






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到Garfield分享单目3D检测的四大类方法,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
3D 物体检测是自动驾驶的关键任务。自动驾驶的许多重要领域,如预测、规划和运动控制,通常需要完美地表示自车周围的 3D 空间。

近年来,研究人员一直在利用高精度激光雷达点云进行精确的 3D 物体检测(特别是在 PointNet 的开创性工作展示了如何直接 用神经网络操纵点云)。然而,激光雷达有其缺点,例如成本高和对恶劣天气条件敏感。使用 RGB 相机执行单目 3D 目标检测的能力也增加了模块冗余,以防其他更昂贵的模块出现故障。因此,如何仅用一张或多张RGB图像进行可靠、准确的3D感知,仍然是自动驾驶感知的制胜法宝。
如何将 2D任务提升为3D任务?
从 2D 图像检测 3D 对象是一项具有挑战性的任务。它基本上是不适定的,因为深度维度的关键信息在 2D 图像的形成过程中被压缩。然而,在特定条件下和具有强大先验信息的情况下,此任务仍然易于处理。特别是在自动驾驶中,大多数感兴趣的物体,例如车辆是具有已知几何形状的刚性物体,因此可以使用单目的图像恢复 3D 车辆信息。
1. Representation transformation (BEV, pseudo-lidar)
摄像头通常安装在一些原型自动驾驶汽车的车顶上,或者像普通行车记录仪一样安装在后视镜后面。因此,相机图像通常具有世界的perspective views。这种视图对于人类驾驶员来说很容易理解,因为它类似于我们在驾驶过程中所看到的,但对计算机视觉提出了两个挑战:由于距离造成的遮挡和尺度变化。
缓解这种情况的一种方法是将透视图像转换为Birds-eye-view 鸟瞰图 (BEV)。在 BEV 中,汽车具有相同的尺寸,与自我车辆的距离不变,并且不同的车辆不重叠(假设在正常驾驶条件下 3D 世界中没有汽车位于其他汽车之上的合理假设)。逆透视映射 (IPM) 是生成 BEV 图像的常用技术,但它假设所有像素都在地面上,并且相机已知准确的在线外部(和内部)信息。然而,外部参数需要在线校准才能足够准确以用于 IPM。

Orthographic Feature Transform (OFT) (BMVC) 这是将perspective views提升为 BEV 的另一种方法,但要通过深度学习框架。这个想法是使用正交特征变换 (OFT) 将基于透视图像的特征映射到正交鸟瞰图中。ResNet-18 用于提取透视图像特征。然后通过在投影体素区域上累积基于图像的特征来生成基于体素的特征。然后沿着垂直维度折叠体素特征以产生正交地平面特征 . 最后,使用另一个类似 ResNet 的自顶向下网络来推理和改进 BEV 映射。
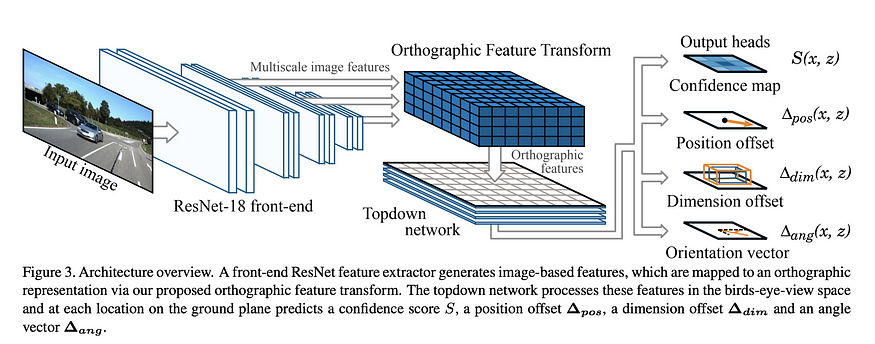
OFT的思路真的很简单,也很有趣,效果也比较好。尽管可以通过使用一些启发式方法更好地初始化基于体素的特征来改进反投影步骤,而不是天真地进行反投影。例如,一个非常大的 bbox 中的图像特征无法对应到非常远的物体。我对这种方法的另一个问题是准确的外在假设,这可能无法在线获得。
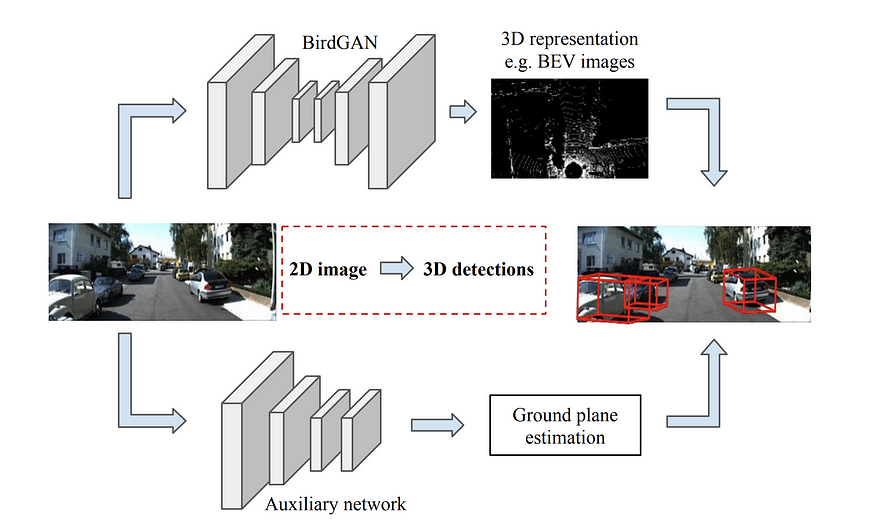
另一个方法是BirdGAN (IROS), 它使用 GAN 执行图像到图像的转换。该论文取得了很好的效果,但正如该论文所承认的那样,转换到 BEV 空间只能在正面距离只有 10 到 15 米的情况下表现良好,因此用途有限。
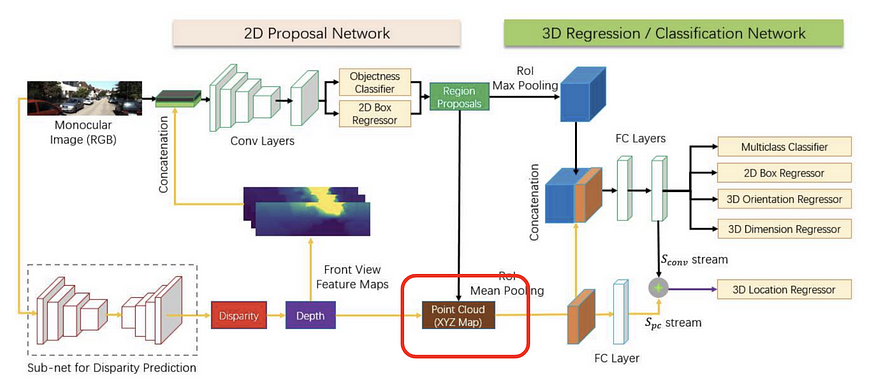
然后输入关于伪激光雷达想法的一系列工作。这个想法是根据图像的估计深度生成点云,这要归功于最近在单目深度估计(这本身就是一个热门话题)方面的进步 自动驾驶中的主题,我将在未来回顾)。以前使用 RGBD 图像的努力主要将深度视为第四个通道,并将普通网络应用于此输入,对第一层的变化很小。Multi-Level Fusion (MLF, CVPR 2018) 是最早提出将估计的深度信息提升到 3D。它使用估计的深度信息(通过 MonoDepth 固定的预训练权重)将 RGB 图像中的每个像素投影到 3D 空间,然后将生成的点云融合 具有图像特征以回归 3D 边界框。
Pseudo-lidar (CVPR 2019) is perhaps the most well-known among this line of work. It is inspired by MLF and uses the generated pseudo-lidar in a more brute-force way, by directly applying state-of-the-art lidar-based 3D object detectors. The authors argue that representation matters, and convolution on depth map does not make sense, as neighboring pixels on depth images may be physically far away in 3D space.

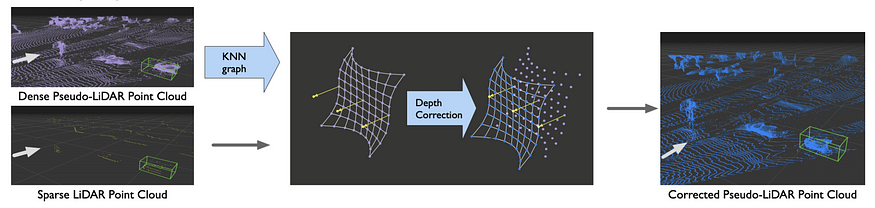
pseudo-lidar 的作者跟进了 Pseudo-lidar++。主要的改进是生成的伪激光雷达点云现在可以通过来自低成本激光雷达的稀疏但准确的测量值来增强(尽管它们模拟了激光雷达数据)。用相机图像和稀疏深度测量生成密集 3D 表示的想法在自动驾驶中非常实用,我希望在未来几年看到更多沿着这条路线的工作。
还有一些跟进并改进了原始的伪激光雷达方法。Pseudo-Lidar Color (CVPR 2019) 通过与颜色信息融合,通过普通连接 (x, y, z) 增强伪激光雷达的概念 ) → (x, y, z, r, g, b) 或基于注意力的门控方法来选择性地传递 rgb 信息。该论文还基于 Frustum PointNet (CVPR 2018) 的概念和平截头体中的平均深度,使用了一种简单而有效的点云分割方法。Pseudo-Lidar end2end (ICCV 2019) 强调了伪激光雷达方法的瓶颈有两个:局部错位由 深度估计的不准确性和由物体外围的深度伪影引起的长尾(边缘出血)。他们通过使用实例分割掩码代替 Frustum PointNet 中的 bbox 扩展了伪激光雷达的工作,并引入了 2D/3D 边界框一致性损失的思想。ForeSeE 也注意到了这些缺点,并强调在深度估计中并非所有像素都同等重要。他们没有像大多数以前的方法那样使用现成的深度估计器,而是训练了新的深度估计器,一个用于前景,一个用于背景,并在推理过程中自适应地融合深度图。
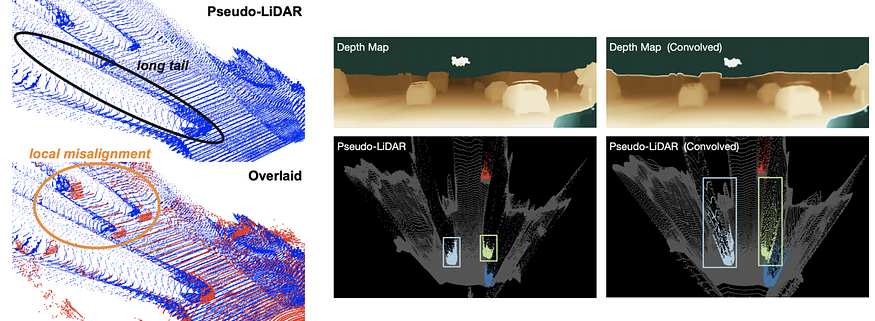
RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving digs into the problem of the point density in pseudo-lidar. It noted that the point density is one order of magnitude higher than that point cloud obtained with, say, a 64-line lidar. The excessively more points in the background lead to spurious false positives and cause more computation. The paper proposed a two-step method to perform structured sparsification, first identifying foreground points then perform sparsification. Firstly, foreground points are identified with two proposed approaches, one supervised and one unsupervised. The supervised method trains a 2D object detector and uses the union of 2D bbox mask as the foreground mask to remove the background points. The unsupervised method uses Laplacian of Gaussian (LoG) to perform keypoint detection and uses 2nd order of nearest neighbors as foreground points. Then these foreground points are sparsified uniformly within each depth bins. RefinedMPL found that even with 10% points, the performance of 3D object detection does not drop and actually outperforms the baseline. The paper also attributes to the performance gap between pseudo-lidar to real lidar point cloud to the inaccurate depth estimation.
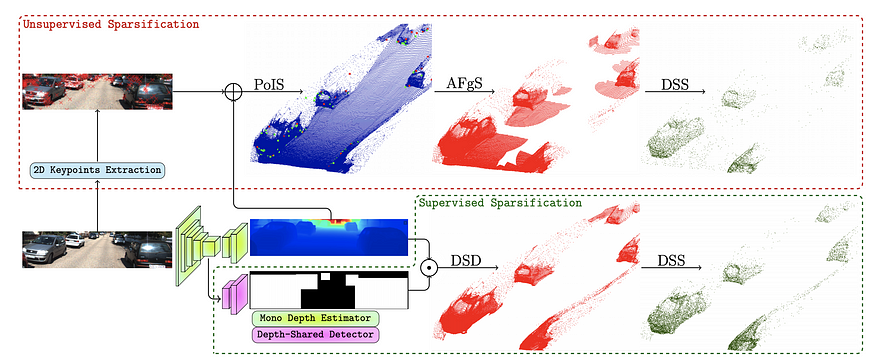
Overall, I have high hopes for this line of approach. What we need is accurate depth estimation of the foreground, which can be augmented by sparse depth measurements, for example, from low-cost 4-line lidars.
2. Keypoints and Shapes
车辆是具有独特公共部件的刚体,可以用作检测、分类和重新识别的地标/关键点。此外,感兴趣对象(车辆、行人等)的维度是已知大小的对象,包括整体大小和关键点间大小。可以有效地利用大小信息来估计与自我车辆的距离。
大多数沿着这条线的研究扩展了 2D 对象检测框架(单阶段,如 Yolo 或 RetinaNet,或两阶段,如 Faster RCNN)来预测关键点。
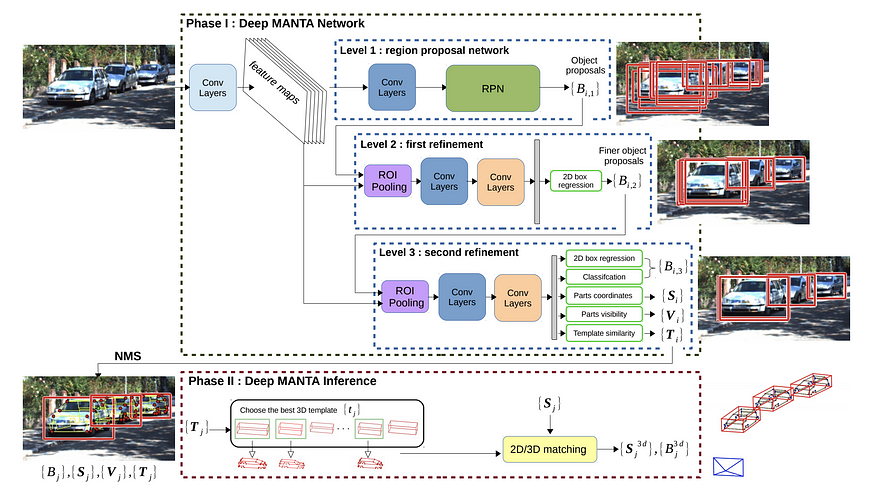
Deep MANTA (CVPR 2017) 是这方面的一项开创性工作。在用于训练和推理的阶段 1 中,它使用级联的 Faster RCNN 架构来回归 2d bbox、分类、2D 关键点、可见性和模板相似性。该模板只是表示 3d bbox 的 (w, h, l) 三元组。Phase 2仅用于推理,利用模板相似性,选择最匹配的3D CAD模型,进行2D/3D匹配,恢复3D位置和方向。
3D-RCNN (CVPR 2018) 估计汽车的形状、姿态和尺寸参数,并渲染(合成)场景。然后将蒙版和深度图与地面实况进行比较,以生成“渲染和比较”损失。主成分分析 (PCA) 用于估计形状空间的低维 (10-d) 表示。姿势(方向)和形状参数是根据 RoIPooled 特征和基于分类的回归估计的(参见[我之前关于多模态回归的帖子](https://towardsdatascience.com/anchors-and-multi -bin-loss-for-multi-modal-target-regression-647ea1974617))。这项工作需要大量输入:2D bbox、3D bbox、3D CAD 模型、2D 实例分割和内在函数。此外,基于 OpenGL 的“渲染和比较”损失似乎也相当工程化。
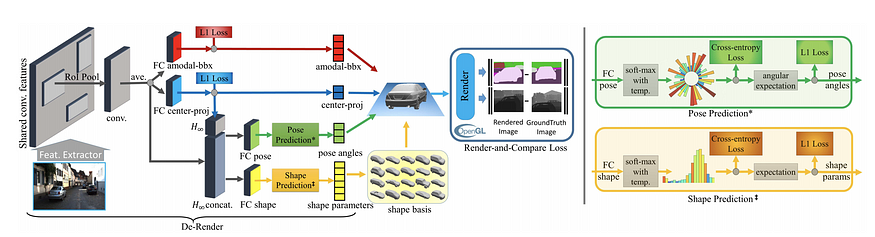
RoI-10D (CVPR 2019)其名称来源于 3D 边界框的 6DoF 姿势 + 3DoF 大小。额外的一维指的是形状空间。与 3D RCNN 一样,RoI-10D 学习形状空间的低维 (6-d) 表示,但使用 3D 自动编码器。来自 RGB 的特征通过估计的深度信息得到增强,然后被 RoIPooled 回归旋转 q(四元数)、RoI-relative 2D 质心(x,y)、深度 z 和度量范围(w,h,l)。根据这些参数,可以估计 3D 边界框的 8 个顶点。可以在所有八个预测顶点和地面真值顶点之间制定角损失。通过最小化重投影损失,基于 KITTI3D 离线标记形状基本事实。形状的使用也相当工程化。
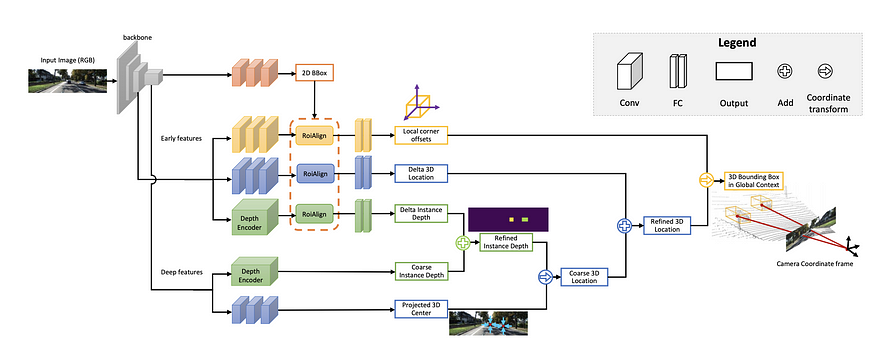
MonoGRNet (AAAI 2019) 回归 3D 中心和粗实例深度的投影,并用两者估计粗略的 3D 位置。它强调2D bbox 中心和 3D bbox 中心在 2D 图像中的投影之间的区别。投影的 3D 中心可以看作是一个人工关键点,类似于 GPP。与许多其他方法不同,它不回归相对容易的观察角度,而是直接回归 8 个顶点相对于 3D 中心的偏移量。
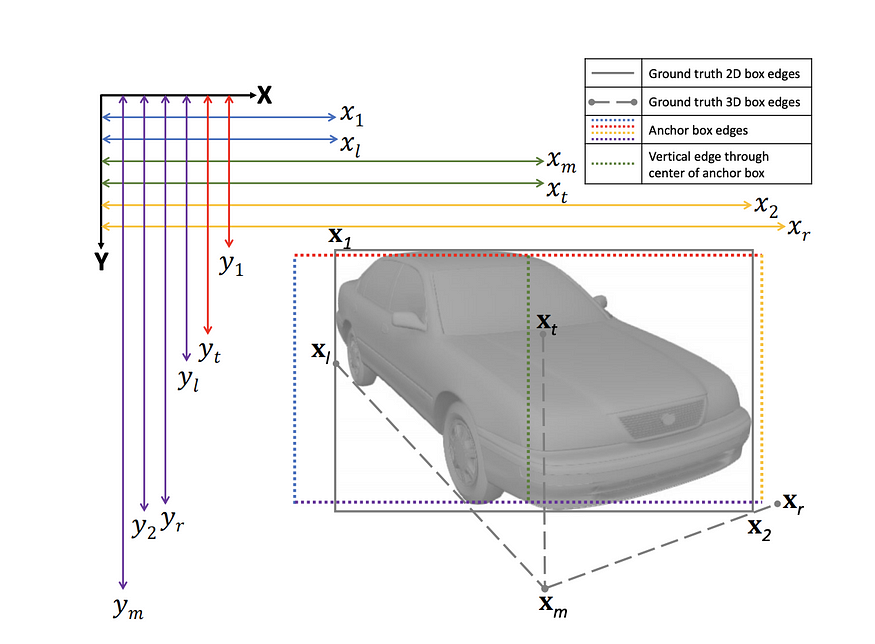
Ground Plane Polling (GPP) 生成 带有 3D bbox 注释的虚拟 2D 关键点。它有目的地预测比估计 3D bbox(过度确定)所需更多的属性,并使用这些预测来形成最大的共识属性集,其方式类似于 RANSAC,使其对异常值更加稳健。
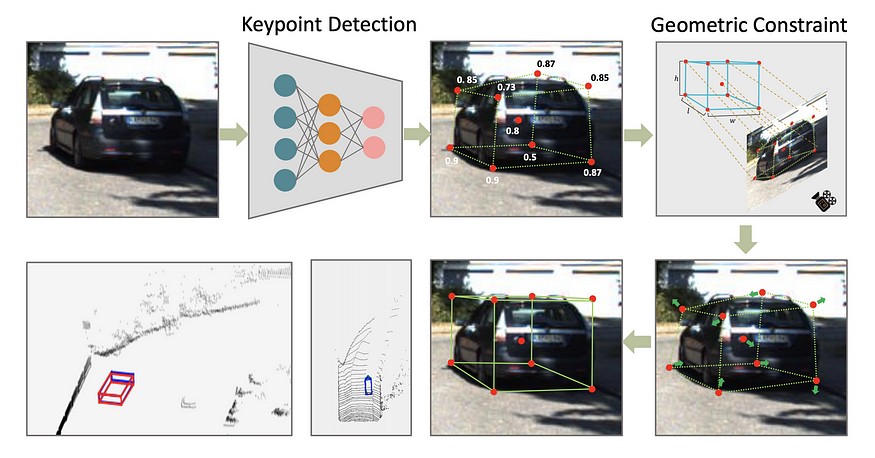
RTM3D (real-time mono-3D) 还使用虚拟关键点并使用类似 CenterNet 的结构来直接检测所有 8 个长方体顶点 + 长方体中心的 2d 投影。该论文还直接回归了距离、方向、大小。这些值不是直接使用这些值来形成长方体,而是用作初始值(先验)来初始化离线优化器以生成 3D bboxes。它声称是第一个实时单目 3D 对象检测算法(0.055 秒/帧)。
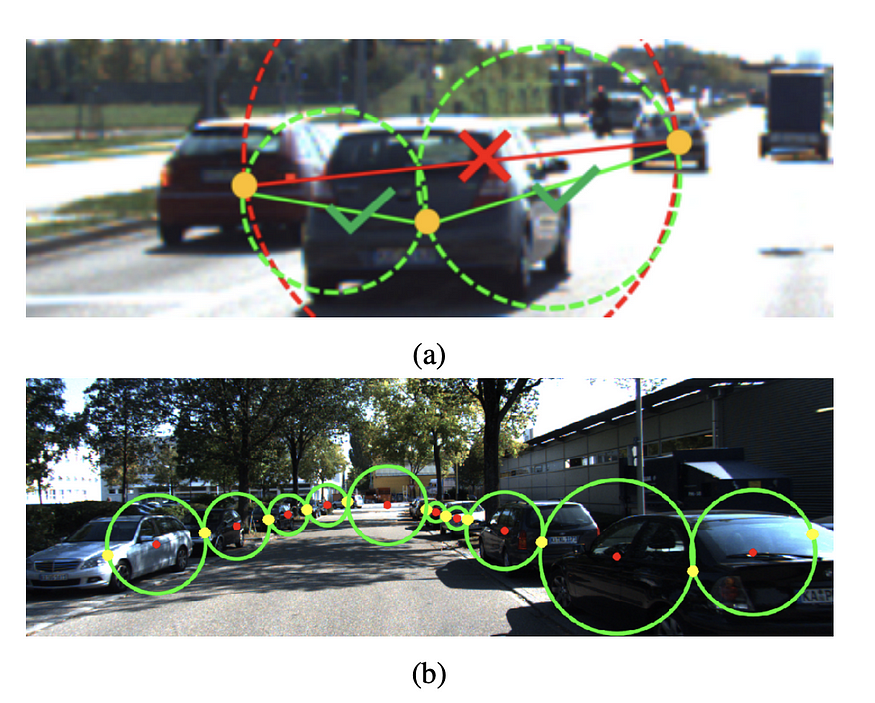
MonoPair 从 CenterNet 中汲取了很多灵感,并专注于基于汽车对之间的空间关系来改进检测结果。它不仅像 CenterNet 中那样直接检测 3D bbox,而且还预测虚拟成对约束关键点。成对关键点 定义为任意两个对象的中间点(如果它们是最近邻)。这种“关系关键点”的定义类似于 像素到图形 (NIPS 2017) 中的定义。3D 全局优化 Monopair 的想法指出,在深度估计过程中结合不确定性会带来最大的性能提升。
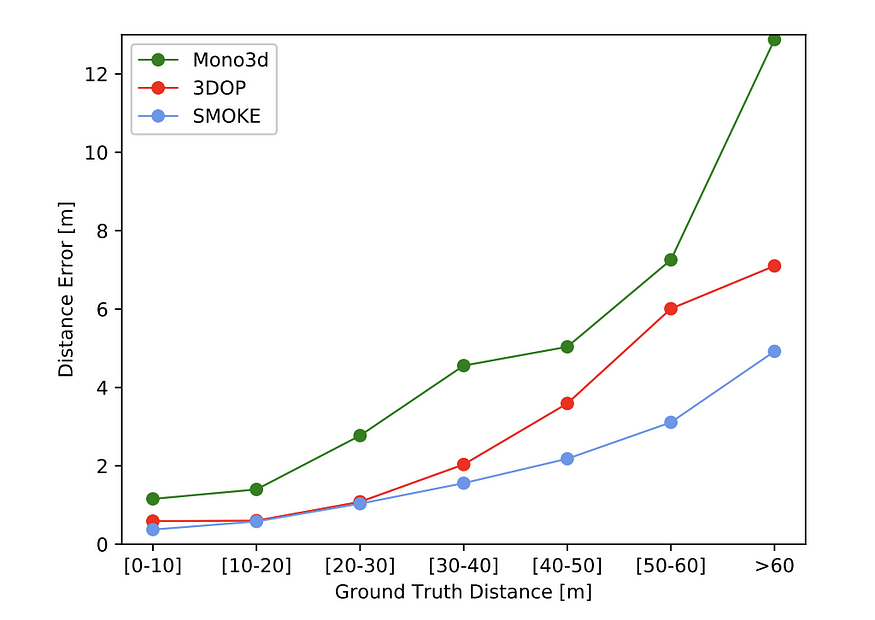
SMOKE (Single-Stage Monocular 3D Object Detection via Keypoint Estimation, CVPRW 2020) 也是受到CenterNet的启发,干脆去掉2D bbox的回归,直接预测3D bbox。它将 3D 边界框编码为 3D 长方体中心投影处的一个点,并将其他参数(大小、距离、偏航)作为其附加属性。损失是受 MonoDIS 启发,使用解缠结的 L1 损失优化的 3D 角损失。这种类型的损失公式,与通过多个损失函数的加权和来预测 7DoF 参数相反,是一种根据不同损失项对 3D 边界框预测的贡献将其加权在一起的隐式方法。它还在 60 米内实现了小于 5% 的距离预测误差。
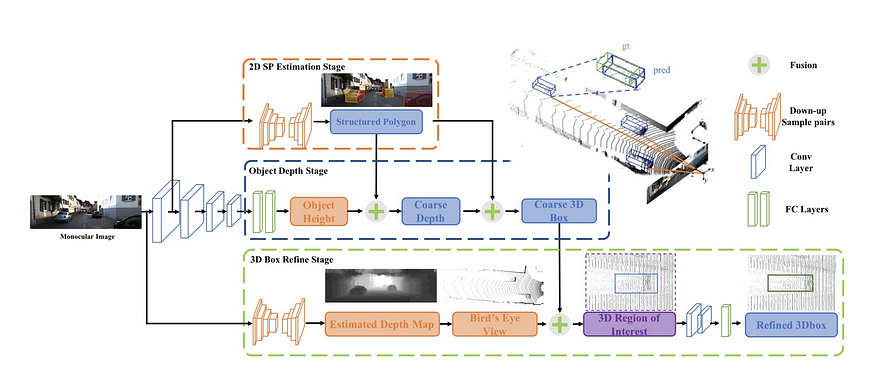
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation (AAAI 2020) is the first work to clearly state that the estimation of the 2D projection of the 3D vertices (referred to as the Structured Polygon in the paper) is totally decoupled from the depth estimation. It uses a similar method as RTM3D to regress the eight projected points of the cuboid, then uses vertical edge height as a strong prior to guide distance estimation. This generates a coarse 3D cuboid. Then this 3D cuboid is used as a seed position in a BEV image (generated using a similar method to Pseudo-Lidar) for finetuning. This leads to better results than monocular Pseudo-Lidar.
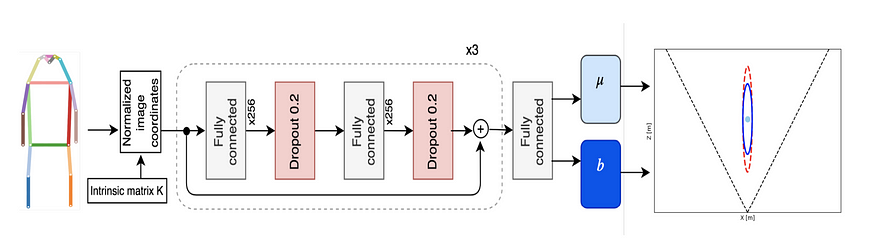
Monoloco (ICCV) 与上面的有点不同,因为它专注于回归行人的位置,这可以说比车辆的 3D 检测更具挑战性,因为行人不是刚体并且具有各种姿势和变形。它使用关键点检测器(自上而下的 Mask RCNN 或自下而上的 Pif-Paf)来提取人类关键点的关键点。作为基线,它利用行人相对固定的高度,特别是肩部到臀部的部分(~50 厘米)来推断深度,这与 MonoGRNet V2 和 GS3D 所做的非常相似。该论文使用多层感知器(完全连接的神经网络)来回归所有关键点段长度的深度,并展示了对简单baseline的改进。该论文还通过任意/认知不确定性的建模对不确定性进行了现实的预测,这在自动驾驶等安全关键应用中至关重要。
总之,提取 2D 图像中的关键点是实用的,并且具有在没有直接监督的情况下从基于激光雷达数据的 3D 注释推断 3D 信息的潜力。然而,这种方法需要对每个对象的多个关键点进行相当繁琐的注释,并且涉及工程繁重的 3D 模型操作。
3. Distance estimation through 2D/3D constraints
这个方向的研究利用 2D/3D 一致性将 2D 提升到 3D。开创性的工作是 deep3DBox (CVPR 2016)。使用这些几何的prompts,它解决了一个过度约束的优化问题以获得 3D 位置,将 2D 边界框提升到 3D。
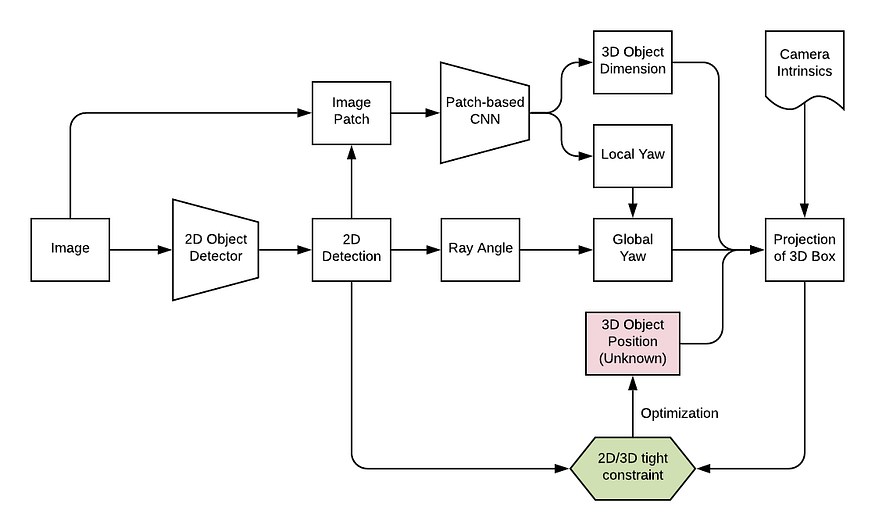
FQNet (CVPR) 将 deep3dbox 的想法扩展到紧身之外。它通过围绕 3D 种子位置(通过严格的 2D/3D 约束获得)进行密集采样,为 deep3dbox 添加了一个细化阶段,然后使用渲染的 3D 线框对 2D 补丁进行评分。然而,密集采样(如稍后将要讨论的 Mono3D 中的那样)需要很长时间并且计算效率不高。
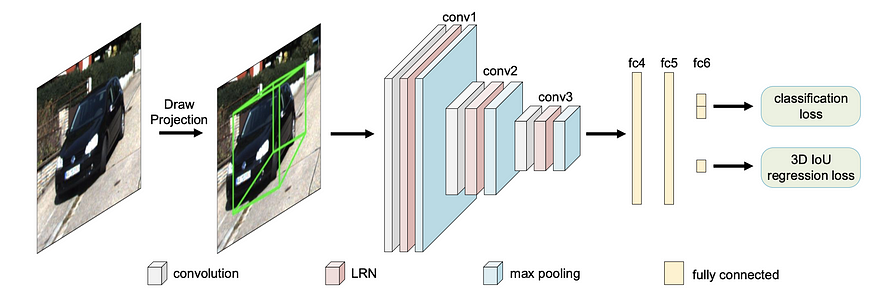
MVRA (Multi-View Reprojection Architecture, ICCV) 将 2D/3D 约束优化构建到神经网络中,并使用迭代方法细化裁剪案例。它引入了一个 3D 重建层来将 2D 提升到 3D,而不是求解过约束方程,在两个不同的空间中有两个损失:1)透视图中的 IoU 损失,在重投影的 3D bbox 和 IoU 中的 2d bbox 之间,以及 2 ) L2 loss in BEV loss estimated distance and gt distance. 它认识到 deep3DBox 不能很好地处理截断框,因为边界框的四个边现在不对应于车辆的真实物理范围。这促使使用 截断 bbox 的迭代方向优化,仅使用 3 个约束而不是 4 个,不包括 xmin(用于左截断)或 xmax(用于右截断)汽车。全局偏航是通过 pi/8 和 pi/32 间隔的两次迭代中的反复试验来估计的。
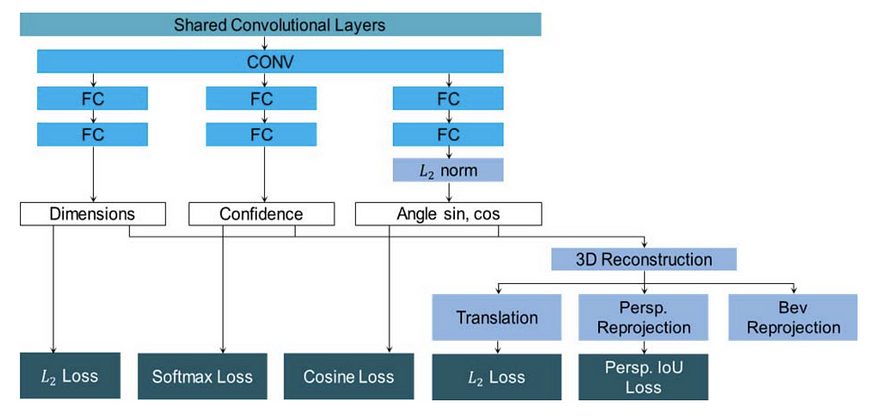
MonoPSR (CVPR 2022) 来自流行的传感器融合框架 AVOD 的同一作者。它首先生成 3D 提案,然后重建动态对象的局部点云。质心建议阶段使用 2D 框高度和回归的 3D 对象高度来推断深度,并将 2D 边界框中心重新投影到估计深度处的 3D 空间。建议的圣人非常实用且非常准确(平均绝对误差~1.5 m)。重建分支回归对象的局部点云,并将其与点云和相机(投影后)中的 GT 进行比较。它呼应了 MonoGRNet 和 TLNet 的观点,即整个场景的深度对于 3D 对象检测来说是过大的。以实例为中心的焦点通过避免回归大深度范围使任务更容易。
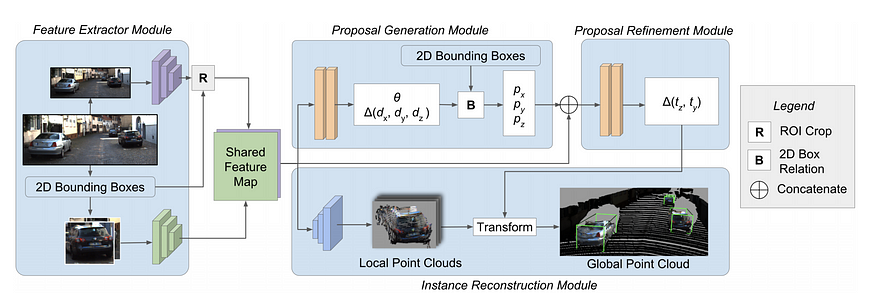
4. Direct Generation of 3D proposal
Uber ATG 在 CVPR16 中的 Mono3D 是单目 3D 对象检测领域的开创性工作之一。它专注于直接 3D 提案生成,并根据汽车应该在地面上这一事实生成密集提案。然后它通过许多手工制作的特征对每个提议进行评分,并执行 NMS 以获得最终的检测结果。在某种程度上,它类似于 FQNet,后者通过检查反向投影线框对 3D bbox 提议进行评分,尽管 FQNet 将 3D 提议置于 Deep3DBox 的初始猜测周围。
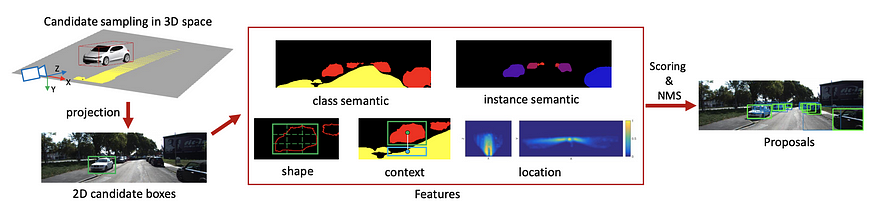
MonoDIS (ICCV 2019)是基于扩展的 RetinaNet 架构直接回归 2D bbox 和 3D bbox。它不是直接监督 2D 和 3D bbox 输出的每个组件,而是采用 bbox 回归的整体视图并使用 2D(有符号)IoU 损失和 3D 角损失。这些损失通常很难训练,因此它提出了一种解耦技术,将除一组(包括一个或多个元素)之外的所有元素固定为 ground truth 并计算损失,本质上只训练该组中的参数。这个选择性训练过程会轮换,直到它覆盖预测中的所有元素,并且总损失在一次前向传递中累积。这种分离训练过程可以实现 2D/3D bbox 的端到端训练,并且可以扩展到许多其他应用程序。
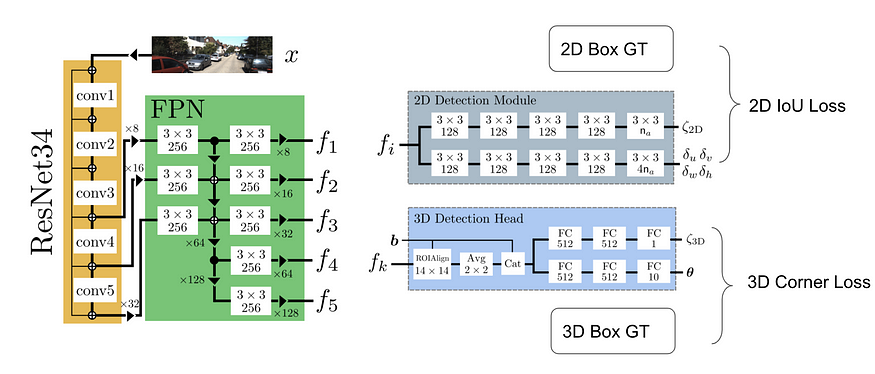
The authors of MonoDIS further improved the algorithm by adopting the idea of Virtual Cameras. The main idea is that the model has to learn different representations for cars at different distances, and the model lack generality for cars beyond the distance range at training. To address a larger distance range, we have to increase the capacity of the model and the accompanying training data. Virtual Camera proposes to break down the entire image into multiple image patches, each containing at least one entire car and with limited depth variation. During inference, a pyramid-like tiling of images are generated for inference. Each tile or strip of the images corresponds to a specific range limit and has varying width and the same height.

CenterNet 是一个通用的对象检测框架,可以扩展到许多与检测相关的任务,例如关键点检测、深度估计、方向估计等。它首先回归一个热图,指示对象中心位置的置信度,然后回归其他对象属性。直接扩展 CenterNet 以将 2D 和 3D 对象检测作为中心点的属性。
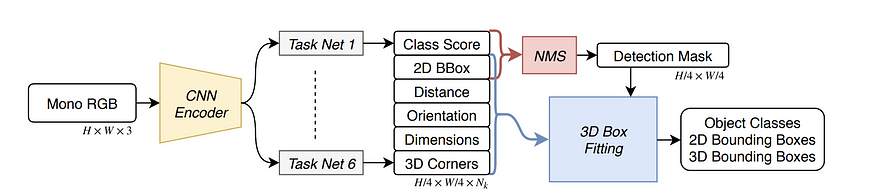
SS3D 不是这样的. 它使用类似 CenterNet 的结构,首先找到潜在对象的中心,然后同时回归 2D 和 3D 边界框。回归任务回归了关于 2D 和 3D 边界框信息的足够信息以进行优化。2D 和 3D 边界框元组的参数化中总共有 26 个代理元素。总损失是26个数字的加权损失。
M3D-RPN (ICCV 2019) 通过预先计算每个 2D 锚点的 3D 平均统计数据,同时回归 2D 和 3D bbox 参数。它直接回归 2D 和 3D 边界框(11 + num_class),类似于 SS3D 回归 26 个数字。论文提出了2D/3D anchor 的有趣想法。本质上它们仍然是平铺在整个图像上的 2D 锚点,但具有 3D 边界框属性。根据 2D 锚点的位置,锚点可能具有不同的 3D 锚点先验统计数据。M3D RPN 建议对不同的行 bin 使用单独的卷积滤波器(深度感知卷积),因为深度在很大程度上与自动驾驶场景中的行相关。
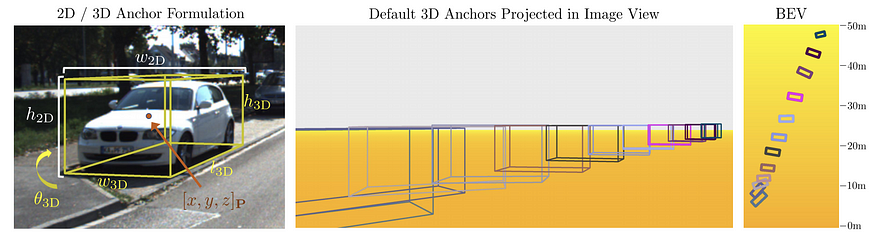
D4LCN (CVPR 2020) 通过引入动态过滤器预测分支,进一步借鉴了 M3D-RPN 的深度感知卷积的思想。这个额外的分支将深度预测作为输入并生成一个过滤器特征量,它根据权重和扩张率为每个特定位置生成不同的过滤器。D4LCN 还使用了来自 M3D-RPN 的 2D/3D anchors 思想,并同时回归 2D 和 3D 框(每个 anchor 35 + 4 类)。
TLNet (CVPR 2019) 主要关注立体图像对,但它们也有坚实的单眼基线。它将 3D 锚点放置在 2D 对象检测所针对的平截头体内作为单声道基线。它重申了 MonoGRNet 的观点,即像素级深度图对于 3DOD 而言过于昂贵,而对象级深度应该足够好。它模仿 Mono3D,因为它在 [0, 70m] 范围内密集放置 3D 锚点(0.25 米间隔),其中 每个对象类的两个方向(0 和 90 度),以及对象类的平均大小。将 3D proposal 投影到 2D 得到 RoI,RoIpooled 特征用于回归位置偏移和维度偏移。
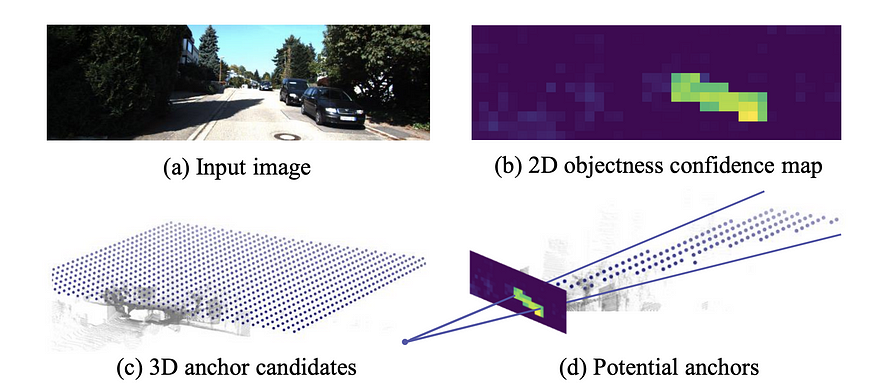
总之,由于可能的位置很大,很难在 3D 空间中直接放置 3D 锚点。anchor本质上是就是sliding的windows,3D 空间的详尽扫描是棘手的。因此,直接生成 3D 边界框通常使用启发式或 2D 对象检测,例如,汽车通常在地面上,而汽车的 3D 边界框在其相应的 2D 边界框对向的截锥体内等。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









