






作者 | ZZZzz 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/624365719
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【占用网络】技术交流群
后台回复【OccupancyNetwork】获取Occupancy Network相关论文干货资料!
Title: OpenOccupancy: A Large Scale Benchmark for Surrounding Semantic Occupancy Perception
github: https://github.com/JeffWang987/OpenOccupancy
发表单位: 中国科学院自动化研究所、鉴智机器人、中国科学院大学、清华大学
Abstract
为了对周围感知算法进行全面的基准测试,我们提出了OpenOccupancy,它是第一个周视语义占用感知基准。
在OpenOccupancy基准中,我们用密集的语义占有率注释扩展了大规模的 nuScenes数据集。
以前的注释依赖于LiDAR点的叠加位置,由于LiDAR通道稀疏,一些占用标签被遗漏。为了缓解这个问题,我们引入了 (Augmenting And Purifying)(AAP)管道,对标签扩充到原来的两倍,其中有4000+小时的人工标注。
此外, 我们为OpenOccupancy基准建立了基于摄像头的、基于LiDAR和多模态的基线。
此外,考虑到周围占有率感知的复杂性在于高分辨率三维预测的计算负担,我们提出了Cascade Occupancy Network(CONet)来完善粗略的预测,相对来说,它比基线提高了30%的性能。
1. Introduction
SemanticKITTI[1]将占用感知扩展到驾驶场景,但其数据集的规模相对较小,而且多样性有限,这阻碍了占用感知算法的推广和评估。此外, SemanticKITTI只评估了前视的占用率预测,而周视感知对安全驾驶更为关键。为了解决这些问题,我们提出了OpenOccupancy,它是第一个周视语义占用感知基准 。
在OpenOccupancy基准中,我们引入了nuScenes-Occupancy,它扩展了大规模 nuScenes 数据集,具有密集的语义占用注释。
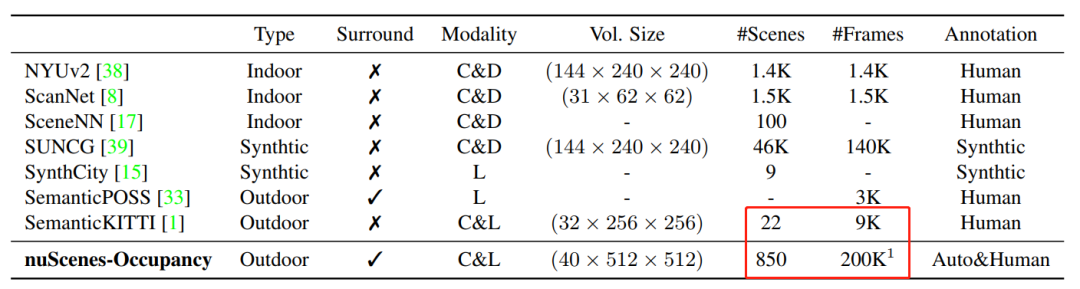
如表1所示,nuScenes-Occupancy的注释场景和帧的数量分别比 SemanticKITTI 多40倍和20倍。
具体来说,我们通过多帧LiDAR点的叠加来初始化注释,其中每个点的语义标签来自 Panoptic nuscenes 。考虑到初始注释的稀疏性(即由于遮挡或有限的LiDAR通道,一些占用标签被遗漏), 我们用伪占用标签来增加它,这些标签是由预先训练的基线构建的(见第3.4节)。为了进一步减少 noise 和 artifacts ,我们用人工来净化增加的注释。基于 AAP管道,我们生成了比初始注释密集2倍的占用标签。
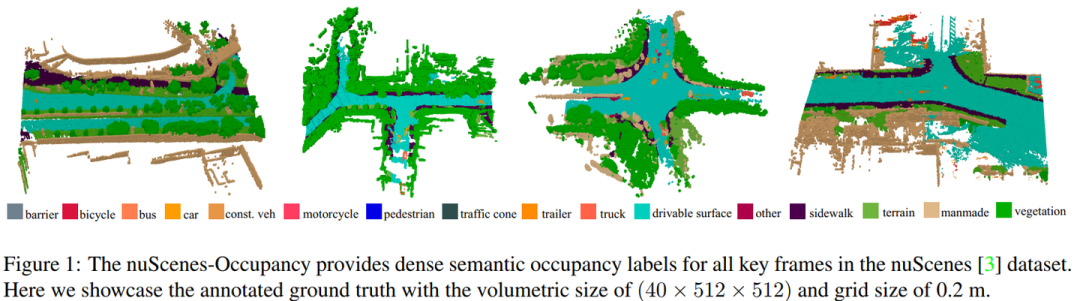
为了促进未来的研究,我们为 OpenOccupancy 基准建立了基于摄像头、基于LiDAR和多模式的基线。
实验结果表明,基于摄像头的方法在小物体(如自行车 、行人、摩托车)上取得了更好的性能,而基于激光雷达的方法在大的结构化区域(如可驾驶的路面、人 行道)上显示出更高的性能。值得注意的是,多模态基线自适应地融合了两种模态的混合特征,相对地将 整体性能(基于摄像头和基于激光雷达的方法)提高 了47%和29%。
考虑到周围占有率感知的计算负担, 提议的基线只能产生低分辨率的预测。为了实现高效的占用率感知,我们提出了 Cascade Occupancy Network (CONet)。在提出的基线上建立了一个从粗到细 (coarse-to-fine) 的管道,相对来说,性能提高了∼30%。
主要贡献如下:
OpenOccupancy:第一个为驾驶场景中的周视占用率感知而设计的基准。
The AAP pipeline:对nuScenes数据集的语义占用标签进行了注释和密集化,所得到的nuScenes-Occupancy是第一个用于周视语义占用的数据集。
在 OpenOccupancy 基准中建立了 camera-based, LiDAR-based and multi-modal 的基线。
基于OpenOccupancy基准,我们对所提出的基线、CONet和现代占用感知方法进行了综合实验
2. Related Work
MonoScene[5]是文献中第一个基于摄像头的占用感知方法,它可以从单一图像中推导出占用语义 。尽管占有率感知方法有了很大的发展,但它们大多集中在前视的室内场景。
最近,TPVFormer[19]提出了一个三视角的视图再现,以产生周视的占用预测,然而它的占用输出是相对稀疏的,因为TPVFormer是为 LiDAR分割设计的.
3. The OpenOccupancy Benchmark
3.1 Surrounding Semantic Occupancy Perception
参照[39],周视语义占有率感知是一项生成完整的 三维空间占有率代表和场景语义标签的任务。与专注 于前视感知的单眼范式[39]不同,周视占用感知算法的目标是在周视场景中产生语义占用。
值得注意的是,周视输入的感知范围比前视 传感器的感知范围大5倍。因此,周视占用感知的核心挑战在于有效地构建高分辨率的占用。
3.2. nuScenes-Occupancy
通过人工直接注释大规模的占用标签几乎是不现实的。因此,我们引入了 Augmenting And Purifying(AAP)管道, 以有效地注释和强化占用标签。

我们首先通过LiDAR点的叠加将标签初始化
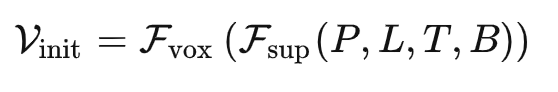
其中静态点(例如,人行道)被转换为统一的世界坐标。
对于可移动的物体(例如,移动的汽车) 我们将点云转换为其边界框 B 的坐标(不同帧中的每个物体可以通过实例标记[32]进行关联)
随后,静态和动态的点被连接起来并被体素化, 产生初始占有率。
由于遮挡或稀疏的 LiDAR通道,一些占用标签被遗漏。受 self-training 的启发,我们用伪占位标签补充初始注释。
具体来说,初始标签被用来训练候选的多模态基线 (见第 3.4节),而伪占位标签 则被预训练模型生成。

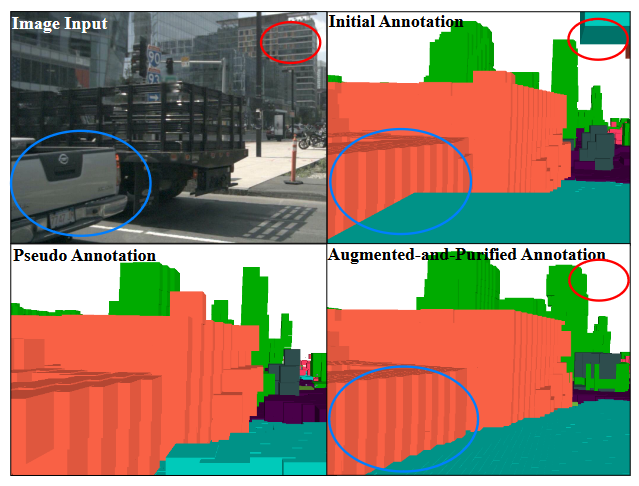
其中红色和蓝色圆圈高亮的区域表示增强的注释更加密集和准确。如图所示,伪标签是对初始注释的补充,而增强和净化后的标签则更加密集和精确。
3.3. Evaluation Protocol
评估范围:X、Y轴为[-51.2m, 51.2m],Z轴为[3m, 5m],体素的分辨率为0.2m,40×512×512。
评价准则:IoU 和 mIoU
3.4. OpenOccupancy Baselines
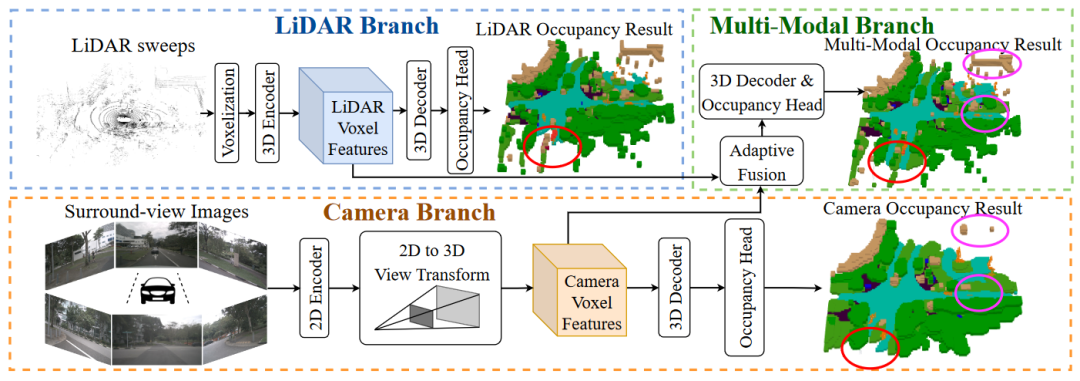
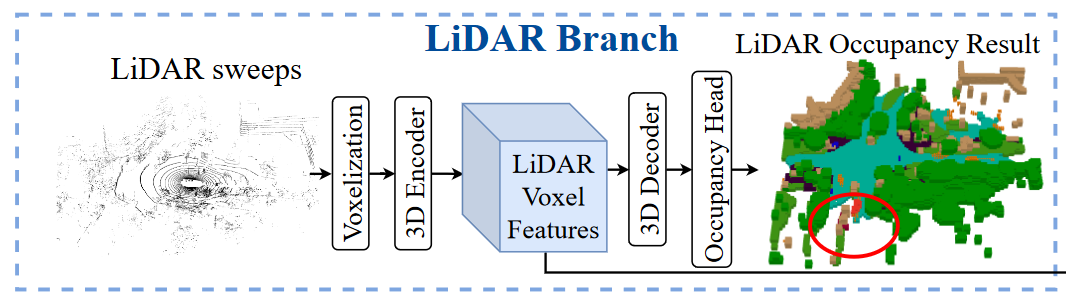
LiDAR-based baseline

Camera-based baseline

Multi-modal baseline
在多模态基线中,我们提出了自适应融合模块,动态地整合来自LiDAR 的体素特征 和相机的体素特征 。

4. Cascade Occupancy Network
与前视占用感知[1]相比,周视占用感知的输入覆盖了5倍的感知范围。因此,复杂性在于高分辨率三维预测的计算负担上。
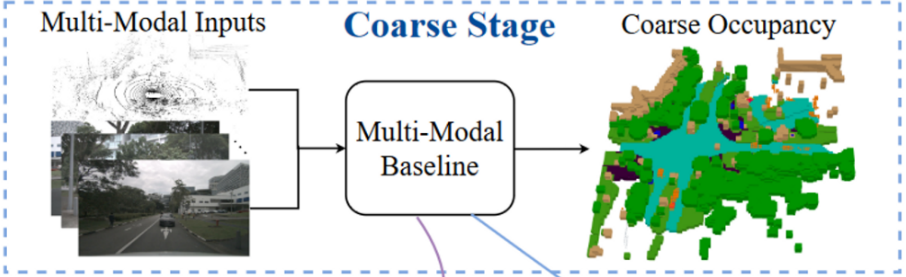
具体来说,CONet 引入了一个 coarse-to-fine 的 pipeline,以多模态基线为例(称为多模态CONet),整体框架如图所示。
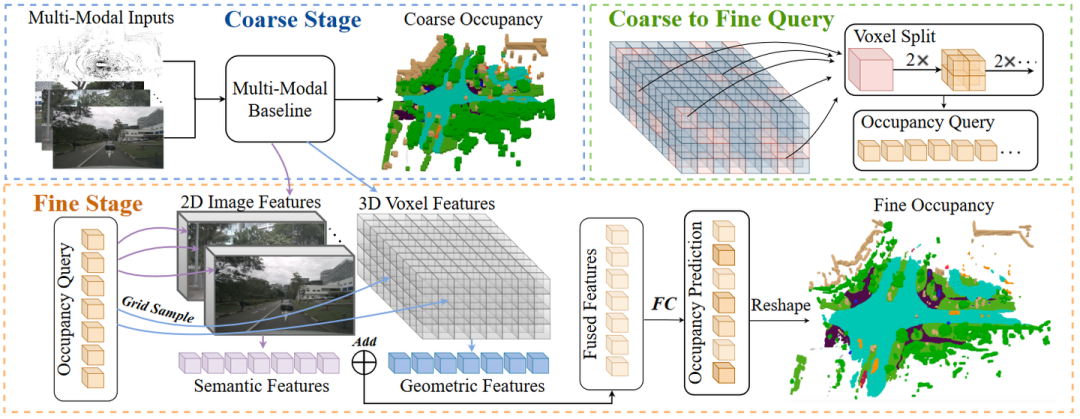


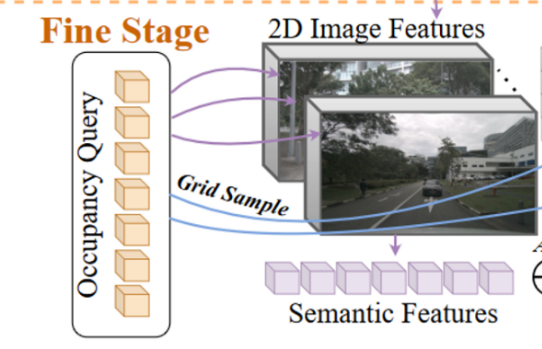
并将转换到体素空间,对几何特征(geometric features)进行采样,
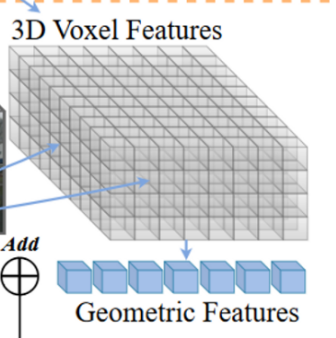

然后将采样的特征进行融合,并通过FC进行正则化产生细粒度的占有率预测(fine-grained occupancy predictions)


其中,Tv→q 将体素坐标转换为高分辨率查询(high-resolution query)的索引。
5. OpenOccupancy Experiment
包括三部分:
camera-based methods
LiDAR-based methods
multimodal methods
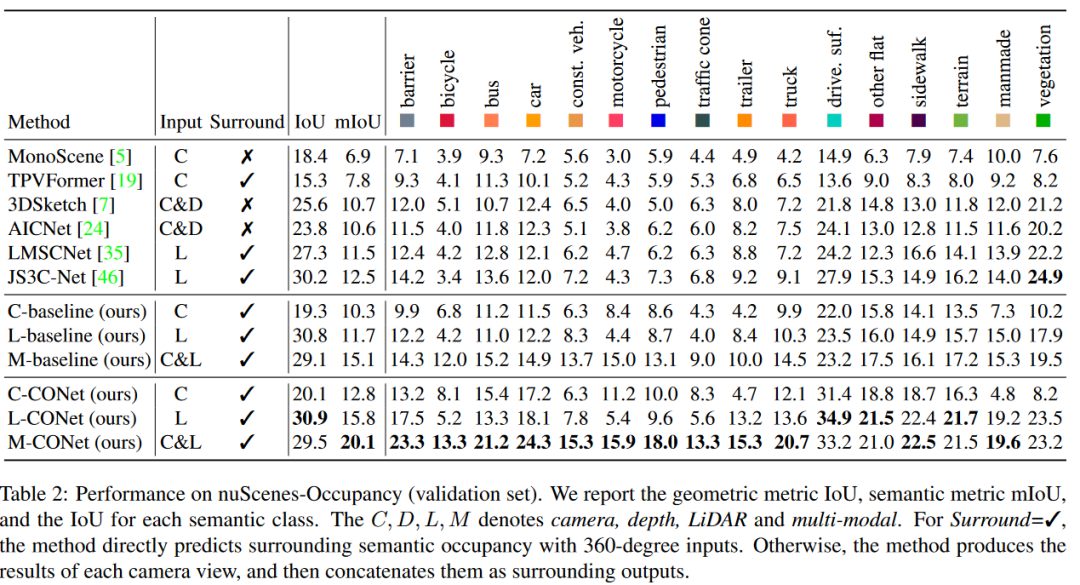
(1) 与单视角方法相比,周视占用感知范式显示出卓越的性能。
(2) 所提出的基线显示了对周围占有率感知的适应性 和可扩展性。对于基于摄像头的方法,我们的基线在 IoU和mIoU上相对提高了TPVFormer的26%和32%。
(3) 来自照相机和LiDAR的信息是相互补充的,多模式基线大大增强了性能。
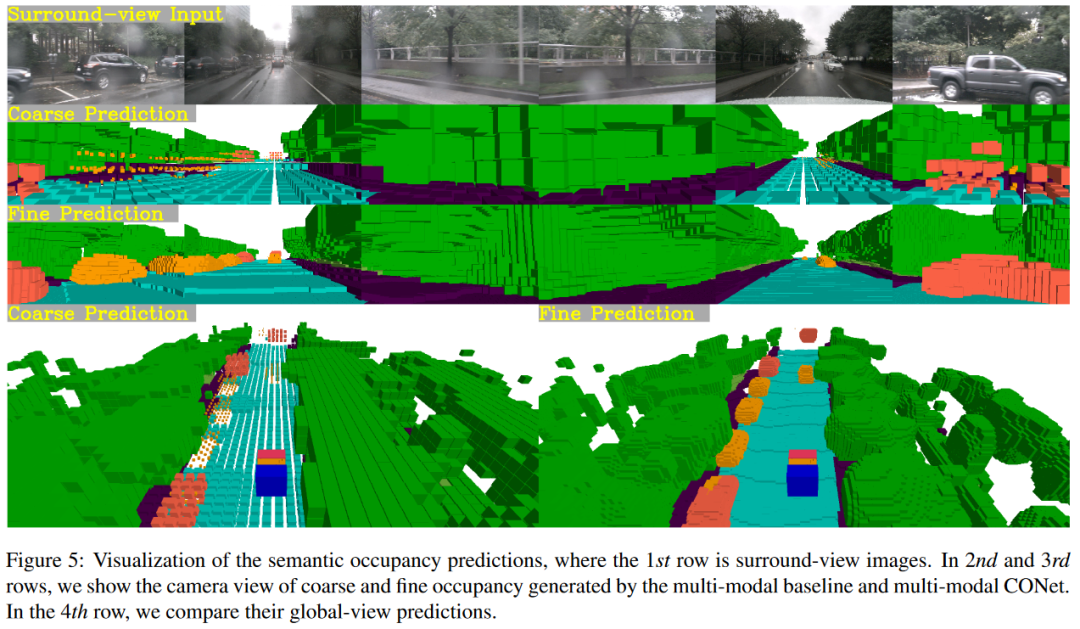
(4) 周视占有率感知的复杂性在于高分辨率三维预测的计算负担,这一点可以通过拟议的CONet来缓解。我们还提供了可视化(见图5),以验证CONet可以在粗略预测的基础上产生细粒度的占用结果。
总结 在本文中,我们提出了OpenOccupancy,这是在驾驶场景中周视语义占用率的第一个基准。
具体来说, 我们介绍了nuScenes-Occupancy,它基于AAP pipeline,用密集的语义占用注释扩展了nuScenes数据集。在OpenOccupancy基准中,我们建立了基于摄像头、 基于激光雷达和多模态的基线。此外,我们还提出了 CONet 来减轻高分辨率占用率预测的计算负担。在OpenOccupancy基准上进行了全面的实验,结果表明 ,基于相机的基线和基于激光雷达的基线是相互补充的,而多模态基线则进一步提高了47%和29%的性能 。此外,提出的CONet最小的延迟开销相对提高了~ 30%的基线。我们希望OpenOccupancy基准将有利于周视语义占用感知的发展。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 300
300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









