






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
原标题:HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
论文链接:https://arxiv.org/pdf/2404.02517.pdf
代码链接:https://github.com/VDIGPKU/HENet
作者单位:北京大学 长安汽车 加州大学默塞德分校

论文思路:
多视角相机的三维感知是自动驾驶系统中的一个关键组成部分,涉及多项任务,如3D目标检测和鸟瞰图(BEV)语义分割。为了提高感知精度,最近的3D感知模型采用了大型图像编码器、高分辨率图像和长时序输入,带来了显著的性能提升。然而,由于计算资源的限制,这些技术在训练和推理场景中常常不兼容。此外,现代自动驾驶系统更倾向于采用端到端框架进行多任务3D感知,这可以简化整个系统架构并降低实施复杂性。然而,在端到端的3D感知模型中共同优化多个任务时,任务之间经常会出现冲突。为了缓解这些问题,本文提出了一个名为 HENet 的端到端多任务3D感知框架。具体来说,本文提出了一个混合图像编码网络,使用大型图像编码器处理短时序帧,使用小型图像编码器处理长时序帧。然后,本文引入了一个基于注意力机制的时序特征集成模块,用于融合两种混合图像编码器提取的不同帧的特征。最后,根据每个感知任务的特点,本文使用不同网格大小的BEV特征、独立的BEV编码器和不同任务的任务解码器。实验结果表明,HENet在nuScenes基准测试中实现了最先进的端到端多任务3D感知结果,包括3D目标检测和BEV语义分割。
主要贡献:
本文提出了一个端到端的多任务3D感知框架,采用混合图像编码网络,以较小的训练成本利用高分辨率图像、长期输入和大型图像编码器的优势。
本文引入了一个基于注意力机制的时序集成模块,用于融合多帧BEV特征,并实现移动物体的动态帧间对齐。
本文分析了端到端多任务学习中的任务冲突,并提出了特征尺寸选择和独立特征编码来缓解这个问题。
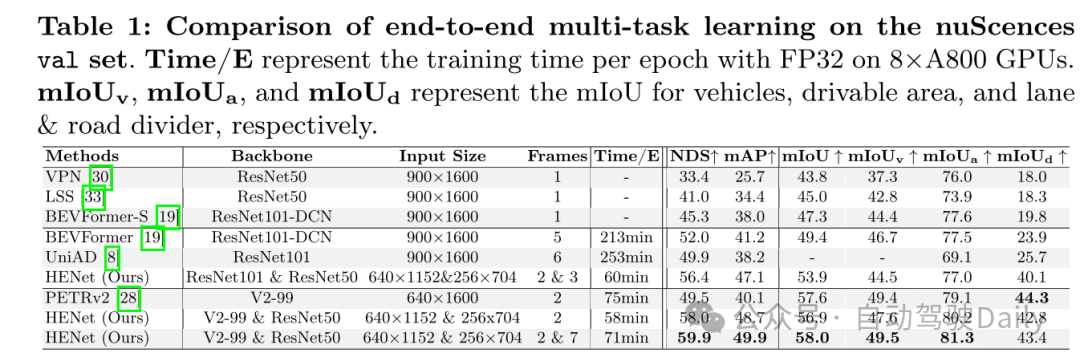
本文在nuScenes数据集上的端到端多任务学习中取得了最先进的结果,包括3D目标检测和BEV语义分割任务。
网络设计:
多视角相机高效且准确地感知周围环境对自动驾驶系统至关重要,它是随后轨迹预测和运动规划任务的基础。一个理想的3D感知系统应该能够同时处理多项任务,包括3D目标检测和鸟瞰图(BEV)语义分割。端到端多任务框架越来越受到重视,因为这样的系统有潜力简化整体架构并减轻实施复杂性。
然而,端到端的多任务3D感知面临以下挑战。首先,在设计基于相机的高性能3D感知模型时,研究人员通常会利用更高分辨率的图像、更长的时序输入和更大的图像编码器来提高3D感知的准确性。然而,将这些技术同时应用于单一的感知模型将导致训练成本极高。为了缓解这个问题,一些研究[32, 46]将过去的信息存储在 memory 中,但这样做有诸如时序特征不一致和数据增强效率低下等缺点。因此,许多最新的方法[26, 37, 44, 52]并没有采用这种策略,而是重新计算过去帧的特征,尽管这样做增加了训练成本。
其次,为了处理长期的时序输入,许多研究[11,17,18]直接在沿通道维度的鸟瞰图(BEV)中将不同帧的特征求和或连接起来,在更长的时间序列中表现出不尽人意的感知性能。原因在于,移动物体的特征在不同帧的鸟瞰图 (BEV) 中沿其轨迹错位并分散在较大区域内。因此,有必要引入动态对齐机制[28, 37]来校正移动物体的位置。
第三,对于端到端的多任务学习,现有的研究[8, 19, 28]使用一个共享的编码网络和多个解码器来处理不同的任务。然而,这些研究中的实验结果表明,端到端地共同学习多个任务往往并不是最优的,即多任务学习中每个任务的性能都低于单独训练。为了缓解这个问题,一些研究[28]提出了调整每个任务的损失权重,但没有全面分析任务之间存在冲突的原因。
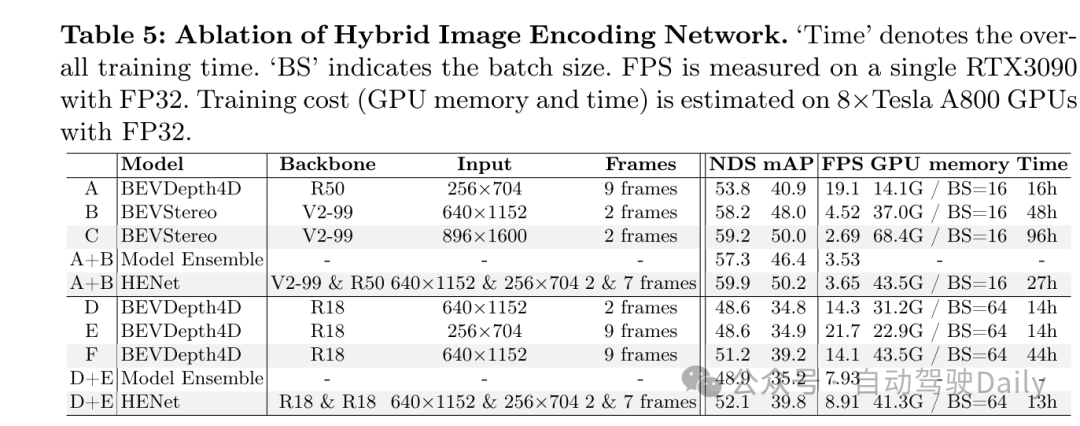
本文提出了HENet,这是一个端到端的多任务3D感知框架,专为多视角相机设计。为了整合大型图像编码器、高分辨率图像和长期输入,本文提出了一种混合图像编码网络,它采用不同的分辨率和图像编码器处理不同的帧。具体来说,本文对短期帧使用高分辨率输入、大型图像主干网络和复杂的透视变换网络,以生成高精度的BEV特征。对于长期帧,选择低分辨率输入,并采用小型图像主干网络和简单的透视变换网络高效生成BEV特征。所提出的混合图像编码网络可以轻松地并入现有的感知模型中。然后,本文引入了一个时序整合模块,以动态地对齐和融合来自多帧的BEV特征。具体来说,在这个模块中,本文提出了一个带有相邻帧融合模块(AFFM)的时序前向和后向过程来聚合BEV特征,通过注意力机制解决了对齐移动物体的问题。最后,本文深入分析了多任务学习中3D目标检测与BEV语义分割之间的冲突,并发现不同任务偏好不同的BEV特征网格大小是关键问题。基于这一观察,本文为不同任务选择了不同网格大小的BEV特征。所选特征被送入独立的BEV编码网络和任务解码器,以进一步缓解任务冲突,从而获得最终的3D感知结果。
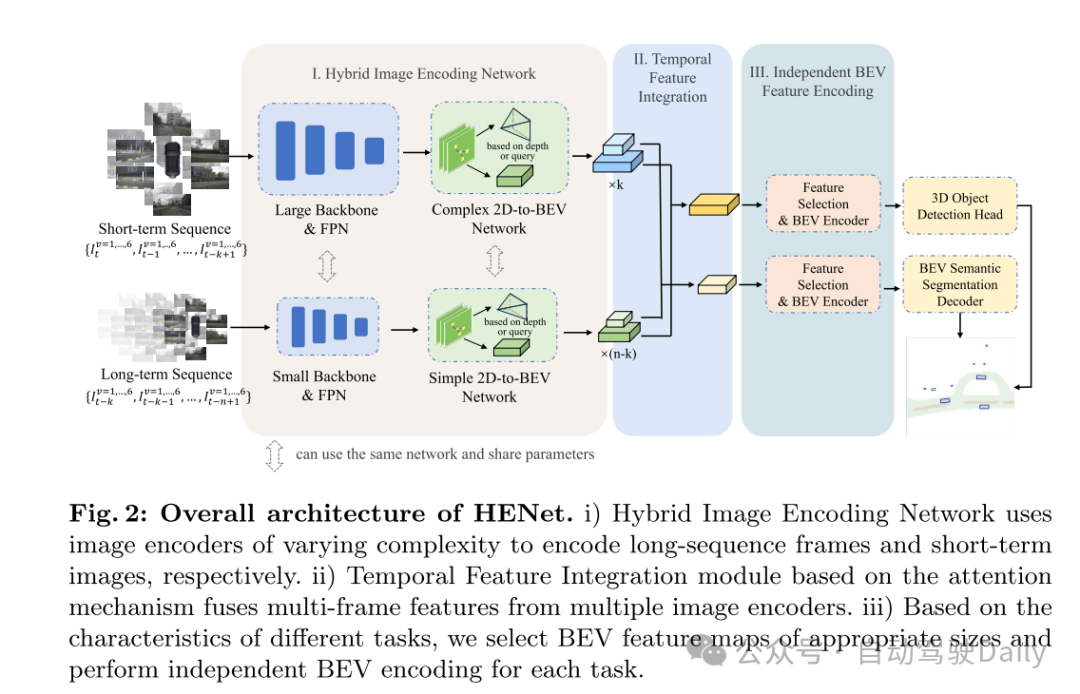
图2:HENet的整体架构。i) 混合图像编码网络使用不同复杂度的图像编码器分别对长序列帧和短期图像进行编码。ii) 基于注意力机制的时序特征整合模块融合了来自多个图像编码器的多帧特征。iii) 根据不同任务的特点,本文选择了合适大小的BEV特征图,并对每个任务执行独立的BEV编码。
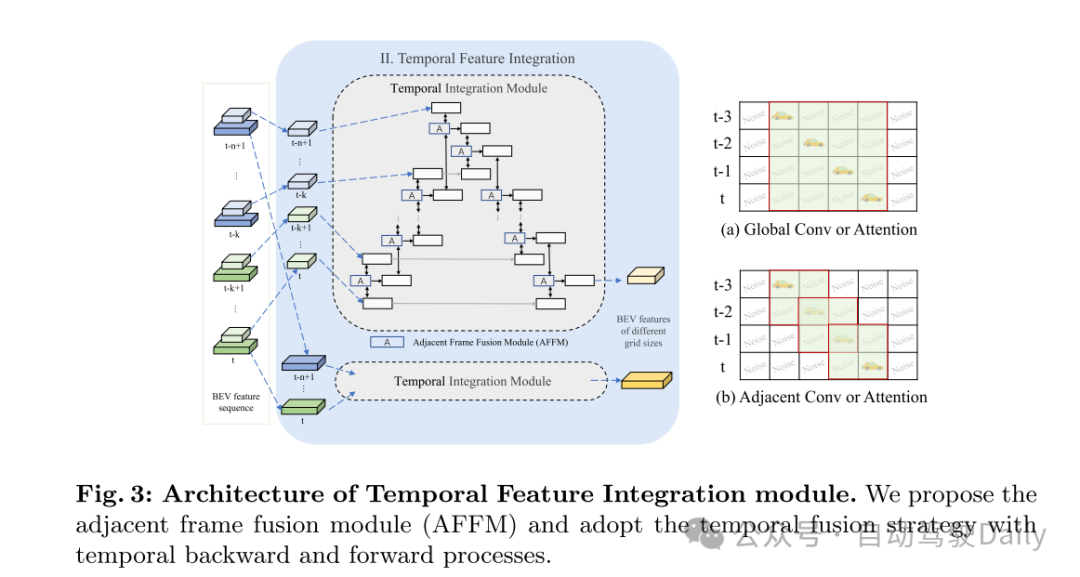
图3:时序特征整合模块的架构。本文提出了相邻帧融合模块(AFFM),并采用了包含时序前向和后向过程的时序融合策略。
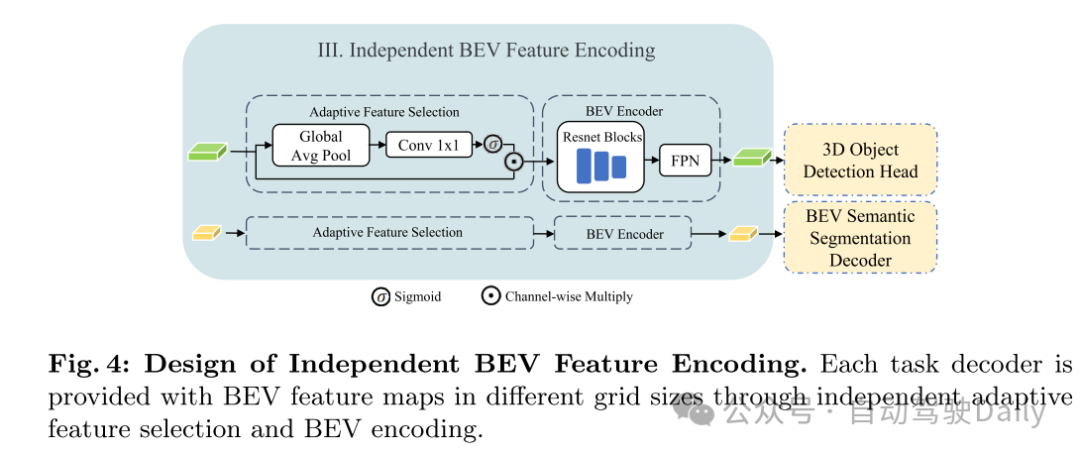
图4:独立BEV特征编码的设计。通过独立的自适应特征选择和BEV编码,为每个任务解码器提供不同网格大小的BEV特征图。

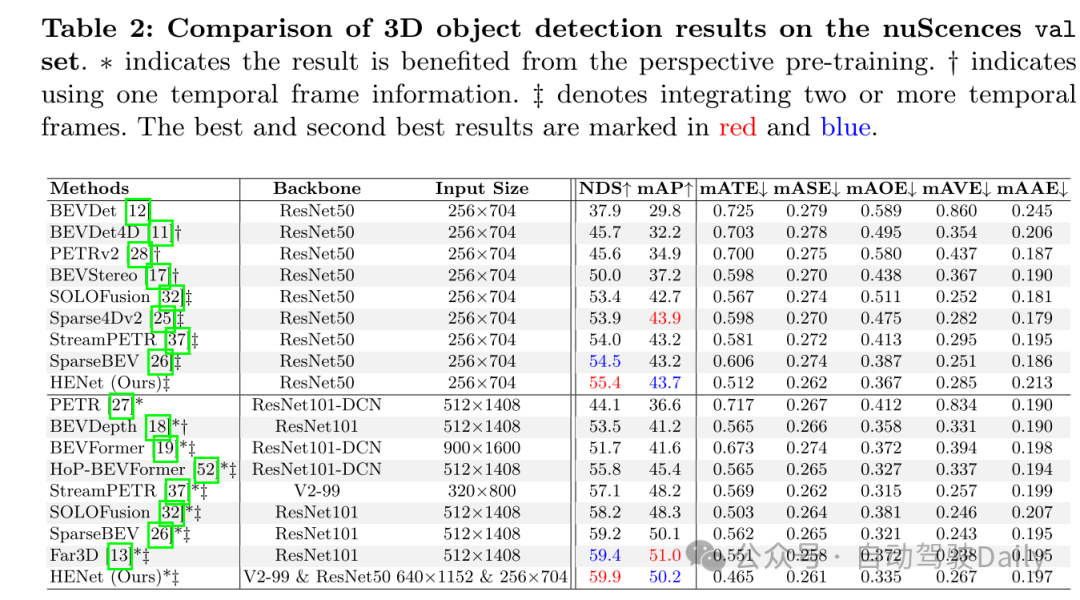
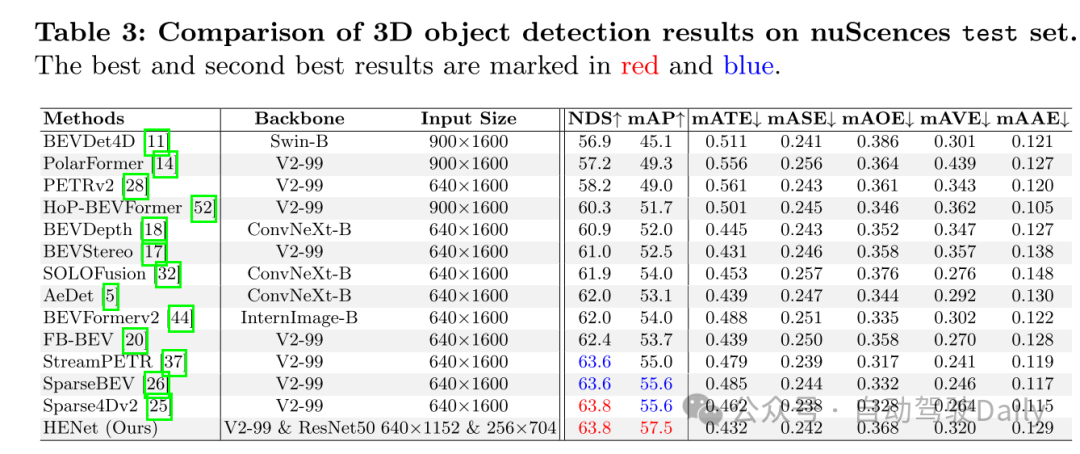
实验结果:
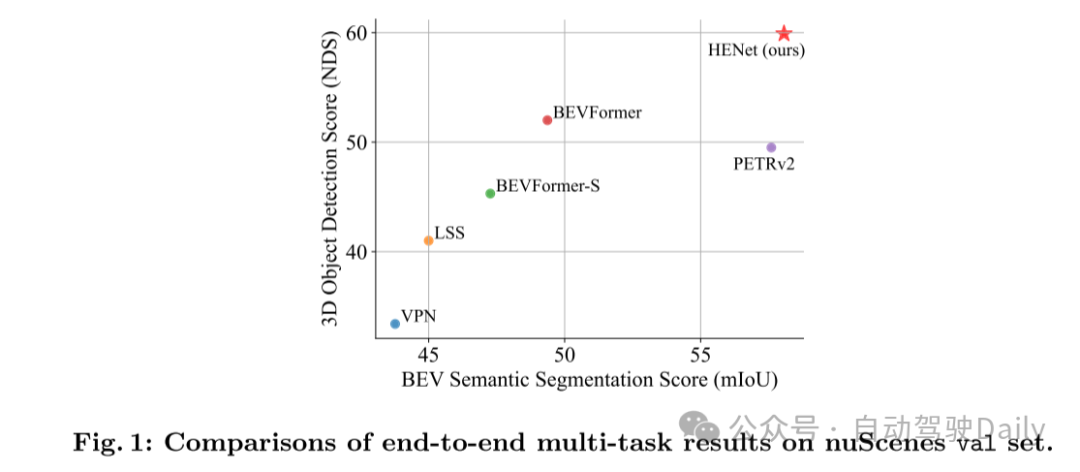
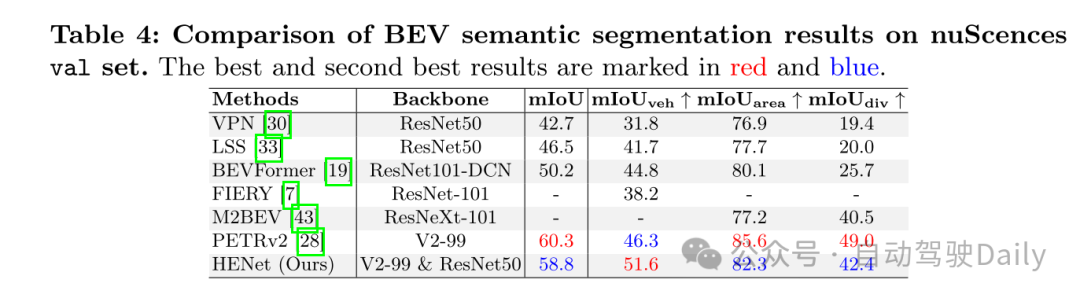
图1:在nuScenes验证集上端到端多任务结果的比较。
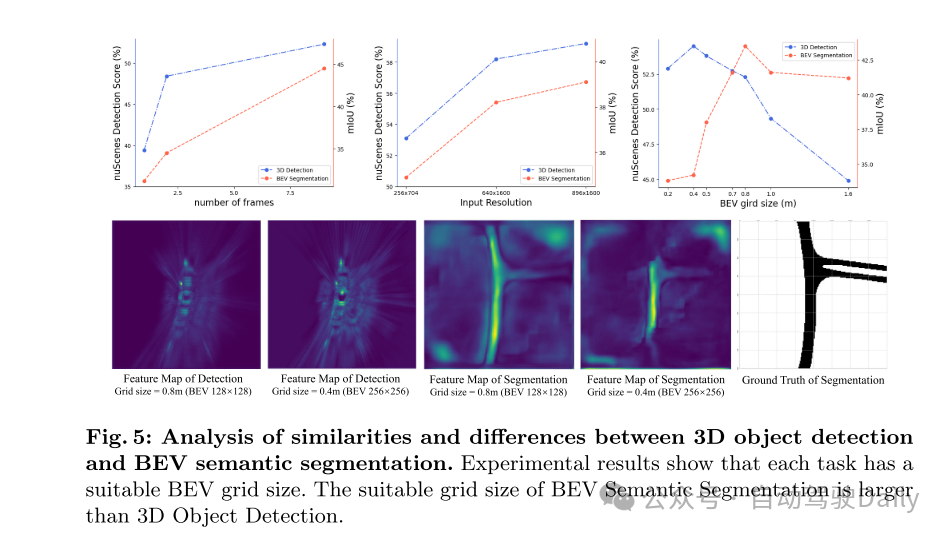
图5:分析3D目标检测与BEV语义分割之间的相似性和差异。实验结果表明,每个任务都有适合的BEV网格大小。BEV语义分割的适宜网格大小 大于 3D目标检测的适宜网格大小。

图6:HENet及基线在端到端多任务处理上的可视化结果。


总结:
本文提出了HENet,这是一个端到端的多任务3D感知框架。本文提出了一种混合图像编码网络和时序特征集成模块,以高效处理高分辨率和长期时间序列的图像输入。此外,本文采用了特定于任务的BEV网格大小、独立的BEV特征编码器和解码器来解决多任务冲突问题。实验结果表明,HENet在nuScenes上获得了最先进的多任务结果,包括3D目标检测和BEV语义分割。
引用:
Xia Z, Lin Z W, Wang X, et al. HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras[J]. arXiv preprint arXiv:2404.02517, 2024.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









