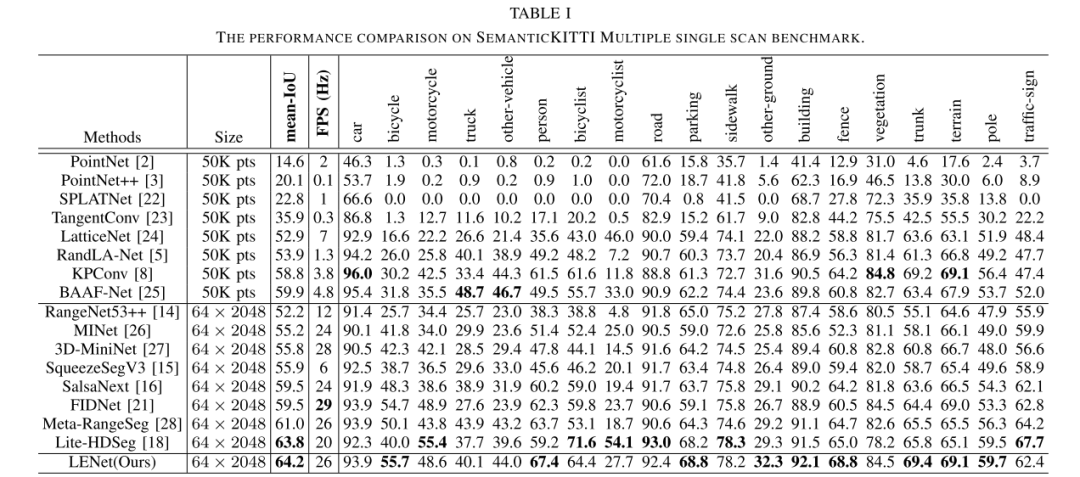
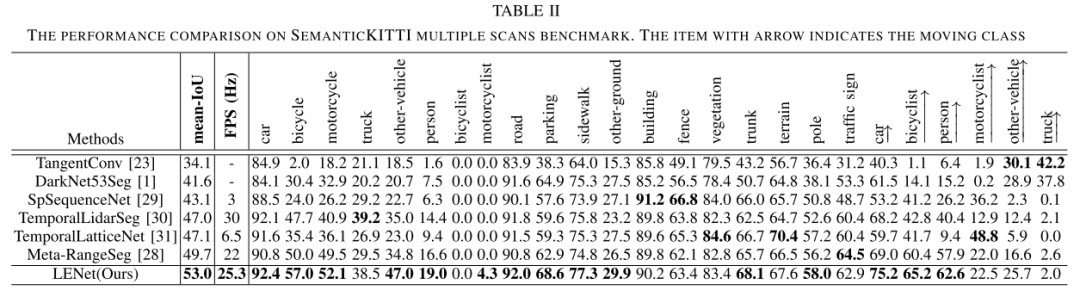
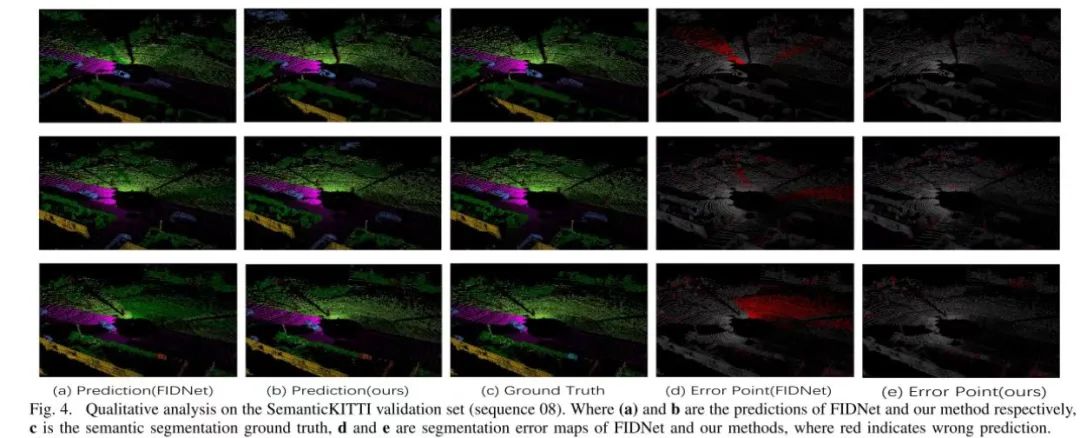
图 4. 对SemanticKITTI验证集的定性分析(序列08)。其中(a)和b分别为FIDNet和本文的方法的预测,c为语义分割基础真值,d和e为FIDNet和本文的方法的分割错误图,红色表示错误预测。
B.验证结果和比较
表一和表二分别显示了在SemanticKITTI单扫描基准和多扫描基准上最近可用和发布的方法的定量结果。从表中可以看出,在单扫描基准(64.2%mIoU)和多扫描基准(53.0%mIoU)下,本文提出的方法与基于点和基于图像的方法相比,达到了最先进的性能。与此同时,值得一提的是,本文的提出的网络非常轻量级,参数约为47m,速度为26fps,同时保持高精度。
为了更好地显示本文提出的模型在基线上的改进,本文在图4中提供了定性比较示例,比较了FIDNet和LENet在三个数据帧中的预测结果和生成的误差图。可以看出,本文提出的方法比FIDNet有了很大的改进。
C.消融研究
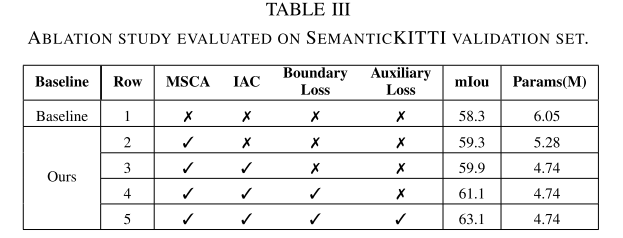
本文在SemanticKITTI验证集(序列08)上进行了几个消融实验,以检查本文提出的网络中每个单独模块的改进。对于各设置的验证,输入距离图像的大小为64×2048,输入距离图像的通道为5。表III显示了在SemanticKITTI验证集上具有相应mIoU得分的模型参数的总数。
为了公平比较,本文首先将FIDNet作为基线方法,它与本文的网络结构相似。接下来,本文在第三节用提出的MSCA和IAC替换基线。最后,本文将边界损失和辅助损失一一相加,来检验它们对本文网络的有效性。如表III所示,当替换基线的基本块时,本文的网络获得了1.0%以上的精度提高,说明多尺度卷积注意力是有效的。其次,在更换原解码器后,IAC的性能优于网络约1.0%。此外,边界损失达到1.2%以上的性能增益,辅助损失增益达到2.0%以上的性能跃迁。最后,与基线相比,本文提出的LENet方法有超过4.8%的改进和约25%的参数减少,这证明了每个模块的有效性。
5.总结
本文提出了一种用于激光雷达点云分割任务的轻量级、高效的实时CNN模型LENet。首先,采用基于多尺度卷积注意力模块的编码器来更好地捕捉激光雷达数据中不同尺寸目标的特征。然后,本文提出了一个简单有效的上采样解码器,大大降低了复杂度和存储成本。最后,在不引入参数和效率代价的情况下,通过嵌入多个辅助分割头对网络进行训练,进一步提高了学习特征的能力。对SemanticKITTI测试数据集的评价表明,本文提出的方法在单扫描和多扫描语义分割方面都达到了最先进的性能。
6.参考
[1] Ding B. LENet: Lightweight And Efficient LiDAR Semantic Segmentation Using Multi-Scale Convolution Attention[J]. arXiv preprint arXiv:2301.04275, 2023.
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









